Amazon Web Services ブログ
Amazon EventBridge を利用した Amazon Elastic Container Service Anomaly Detector
この記事は Amazon Elastic Container Service Anomaly Detector using Amazon EventBridge を翻訳したものです。
この記事は Ugur KIRAと Santosh Kumar によって投稿されました。このコンセプトは大規模な ECS クラスターの管理に関する Skyscanner UKとの議論から生まれました。
Amazon EventBridge はサーバーレスのイベントバスで、独自のアプリケーション、統合された SaaS (Software-as-a-Service) アプリケーション、AWS サービスからのデータを使用して、アプリケーション同士を簡単に接続することができます。
EventBridge は Amazon Elastic Container Service (Amazon ECS) などのイベントソースからリアルタイムまたはそれに近いデータのストリームを配信し、そのデータを AWS Lambda や Amazon Simple Notification Service などのターゲットにルーティングします。これにより、AWS サービスを自動化し、アプリケーションの可用性の問題やリソースの変更などのシステムイベントに自動的に対応することができます。EventBridge の Amazon ECS イベントを使用すると Amazon ECS クラスターの現在の状態に関する通知をほぼリアルタイムに受け取ることができます。タスクが Fargate 起動タイプを使用している場合は、タスクの状態を確認できます。タスクが EC2 起動タイプを使用している場合は、コンテナインスタンスとその上で実行されているすべてのタスクの現在の状態の両方を確認できます。
ECS と EventBridge の統合により、ECS のお客様はコンテナインスタンスの状態変化、タスクの状態変化、サービスのスケーリングアクティビティなど、すべての ECS イベントを詳細なレベルで追跡することができます。さらに ECS のユーザーは ECS サービスで発生した異常なイベントを直ちに検出することができます。
ミッションクリティカルなワークロードを、複数の ECS サービスを実行する単一の大規模な ECS クラスターに導入することがよくあります。このアプローチの運用上の課題は、同時に発生するサービスイベントの数が多いため、誤動作や異常なスケールをしているサービスを識別するのに時間がかかることです。このような複雑な本番環境の異常をタイムリーに検出できないと、インシデントに即座に対応する能力が制限され、ECS サービス上で稼働する本番ワークロードへの影響が大きくなります。
Amazon ECS サービススケジューラによって実施されたタスクの配置とインスタンスのヘルスイベントが AWS コンソールに表示されます。このイベントビューは役に立ちますが、ECS は直近の 100 のサービスイベントしか表示しません。多くの ECS クラスターにとって、直近の 100 のイベント表示だけではサービスアクティビティを適切に分析するのに十分ではありません。
大規模な ECS クラスターでは、問題の根本原因を検出したり、問題が発生したサービスをピンポイントで特定したり、異常なスケーリングや特定のサービスによってトリガーされたスケーリングアクティビティが正当なものかどうかを判断することができなくなる可能性があります。これは本番 ECS クラスターを大規模に運用する能力を低下させます。そこで ‘ECS Anomaly Detection powered by Amazon EventBridge’ を導入することで、ECS サービス全体に共通する異常をほぼリアルタイムで検出し、長期間経過した後でも ECS サービスで発生したイベントに関するレポートをオンデマンドで生成できるようになります。
このブログでは ECS Anomaly Detection のアーキテクチャについて説明します。このアーキテクチャではすべての ECS イベントを CloudWatch Logs にストリーミングし、Lambda 関数をトリガーする複数のターゲットを使用し、SNS 通知を送信することで以下を行います。
- Amazon EventBridge が提供する ECS イベントを分析することで、複数の ECS サービスにまたがる異常なスケーリング動作やタスク配置の失敗などの異常を検知
- CW Logs Insights Queries を使用したオンデマンドレポートの生成や、タスクレベルでのリソース使用状況の分析
- サービス内で異常の検出や ECS サービスのデプロイメントの開始/失敗を SNS を通じて通知
この方法は既存の ECS クラスターだけでなく新規の ECS クラスターにも使用できます。既存のクラスターでは ECS イベントを有効にしてからクエリ実行が可能になります。
概要
現時点で Amazon ECS は 3 つの異なるイベントカテゴリ (Info、Warning、Error) で 4 種類のイベントを Amazon EventBridge に送信することができます。これらのイベントは「コンテナインスタンス状態変更イベント」「タスク状態変更イベント」「サービスアクションイベント」および「サービスデプロイ状態変更イベント」です。ECS Anomaly Detector ではこれらの ECS イベントを捕捉し、サーバーレスアーキテクチャを用いて ECS のサービスアクティビティに関するインサイトをほぼリアルタイムで提供します。
ECS Anomaly Detection の一部として、まず ECS クラスターのすべてのイベントを取得し CloudWatch Logs に保存します。その後、EventBridge ルールのマルチターゲット機能を使用して CloudWatch Logs Insights や Lambda 関数を利用したイベント分析、必要に応じて SNS を使用した SERVICE_TASK_PLACEMENT_FAILURE イベントのアラート通知を行います。
前提条件
- アクティブな AWS アカウント
- 少なくとも 1 つのサービスが稼働している ECS クラスター
- AWS CLI と管理者権限またはセットアップを実行するために必要なすべての権限を持つ IAM ユーザー
- jq – コマンドラインベースの JSON プロセッサ
- ECS Anomaly Detection のワークフローでは複数の ECS サービスを持つ 1 つの ECS クラスターを設定対象とします。複数のクラスターをサポートするためには、後述の「まとめ」に記載されている考慮事項を確認してください。
ソリューションの詳細:
