Amazon Web Services ブログ
AWS Glueを使ったソーススキーマの変更点の特定
現在の多くの組織ではトランザクションデータストア、クリックストリーム、ログデータ、IoT データなど、あらゆる種類の異なるデータソースからこれまでにないほど多くのデータを収集しています。このデータは、構造化データや非構造化データなど、異なる形式であることが多いものです。これらはビッグデータの特徴としてよく言及される 3 つの V (ボリューム、ベロシティ、バラエティ)に含まれます。データから情報を抽出するために、それらのデータは通常、Amazon Simple Storage Service (S3)上に構築されたデータレイクに保存されます。データレイクで利用できるスキーマオンリードという機能を活用することで、データソース上のスキーマやスキーマの変更を気にすることなくデータをデータレイクに取り込むことができます。これにより、データの取り込みやデータパイプラインの構築の高速化が可能になります。
しかし、アプリケーションとの連携を考えると、Amazon QuickSight のようなサービスでのビジネスインテリジェンス (BI) ダッシュボードの構築、Amazon Athena のようなサーバーレスクエリーエンジンを使ったデータ探索など、他の使用事例のために、このデータを活用しているかもしれません。さらに、運用と分析のニーズに合わせて、リレーショナルデータベース、非リレーショナルデータベース、またはデータウェアハウスなどのデータストアにデータを投入するための抽出、変換、ロード(ETL)データパイプラインを構築している場合もあります。このような場合、アプリケーションの障害やダッシュボードやレポートの問題を避けるために、スキーマを前もって定義したり、新しいカラムの追加、既存のカラムの削除、既存のカラムのデータ型の変更、既存のカラムの名前の変更など、スキーマの変更を記録しておく必要があります。
多くのユースケースで、データパイプラインの構築を担当するデータチームはソーススキーマを制御できず、ソーススキーマの変更を特定するソリューションを構築して、それを基にプロセスや自動化を構築する必要があることが分かっています。これには、ソーススキーマに依存するチームへの変更通知の送信、スキーマの変更をすべて記録する監査ソリューションの構築、ソーススキーマの変更を ETL ツールや BI ダッシュボードなどの下流アプリケーションに伝播させるための自動化または変更要求プロセスの構築などが含まれるかもしれません。スキーマのバージョン数を制御するために、古いバージョンのスキーマと新しいスキーマの間で変更が検出されない場合に、古いバージョンのスキーマを削除したい場合があります。
たとえば、さまざまな外部パートナーからフラットファイルの形で請求ファイルを受け取り、これらのファイルに基づいて請求を処理するソリューションを構築したとします。しかし、これらのファイルは外部パートナーから送られてきたものであるため、スキーマやデータ形式をあまり制御することができません。例えば、customer_id や claim_id といったカラムが、あるパートナーによって customerid や claimid に変更されたり、別のパートナーが customer_age や earning といった新しいカラムを追加して、残りのカラムは同じにしている場合があります。このような変更を事前に確認し、カラム名の変更や新しいカラムの追加など、変更に対応したETLジョブの編集を行い、請求を処理できるようにする必要があります。
本ソリューションでは、AWS Glue のクローラーを利用して、データソースのスキーマ変更の捕捉を簡略化する仕組みを紹介します。
ソリューションの概要
