Was sind Einbettungen beim Machine Learning?
Was sind Einbettungen beim Machine Learning?
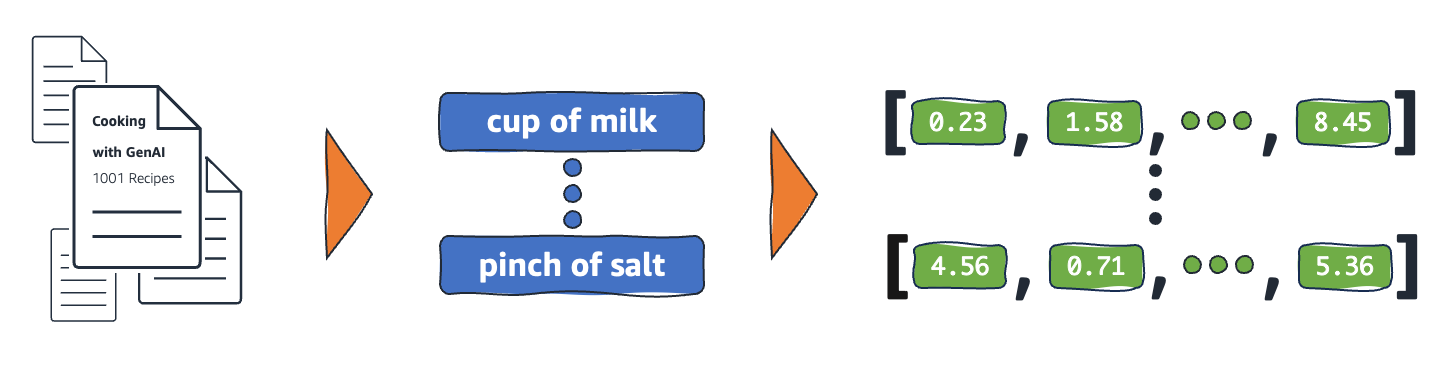
Einbettungen sind numerische Repräsentationen realer Objekte, die Systeme für maschinelles Lernen (ML) und künstliche Intelligenz (KI) verwenden, um komplexe Wissensdomänen wie Menschen zu verstehen. Beispielsweise gehen Rechenalgorithmen davon aus, dass der Unterschied zwischen 2 und 3 1 ist, was auf eine enge Beziehung zwischen 2 und 3 im Vergleich zu 2 und 100 hinweist. Daten aus der realen Welt beinhalten jedoch komplexere Zusammenhänge. Ein Vogelnest und eine Löwenhöhle sind beispielsweise analoge Paare, während Tag und Nacht entgegengesetzte Begriffe sind. Einbettungen wandeln reale Objekte in komplexe mathematische Repräsentationen um, die inhärente Eigenschaften und Beziehungen zwischen realen Daten erfassen. Der gesamte Prozess ist automatisiert, wobei KI-Systeme während des Trainings selbst Einbettungen erstellen und sie bei Bedarf verwenden, um neue Aufgaben zu erledigen.
Warum sind Einbettungen wichtig?
Einbettungen ermöglichen Deep-Learning-Modellen, reale Datendomänen effektiver zu verstehen. Sie vereinfachen die Darstellung realer Daten und behalten gleichzeitig die semantischen und syntaktischen Beziehungen bei. Dadurch können Algorithmen für Machine Learning komplexe Datentypen extrahieren und verarbeiten und innovative KI-Anwendungen ermöglichen. In den folgenden Abschnitten werden einige wichtige Faktoren beschrieben.
Reduzieren Sie die Datendimensionalität
Datenwissenschaftler verwenden Einbettungen, um hochdimensionale Daten in einem niedrigdimensionalen Raum darzustellen. In der Datenwissenschaft bezieht sich der Begriff Dimension typischerweise auf eine Funktion oder ein Attribut der Daten. Höherdimensionale Daten in KI beziehen sich auf Datensätze mit vielen Merkmalen oder Attributen, die jeden Datenpunkt definieren. Dies kann Dutzende, Hunderte oder sogar Tausende von Dimensionen bedeuten. Beispielsweise kann ein Bild als hochdimensionale Daten betrachtet werden, da jeder Pixelfarbwert eine separate Dimension darstellt.