大まかに言うと ECS Anomaly Detector は複数の EventBridge ルールを使用してすべてのイベントを検出し、 CloudWatch Logs Insights で分析するために CloudWatch Logs に保存します。その際に、イベントの種類やカテゴリに応じて SNS や Lambda 関数などのサポート済みのターゲットも活用します。ここでは、EventBride ルールの詳細と高いレベルで設定されたターゲットについて紹介します。
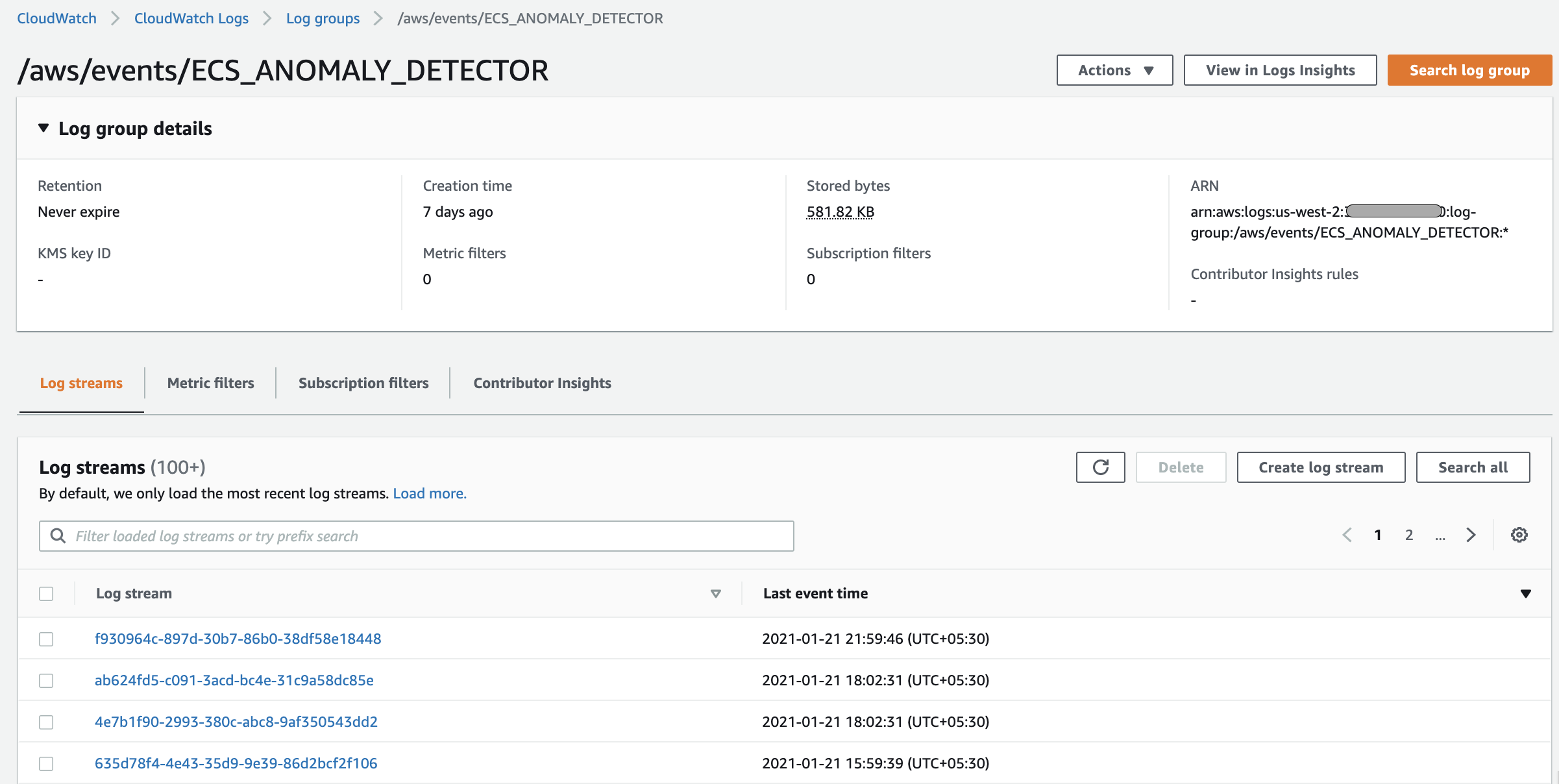
- すべての ECS サービスのイベントと ECS タスクの状態変更イベントは ‘ECS_AD_ServiceActivity’ という名前の EventBridge ルールによって検出されます。また、‘/aws/events/ECS_ANOMALY_DETECTOR’ という名前の CloudWatch ロググループに保存され、CloudWatch Logs Insights を使用してオンデマンドで分析されます。
- 2 番目の EventBridge ルール ‘ECS_AD_ServiceAction_ERROR’ は ERROR および WARN タイプの ECS サービスイベントのみを検出し、設定された SNS トピックを使用して E メールでアラートを送信するために使用されます。
- 3 番目の EventBridge ルール ‘ECS_AD_StoppedTask_Detector’ は失敗したタスクや問題のあるタスクを検出し、設定された SNS トピックを使用して E メールでアラートを送信するために使用されます。
- 4 番目の EventBridge ルール ‘ECS_AD_DeploymentStateChange_Event’ は ECS のすべての「サービスデプロイ状態変更イベント」を検出し 2 つの異なるターゲットに送信するために使用されます。ターゲットは CloudWatch Logs と SNS トピックです。CloudWatch Logs のターゲットは、イベントを ‘/aws/events/ECS_ANOMALY_DETECTOR’ という CloudWatch ロググループに保存し、SNS トピックのターゲットは E メールでアラートを送信します。
- 5 番目の EventBridgeルール ‘ECS_AD_UpdateService_CTEvent’ は CloudTrail のログを通じて ‘UpdateService’ の API コールを検出し、2 つの異なるターゲットに送信するために使用されます。ターゲットは CloudWatch Logs と Lambda 関数です。このルールは主に ECS サービスごとのスケーリングアクティビティに焦点を当てています。
これは ECS Anomaly Detection を構成するアーキテクチャの個々のコンポーネントを示す図です。
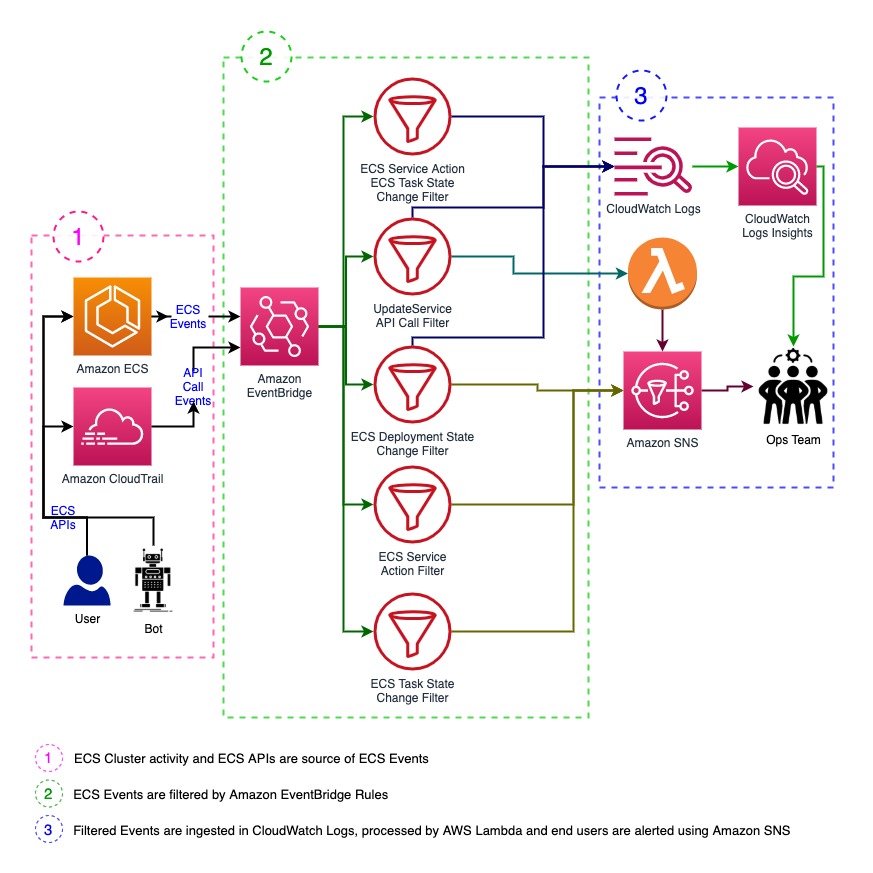
Amazon EventBridge を利用した ECS に関連するすべてのイベントの取り込み
「サービスアクションイベント」「タスク状態変更イベント」「サービスデプロイ状態変更イベント」に記載があるように、Amazon ECS は ECS サービスに関連するすべての重要なイベントを Amazon EventBridgeに 送信します。以下の手順を実行すると EventBridge ルールのセットを設定し、1 つまたは複数の ECS サービス固有のイベントをフィルタリングし、Amazon CloudWatch ロググループに異常検出のためのイベントを記録することができます。
Step 1: Amazon EventBridge ルールでのログ取り込みを可能にする CloudWatch Logs ポリシーを設定する
ECS イベントを CloudWatch Logs、SNS トピック、または Lambda 関数に発行する場合、EventBridge はリソースベースのポリシーに依存します。次のコマンドを使用して、EventBridge が CloudWatch Logs に対して CreateLogStream と PutLogEvents を実行するの必要なリソースベースのポリシーが存在するかどうかを確認します。
注:デフォルトではこのブログの手順はすべての AWS リソースを us-west-2 リージョンに作成します。REGION 変数を、 ECS クラスターや Anomaly Detection で使用するリソースを作成したいリージョンに変更しましょう。
export REGION='us-west-2'
export ACCOUNTID=$(aws sts get-caller-identity --region $REGION --output text | awk '{print $1}')
aws logs describe-resource-policies --region $REGION --output jsonCloudWatch Logs に対して EventBridge がログストリーム (logs:CreateLogStream) を作成しログイベント (logs:PutLogEvents) を保存を許可するポリシーがない場合、以下のコマンドを使用して作成してください。
POLICY_DOCUMENT="{\"Version\":\"2012-10-17\",\"Statement\":[{\"Sid\":\"TrustEventsToStoreLogEvent\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":[\"events.amazonaws.com\",\"delivery.logs.amazonaws.com\"]},\"Action\":[\"logs:CreateLogStream\",\"logs:PutLogEvents\"],\"Resource\":\"arn:aws:logs:$REGION:$ACCOUNTID:log-group:/aws/events/*:*\"}]}"
aws logs put-resource-policy --policy-name TrustEventsToStoreLogEvents --policy-document $POLICY_DOCUMENT --region $REGIONStep 2: Amazon EventBridge 経由で通知を送るための SNS トピックを作成する
通知の送信に使用する既存の SNS トピックがある場合は変数 “SNS_TOPIC_NAME” に SNS トピック名を指定して、Step 3 に進んでください。
既存の SNS トピックがない場合は、以下のコマンドで SNS トピックを作成してください。
export SNS_TOPIC_NAME="ECS_AD_Notification_Topic"
export TOPIC_ARN="arn:aws:sns:$REGION:$ACCOUNTID:$SNS_TOPIC_NAME"
