Amazon Web Services ブログ

週刊生成AI with AWS – 2026/4/13週
週刊生成AI with AWS, HANNOVER MESSE 2026 開催で産業 AI の熱が高まる2026年4月13日週号 – ブラザー工業様とパナソニック エレクトリックワークス様の AI-DLC 実践事例、スギ薬局様の Amazon Bedrock を活用した現場変革事例、そして Spec-Driven Presentation Maker 紹介記事など9件のブログを紹介。サービスアップデートでは、Amazon Bedrock で Claude Opus 4.7 の提供開始、Kiro CLI 2.0 のヘッドレスモードと Windows サポートのリリースも注目です。

AWS と NVIDIA によるフィジカル AI の加速: シミュレーションと実世界での学習による本番環境向けアプリケーションの構築
本記事は 2026/04/15 に公開された “Accelerating physical AI […]

AWS Interconnect が一般提供され、ラストマイル接続を簡素化する新しいオプションが追加されました
2026 年4 月 14 日、AWS Interconnect – マルチクラウドの一般提供についてお知らせし […]
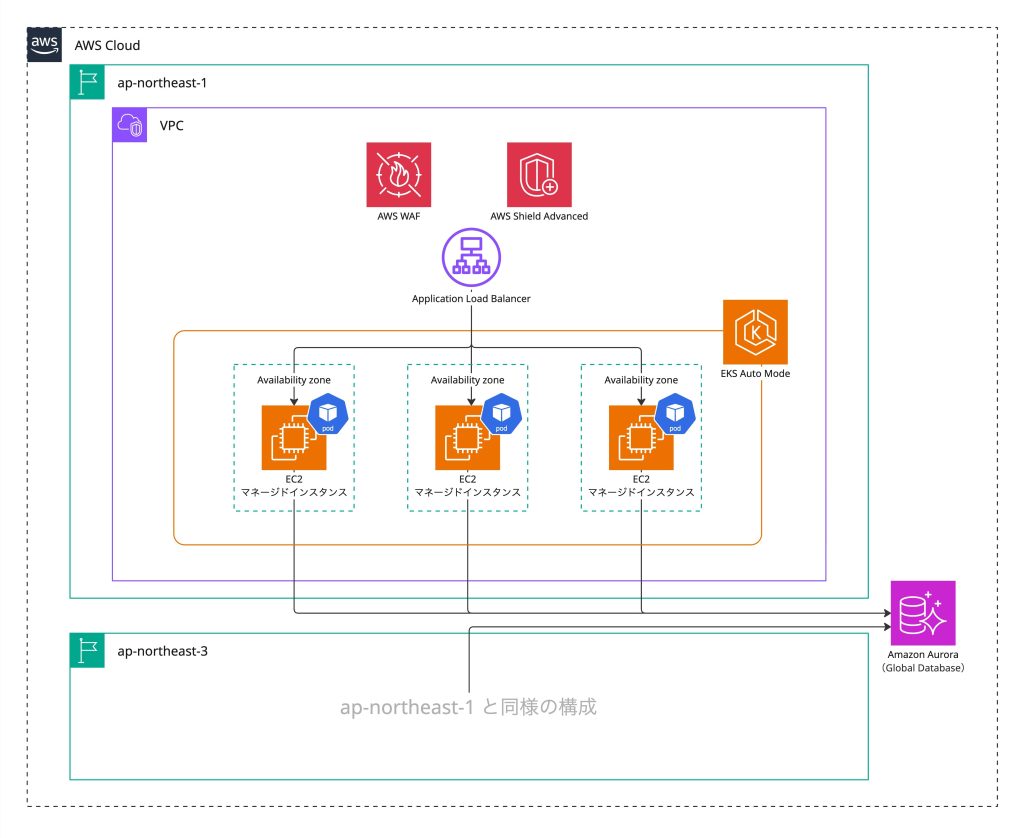
寄稿:SBI ネオバンキングシステムにおける Amazon EKS Auto Mode の導入事例 ― 移行で実現した運用負荷の軽減
本稿は、SBI ネオバンキングシステム株式会社による AWS EKS Auto Modeの活用について、主導さ […]

Amazon Quick Event 東京リージョンローンチ記念イベント 開催報告
2026 年 3 月 27 日、Chat Agent や Flows をはじめとする Amazon Quick のAI Agent 機能の東京リージョンローンチを記念したイベント「Amazon Quick Event」が開催されました。本イベントでは、Amazon Quick の製品紹介や Amazon 社内での活用事例に加え、AWS パートナー企業やお客様による具体的な導入事例が共有されました。会場には多くのお客様にお越しいただき、オンラインでも多数の方にご参加いただきました。本記事では、イベントの模様をレポートします。

スギ薬局様の AWS 生成 AI 事例:業務課題に向き合う組織体制と、生成 AI による現場変革
スギ薬局様では、現場の業務課題と技術を組織的に結びつける体制のもと、Amazon Bedrock を活用した年末調整 QA ボットと調剤医薬品在庫確認エージェントを構築。成果が次の AI 活用を呼ぶサイクルが回り始めています。

Planview が Kiro CLI で SOC 2 コンプライアンスを自動化し、監査サイクルあたり 40 時間以上を削減
コンプライアンス管理は、時に圧倒的な負担に感じることがあります。多くのエンジニアリングチームにとって、継続的に大きな注意を払い続ける必要がある業務です。チームは年間サイクルごとに 40 時間以上をかけてエビデンスを収集し、クラウドプロバイダーのコンソールを操作し、監査期限が迫る中でスプレッドシートを作成しています。戦略的ポートフォリオ管理のリーダーとして世界中で 3,000 社以上の顧客にサービスを提供する Planview も、同じ課題に直面していました。マルチサービスの AWS インフラストラクチャ全体で SOC 2 コンプライアンスを維持するために、顧客向けの機能開発に充てるべきエンジニアリング時間が消費されていたのです。ここでは、Planview が Kiro CLI を使ってコンプライアンスワークフローをどのように変革し、コンプライアンスサイクルあたり 40 時間以上を削減したかをご紹介します。

AWS Weekly Roundup: Amazon Bedrock での Claude Mythos のプレビュー、AWS Agent Registry など (2026 年 4 月 13 日)
前回の Week in Review に、2026 年、お客様との AI-Driven Development […]

パナソニック エレクトリックワークス株式会社の新組織立ち上げに向けた取り組み – AI駆動開発ライフサイクルとAI成熟度診断の実践
AI の業務活用が広がる中、多くの企業が次の課題に向き合っています。個別の AI 活用は始まっているものの、組 […]

Kiro CLI 2.0: デザイン刷新、ヘッドレス CI/CD パイプライン、Windows サポート
ターミナルで作業する開発者にとって、ワークフローに合ったツールが必要です。その逆ではありません。だからこそ私たちは Kiro CLI を開発しました。Kiro CLI は、そのまま使えるエージェント型ターミナルで、高品質なコードをより速くリリースできます。ローンチ以来、皆さんから素晴らしい反響をいただきました。気に入った点、改善が必要な点、そして足りない機能について教えていただきました。私たちはその声に耳を傾け、本日、皆さんからリクエストの多かった 3 つの大きな機能をリリースしました。