Amazon Web Services ブログ
Amazon Textract および Amazon Comprehend を使用した NLP 対応検索インデックスの構築
すべての業界の組織には、多数の物理的なドキュメントがあります。テーブル、フォーム、パラグラフ、チェックボックスなどの形式が含まれているとき、スキャンしたドキュメントからテキストを抽出することは困難な場合があります。組織は、光学式文字認識 (OCR) 技術を使用してこれらの問題に対応してきましたが、フォーム抽出およびカスタムワークフローにはテンプレートが必要です。
画像または PDF からテキストを抽出して分析することは、従来型の機械学習 (ML) および自然言語処理 (NLP) の問題です。文書からコンテンツを抽出するとき、全体的なコンテキストを維持し、情報を読み取り可能および検索可能な形式で保存することが必要になります。高度なアルゴリズムを作成するには、大量のトレーニングデータとコンピューティングリソースが必要です。完全な機械学習モデルを構築し、トレーニングするには、費用と時間がかかる場合があります。
このブログ投稿では、スキャンされた画像ドキュメントを保存および分析するための自動コンテンツ処理パイプラインとして、Amazon Textract および Amazon Comprehend で NLP 対応の検索インデックスを作成する方法を説明します。PDF ドキュメントの処理については、AWS サンプル github リポジトリを参照して Textractor を使用してください。
このソリューションでは、サーバーレステクノロジーとマネージドサービスを使用して、スケーラブルで費用対効果を高めています。このソリューションで使用されるサービスは次のとおりです。
- Amazon Textract – スキャンしたドキュメントからテキストとデータを自動的に抽出します。
- Amazon Comprehend – ML を使用して、テキストのインサイトと関係を見つけます。
- Amazon ES with Kibana – 情報を検索して視覚化します。
- Amazon Cognito – Amazon ES と統合し、Kibana へのユーザーアクセスを認証します。詳細については、Amazon Elasticsearch Service を使い始める: Kibanaのアクセス制御にAmazon Cognitoを使用する を参照してください。
- Amazon S3 – 文書を保存し、微調整されたアクセス制御による一元管理を可能にします。
- AWS Lambda –データの変更、システム状態の変化、ユーザーアクションなどのトリガーに応答してコードを実行します。S3はLambda 関数を直接トリガーできるため、さまざまなリアルタイムのサーバーレスデータ処理システムを構築できます。
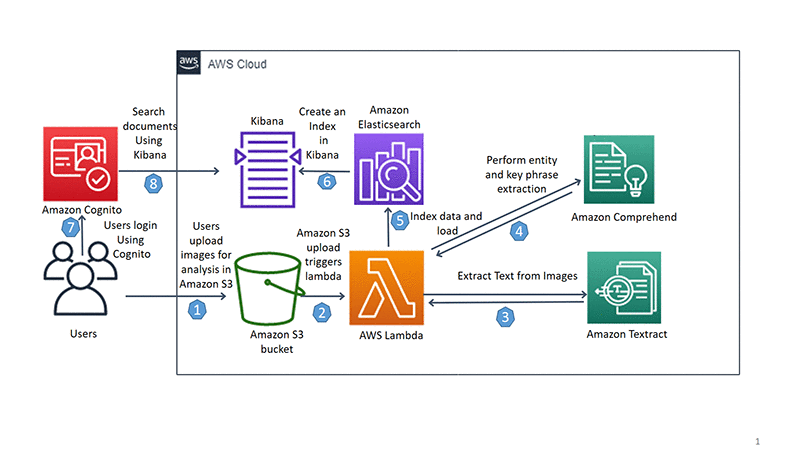
アーキテクチャ
- ユーザーは、分析のために OCR イメージを Amazon S3 にアップロードします。
- Amazon S3 アップロードは AWS Lambda をトリガーします。
- AWS Lambda は Amazon Textract を呼び出して画像からテキストを抽出します。
- AWS Lambda は、エンティティおよびキーフレーズ抽出のために、画像から抽出したテキストを Amazon Comprehend に送信します。
- このデータにはインデックスが付けられ、Amazon Elasticsearch にロードされます。
- Kibana はインデックス付きデータを取得します。
- ユーザーは Amazon Cognito にログインします。
- Amazon Cognito は Kibana に対して認証を行い、ドキュメントを検索します。
AWS CloudFormation を使用したアーキテクチャのデプロイ
最初のステップは、AWS CloudFormation テンプレートを使用して必要な IAM ロールと AWS Lambda 関数をプロビジョニングし、Amazon S3、AWS Lambda、Amazon Textract、および Amazon Comprehend API とやり取りすることです。
- US-East-1 (バージニア北部) リージョンで AWS CloudFormation テンプレートをローンチします。