aws sns create-topic --name $SNS_TOPIC_NAME --region $REGIONSNS トピックに送信された通知を受信するためには、サブスクライバが SNS トピックをサブスクライブする必要があります。このブログでは、E メールによる通知を使用します。そのため、上記で作成した SNS トピックに E メールが登録されている必要があります。以下のコマンドで例示しているメールアドレス “myemail@example.com” を、通知を受けたいメールアドレスに置き換えてコマンドを実行してください。
export EMAIL_ID='myemail@example.com'
aws sns subscribe --topic-arn $TOPIC_ARN --protocol email --notification-endpoint $EMAIL_ID --region $REGIONAWS は subscribe コマンドで指定したメールアドレスに対して、すぐに確認メッセージを E メールで送信します。必ず E メールを確認し、送られてきたリンクをクリックしてサブスクリプションを確認してください。
Step 3: Amazon EventBridge が Amazon SNS トピックに対してイベントを送信できる IAM ポリシーが存在するかどうかを確認する
EventBridge ルールから SNS トピックに通知を発行するために必要なリソースベースのポリシーは、AWS マネジメントコンソールを使ってルールを作成し、そのターゲットとして SNS を追加すると自動的に作成されますが、CLI や SDK を使ってルールを作成する場合は明示的に作成する必要があります。SNS トピックにリソースベースのポリシーが既に設定されているかどうかを確認するには、以下のコマンドを実行します。
注:以下の SNS_TOPIC_NAME は、通知の送信に使用したい SNS トピック名に置き換えてください。
export TOPIC_ARN="arn:aws:sns:$REGION:$ACCOUNTID:$SNS_TOPIC_NAME"
aws sns get-topic-attributes --topic-arn "$TOPIC_ARN" --region $REGION --output jsonEventBridge が SNS トピックにイベントを送信できるポリシーがない場合、以下のコマンドを使用してポリシーを作成してください。
注:以下のコマンドを実行する前に、jq が インストールされていることを確認してください。
aws sns get-topic-attributes --topic-arn "$TOPIC_ARN" --region $REGION --output json --query 'Attributes.Policy' | jq -r '.' | jq --arg TOPIC_ARN "$TOPIC_ARN" '.Statement += [{"Sid":"PublishEventsToMyTopic","Effect":"Allow","Principal":{"Service":"events.amazonaws.com"},"Action":"sns:Publish","Resource": $TOPIC_ARN}]' > /tmp/ECS_AD_SNSTopicPolicy.json
aws sns set-topic-attributes --topic-arn "$TOPIC_ARN" --attribute-name Policy --attribute-value file:///tmp/ECS_AD_SNSTopicPolicy.json --region $REGIONStep 4: Amazon EventBridge ルールを作成して ECS の「サービスアクション」と「タスク状態変更イベント」を検出し、CloudWatch Logs に記録する
以下のコマンドを実行して ECS の「サービスアクション」と「タスク状態変更イベント」を CloudWatch ロググループに記録する EventBridge ルールをセットアップします。以下の JSON の ECS_CLUSTER_NAME を ECS クラスターの名前に置き換えてください。
export ECS_CLUSTER_NAME='YourECSClusterName'
export CW_LG_NAME='ECS_ANOMALY_DETECTOR'
aws logs create-log-group --log-group-name "/aws/events/$CW_LG_NAME" --region $REGION
cat <<EOF > /tmp/EventRulePattern.json
{
"source": [
"aws.ecs"
],
"detail-type": [
"ECS Service Action",
"ECS Task State Change"
],
"detail": {
"clusterArn": [
"arn:aws:ecs:$REGION:$ACCOUNTID:cluster/$ECS_CLUSTER_NAME"
]
}
}
EOF
aws events put-rule --name "ECS_AD_ServiceActivity" --event-pattern file:///tmp/EventRulePattern.json --region $REGION
aws events put-targets --rule "ECS_AD_ServiceActivity" --targets "Id"="CWLG","Arn"="arn:aws:logs:$REGION:$ACCOUNTID:log-group:/aws/events/$CW_LG_NAME" --region $REGION必要に応じて上記のイベントパターンの “detail” セクションを削除することで、アカウント内の指定されたリージョンにあるすべての ECS クラスターからのすべてのイベントを取得してストリーミングできます。
一方、ECS クラスター内の特定の ECS サービスのみのイベントを取得してストリームするためには、以下の resources セクションに ECS サービスの ARN を (複数の場合はカンマ区切りで) 追加し、上記イベントパターンの “detail” セクションを置き換えます。
"resources": [
"arn:aws:ecs:us-west-2:0123456789:service/main-cluster/ecs-anamoly-detector"
]Step 5: ERROR および WARN タイプの ECS サービスイベントを検出し、Amazon SNS を使用して通知を送信するための Amazon EventBridge ルールを作成する
