Getting Started / Hands-on / ...
Create a machine learning model automatically
with Amazon SageMaker Autopilot
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly.
In this tutorial, you create machine learning models automatically without writing a line of code! You use Amazon SageMaker Autopilot, an AutoML capability that automatically creates the best classification and regression machine learning models, while allowing full control and visibility.
In this tutorial, you learn how to:
- Create an AWS Account
- Set up Amazon SageMaker Studio to access Amazon SageMaker Autopilot
- Download a public dataset using Amazon SageMaker Studio
- Create a training experiment with Amazon SageMaker Autopilot
- Explore the different stages of the training experiment
- Identify and deploy the best performing model from the training experiment
- Predict with your deployed model
For this tutorial, you assume the role of a developer working at a bank. You have been asked to develop a machine learning model to predict whether a customer will enroll for a certificate of deposit (CD). The model will be trained on the marketing dataset that contains information on customer demographics, responses to marketing events, and external factors.
| About this Tutorial | |
|---|---|
| Time | 10 minutes |
| Cost | Less than $10 |
| Use Case | Machine Learning |
| Products | Amazon SageMaker |
| Audience | Developer |
| Level | Beginner |
| Last Updated | May 12, 2020 |
Step 1. Create an AWS Account
The cost of this workshop is less than $10. For more information, see Amazon SageMaker Studio Pricing.
Already have an account? Sign-in
Step 2. Set up Amazon SageMaker Studio
Complete the following steps to onboard to Amazon SageMaker Studio for access to Amazon SageMaker Autopilot.
Note: For more information, see Get Started with Amazon SageMaker Studio in the Amazon SageMaker documentation.
a. Sign in to the Amazon SageMaker console.
Note: In the top right corner, make sure to select an AWS Region where Amazon SageMaker Studio is available. For a list of Regions, see Onboard to Amazon SageMaker Studio.


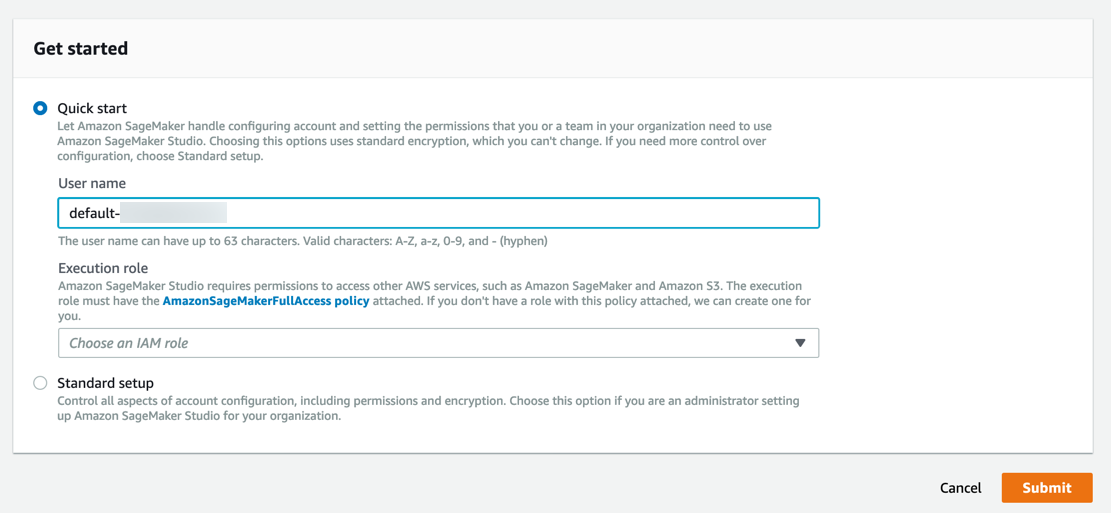
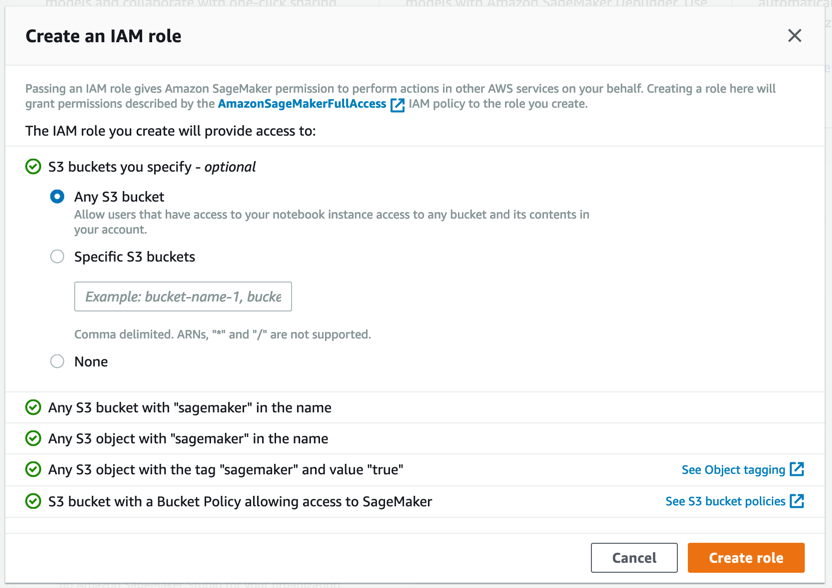
Amazon SageMaker creates a role with the required permissions and assigns it to your instance.