- [Create stack] 画面に以下の情報が表示されます。
スタック名: ドキュメント検索
CognitoAdminEmail: abc@amazon.com
DOMAINNAME: documentsearchapp。メールアドレスで CognitoAdminEmail を編集します。一時的な Kibana 資格情報をメールで受け取ります。

- [Capabilities] まで下方にスクロールし、両方のボックスをオンにして、AWS CloudFormation が IAM リソースを作成することを確認します。詳細については、AWS IAM リソースを参照してください。

- [Transforms] まで下方にスクロールし、Create Change Set を選択します。
 AWS CloudFormation テンプレートは AWS SAM を使用し、とサーバーレスアプリケーション用の関数と API の定義方法のみならず、環境変数などのこれらのサービスの機能を簡素化します。AWS SAM テンプレートを AWS CloudFormation テンプレートにデプロイする場合、変換ステップを実行して AWS SAM テンプレートを変換する必要があります。
AWS CloudFormation テンプレートは AWS SAM を使用し、とサーバーレスアプリケーション用の関数と API の定義方法のみならず、環境変数などのこれらのサービスの機能を簡素化します。AWS SAM テンプレートを AWS CloudFormation テンプレートにデプロイする場合、変換ステップを実行して AWS SAM テンプレートを変換する必要があります。 - 変更セットがコンピューティングの変更を完了するまで数秒待ちます。画面は、アクション、論理 ID、物理 ID、リソースタイプ、および交換で次のようになります。最後に、[Execute] ボタンをクリックして、AWS CloudFormation がバックグラウンドでリソースを開始できるようにします。

- 次の [Stack Detail] ページのスクリーンショットは、CloudFormation スタックのステータスを [
CREATE_IN_PROGRESS] として示しています。ステータスが [CREATE_COMPLETE] に変わるまで最大 20 分待ちます。Outputs で、S3KeyPhraseBucket および KibanaLoginURL の値をコピーします。
S3 バケットへのドキュメントのアップロード
上記の手順で新しく作成した S3 バケットにドキュメントをアップロードするには、次の手順を実行します。
- CloudFormation 出力からコピーした Amazon S3 バケット URL をクリックします。
- サンプルデータセット
demo-data.zipを GitHub リポジトリ からダウンロードします。このデータセットには、フォーム、パラグラフのあるスキャンされたページ、2 列のドキュメントなど、さまざまな画像が含まれています。 - データを解凍します。
- Demo-data フォルダー内のファイルを、
document-search-blog-s3-<Random string> で始まる Amazon S3 バケットにアップロードします。
詳細については、S3 バケットにファイルとフォルダーをアップロードするにはどうすればよいですか? を参照してください。
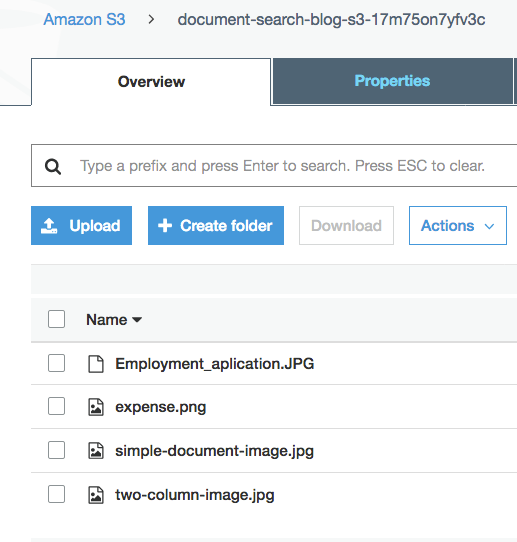
アップロードが完了すると、次の 4 つの画像ファイルが表示されます。S3 バケット内の Employment_application.JPG、expense.png、simple-document-image.jpg、および two-column-image.jpg です。
データを S3 にアップロードすると、Lambda S3 イベント通知がトリガーされ、Lambda 関数が呼び出されます。Amazon S3 バケットのプロパティで設定されたイベントトリガーは、[Advanced settings] -> [Events] にあります。document-search-blog-ComprehendKeyPhraseAnalysis-<Random string> で始まる Lambda 関数が表示されます。この Lambda 関数は以下のステップを実行します。
- Amazon Textract を使用して画像からテキストを抽出します。
- Amazon Comprehend を使用してキーフレーズ抽出を実行します。
- Amazon ES を使用してテキストを検索します。
次のコード例は、Amazon Textract を使用して画像からテキストを抽出します。
次のコード例は、Amazon Comprehend を使用してキーフレーズを抽出します。
Amazon Textract および Amazon Comprehend から受信した応答にインデックスを付け、Amazon ES にロードして、NLP 対応検索インデックスを作成できます。以下のコードを参照してください。
詳細については、GitHub リポジトリ を参照してください。
Kibana を使用したドキュメントの視覚化と検索
Kibana を使用してドキュメントを視覚化および検索するには、次の手順を実行します。
- 件名が「Your temporary password」である受信トレイでメールを見つけます。 受信トレイにメールが表示されない場合は、ジャンクフォルダーを確認してください。