通知の数を減らすために専用の EventBridge ルールを新規で作成します。ERROR および WARN タイプの「サービスアクション」 イベントのみをフィルタリングし、検出された場合に SNS トピックを使用してアラートを送信します。
以下のコマンドを実行して、ERROR および WARN タイプの「サービスアクション」イベントを特別にフィルタリングするための新しい EventBridge ルールを作成ます。イベントが検出された場合にカスタマイズされたアラートを送信します。
cat <<EOF > /tmp/SVCActionErrorEventRulePattern.json
{
"source": [
"aws.ecs"
],
"detail-type": [
"ECS Service Action"
],
"detail": {
"eventType": ["ERROR", "WARN"],
"clusterArn": [
"arn:aws:ecs:$REGION:$ACCOUNTID:cluster/$ECS_CLUSTER_NAME"
]
}
}
EOF
aws events put-rule --name "ECS_AD_ServiceAction_ERROR" --event-pattern file:///tmp/SVCActionErrorEventRulePattern.json --region $REGION
cat <<EOF > /tmp/targets.json
[
{
"Id": "SNST",
"Arn": "$TOPIC_ARN",
"InputTransformer": {
"InputPathsMap": {
"ClusterARN": "$.detail.clusterArn",
"DetailType": "$.detail-type",
"EventName": "$.detail.eventName",
"Region": "$.region",
"Service": "$.resources",
"Severity": "$.detail.eventType",
"Time": "$.time"
},
"InputTemplate": "\"ECS Service <Service> from Cluster <ClusterARN> emitted an <DetailType> event of severity level <Severity> at <Time>At <Time>.\"\n\n\"Event Details:\"\n\"Time: <Time>\"\n\"Cluster ARN: <ClusterARN>\"\n\"Region: <Region>\"\n\"DetailType: <DetailType>\"\n\"EventName: <EventName>\"\n\"Severity: <Severity>\"\n\"Service: <Service>\""
}
}
]
EOF
aws events put-targets --rule "ECS_AD_ServiceAction_ERROR" --targets file:///tmp/targets.json --region $REGION --region $REGIONStep 6: ECS タスクの障害を検出し、Amazon SNS を使用して通知を送信するための Amazon EventBridge ルールを作成する
タスクの予期せぬ状態変化は ECS クラスター内の何らかの問題を示している可能性があり、予期せぬエラーコードでタスクが停止または終了した場合はアクションを取る必要があるかもしれません。後続の手順で作成する EventBridge ルールは、ECS クラスター内でタスクの状態が下記のいずれかの理由で STOPPED に変更された場合に通知を送信します。
- ALB のヘルスチェックでタスクが失敗
- essential パラメータが true のコンテナが終了またはクラッシュしたためタスクが失敗
- タスクがコンテナレベルのヘルスチェックに失敗
以下のコマンドを実行して EventBridge ルールを作成し、カスタマイズされたメッセージでアラートを送信する対象として SNS トピックを追加します。
cat <<EOF > /tmp/TasksStoppedEventRulePattern.json
{
"source": [
"aws.ecs"
],
"detail-type": [
"ECS Task State Change"
],
"detail": {
"desiredStatus": [
"STOPPED"
],
"stoppedReason": [
{
"prefix": "Task failed ELB health checks"
},
"Essential container in task exited",
"Task failed container health checks"
],
"clusterArn": [
"arn:aws:ecs:$REGION:$ACCOUNTID:cluster/$ECS_CLUSTER_NAME"
]
}
}
EOF
aws events put-rule --name "ECS_AD_StoppedTask_Detector" --event-pattern file:///tmp/TasksStoppedEventRulePattern.json --region $REGION
cat <<EOF > /tmp/targets.json
[
{
"Id": "SNST",
"Arn": "$TOPIC_ARN",
"InputTransformer": {
"InputPathsMap": {
"ClusterARN": "$.detail.clusterArn",
"Code": "$.detail.stopCode",
"DesiredStatus": "$.detail.desiredStatus",
"Region": "$.region",
"TaskARN": "$.detail.taskArn",
"TaskDefinitionARN": "$.detail.taskDefinitionArn",
"TaskStoppedReason": "$.detail.stoppedReason",
"Time": "$.time"
},
"InputTemplate": "\"At <Time> the ECS Task <TaskARN> running in ECS Cluster <ClusterARN> <DesiredStatus> with reason <TaskStoppedReason> in <Region> region.\"\n\n\"Task Details:\"\n\"Time: <Time>\"\n\"Task ARN: <TaskARN>\"\n\"Task Definition ARN: <TaskDefinitionARN>\"\n\"Cluster ARN: <ClusterARN>\"\n\"Task Desired Status: <DesiredStatus>\"\n\"Status Code: <Code>\"\n\"Task Stopped Reason: <TaskStoppedReason>\"\n\"Region: <Region>\""