Wenn Deep-Learning-Modelle hochdimensionale Daten erhalten, benötigen sie mehr Rechenleistung und Zeit, um genau zu lernen, zu analysieren und Schlussfolgerungen zu ziehen. Einbettungen reduzieren die Anzahl der Dimensionen, indem Gemeinsamkeiten und Muster zwischen verschiedenen Merkmalen identifiziert werden. Dies reduziert folglich die Rechenressourcen und die Zeit, die für die Verarbeitung von Rohdaten erforderlich sind.
Große Sprachmodelle trainieren
Einbettungen verbessern die Datenqualität beim Training großer Sprachmodelle (LLMs). Datenwissenschaftler verwenden beispielsweise Einbettungen, um die Trainingsdaten von Unregelmäßigkeiten zu befreien, die das Modelllernen beeinträchtigen. ML-Techniker können vortrainierte Modelle auch wiederverwenden, indem sie neue Einbettungen für Transferlernen hinzufügen, was eine Verfeinerung des grundlegenden Modells mit neuen Datensätzen erfordert. Mithilfe von Einbettungen können Techniker ein Modell für benutzerdefinierte Datensätze aus der realen Welt optimieren.
Entwickeln Sie innovative Anwendungen
Einbettungen ermöglichen neue Anwendungen für Deep Learning und generative künstliche Intelligenz (generative KI). Verschiedene Einbettungstechniken, die in der neuronalen Netzwerkarchitektur angewendet werden, ermöglichen die Entwicklung, das Training und den Einsatz genauer KI-Modelle in verschiedenen Bereichen und Anwendungen. Beispiel:
- Mithilfe von Bildeinbettungen können Techniker hochpräzise Computer-Vision-Anwendungen für die Objekterkennung, Bilderkennung und andere visuelle Aufgaben erstellen.
- Mithilfe von Worteinbettungen kann Software zur Verarbeitung natürlicher Sprache den Kontext und die Beziehungen von Wörtern genauer verstehen.
- Graph-Einbettungen extrahieren und kategorisieren verwandte Informationen aus miteinander verbundenen Knoten, um die Netzwerkanalyse zu unterstützen.
Computer-Vision-Modelle, KI-Chatbots und KI-Empfehlungssysteme verwenden alle Einbettungen, um komplexe Aufgaben zu erledigen, die die menschliche Intelligenz nachahmen.
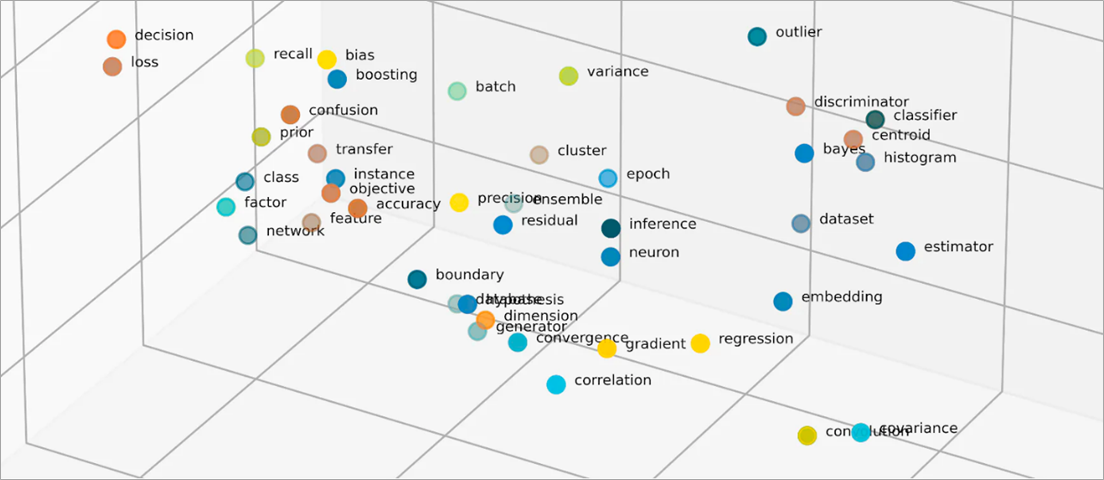
Was sind Vektoren in Einbettungen?