このソリューションでは、AWS Glue データクローラーを構築し、既存データに基づいてメタデータを同期します。変更を特定した後、Amazon CloudWatch を使って変更を記録し、Amazon Simple Notification Service (Amazon SNS) を使ってメールにてアプリケーションチームに変更を通知します。この投稿の範囲外ですが、このソリューションを拡張して、下流のアプリケーションやパイプラインに変更を伝播させる自動化の仕組みを構築し、スキーマの変更によって下流のアプリケーションで障害が発生しないようにするなど、他のユースケースに対応することができます。また、比較したスキーマのバージョン間で変更がない場合、古いバージョンのスキーマを削除する方法も紹介します。
イベントドリブンで変更を捕捉したい場合は、Amazon EventBridge を使用することで可能になります。しかし、特定のスケジュールに基づいて、複数のテーブルのスキーマ変更を同時に捕捉したい場合は、この投稿のソリューションを適用することができます。
今回のシナリオでは、スキーマが異なる 2 つのファイルを用意し、スキーマが変更されたデータをシミュレートしています。AWS Glue のクローラーを使って、S3 バケットにあるデータからメタデータを抽出します。次に、AWS Glue の ETL ジョブでスキーマの変更を AWS Glue Data Catalog に反映します。
AWS Glue は、分析目的のために複数のソースから多数のデータセットを抽出、変換、ロードするためのサーバーレス環境を提供します。データカタログは、 AWS Glue 内の機能で、異なるデータストアからデータを保存し、アノテーションを付けることで、メタデータの一元的なデータカタログを作成することができます。データストアには、例えば、 Amazon S3 のようなオブジェクトストア、Amazon Aurora PostgreSQL-Compatible Edition のようなリレーショナルデータベース、 Amazon Redshift のようなデータウェアハウスが含まれます。そして、そのメタデータを使用して、もとになるデータに対してクエリを発行して、データを変換できます。データカタログにテーブルを追加するには、クローラーを使用します。クローラーは自動的に新しいデータを発見し、スキーマ定義を抽出し、スキーマの変更を検出し、テーブルをバージョンアップすることができます。また、 Amazon S3 上の Hive スタイルのパーティション(year=YYYY, month=MM, day=DD など)を検出することができます。
Amazon S3 は、自身のデータレイクのストレージとして機能します。 Amazon S3 は、業界をリードするスケーラビリティ、データの可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。
このソリューションのアーキテクチャを以下の図に示します。
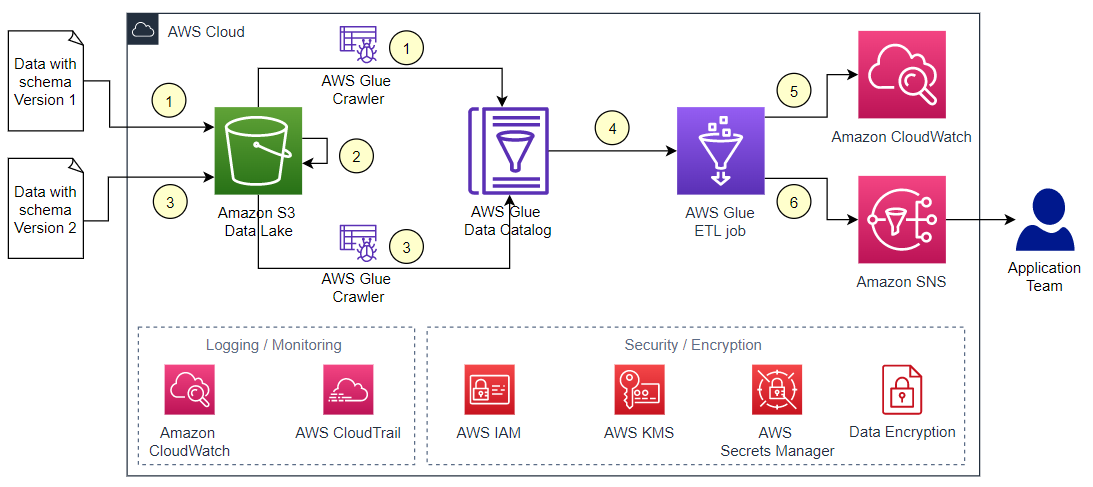
ワークフローは、以下の手順で行われます。
- 最初のデータファイルを S3 バケットの
dataフォルダにコピーし、 AWS Glue クローラーを実行してデータカタログに新しいテーブルを作成します。 - 既存のファイルを
dataフォルダからarchivedフォルダに移動します。 - スキーマが更新された 2 つ目のデータファイルを
dataフォルダにコピーし、クローラーを再実行して新しいバージョンのテーブルスキーマを作成します。 - AWS Glue ETL ジョブを実行し、新しいバージョンのテーブルスキーマがあるかどうかを確認します。
- AWS Glue ジョブは、CloudWatch Logs にスキーマの変更点を旧バージョンのスキーマと一緒にリストアップします。スキーマに変更がなく、古いバージョンを削除するフラグが true に設定されている場合、ジョブは古いバージョンのスキーマも削除します。