}
}
]
EOF
aws events put-targets --rule "ECS_AD_StoppedTask_Detector" --targets file:///tmp/targets.json --region $REGIONStep 7: ECS のデプロイイベントを Amazon CloudWatch Logsに記録し、Amazon SNS を使用して通知を送信するための Amazon EventBridge ルールを作成する
また、Amazon ECS は「サービスデプロイ状態変更イベント」を INFO と ERROR の重要度で EventBridge に送信します。EventBridge のルールを使用してイベントを検出し、CloudWatch Logs にすべてのログを記録します。
次のコマンドを使用して EventBridge ルールを作成し、ECS クラスター内のすべてのサービスの「サービスデプロイ状態変更イベント」を監視して CloudWatch ロググループにその内容を記録します。
ここで重要なのは「サービスデプロイ状態変更イベント」には ECS クラスターの ARN フィールドが定義されていないため、これらのイベントは ECS サービスの ARN を使用してのみ検出されるという点です。多くの環境では ECS サービスの実行期間が長くない可能性があるため、新しいサービスが ECS クラスターに追加または削除されるたびにこのルールのイベントパターンを変更する必要があるという新たな課題が生じます。ECS サービスが ECS クラスターに追加または削除されたときに、以下のコマンドを実行してルールを更新することもできます。
Services_List=$(aws ecs list-services --cluster $ECS_CLUSTER_NAME --output text --query 'serviceArns[*]' --region $REGION | tr -s '[:blank:]' ',' | sed -e 's/.*/"&"/g' -e 's/,/","/g')
cat <<EOF > /tmp/ECSAnomalyDetector-DeploymentStateChange-Event.json
{
"source": [
"aws.ecs"
],
"resources": [ $Services_List ],
"detail-type": [
"ECS Deployment State Change"
]
}
EOF
aws events put-rule --name "ECS_AD_DeploymentStateChange_Event" --event-pattern file:///tmp/ECSAnomalyDetector-DeploymentStateChange-Event.json --region $REGION
aws events put-targets --rule "ECS_AD_DeploymentStateChange_Event" --targets "Id"="MyId","Arn"="arn:aws:logs:$REGION:$ACCOUNTID:log-group:/aws/events/$CW_LG_NAME" --region $REGION
cat <<EOF > /tmp/targets.json
[
{
"Id": "SNSDEPLOYT",
"Arn": "$TOPIC_ARN",
"InputTransformer": {
"InputPathsMap": {
"Region": "$.region",
"Time": "$.time",
"Service": "$.resources",
"Event": "$.detail.eventName",
"DeploymentID": "$.detail.deploymentId",
"State": "$.detail.reason"
},
"InputTemplate": "\"Deployment state for ECS Service <Service> is <State> at <Time> in Region <Region>.\"\n\n\"Service Deployment Detail:\"\n\"Time: <Time>\"\n\"Region: <Region>\"\n\"Service: <Service>\"\n\"Event: <Event>\"\n\"Deployment State: <State>\"\n\"Deployment ID: <DeploymentID>\""
}
}
]
EOF
aws events put-targets --rule "ECS_AD_DeploymentStateChange_Event" --targets file:///tmp/targets.json --region $REGIONAWS CloudTrail の ECS のスケーリングアクティビティを監視し、特定のしきい値に達したときに Amazon SNS を使用して通知を送信
Step 8: CloudTrail の “UpdateService” API コールのイベントを検出し、CloudWatch Logs に記録する Amazon EventBridge ルールを作成する
ECS サービスのスケーリングアクティビティを認識し異常を検出するために、 CloudTrail の “UpdateService” API コールのイベントは EventBridge ルールを使用して監視・分析します。EventBridge ルールを設定し、UpdateService API コールのイベントを CloudWatch Logs に記録するには、次のコマンドを使用します。
cat <<EOF > /tmp/ECSAnomalyDetector-UpdateService-CloudTrailEvent.json
{
"source": [
"aws.ecs"
],
"detail-type": [
"AWS API Call via CloudTrail"
],
"detail": {
"eventSource": [
"ecs.amazonaws.com"
],
"eventName": [
"UpdateService"
],
"requestParameters": {
"cluster": [
"$ECS_CLUSTER_NAME"
]
}
}
}
EOF
aws events put-rule --name "ECS_AD_UpdateService_CTEvent" --event-pattern file:///tmp/ECSAnomalyDetector-UpdateService-CloudTrailEvent.json --region $REGION