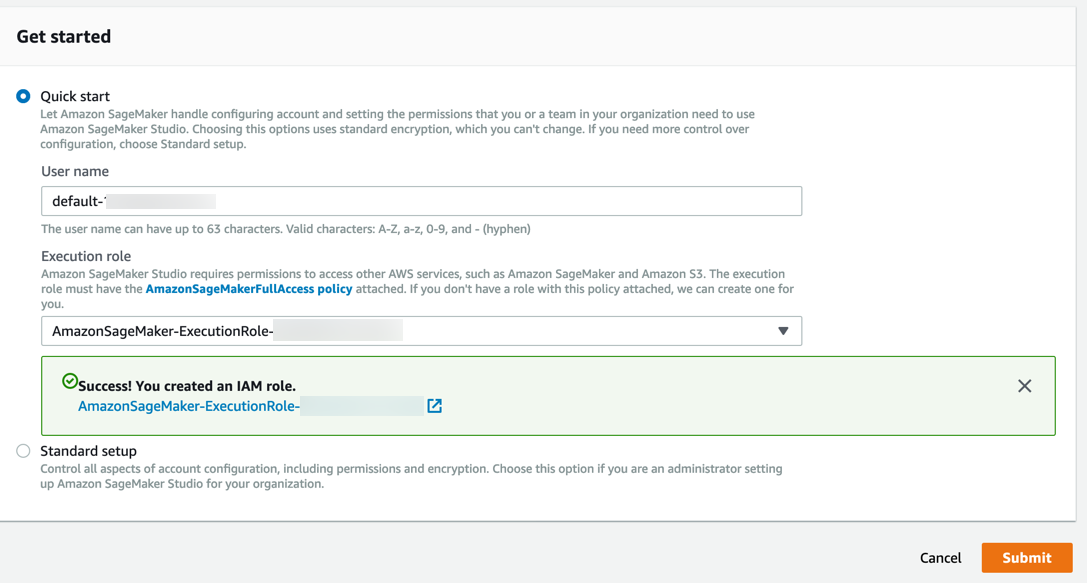
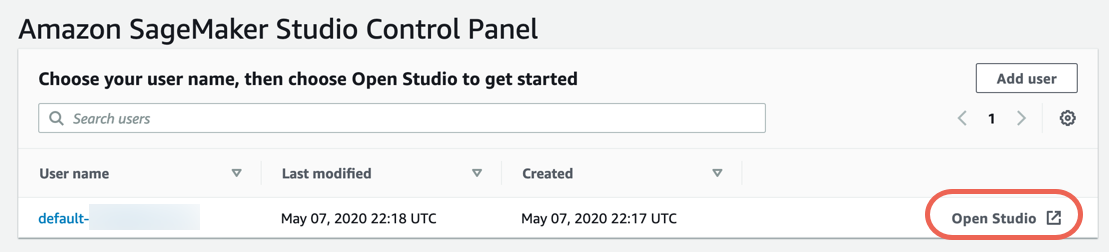
Step 3. Download the dataset
Complete the following steps to download and explore the dataset.
Note: For more information, see Amazon SageMaker Studio tour in the Amazon SageMaker documentation.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Copy and paste the following code into a new code cell and choose Run.