- AWS Glue ジョブは、スキーマのすべての変更を、Amazon SNS を使用してE メールでアプリケーションチームに通知します。
ソリューションを構築するには、次の手順を実行します。
- 新しいデータファイルと処理されたデータファイルを保存するために、
dataとarchivedフォルダを持つ S3 バケットを作成します。 - AWS Glue データベースと、
dataフォルダ内のデータファイルをクロールしてデータベース内に AWS Glue テーブルを作成する AWS Glue クローラーを作成します。 - SNS トピックを作成し、E メールのサブスクリプションを追加します。
- AWS Glue ETL ジョブを作成し、2 つのバージョンのテーブルスキーマを比較し、古いバージョンのスキーマからの変更点をリストアップし、古いバージョンのスキーマを削除するフラグが true に設定されていれば、古いバージョンのスキーマを削除します。また、このジョブはスキーマの変更をデータチームに通知するために、Amazon SNS でイベントをパブリッシュします。
この投稿では、データファイルを data フォルダから archived フォルダに移動し、クローラーと ETL ジョブをトリガーするステップを手動で実行します。アプリケーションのニーズに応じて、AWS Glue ワークフローでこのプロセスを自動化し、オーケストレーションすることができます。
AWS Glue テーブルのバージョンを直近のスキーマ変更で更新されたバージョンと比較するソリューションを体験するために必要なインフラストラクチャをセットアップしてみましょう。
S3 バケットとフォルダの作成
新しいデータファイルと処理されたデータファイルを保存するために、data と archived フォルダを持つ S3 バケットを作成するには、次の手順を実行します。
- Amazon S3 コンソールで、ナビゲーションペインからバケットを選択します。
- バケットの作成を選択します。
- バケット名に、DNS に準拠した一意の名前を入力します(例:
aws-blog-sscp-ng-202202)。 - リージョンには、バケットを配置するリージョンを選択します。
- その他の設定はデフォルトのまま、バケットを作成を選択します。
- バケットページで、新しく作成したバケットを選択します。
- フォルダの作成を選択します。
- フォルダ名には、
dataを入力します。 - サーバーサイドの暗号化はデフォルト(無効)のままにしておきます。
- フォルダの作成を選択します。
- この手順を繰り返して、同じバケットに
archivedフォルダを作成します。
AWS Glueデータベースとクローラーの作成
ここでは、AWS Glue データベースと、データバケット内のデータファイルをクロールするクローラーを作成し、新しいデータベースに AWS Glue テーブルを作成します。
注)2022年10月20日時点の新UIの手順に対応しました。
- AWS Glue のコンソールで、ナビゲーションペインから Databases を選択します。
- Add database を選択します。
- Name(例:
sscp-database)と Description を入力します。 - Create Database を選択します。
- ナビゲーションペインで Crawlers を選択します。
- Create crawler を選択します。
- Name には、名前(
glue-crawler-sscp-sales-data)を入力します。 - Next を選択します。
- Add a data source を選択します。
- Data source は、 S3 を選択します。
- S3 path で、作成した S3 バケットとフォルダ(