aws events put-targets --rule "ECS_AD_UpdateService_CTEvent" --targets "Id"="MyCTId","Arn"="arn:aws:logs:$REGION:$ACCOUNTID:log-group:/aws/events/$CW_LG_NAME" --region $REGIONECS 上でマルチテナント SaaS のアプリケーションを実行し、何百もの ECS サービスを備えた ECS クラスターや異なる社内チームで共有されている ECS クラスターを管理している場合、コンピュートリソースの使用量やコストが予想外に増加したサービスを見つけたり、その原因を突き止めるのは困難な作業です。原因を突き止めるためには、スケーリングアクティビティ、特に ECS サービスごとの実行数と必要数を分析する必要があります。
ECS のサービススケジューラが ECS サービスまたはタスクセットの必要数を更新すると「サービスアクションイベント」の SERVICE_DESIRED_COUNT_UPDATED が INFO カテゴリで発行されます。このイベントにはサービスの実行中のタスク数とタスクの必要数に関する情報が含まれています。これらの数値は通常、ECS サービスのスケーリングアクティビティを所定のタイムラインに取り組むために使用できます。しかしユーザーがタスクの必要数を手動で更新した場合、このイベントは送信されません。ほとんどの場合、ECS サービスのタスクの必要数は ASG Scaling ポリシーによって更新されますが、これは ECS による手動更新とも考えられるためイベントはトリガーされません。したがって、タスクの必要数の変更を追跡するためには ‘SERVICE_DESIRED_COUNT_UPDATED’ イベントではなく、AWS CloudTrail から Amazon EventBridge に送信される “UpdateService” API コールイベントを使用します。
さらにStep 8 で説明したように、スケーリングイベントごとに変化の大きさを計算する Lambda 関数を使用して、変化の大きさが事前に定義された閾値を超えた場合に SNS 通知をトリガーすることもできます。
Step 9 (オプション): ECS サービスのキャパシティの変化が (設定可能な) 定義済みの閾値以上になったときにアラートを出す Lambda 関数を設定する
AWS CloudTrail のすべての UpdateService イベントには、サービスの実行中のタスク数とタスクの必要数の情報があります。この情報を使って ECS サービスのタスクの変化の大きさを見つけ、いつアラートを送るかを検討します
- 実行中のタスク数が 3〜6 の場合、タスクの増加率が 100% 以上、または減少率が 50% 以下
- 実行中のタスク数が 6 以上の場合、タスクの増加率が 50% 以上、または減少率が 30% 以下
- 実行中のタスク数が 3 未満の場合は ECS サービスのタスク変更の大きさは評価しない
キャパシティの変化を計算するために、Lambda 関数では以下の式を使用します。
注:上記のしきい値は説明のためのものです。以下の Lambda コードの設定は必要に応じて自由に変更してください。
以下のコマンドを使用して Lambda 関数と IAM ロールを作成し、AWS CloudTrail 経由で ECS のスケーリングアクティビティを記録するために上記で作成した EventBridge ルールにターゲットとして追加します。
Lambda_RoleArn=$(aws iam create-role --role-name ECS_AD_Lambda_Role --assume-role-policy-document '{"Version": "2012-10-17","Statement": [{ "Effect": "Allow", "Principal": {"Service": "lambda.amazonaws.com"}, "Action": "sts:AssumeRole"}]}' --output text --region $REGION --query 'Role.Arn')
cat <<EOF > /tmp/LambdaRolePolicy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"SNS:Publish"
],
"Resource": "*"
}
]
}
EOF
aws iam put-role-policy --role-name ECS_AD_Lambda_Role --policy-name ECS_AD_Lambda_Role_Policy --policy-document file:///tmp/LambdaRolePolicy.json --region $REGION
cat <<EOF > /tmp/lambda_function.py
import json
import boto3
import os
def Send_Notification(CapacityChange, ServiceName, ClusterName, runningCount, desiredCount):
snsClient = boto3.client('sns')
sns_topic_arn = os.environ['SNS_TOPIC_ARN']
if CapacityChange > 0:
text = 'increased'
if CapacityChange < 0:
text = 'decreased'
SNSMessage = 'Task Count for ECS Service {} in Cluster {} {} by {}%.\n\nRunning task count before UpdateService API: {}\n\nDesired Task Count Set by UpdateService API: {}\n'.format(ServiceName, ClusterName, text, abs(CapacityChange), runningCount, desiredCount)
print('SNSMessage: {}'.format(SNSMessage))
Resp = snsClient.publish(
TargetArn=sns_topic_arn,
Message=SNSMessage
)
print('Resp: {}'.format(Resp))
def lambda_handler(event, context):
Running_Count_Threshold = 3
if event['detail']['eventName'] == 'UpdateService':