- AWS CloudFormation の出力からコピーされた Kibana ログイン URL に移動します。
- メールアドレスをユーザー名として、確認メールの仮パスワードを Password として使用してログインします。 [Sign In] をクリックします。

注: AWS CloudFormation のデプロイ中にメールを受信しなかったか、見逃した場合は、[Sign up] を選択します。 - 次のページで、新しいパスワードを入力します。
- Kibana のランディングページで、メニューから [Discover] を選択します。
- [Management/Kibana] ページに、ステップ1/2; インデックスパターンを定義するが表示され、[Index pattern] には、
document*と入力します。「成功しました! インデックスパターンは 1 つのインデックスと一致します。」というメッセージが表示されます。[Next step] を選択します。[Create Index Pattern] をクリックします
 数秒後、ドキュメントインデックスページが表示されます。
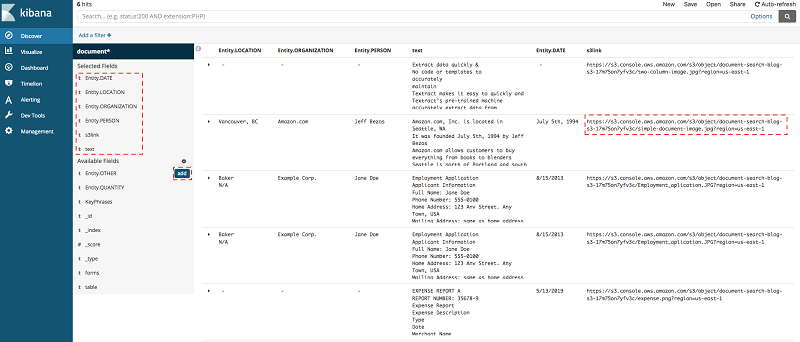
数秒後、ドキュメントインデックスページが表示されます。 - メニューから再度 [Discover] を選択します。以下のスクリーンショットでは、ドキュメントの属性を確認できます。

- 各エントリの特定のフィールドを表示するには、左側のサイドバーのフィールドにカーソルを合わせて、[Add] をクリックします。
これにより、フィールドが [Selected Fields] メニューに移動します。Kibana ダッシュボードは、読みやすい形式でデータを作成します。次のスクリーンショットは、[Selected Fields] メニューに Entity.DATE、Entity.Location、Entity.PERSON、S3link およびテキストを追加した後のビューを示しています。
元のドキュメントを表示するには、s3link を選択します。
注: フォームとテーブルを追加して、テーブルとフォームを表示および検索することもできます。
結論
この投稿では、画像ドキュメントからデータを抽出して処理し、視覚化して実用的なインサイトを作成する方法を示しました。
スキャンした画像ドキュメントを処理すると、大量のデータを発見でき、新しいビジネスの可能性が広がります。Amazon Textract や Amazon Comprehend などのマネージド ML サービスを使用すると、これまでに発見されていないデータに関するインサイトを得ることができます。たとえば、カスタムアプリケーションを作成して、スキャンした法的文書、購入領収書、注文書からテキストを取得できます。
大規模なデータは、あらゆる業界に関連しています。画像または PDF のデータを処理する場合、AWS はデータの取り込みと分析を簡素化しながら、全体的な IT コストを管理可能にします。
このブログ記事が問題解決の助けやヒントとなるなら、ぜひご意見をお聞かせください。 このソリューションのコードは、使用および拡張するために GitHub リポジトリ で入手できます。皆さんの貢献を歓迎いたします!
著者について
 Saurabh Shrivastava は、世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクトおよびビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。彼は家族とアウトドアで過ごしたり、新しい場所に旅して未知の文化を発見したりすることを楽しんでいます。
Saurabh Shrivastava は、世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクトおよびビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。彼は家族とアウトドアで過ごしたり、新しい場所に旅して未知の文化を発見したりすることを楽しんでいます。
 Mona は、AWS Public Sector Team と協力する AI/ML スペシャリストソリューションアーキテクトです。彼女は、AWS のお客様と協力して、大規模な Machine Learning の採用を支援しています。彼女は自由な時間に絵と料理を楽しんでいます。
Mona は、AWS Public Sector Team と協力する AI/ML スペシャリストソリューションアーキテクトです。彼女は、AWS のお客様と協力して、大規模な Machine Learning の採用を支援しています。彼女は自由な時間に絵と料理を楽しんでいます。