s3://aws-blog-sscp-ng-202202/data)を選択します。 - データストアを繰り返しクロールする場合は、Subsequent crawler runs で、Crawl all sub-folders を選択します。
- Add an S3 data source を選択します。
- Next を選択します。
- Creat new IAM role を選択し、ロールの名前を入力します(例:
sscp-blog)。 - Next を選択します。
- Target database は、AWS Glue データベース(
sscp-database)を選択します。 - Table name prefix に、プレフィックスを入力します(例:
sscp_sales_)。 - Advanced options セクションを展開し、 Update the table definition in the data catalog を選択します。
- Crawler schedule の Frequency は、On demand を選択します。
- その他の設定をデフォルトのままにして、 Next を選択します。
- Create crawler を選択して、クローラーを作成します。
SNS のトピックを作成
SNSトピックを作成し、Eメールサブスクリプションを追加するには、次の手順を実行します。
- Amazon SNS コンソールで、ナビゲーションペインからトピックを選択します。
- トピックの作成を選択します。
- タイプでスタンダードを選択します。
- トピックの名前を入力します (例:
NotifySchemaChanges)。 - その他の設定をすべてデフォルトのままにして、トピックの作成を選択します。
- ナビゲーション ウィンドウで、サブスクリプションを選択します。
- サブスクリプションの作成を選択します。
- トピック ARN で、作成した SNS トピックの ARN を選択します。
- プロトコルで E メールを選択します。
- エンドポイントには、通知を受け取るメールアドレスを入力します。
- その他はデフォルトのまま、サブスクリプションの作成を選択します。サブスクリプション確認の E メールが届くはずです。
- メールに記載されているリンクを選択し、確認します。
- 先ほどクローラー作成で作成した AWS Glue サービスロール(
AWSGlueServiceRole-sscp-blog)に以下の権限ポリシーを追加し、SNS トピックへの公開を許可します。ポリシー内の <$SNSTopicARN> は、実際の SNS トピックの ARN に変更することを忘れないでください。
- Job details のタブを選択します。
- ジョブの名前を入力します(例:
find-change-job-sscp)。 - IAM Role は、AWS Glue のサービスロール(
AWSGlueServiceRole-sscp-blog)を選択します。 - その他はデフォルトのまま、Save を選択します。
ソリューションのテスト
これまでの手順で、このソリューションを実行するためのインフラストラクチャを構成しました。では、実際に動かしてみましょう。まず、最初のデータファイルをアップロードし、クローラーを実行して、データカタログに新しいテーブルを作成します。 注)2022年10月20日時点の新UIの手順に対応しました。- 以下の内容で
salesdata01.csvという名前の CSV ファイルを作成します。
- Amazon S3 コンソールで、data フォルダに移動し、CSV ファイルをアップロードします。
- AWS Glue コンソールで、ナビゲーションペインから Crawlers を選択します。
- クローラーを選択し、Run を選択します。クローラーが完了するまで数分かかります。AWS Glue のデータベース(
