Amazon Web Services ブログ

週刊AWS – 2026/7/27週
NFS キャッシュソリューション KNFSD File Cache の Preview 提供開始、Amazon CloudWatch が AI コーディングエージェントの利用状況を可視化する Coding Agent Insights を発表、AWS CloudTrail でネットワークアクティビティイベントを ID 別に選択的にログ記録可能に、Amazon RDS for SQL Server が Microsoft SQL Server 2025 に対応、Amazon ECS がデプロイ中の操作を可視化する Action Logs を提供開始、Amazon SES が 3 段階の料金プランを導入、Amazon EKS の EKS Auto Mode と Karpenter で EFA と Placement Group をサポート、Network Load Balancer が送信元 IP アドレスタイプに基づくリスナールールに対応、Amazon CloudWatch Logs が Application Load Balancer ログに対応、AI エージェント向けオープンソースベンチマーク aws-bench をリサーチプレビューで公開、AWS で Claude Opus 5 が利用可能に等
オープンソースサプライチェーン攻撃の背後にいる北朝鮮のハッカーグループを Amazon が特定
Amazon Threat Intelligence は、axios、debug、chalk、typo-crypto という人気 NPM パッケージの侵害が、同一の北朝鮮 (DPRK) に関連する脅威アクターによるものであることを初めて特定しました。本記事では、オープンソースサプライチェーン攻撃の手口がどのように進化しているか、スロップスクワッティングや間接プロンプトインジェクションといった生成 AI がもたらす新たな脅威、そして Amazon Inspector や Amazon GuardDuty を通じた AWS の対応について解説します。

AWS Nitro Isolation Engine: AWS Nitro System におけるハイパーバイザーの形式的検証
AWS Nitro System のハイパーバイザー内で分離を実施する専用コンポーネント「AWS Nitro Isolation Engine」の一般提供を Graviton5 ベースのインスタンスで開始しました。形式的検証により、機密性と完全性、機能的正確性、ランタイムエラーの不在、メモリ安全性という 4 つの特性を数学的に証明し、形式的に検証された初のクラウドハイパーバイザーを実現します。Rust による実装や今後の展望も紹介します。
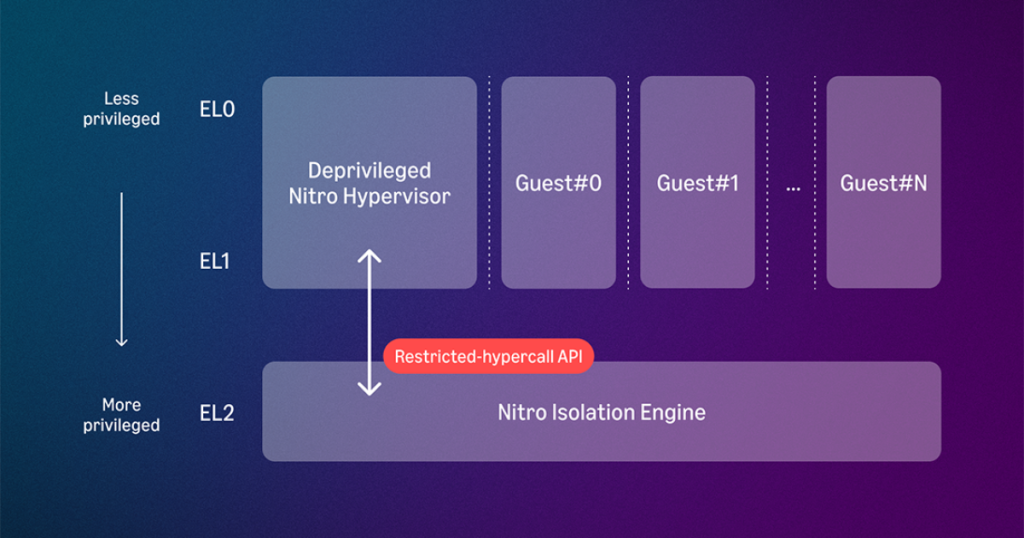
形式的検証済みの Nitro Isolation Engine が Amazon EC2 の仮想マシン分離を数学的に保証
Amazon EC2 の新しい M9g/M9gd インスタンスとともに一般提供が始まった Nitro Isolation Engine は、商用クラウド環境にデプロイされた初の形式的検証済みハイパーバイザーの重要なコンポーネントで、その唯一の役割は仮想マシン (VM) を相互に分離することです。本記事では、Isabelle/HOL 定理証明支援系を用い、機械的に検証された 330,000 行の数学的記述によって VM 間の分離を証明した手法を解説します。μRust と分離論理による機能検証、非干渉性に基づく機密性と完全性の証明を紹介します。

Isabelle/HOL: Nitro Isolation Engine を支える定理証明支援系
Amazon Web Services (AWS) は、定理証明支援系 Isabelle/HOL を用いて Nitro Isolation Engine (NIE) の正当性とセキュリティ保証を検証し、世界初の形式的に検証されたクラウドハイパーバイザーを実現しました。本記事では、ブール論理から一階述語論理、高階論理、依存型理論に至る数理論理の言語階層を解説し、Isabelle/HOL が備える数学的な記述の表現力、自動化、スケーラビリティのバランスや、sledgehammer やロケールなどの主要機能、seL4 や CRDT などの応用事例を紹介します。

寄稿:三菱UFJフィナンシャル・グループの DX を牽引する Japan Digital Design、Aurora DSQL の採用で DB コストを約 87% 削減し、運用負荷ほぼゼロを実現
本稿は、Japan Digital Design 株式会社 佐藤様による「三菱UFJフィナンシャル・グループの […]

AWS Weekly Roundup: アテネのローカルゾーン、AWS 上の Claude Opus 5、.NET 用の Lambda 永続実行など (2026 年 7 月 27 日)
2026 年 7 月 20 日週、私はサンパウロで中南米各地のテクニカルビルダーと 3 日間過ごす機会に恵まれ […]

【開催報告】AWS Summit Japan 2026 〜 流通小売・消費財・飲食業界向けブース
こんにちは。流通小売・消費財・飲食業界を担当するソリューションアーキテクトチームです。 6 月 25 日(木) […]

2026 年 6 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2026 年 06 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
Outpost VFX が ビジュアルエフェクト向けに AI モデルのトレーニングを AWS で加速した方法
本記事では、Outpost VFX が AWS インフラを活用してトレーニング速度を 8 倍に向上させ、顔置換ワークフローを刷新した方法、単一 GPU の限界を克服するために実装した技術アーキテクチャ、そして AWS マルチ GPU トレーニングで得られた具体的な成果について紹介します。