Amazon Web Services ブログ
Category: Amazon Aurora

Aurora DSQL での Auto Analyze:マルチリージョンデータベースにおけるマネージドオプティマイザー統計
本記事は 2026/02/04に投稿された Auto Analyze in Aurora DSQL: Mana […]
【寄稿】CO2 排出量可視・削減サービス「e-dash」を支えるサーバーレスアーキテクチャと IaC 戦略
こんにちは、AWS ソリューションアーキテクトの松本 敢大です。 本日は、三井物産発の環境系スタートアップである e-dash 株式会社様が提供する CO2 排出量可視化・削減サービスプラットフォーム「e-dash」のシステム構築事例をご紹介します。e-dash 株式会社 プロダクト開発部部長の佐藤様、プロダクト開発部の伊藤様、竹内様に、AWS を活用したモダンなアプリケーション開発の取り組みについてお話を伺いました。

Amazon Aurora PostgreSQL の共有プランキャッシュの使用
Aurora PostgreSQL の共有プランキャッシュ機能により、高並行性環境で汎用 SQL プランのメモリ消費を大幅に削減できます。プラン重複を解消することで、40GB のメモリ負荷を 400MB まで削減し、より小さなインスタンスでより多くの接続を実行できます。

【開催報告】第9回鉄道技術展2025 AWS出展報告
2025年11月26日から29日の4日間、千葉県の幕張メッセにて「第9回鉄道技術展2025(Mass-Tran […]

Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL のバージョン 13 からのアップグレード戦略
本記事は 2026 年 1 月 27 日 に公開された「Strategies for upgrading Am […]
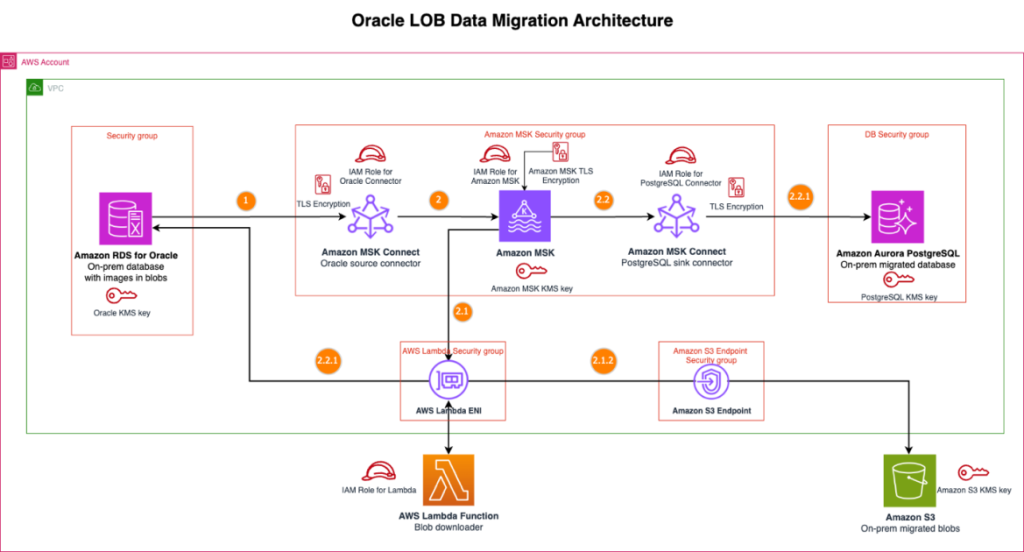
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。
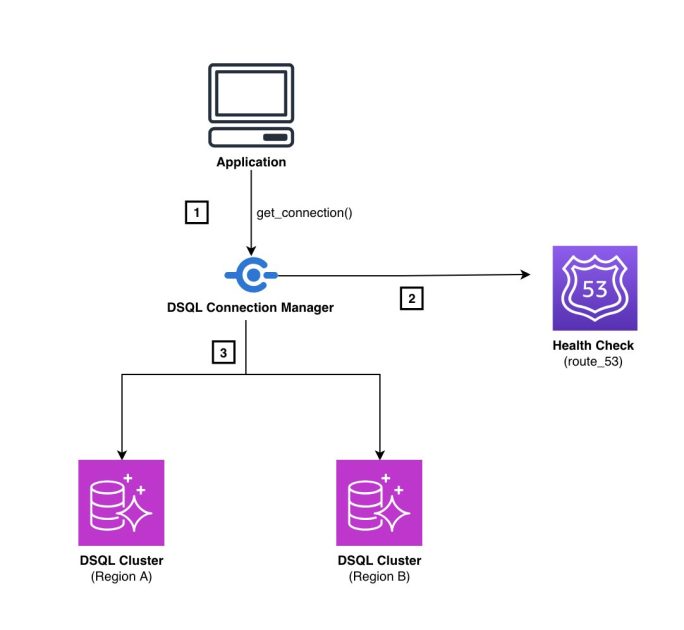
Amazon Aurora DSQL のマルチリージョンエンドポイントルーティングを実装する
Amazon Aurora DSQL のマルチリージョンクラスターにおいて、Route 53 ヘルスチェックとクライアント側レイテンシー測定を組み合わせた自動エンドポイントルーティングソリューションを実装する方法を紹介します。リージョナルエンドポイント障害時に自動的に正常なエンドポイントへフェイルオーバーし、アプリケーションの継続的なデータベースアクセスを実現します。

標準 JDBC ドライバーで AWS Advanced JDBC Wrapper を使い Amazon Aurora の高度な機能を活用する
本記事では、AWS Advanced JDBC Wrapper を使って標準 JDBC ドライバーに Amazon Aurora の高速フェイルオーバーや読み取り/書き込み分離などのクラウド機能を追加する方法を紹介します。最小限のコード変更で、既存の Java アプリケーションを段階的に拡張する手順を解説します。
smart EuropeがAmazon Bedrockでカスタマーサポート業務を変革した方法
自動車メーカーにとって、新型車のリリース、無線通信(OTA)によるソフトウェアアップデート、コネクテッドサービスの開始は、新鮮な顧客体験を生み出します。これらのイノベーションは運転体験の向上に役立つ一方で、自動車所有者から車両の機能、充電機能、メンテナンス手順、デジタルサービスに関する多数の問い合わせを生み出します。
AWSはsmart Europeと協力し、smart.AI Case Handlerを開発しました。このツールは、問い合わせに関するインサイトとカスタマイズされた対応を提案することで、サポート担当者の効率を大幅に向上させます。
人に依存しないCRMによりEC事業者のLTV最大化を実現 Amazon Bedrock AgentCoreを活用したAIオートパイロット型CRM開発事例
株式会社ダイレクトマーケティングエージェンシー(以下、DMA)は、2006年の創業以来、ECビジネス支援エー […]