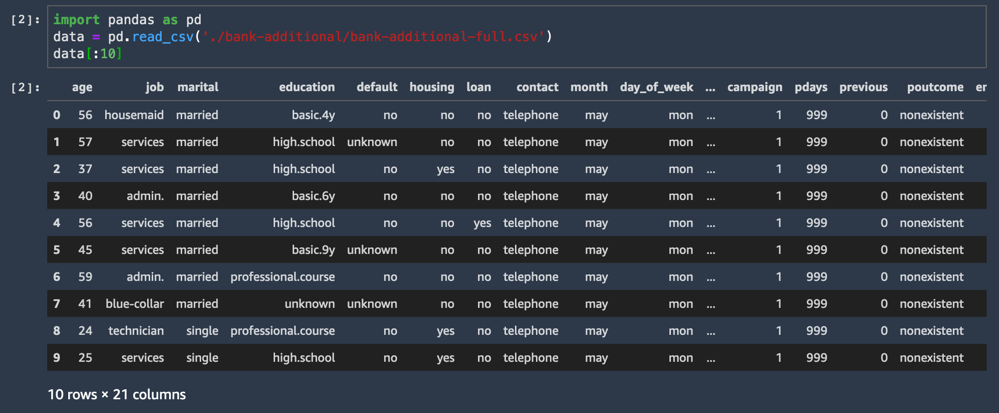
The CSV dataset loads and displays the first ten lines.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]One of the dataset columns is named y, and represents the label for each sample: did this customer accept the offer or not?
This step is where data scientists would start exploring the data, creating new features, and so on. With Amazon SageMaker Autopilot, you don’t need to do any of these extra steps. You simply upload tabular data in a file with comma-separated values (for example, from a spreadsheet or database), choose the target column to predict, and Autopilot builds a predictive model for you.
d. Copy and paste the following code into a new code cell and choose Run.
This step uploads the CSV dataset into an Amazon S3 bucket. You do not need to create an Amazon S3 bucket; Amazon SageMaker automatically creates a default bucket in your account when you upload the data.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
You're done! The code output displays the S3 bucket URI like the following example:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvKeep track of the S3 URI printed in your own notebook. You need it in the next step.

Step 4. Create a SageMaker Autopilot experiment
Now that you have downloaded and staged your dataset in Amazon S3, you can create an Amazon SageMaker Autopilot experiment. An experiment is a collection of processing and training jobs related to the same machine learning project.
Complete the following steps to create a new experiment.
Note: For more information, see Create an Amazon SageMaker Autopilot Experiment in SageMaker Studio in the Amazon SageMaker documentation.
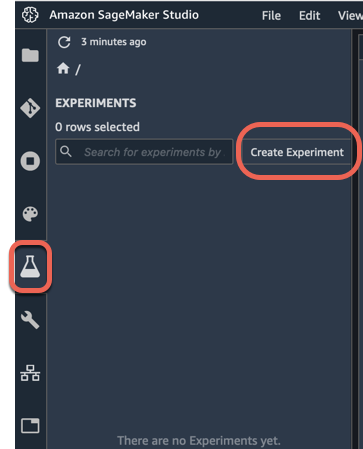
a. In the left navigation pane of Amazon SageMaker Studio, choose Experiments (icon symbolized by a flask), then choose Create Experiment.
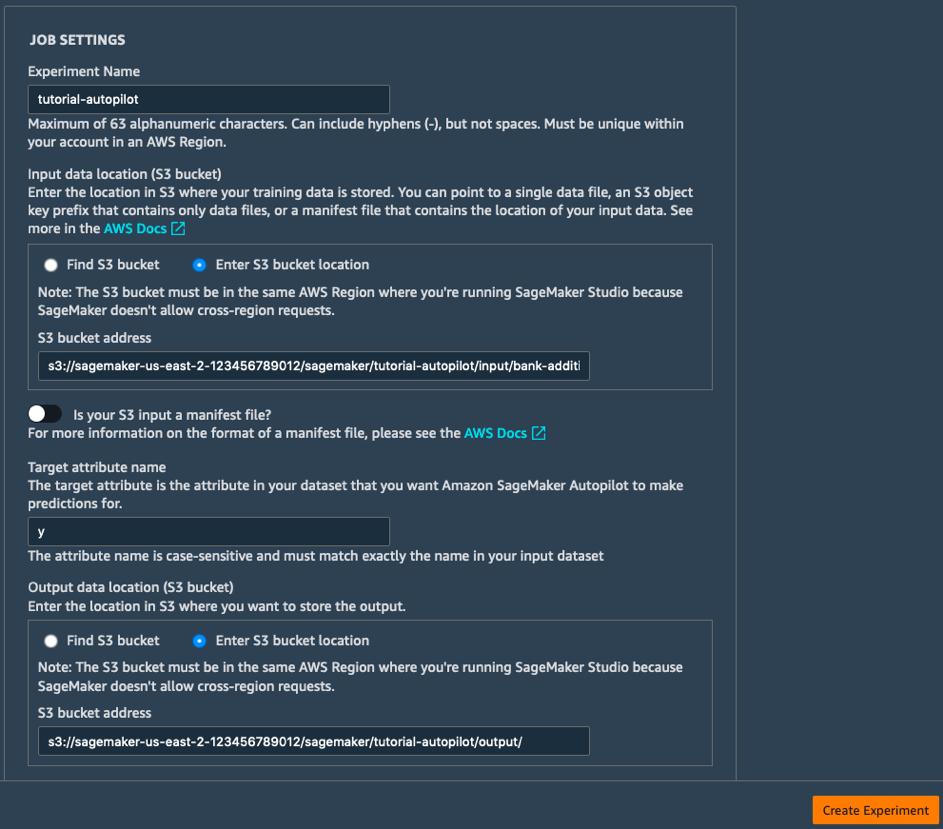
b. Fill the Job Settings fields as follows:
- Experiment Name: tutorial-autopilot
- S3 location of input data: S3 URI you printed above
(e.g. s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name: y
- S3 location for output data: s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(make sure to replace [ACCOUNT-NUMBER] with your own account number)