try:
if event['detail']['errorCode']:
print("This event contains ErrorCode: {}. CloudTrail requestID: {}. Skipping script execution.".format(event['detail']['errorCode'], event['detail']['requestID']))
except KeyError:
runningCount = event['detail']['responseElements']['service']['runningCount']
desiredCount = event['detail']['responseElements']['service']['desiredCount']
if runningCount >= Running_Count_Threshold:
Change_in_Task_Count = desiredCount - runningCount
CapacityChange = (Change_in_Task_Count / runningCount) * 100
ServiceName = event['detail']['responseElements']['service']['serviceName']
ClusterName = event['detail']['requestParameters']['cluster']
print("Change_in_Task_Count: {}, CapacityChange: {}, ServiceName: {}, ClusterName: {}".format(Change_in_Task_Count, CapacityChange, ServiceName, ClusterName))
if runningCount >= 3 and runningCount <= 6:
if CapacityChange >= 100 or CapacityChange <= -50:
Send_Notification(CapacityChange, ServiceName, ClusterName, runningCount, desiredCount)
if runningCount > 6:
if CapacityChange >= 50 or CapacityChange <= -30:
Send_Notification(CapacityChange, ServiceName, ClusterName, runningCount, desiredCount)
else:
print("This is not UpdateService event, it is {} instead. Skipping function execution.".format(event['eventName']))
EOF
cd /tmp && zip ECS_AD_Lambda_Code.zip lambda_function.py
lambdaArn=$(aws lambda create-function --function-name ECS_AD_Lambda_Function --zip-file fileb:///tmp/ECS_AD_Lambda_Code.zip --handler lambda_function.lambda_handler --runtime python3.7 --role $Lambda_RoleArn --timeout 900 --region $REGION --environment "Variables={SNS_TOPIC_ARN=$TOPIC_ARN}" --output text --query 'FunctionArn')
aws events put-targets --rule "ECS_AD_UpdateService_CTEvent" --targets "Id"="MyLambdaId","Arn"="$lambdaArn" --region $REGION
aws lambda add-permission --statement-id "InvokeLambdaFunction" --action "lambda:InvokeFunction" --principal "events.amazonaws.com" --function-name "$lambdaArn" --source-arn "arn:aws:events:$REGION:$ACCOUNTID:rule/ECS_AD_UpdateService_CTEvent" --region $REGION検証
前のセクションのコマンドを実行した後、AWS マネジメントコンソール上で Amazon EventBridge ルールを確認し、“ECS_AD_” という文字列でルールをフィルタリングします。フィルタリングを行うと以下のような 5 つの異なる Amazon EventBridge ルールがリストアップされるはずです。

Amazon EventBridge ルールが ECS イベントを検出し、CloudWatch Logs に記録しているかどうかを確認するには、AWS マネジメントコンソールで Amazon CloudWatch を確認します。数分後または ECS クラスターでいくつかの関連イベントが生成されるとすぐに、以下の図のようなログストリームが入力されるはずです。
イベント分析と異常検知
Anomaly Detector の設定が完了した後、このセクションでは ECS サービスで生成されたイベントを CloudWatch Logs Insights を使って 3 つのカテゴリで分析します。
1. 容量の変化 – スケーリングアクティビティ: このカテゴリでは、Logs Insights クエリを使用してすべてのスケーリングアクティビティを分析し、オンデマンドのレポートを生成することでコンテナのキャパシティの大きな変化を見つけることができます。
CloudWatch Logs Insights のクエリ:
filter `detail-type`="AWS API Call via CloudTrail" and detail.eventName ="UpdateService" and !ispresent(detail.errorCode)
| fields @timestamp as Time, detail.responseElements.service.serviceName as ServiceName,
detail.responseElements.service.runningCount as RunningCount,
detail.responseElements.service.desiredCount as DesiredCount,