ML-Modelle können Informationen in ihrem Rohformat nicht verständlich interpretieren und benötigen numerische Daten als Eingabe. Sie verwenden neuronale Netzwerkeinbettungen, um reale Wortinformationen in numerische Repräsentationen umzuwandeln, die als Vektoren bezeichnet werden. Vektoren sind numerische Werte, die Informationen in einem mehrdimensionalen Raum darstellen. Sie ermöglichen es ML-Modellen, Ähnlichkeiten zwischen spärlich verteilten Elementen zu finden.
Jedes Objekt, von dem ein ML-Modell lernt, hat verschiedene Eigenschaften oder Merkmale. Betrachten Sie als einfaches Beispiel die folgenden Filme und Fernsehsendungen. Jedes ist durch Genre, Typ und Erscheinungsjahr gekennzeichnet.
The Conference (Horror, 2023, Film)
Upload (Komödie, 2023, Fernsehserie, Staffel 3)
Tales from the Crypt (Horror, 1989, Fernsehserie, Staffel 7)
Dream Scenario (Horror-Komödie, 2023, Film)
ML-Modelle können numerische Variablen wie Jahre interpretieren, aber keine nichtnumerischen Variablen wie Genre, Typen, Episoden und Gesamtzahl der Staffeln vergleichen. Das Einbetten von Vektoren kodiert nicht-numerische Daten in eine Reihe von Werten, die ML-Modelle verstehen und in Beziehung setzen können. Das Folgende ist beispielsweise eine hypothetische Darstellung der zuvor aufgeführten Fernsehprogramme.
The Conference (1.2, 2023, 20.0)
Upload (2,3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
Die erste Zahl im Vektor entspricht einem bestimmten Genre. Ein ML-Modell würde feststellen, dass The Conference und Tales from the Crypt dasselbe Genre haben. Ebenso wird das Modell anhand der dritten Zahl, die das Format, die Staffeln und die Episoden darstellt, mehr Beziehungen zwischen Upload und Tales from the Crypt finden. Wenn mehr Variablen eingeführt werden, können Sie das Modell verfeinern, um mehr Informationen in einem kleineren Vektorraum zusammenzufassen.
Wie funktionieren Einbettungen?
Einbettungen wandeln Rohdaten in kontinuierliche Werte um, die ML-Modelle interpretieren können. Herkömmlicherweise verwenden ML-Modelle One-Hot-Encoding, um kategoriale Variablen Formen zuzuordnen, aus denen sie lernen können. Die Kodierungsmethode unterteilt jede Kategorie in Zeilen und Spalten und weist ihnen Binärwerte zu. Berücksichtigen Sie die folgenden Produktkategorien und deren Preis.
|
Obst |
Preis |
|
Apple |
5,00 |
|
Orange |
7,00 |
|
Karotte |
10,00 |
Die Darstellung der Werte mit One-Hot-Codierung ergibt die folgende Tabelle.
|
Apple |
Orange |
Birne |
Preis |
|
1 |
0 |
0 |
5,00 |
|
0 |
1 |
0 |
7,00 |
|
0 |
0 |
1 |
10,00 |
Die Tabelle wird mathematisch als Vektoren [1,0,0,5.00], [0,1,0,7.00] und [0,0,1,10.00] dargestellt.