c. Leave all other settings as the defaults and choose Create Experiment.
Success! This starts the Amazon SageMaker Autopilot experiment! The process will generate a model as well as statistics that you can view in real time while the experiment is running. After the experiment is completed, you can view the trials, sort by objective metric, and right-click to deploy the model for use in other environments.
Step 5. Explore SageMaker Autopilot experiment stages
While your experiment is running, you can learn about and explore the different stages of the SageMaker Autopilot experiement.
This section provides more details on the SageMaker Autopilot experiment stages:
- Analyzing Data
- Feature Engineering
- Model Tuning
Note: For more information, see the SageMaker Autopilot Notebook Output.
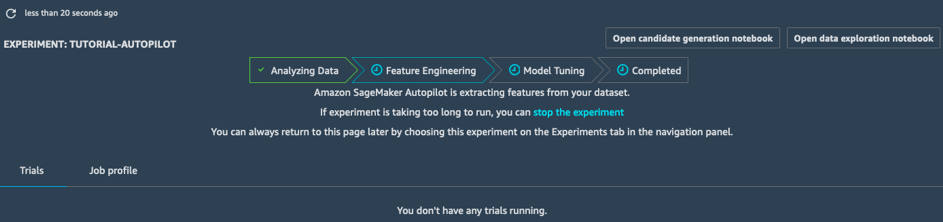
Analyzing Data
The Analyzing Data stage identifies the problem type to be solved (linear regression, binary classification, multiclass classification). Then, it comes up with ten candidate pipelines. A pipeline combines a data preprocessing step (handling missing values, engineering new features, etc.), and a model training step using an ML algorithm matching the problem type. Once this step is complete, the job moves on to feature engineering.
Feature Engineering
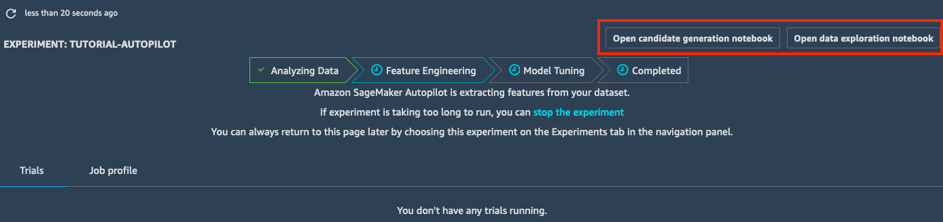
In the Feature Engineering stage, the experiment creates training and validation datasets for each candidate pipeline, storing all artifacts in your S3 bucket. While in the Feature Engineering stage, you can open and view two auto-generated notebooks:
- The data exploration notebook contains information and statistics on the dataset.
- The candidate generation notebook contains the definition of the ten pipelines. In fact, this is a runnable notebook: you can reproduce exactly what the AutoPilot job does, understand how the different models are built, and even keep tweaking them if you want.
With these two notebooks, you can understand in detail how data is preprocessed, and how models are built and optimized. This transparency is an important feature of Amazon SageMaker Autopilot.