(detail.responseElements.service.desiredCount-detail.responseElements.service.runningCount) as Change_in_Task_Count,
floor(((detail.responseElements.service.desiredCount-detail.responseElements.service.runningCount)/detail.responseElements.service.runningCount)*100) as `CapacityChange (%)`,
abs(`CapacityChange (%)`) as `Absolute_Change (%)`
| sort `Absolute_Change (%)` desc, @timestamp desc
| limit 20CloudWatch Logs Insightsのクエリ出力:

2. Amazon ECS サービスのイベント分析: このカテゴリでは “SERVICE_TASK_PLACEMENT_FAILURE ” のようなすべてのサービスイベントとイベントの理由/トリガーを、オンデマンドでレポート生成することで分析することができます。さらに、ELB ヘルスチェックの失敗など ECS タスクの失敗とその原因に関する詳細な情報をここで確認することもできます。
ECS のサービス障害を分析するための CloudWatch Logs Insights クエリ:
filter `detail-type`="ECS Service Action"
|fields @timestamp, `detail-type` as Type, detail.eventName as Event,detail.reason as Reason , resources.0 as ServiceName
| sort @timestamp desc
| limit 200CloudWatch Logs Insightsのクエリ出力:

ECS タスクの障害を分析するための CloudWatch Logs Insights クエリ:
filter `detail-type`="ECS Task State Change" and detail.desiredStatus="STOPPED"
|fields detail.stoppingAt as stoppingAt ,detail.stoppedReason as stoppedReason,detail.taskArn as Task
| sort @timestamp desc
| limit 200CloudWatch Logs Insightsのクエリ出力:

3. タスクレベルでのリソース使用状況の分析: このカテゴリでは、ECS サービスごとのタスクレベルで予約された CPU とメモリ、および各タスクの開始時間と終了時間を分析し、これらの使用状況に関するレポートをオンデマンドで作成することができます。このようなレポートを使用することで、サービスのチャージバックやタスクレベルでのコスト分析が容易になります。
タスクレベルのリソース使用量を照会する CloudWatch Logs Insights クエリ:
filter `detail-type`="ECS Task State Change" and detail.desiredStatus="STOPPED"
|fields detail.startedAt as startedAt ,detail.stoppingAt as stoppingAt ,detail.cpu as CPU,detail.memory as Memory, detail.taskArn as Task
| sort @timestamp desc
| limit 200CloudWatch Logs Insights のクエリ出力:

まとめ
Amazon ECS によって送信される Amazon EventBridge イベントは、ECS クラスターの効率的な管理のための可視性を提供し、大規模な ECS クラスターにとって特に有益な優れた運用を実現できます。ECS Anomaly Detection のメカニズムを有効にして使用する際には、ECS クラスター内のサイズとイベント数に基づいて CloudWatch Logs の料金を考慮することが重要です。この料金には 保存 (アーカイブ) だけでなく収集 (データの取り込み) の料金も含まれます。Amazon CloudWatch の料金についての詳細は Amazon CloudWatch の料金ページを参照してください。また、CloudWatch Logs でのログデータ保管期間の変更を行うことで、異常検知を継続して利用し ECS クラスターの可観測性を向上させながら関連コストを大幅に削減することも可能です。
この記事では 1 つの ECS クラスターと、そのクラスター上で動作するすべてのサービスのセットアップに焦点を当てました。言い換えると、ECS クラスターごとに ECS Anomaly Detection を有効する必要があります。これは以下の手順を踏むことで、同じリージョンの複数のクラスターに簡単に拡張することができます。
- 以下の EventBridge ルールが複数の ECS クラスターからのイベントを検出するようにするには、イベントパターンに ECS クラスターの ARN をカンマ区切りのリストとして追加し、“aws events put-rule” コマンドを使用して EventBridge ルールを更新します。
- ECS_AD_ServiceActivity
- ECS_AD_ServiceAction_ERROR
- ECS_AD_StoppedTask_Detector
- EventBridge ルール “ECS_AD_UpdateService_CTEvent” が複数の ECS クラスターからのイベントを検出するようにするには、イベントパターンにカンマ区切りのリストとして ECS クラスター名を追加し、“aws events put-rule” コマンドを使用して EventBridge ルールを更新します。
- EventBridge ルール “ECS_AD_DeploymentStateChange_Event ” が複数の ECS クラスターからのイベントを検出するようにするには、イベントパターンの “resources” セクションにすべてのサービスの ECS サービスの ARN をカンマ区切りのリストとして追加し、”aws events put-rule” コマンドを使用して EventBridge ルールを更新します。
Amazon EventBridgeの 詳細については EventBridge のユーザーガイドを参照してください。EventBridge に発行される ECS イベントの詳細については Amazon ECS イベントを参照してください。
翻訳はソリューションアーキテクト加治が担当しました。原文はこちらです。