Amazon Web Services ブログ
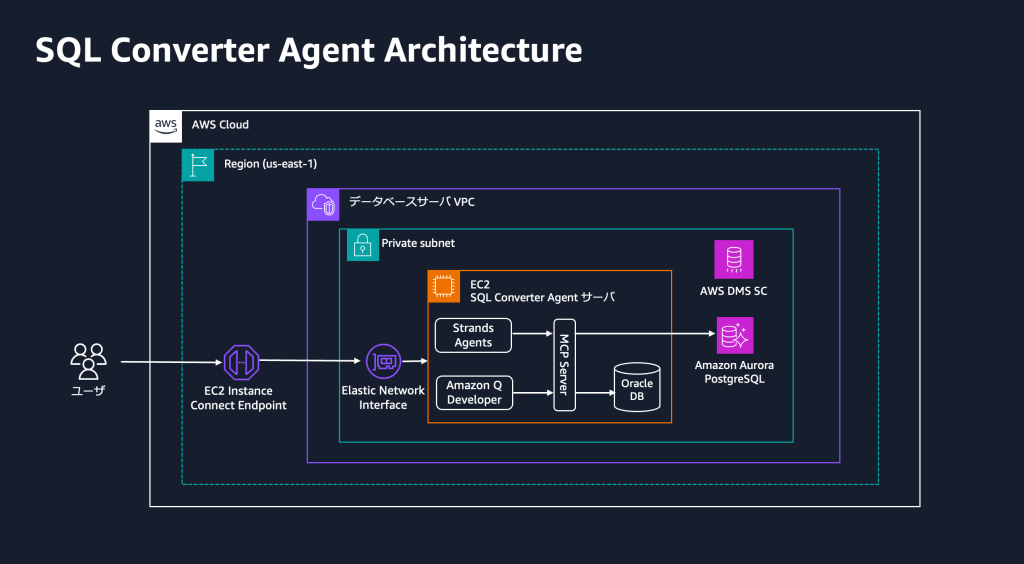
Oracle Database から Amazon Aurora PostgreSQL への移行を加速する生成 AI エージェント
本ブログは三菱電機ビルソリューションズ株式会社様と Amazon Web Services Japan 合同会 […]

Kiro における負債にならない Spec ファイルの扱い方
Kiro の Spec ファイルは「仕様駆動開発」を構成する要素です。Spec ファイルにより仕様を起点として設計・実装を進めることができ、仕様と実装の同期を保ちながら開発を進めることができます。このように Spec ファイルは Kiro の中核をなす要素なのですが、適切に扱わないと負債になってしまう可能性があります。本記事では、「Spec ファイルの切り方」「Spec ファイルの更新方法」「Spec ファイルの共有方法」の 3 つの視点から、負債にならないための工夫をお伝えします。

AWS re:Invent 2025 広告・マーケティングテクノロジーのためのガイド
本記事は 2025 年 11 月 20 日に公開された Anthony Hayes による “Your gui […]

SAPモダンオブザーバビリティフレームワーク:PowerConnectとDynatraceによる監視課題の解決策
モダンなSAP環境では、ビジネスプロセスが単一システムの枠を超えて拡張されるにつれ、高度な監視機能が求められています。組織は現在、SAP Cloud ERP、SAP Business Technology Platform(BTP)、AWSサービス、および様々なクラウドソリューションを含む相互接続されたプラットフォームを管理しています。この複雑性には、システム監視に対する新しいアプローチが必要です。SoftwareOne PowerConnect for SAP Solutionsは、SAPエコシステム全体にわたる広範なカバレッジを提供することで、これらの課題に対処します。そのオブザーバビリティフレームワークは、OpenTelemetry標準を通じて、システム固有の監視を実用的なインテリジェンスに変換し、プロアクティブなパフォーマンス管理とリアルタイムの運用インサイトを可能にします。
複数の組織にわたる AWS 請求とコストを一元管理するための新しい AWS Billing Transfer
2025 年 11 月 19 日、Billing Transfer の一般提供についてお知らせします。これは、 […]

Container Network Observability を使用して、EKS クラスター全体のネットワークパフォーマンスとトラフィックをモニタリング
組織は、マイクロサービスを導入して段階的に革新し、ビジネス価値をより早く提供することで、Kubernetes […]

AI ワークロードのパフォーマンスとコストの一致に役立つ新しい Amazon Bedrock サービスティア
2025 年 11 月 18 日、アプリケーションに必要なパフォーマンスレベルを維持しながら、AI ワークロー […]

週刊AWS – 2025/11/17週
Amazon MWAA が Apache Airflow ワークフロー向けサーバーレスデプロイメントオプションを導入、Amazon EC2 で Microsoft SQL Server 高可用性デプロイメントのコストを削減、ウェブサイト配信とセキュリティの定額料金プランを発表、複数組織の請求とコスト管理のための Billing Transfer を開始、Savings Plans と Reserved Instances のグループ共有が一般提供開始、Amazon CloudFront がオリジン接続で TLS 1.3 をサポート開始、Amazon EC2 での Microsoft SQL Server 2025 イメージの提供開始を発表など

週刊生成AI with AWS – 2025/11/17 週
週刊生成AI with AWS, 充実の2025年11月17日週号 – 三遠ネオフェニックス様、NTT西日本様・エルガナ様、ANAシステムズ様の国内事例ブログを紹介。Kiro Week in Japan特集として5日間の連載記事とre:Invent 2025セッションガイドを公開。サービスアップデートでは、SageMaker の AI エージェント機能、Bedrock の Model Import 拡張と Priority/Flex ティア、EC2 P6 B300 インスタンス、Polly 生成的TTSエンジンをはじめとする23件のアップデートを紹介。

新しい Amazon EC2 P6-B300 インスタンスで大規模な AI アプリケーションを高速化
2025 年 11 月 18 日、NVIDIA Blackwell Ultra GPU によって高速化された次 […]