Model Tuning
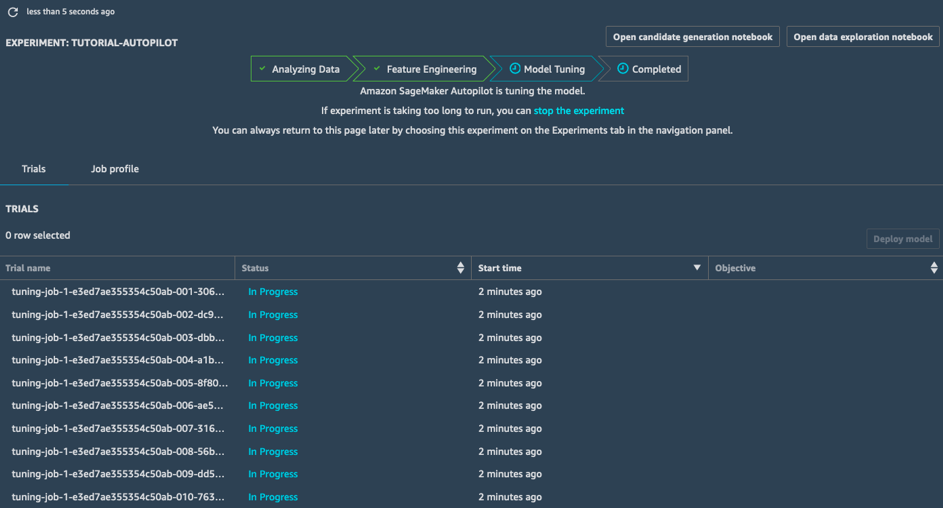
In the Model Tuning stage, for each candidate pipeline and its preprocessed dataset, SageMaker Autopilot launches an hyperparameter optimization job; the associated training jobs explore a wide range of hyperparameter values, and quickly converge to high performance models.
Once this stage is complete, the SageMaker Autopilot job is complete. You can see and explore all jobs in SageMaker Studio.
Step 6. Deploy the best model
Now that your experiment has completed, you can choose the best tuning model and deploy the model to an endpoint managed by Amazon SageMaker.
Follow these steps to choose the best tuning job and deploy the model.
Note: For more information, see the Choose and deploy the best model.
a. In the Trials list of your experiment, choose the carrot next to Objective to sort the tuning jobs in descending order. The best tuning job is highlighted with a star.
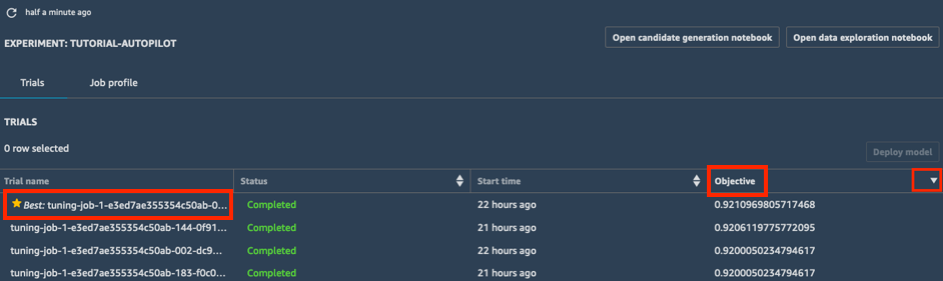
b. Select the best tuning job (indicated by a star) and choose Deploy model.