sscp-database)にテーブル(sscp_sales_data)が追加されます。 - ナビゲーションペインの Tables を選択して、作成されたテーブルを確認します。ここで、
dataフォルダの既存のファイルをarchivedフォルダに移動します。 - Amazon S3 コンソールで、
dataフォルダに移動します。 - アップロードしたファイル(
salesdata01.csv)を選択し、アクションメニューから移動を選択します。 - ファイルを
archivedフォルダに移動します。スキーマを更新した2つ目のデータファイルをdataフォルダにコピーし、クローラーを再実行します。 - 次のコードで
salesdata02.csvという CSV ファイルを作成します。前のバージョンからの変更点は以下の通りです。regionカラムのデータを地域名から何らかのコードに変更(例:データ型を文字列から BIGINT に変更する)。repカラムを削除- 新しいカラム
totalを追加
- Amazon S3 バケット上で、
dataフォルダにファイルをアップロードします。 - AWS Glue コンソールで、ナビゲーションペインの Crawlers を選択します。
- クローラーを選択し、Run を選択します。クローラーの実行には約 2 分かかります。以前に作成したテーブル (
sscp_sales_data) のスキーマを更新します。 - Tables ページで新しいバージョンのテーブルが作成されていることを確認します。ここで AWS Glue ETL ジョブを実行し、新しいバージョンのテーブルスキーマがあるかどうかを確認し、CloudWatch Logs に旧バージョンのスキーマとの変更点をリストアップします。
- AWS Glue コンソールで、ナビゲーションペインから Jobs を選択します。
- ジョブ (find-change-job-sscp) を選択し、Script タブを選択します。
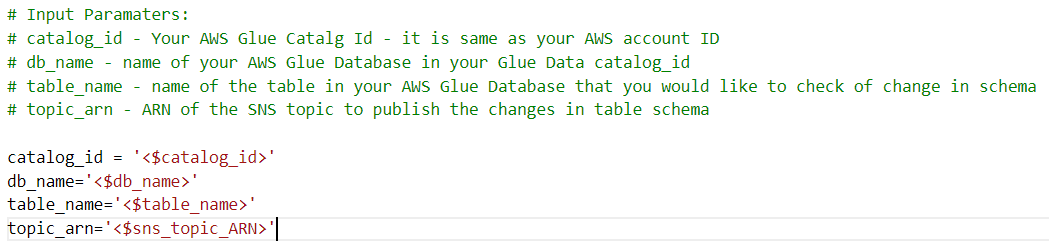
- スクリプト内のジョブの以下の入力パラメータを、設定に合わせて変更します。
- Save を選択します。
- スクリプトエディタを閉じます。
- ジョブを再度選択し、デフォルトのパラメータはすべてそのままにして、Run Job を選択します。
- ジョブの状態を監視するには、ナビゲーションペインから monitoring を選択し、Job runs にてジョブを確認します。
- ジョブが完了したら、View Cloud Watch Logs を選択します。
ログには、AWS Glue ジョブで確認された変更が表示されるはずです。
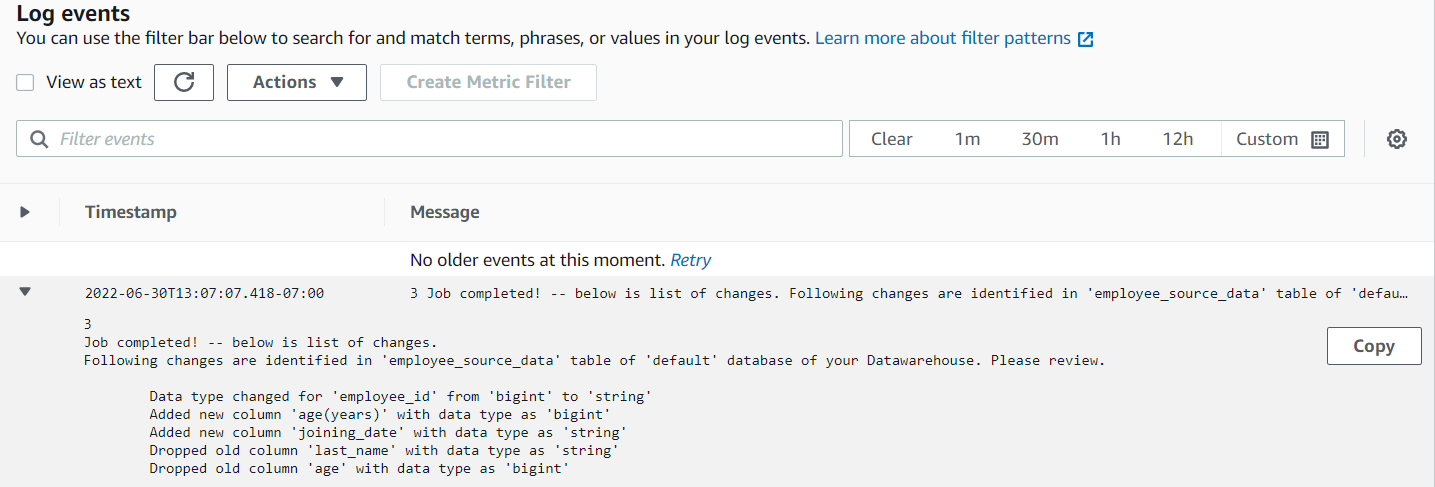
また、スキーマの変更に関する詳細が記載されたメールも受信しているはずです。以下は、受信したメールの例です。

これで、AWS Glue ETL ジョブによって特定されたスキーマの変更を確認し、S3 バケットから下流のアプリケーションにデータを伝播させるジョブを実行する前に、スキーマの変更に応じて下流のデータストアに変更を加えることができます。例えば、Amazon Redshift のテーブルがある場合、ジョブがすべてのスキーマ変更をリストアップした後、Amazon Redshift データベースに接続し、これらのスキーマ変更を行う必要があります。本番システムでスキーマ変更を行う前に、組織で設定された変更要求プロセスに従うことを忘れないでください。
以下の表は、Apache Hive と Amazon Redshift のデータ型に対するマッピングのリストです。他のデータストアの同様のマッピングを見つけ、下流のデータストアを更新することができます。
