Amazon Web Services ブログ
Category: Amazon Aurora
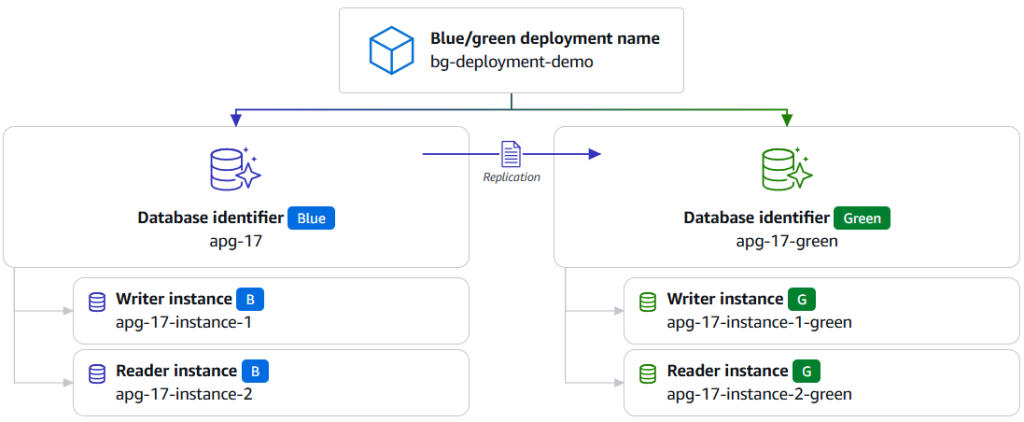
AWS JDBC Driver の Blue/Green デプロイメントプラグインでデータベースメンテナンスのダウンタイムをほぼゼロに
本記事では、AWS JDBC Driver の Blue/Green デプロイメントプラグインを紹介します。このプラグインは、Amazon RDS および Amazon Aurora の Blue/Green デプロイメント切り替え時に、接続ルーティングとトラフィック管理を自動化し、データベースメンテナンスのダウンタイムをほぼゼロにします。プラグインの設定方法とテスト結果を示し、従来の 30 秒超のダウンタイムを約 12 秒の一時停止に短縮できることを実証します。

Amazon Aurora DSQL での Change Data Capture 入門
Amazon Aurora DSQL は、パブリックプレビューで Change Data Capture (CDC) を発表しました。これにより、データベースの変更をほぼリアルタイムで Amazon Kinesis Data Streams にストリーミングできます。本記事では、Aurora DSQL CDC の仕組み、ストリーミングパイプラインの構成方法、変更イベントの消費方法を、CDC ストリームと Kinesis ストリームの作成から実際のイベント解析までの手順とともに説明します。
Amazon Aurora DSQL によるグローバル規模の金融トランザクション
Amazon Aurora DSQL を使用して、強い整合性と低レイテンシーを両立しながらグローバル規模の金融トランザクションを実行する方法を解説します。コアバンキング、グローバル経費管理、デジタル通貨インフラストラクチャの 3 つのユースケースを通じて、従来の 2 フェーズコミットや結果整合性のトレードオフを解消するアーキテクチャを紹介します。

Amazon Aurora スナップショットから Amazon Aurora DSQL へのデータ移行
Amazon Aurora DSQL はサーバーレスの分散 SQL データベースで、データ移行には COPY コマンドや dataloader スクリプトが利用できますが、テーブル単位の処理しかできず、データ変換の手段もありません。本記事では AWS Glue を使い、Aurora PostgreSQL のスナップショットから Aurora DSQL へ、データ型変換や主キーの UUID 化を含めて移行する手順を紹介します。

AWS Weekly Roundup : Anthropic と Meta のパートナーシップ、AWS Lambda S3 ファイル、Amazon Bedrock AgentCore CLI など (2026 年 4 月 27 日)
3 月下旬、世界中の AWS スペシャリストが集まる最も活気あふれるイベントの 1 つである Speciali […]

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]

Amazon Aurora DSQL 及び Database 事例イベントのお知らせ
AWS では、データと AI を活用したイノベーションの推進を支援するため、「AWS Data & A […]

Amazon Aurora PostgreSQL サーバーレスデータベースの数秒での作成の発表
re:Invent 2025 において、AWS の Vice President of Databases で […]

AWS Weekly Roundup: Amazon Bedrock の Claude Sonnet 4.6、Kiro in GovCloud リージョンの Kiro、新しいエージェントプラグインなど (2026 年 2 月 23 日)
2026 年 2 月 16 日週、私のチームは米国サンノゼで開催された Developer Week で大勢の […]

新しい Amazon Aurora クラスターに対する保管時のデフォルト暗号化の使用
Amazon Aurora では、すべての新しいデータベースクラスターに対して AWS 所有キーによる保管時の暗号化がデフォルトで有効になりました。追加コストや設定作業なしでセキュリティの強化とコンプライアンスの簡素化を実現できます。