Bei der One-Hot-Codierung werden die Dimensionswerte 0 und 1 erweitert, ohne dass Informationen bereitgestellt werden, anhand derer Modelle die verschiedenen Objekte miteinander in Beziehung setzen können. Das Modell kann beispielsweise keine Ähnlichkeiten zwischen Apfel und Orange feststellen, obwohl es sich um Obst handelt, und es kann auch nicht zwischen Orange und Karotte als Obst und Gemüse unterscheiden. Wenn der Liste weitere Kategorien hinzugefügt werden, führt die Kodierung zu dünn verteilten Variablen mit vielen leeren Werten, die enormen Speicherplatz beanspruchen.
Einbettungen vektorisieren Objekte in einen niedrigdimensionalen Raum, indem Ähnlichkeiten zwischen Objekten mit numerischen Werten dargestellt werden. Einbettungen neuronaler Netzwerke stellen sicher, dass die Anzahl der Dimensionen bei wachsenden Eingabefeatures überschaubar bleibt. Eingabemerkmale sind Merkmale bestimmter Objekte, die ein ML-Algorithmus analysieren soll. Die Reduzierung der Dimensionalität ermöglicht Einbettungen, um Informationen beizubehalten, die ML-Modelle verwenden, um Ähnlichkeiten und Unterschiede zwischen Eingabedaten zu finden. Datenwissenschaftler können auch Einbettungen in einem zweidimensionalen Raum visualisieren, um die Beziehungen verteilter Objekte besser zu verstehen.
Was sind Einbettungsmodelle?
Einbettungsmodelle sind Algorithmen, die darauf trainiert wurden, Informationen in dichten Repräsentationen in einem mehrdimensionalen Raum zu kapseln. Datenwissenschaftler verwenden Embedding-Modelle, um ML-Modellen zu ermöglichen, hochdimensionale Daten zu verstehen und daraus zu folgern. Dies sind gängige Einbettungsmodelle, die in ML-Anwendungen verwendet werden.
Hauptkomponentenanalyse
Die Hauptkomponentenanalyse (PCA) ist eine Technik zur Dimensionsreduzierung, die komplexe Datentypen in niederdimensionale Vektoren reduziert. Es findet Datenpunkte mit Ähnlichkeiten und komprimiert sie, um Vektoren einzubetten, die die Originaldaten widerspiegeln. PCA ermöglicht es Modellen zwar, Rohdaten effizienter zu verarbeiten, während der Verarbeitung kann es jedoch zu Informationsverlusten kommen.
Singulärwertdekomposition
Die Singulärwertdekomposition (SVD) ist ein Einbettungsmodell, das eine Matrix in ihre singulären Matrizen umwandelt. Die resultierenden Matrizen behalten die ursprünglichen Informationen bei und ermöglichen es den Modellen gleichzeitig, die semantischen Beziehungen der Daten, die sie repräsentieren, besser zu verstehen. Datenwissenschaftler verwenden SVD, um verschiedene ML-Aufgaben zu ermöglichen, darunter Bildkomprimierung, Textklassifizierung und Empfehlung.
Word2Vec
Word2Vec ist ein ML-Algorithmus, der darauf trainiert ist, Wörter zu verknüpfen und sie im Einbettungsraum darzustellen. Datenwissenschaftler füttern das Word2Vec-Modell mit riesigen Textdatensätzen, um das Verständnis natürlicher Sprache zu ermöglichen. Das Modell findet Ähnlichkeiten in Wörtern, indem es ihren Kontext und ihre semantischen Beziehungen berücksichtigt.
Es gibt zwei Varianten von Word2Vec – Continuous Bag of Words (CBOW) und Skip-Gram. CBOW ermöglicht es dem Modell, ein Wort aus dem gegebenen Kontext vorherzusagen, während Skip-Gram den Kontext von einem bestimmten Wort ableitet. Word2Vec ist zwar eine effektive Technik zur Worteinbettung, kann aber kontextuelle Unterschiede desselben Wortes, das verwendet wird, um unterschiedliche Bedeutungen zu implizieren, nicht genau unterscheiden.