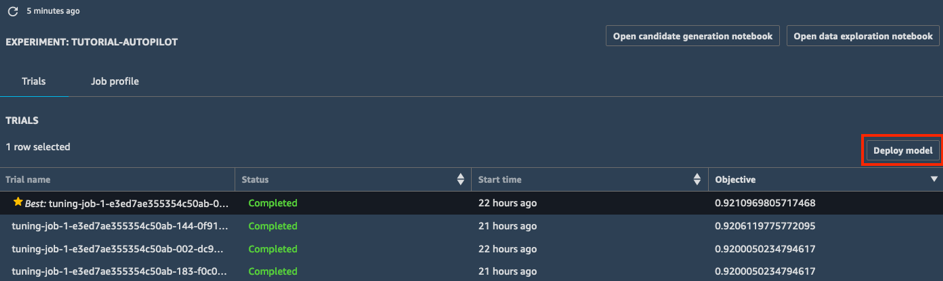
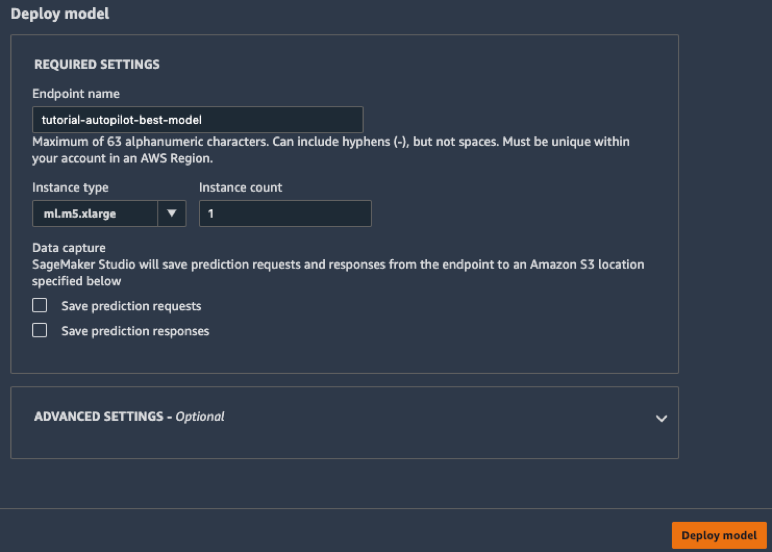
c. In the Deploy model box, give your endpoint a name (e.g. tutorial-autopilot-best-model) and leave all settings as the defaults. Choose Deploy model.
Your model is deployed to an HTTPS endpoint managed by Amazon SageMaker.
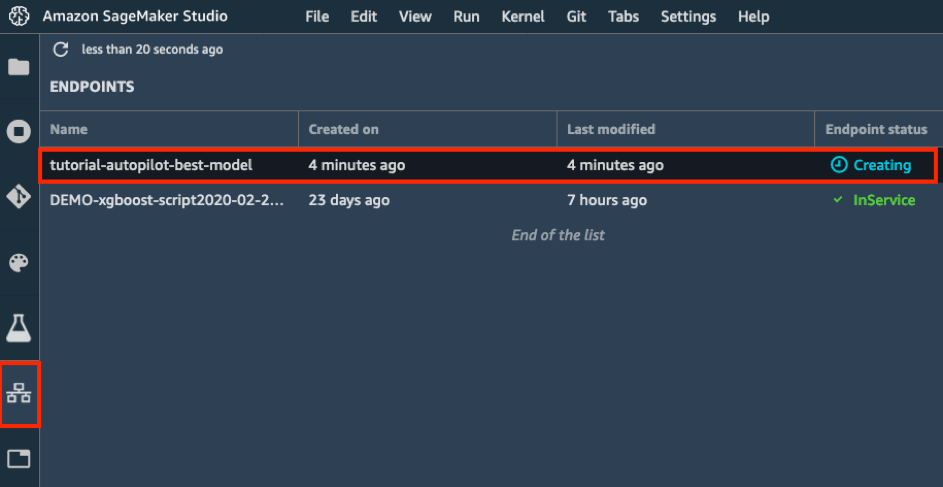
d. In the left toolbar, choose the Endpoints icon. You can see your model being created, which will take a few minutes. Once the endpoint status is InService, you can send data and receive predictions!
Step 7. Predict with your model
Now that the model is deployed, you can predict the first 2,000 samples of the dataset. For this purpose, you use the invoke_endpoint API in the boto3 SDK. In the process, you compute important machine learning metrics: accuracy, precision, recall, and the F1 score.
Follow these steps to predict with your model.
Note: For more information, see the Manage Machine Learning with Amazon SageMaker Experiments.
In your Jupyter notebook, copy and paste the following code and choose Run.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tp/(tp+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
You should see the following output.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
This output is a progress indicator showing the number of samples that have been predicted!
Step 8. Clean up
In this step, you terminate the resources you used in this lab.
Important: Terminating resources that are not actively being used reduces costs and is a best practice. Not terminating your resources will result in charges to your account.
Delete your endpoint: In your Jupyter notebook, copy and paste the following code and choose Run.
sess.delete_endpoint(endpoint_name=ep_name)If you want to clean up all training artifacts (models, preprocessed data sets, etc.), copy and paste the following code into your code cell and choose Run.
Note: Make sure to replace ACCOUNT_NUMBER with your account number.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Congratulations
You created a machine learning model with the best accuracy automatically with Amazon SageMaker Autopilot.
Recommended next steps
Take a tour of Amazon SageMaker Studio
Learn more about Amazon SageMaker Autopilot
If you want to learn more, read the blog post or see the Autopilot video series.