提供された Python コードは、スキーマの変更を比較するためのロジックを担当します。スクリプトは、AWS Glue データカタログ ID、AWS Glue データベース名、AWS Glue テーブル名のパラメータを受け取ります。
| Hive Data Types | Description | Amazon Redshift Data Types | Description |
| TINYINT | 1 byte integer | . | . |
| SMALLINT | Signed two-byte integer | SMALLINT | Signed two-byte integer |
| INT | Signed four-byte integer | INT | Signed four-byte integer |
| BIGINT | Signed eight-byte integer | BIGINT | Signed eight-byte integer |
| DECIMAL | . | . | . |
| DOUBLE | . | . | . |
| STRING | . | VARCHAR, CHAR | . |
| VARCHAR | 1 to 65355, available starting with Hive 0.12.0 | VARCHAR | . |
| CHAR | 255 length, available starting with Hive 0.13.0 | CHAR | . |
| DATE | year/month/day | DATE | year/month/day |
| TIMESTAMP | No timezone | TIME | Time without time zone |
| . | . | TIMETZ | Time with time zone |
| ARRAY/STRUCTS | . | SUPER | . |
| BOOLEAN | . | BOOLEAN | . |
| BINARY | . | VARBYTE | Variable-length binary value |
クリーンアップ
ソリューションの体験が終わったら、このウォークスルーの一部として作成したリソースを削除してください。
注)下記リソースを削除しない場合、継続的な課金がなされますのでご注意ください。
- AWS Glue ETL ジョブ (
find-change-job-sscp) - AWS Glue クローラ (
glue-crawler-sscp-sales-data) - AWS Glue テーブル (
sscp_sales_data) - AWS Glue データベース (
sscp-database) - クローラーと ETL ジョブ用の IAM ロール (
AWSGlueServiceRole-sscp-blog) - data フォルダと archived フォルダにあるすべてのファイルと、それらが格納されていた S3 バケット (
aws-blog-sscp-ng-202202) - SNS トピックとサブスクリプション (
NotifySchemaChanges)
結論
この投稿では、AWS サービスを組み合わせてソースデータのスキーマ変更を検出し、それを使って下流のデータストアを変更したり、ETL ジョブを実行したりして、データパイプラインの障害を回避する方法を紹介しました。ソースデータのスキーマを理解しカタログ化するために AWS Glue を、スキーマの変更を特定するために AWS Glue API を、そして変更についてチームに通知するために Amazon SNS を使用しました。また、AWS Glue API を使用して、ソースデータスキーマの古いバージョンを削除する方法を紹介しました。データレイクのストレージ層として、Amazon S3 を使用しました。
こちらで、AWS Glue の詳細について説明しています。
原文は、こちらです。