BERT
BERT ist ein transformatorbasiertes Sprachmodell, das mit riesigen Datensätzen trainiert wurde, um Sprachen so zu verstehen, wie es Menschen tun. Wie Word2Vec kann BERT Worteinbettungen aus Eingabedaten erstellen, mit denen es trainiert wurde. Darüber hinaus kann BERT kontextuelle Bedeutungen von Wörtern unterscheiden, wenn es auf verschiedene Phrasen angewendet wird. BERT erstellt zum Beispiel verschiedene Einbettungen für „spielen“ wie in „Ich war bei einem Fußballspiel“ und „Ich spiele gerne“.
Wie werden Einbettungen erstellt?
Ingenieure verwenden neuronale Netze, um Einbettungen zu erstellen. Neuronale Netzwerke bestehen aus verborgenen Neuronenschichten, die iterativ komplexe Entscheidungen treffen. Beim Erstellen von Einbettungen lernt eine der verborgenen Ebenen, wie Eingabe-Features in Vektoren faktorisiert werden. Dies geschieht vor den Ebenen der Feature-Verarbeitung. Dieser Prozess wird von Technikern mit den folgenden Schritten überwacht und geleitet:
- Techniker versorgen das neuronale Netzwerk mit einigen vektorisierten Proben, die manuell vorbereitet wurden.
- Das neuronale Netzwerk lernt aus den in der Probe entdeckten Mustern und nutzt das Wissen, um anhand unsichtbarer Daten genaue Vorhersagen zu treffen.
- Gelegentlich müssen Techniker möglicherweise eine Feinabstimmung des Modells vornehmen, um sicherzustellen, dass die Eingabe-Features im entsprechenden dimensionalen Raum verteilt werden.
- Im Laufe der Zeit arbeiten die Einbettungen unabhängig voneinander, sodass die ML-Modelle Empfehlungen aus den vektorisierten Darstellungen generieren können.
- Die Techniker überwachen weiterhin die Leistung der Einbettung und stimmen sie mit neuen Daten ab.
Wie kann AWS Ihnen bei Ihren Embedding-Anforderungen helfen?
Amazon Bedrock ist ein vollständig verwalteter Service, der eine Auswahl an leistungsstarken Basismodellen (FMs) von führenden KI-Unternehmen sowie eine breite Palette von Funktionen zur Entwicklung generativer künstlicher Intelligenz (generative KI) -Anwendungen bietet. Amazon Nova ist eine neue Generation von hochmodernen (SOTA) Foundation Models (FMs), die bahnbrechende Informationen und ein branchenführendes Preis-Leistungs-Verhältnis bieten. Es handelt sich um leistungsstarke Allzweckmodelle, die für eine Vielzahl von Anwendungsfällen entwickelt wurden. Verwenden Sie sie unverändert oder passen Sie sie mit Ihren eigenen Daten an.
Titan Embeddings ist ein LLM, das Text in eine numerische Darstellung übersetzt. Das Titan-Embeddings-Modell unterstützt das Abrufen von Text, semantische Ähnlichkeit und Clustering. Der maximale Eingabetext beträgt 8K Tokens und die maximale Länge des Ausgabevektors beträgt 1536.
Teams für maschinelles Lernen können Amazon SageMaker auch verwenden, um Einbettungen zu erstellen. Amazon SageMaker ist ein Hub, in dem Sie ML-Modelle in einer sicheren und skalierbaren Umgebung erstellen, trainieren und bereitstellen können. Es bietet eine Einbettungstechnik namens Object2Vec, mit der Techniker hochdimensionale Daten in einem niederdimensionalen Raum vektorisieren können. Sie können die erlernten Einbettungen verwenden, um Beziehungen zwischen Objekten für nachgelagerte Aufgaben wie Klassifizierungen und Regression zu berechnen.
Beginnen Sie mit Einbettungen auf AWS, indem Sie noch heute ein Konto erstellen.
Nächste Schritte mit AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages