Amazon Web Services ブログ
新しい SQL コマンド MERGE と QUALIFY を Redshift の変更データキャプチャの実装と検証のために使用する
Amazon Redshift は、クラウドにあるフルマネージド型のペタバイトスケールのデータウェアハウスサービスです。 何万ものお客様が Amazon Redshift を使用して毎日エクサバイトのデータを処理し、分析ワークロードを強化しています。
Amazon Redshift には、ROLLUP、CUBE、GROUPING SETS などの分析処理を強化する多くの機能が追加されています。これらの機能は、「ROLLUP、CUBE、GROUPING SETS などの新しい SQL 構文を使用して Amazon Redshift のオンライン分析処理 (OLAP) クエリを簡略化」という記事で説明されています。 Amazon Redshift では最近、多くの SQL コマンドと式が追加されました。 この記事では、データの取り込みとデータのフィルタリングを簡略化する MERGE 文と QUALIFY 句という 2 つの新しい SQL 機能について説明します。
ほとんどのダウンストリームアプリケーションでおなじみのタスクの 1 つは、変更データキャプチャ (CDC) とそのターゲットテーブルへの適用です。 このタスクでは、ソースデータを調べて、それが既存のターゲットデータへの更新なのか、挿入なのかを判断する必要があります。 MERGE 文を使用しない場合は、キーを使用して新しいデータセットを既存のデータセットと照合する必要がありました。 一致しない場合は、既存のデータセットに新しい行を挿入します。一致する場合は、既存のデータセット行を新しいデータセット値で更新します。
MERGE 文は、ソーステーブルの行を条件付きでターゲットテーブルにマージします。 従来、これは複数の insert、update、または delete 文を別々に使用することによってのみ実現できました。 複数のステートメントを使用してデータを更新または挿入する場合、異なる操作間で矛盾が生じるリスクがあります。 MERGE 操作では、すべての操作が 1 つのトランザクションで同時に実行されるため、このリスクが軽減されます。

QUALIFY 句は、ユーザーが指定した検索条件に従って、以前に計算されたウィンドウ関数の結果をフィルタリングします。 この句を使用すると、サブクエリを使用せずにウィンドウ関数の結果にフィルタリング条件を適用できます。 これは、WHERE 句が適用された行にさらに絞り込む条件を適用する HAVING 句に似ています。 QUALIFY と HAVING の違いは、QUALIFY 句でのフィルター処理はウィンドウ関数の実行結果を元に実行が可能なことです。 1 つのクエリで QUALIFY 句と HAVING 句の両方を使用できます。

この記事では、MERGE 文を使用して CDC を実装する方法と、QUALIFY を使用してそれらの変更の検証を簡略化する方法を示します。
ソリューションの概要
このユースケースでは、データウェアハウスがあり、その中に常にソースシステムから最新のデータを取得する必要がある顧客ディメンションテーブルがあります。 このデータは、監査と追跡の目的で、初期作成時刻と最終更新時刻も反映されている必要があります。
これを解決する簡単な方法は、顧客ディメンションを毎日完全に上書きすることです。ただし、これでは監査義務がある更新の追跡を実現できず、大規模なテーブルでは実行できない可能性があります。
Amazon Simple Storage Service (Amazon S3) からサンプルデータをロードするには、こちらの手順に従います。 sample_data_dev.tpcds の下にある既存の顧客テーブルを使用して、既存の顧客データの更新と新規顧客データの挿入の両方を含む顧客ディメンションテーブルとソーステーブルを作成します。 MERGE 文を使用して、ソーステーブルデータをターゲットテーブル (顧客ディメンション) とマージします。 また、QUALIFY 句を使用してターゲットテーブルの変更を簡単に検証する方法も示します。
この記事の手順を実行するには、付属のノートブックをダウンロードすることをお勧めします。ノートブックには、この記事で実行するすべてのスクリプトが含まれています。 ノートブックの作成と実行については、「ノートブックの作成と実行」を参照してください。
前提条件
以下の前提条件を満たしている必要があります。
- AWS アカウント
- Redshift のプロビジョニングされたクラスターまたは Amazon Redshift Serverless エンドポイント
sample_data_devデータベース (顧客テーブルを含む) 内にある tpcds データ
ディメンションテーブルの作成と設定
customer_dimension テーブルを作成するために、sample_data_dev.tpcds の下にある既存の顧客テーブルを使用します。 次の手順を実行します。
-
- キーを含むいくつかのフィールドを使用してテーブルを作成し、メンテナンスするためのフィールドとして挿入および更新のタイムスタンプを追加します。
- ディメンションテーブルにデータを挿入します。

- 行数とテーブルの内容を検証します。

顧客テーブルの変更をシミュレートする
次のコードを使用して、テーブルに加えられた変更をシミュレートします。

ソーステーブルをターゲットテーブルにマージする
これで、顧客ディメンションテーブルに対してマージする必要のある変更を加えた、ソーステーブルができました。
MERGE 文が使用できるようになる前は、このタイプのタスクを実装するために 2 つの個別の UPDATE コマンドと INSERT コマンドが必要でした。
MERGE 文はより簡潔な構文を使用します。この構文では、キーを比較した結果を使用して、更新の DML 操作(一致した場合)を実行するか、挿入の DML 操作(一致しない場合)を実行するかを決定します。

ターゲットテーブルのデータ変更を検証
次に、変更されたデータがターゲットテーブルに正しく反映されたことを確認する必要があります。 まず、更新タイムスタンプを使用して更新されたデータを確認できます。 これが初めての更新だったので、更新タイムスタンプが null でないすべての行を調べることで検証可能です。
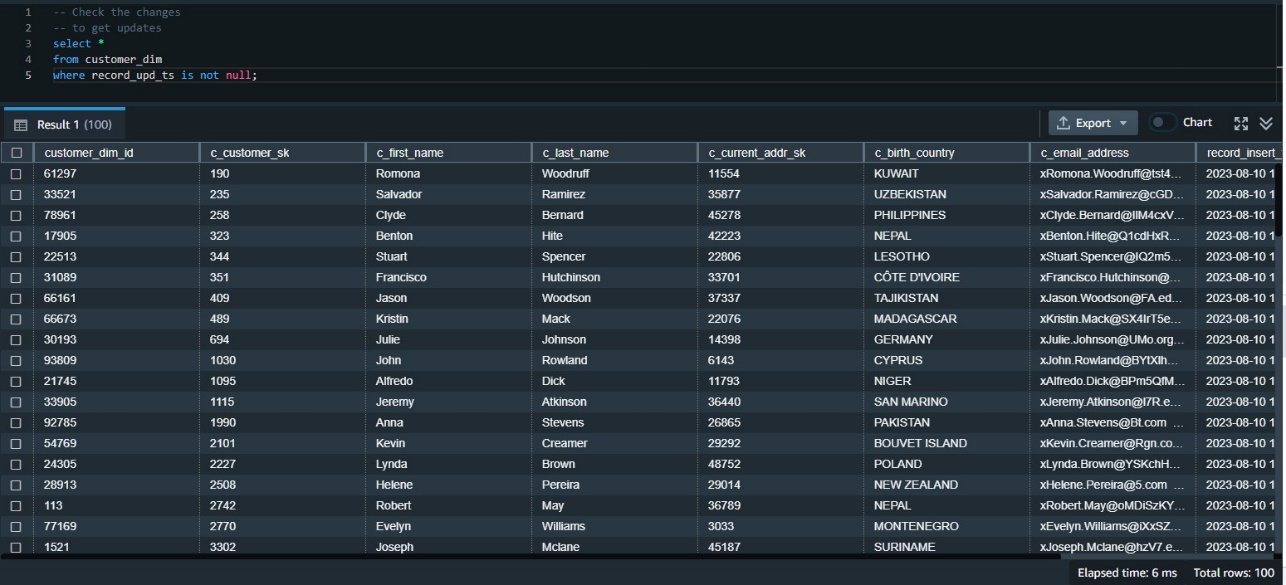
QUALIFYを使用して、データ変更の検証を簡略化する
テーブルに挿入された一番新しいデータを調べる必要があります。 その方法の 1 つは、挿入タイムスタンプでデータをランク付けし、最上位のデータを取得することです。 これには、ウィンドウ関数 rank () を使用する必要があり、結果を取得するためのサブクエリも必要です。
QUALIFYが利用可能になる前は、次のようなサブクエリを使用してそれを構築する必要がありました。
QUALIFY 関数を使用すると、次のコードのようにサブクエリが不要になります。
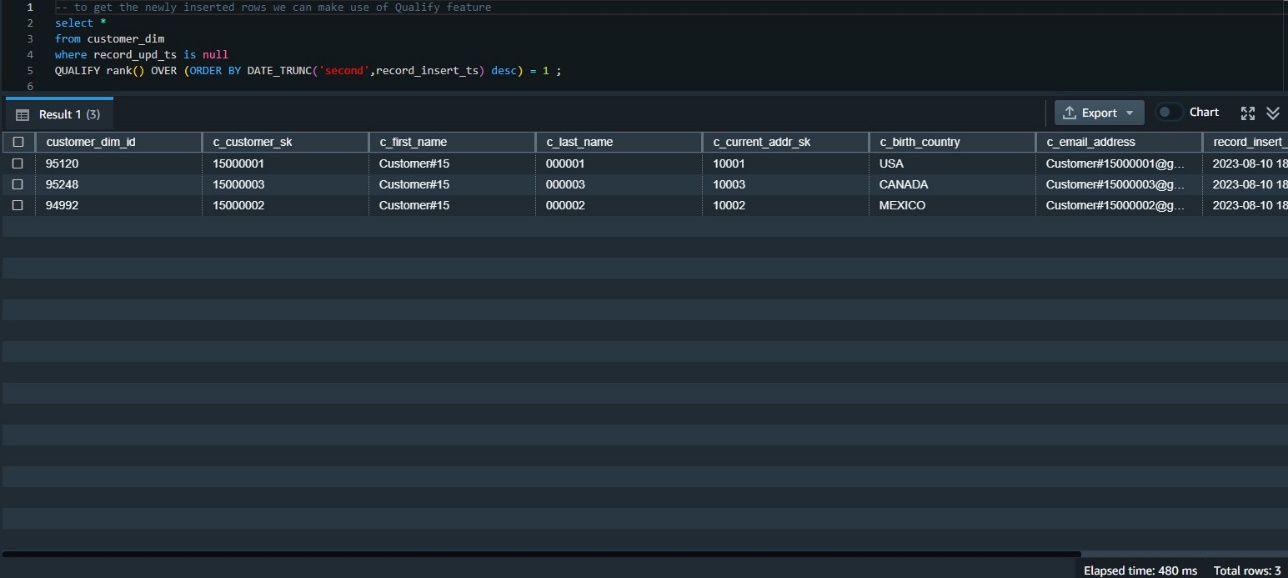
すべてのデータ変更を検証
両方のクエリの結果を結合して、すべての挿入と更新の変更を取得できます。
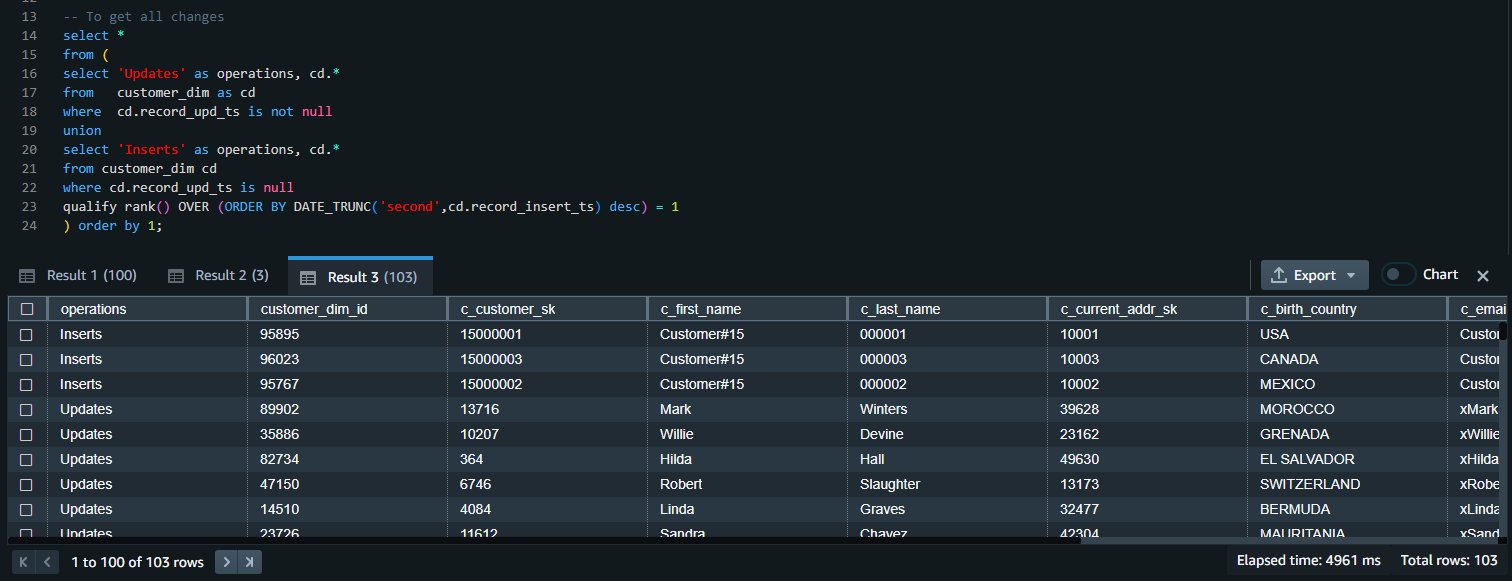
クリーンアップ
使用したリソースをクリーンアップするには、この記事用に作成した Redshift のプロビジョニングされたクラスター、または Redshift Serverless のワークグループと名前空間を削除します (これにより、作成されたすべてのオブジェクトも削除されます)。
既存の Redshift プロビジョニングされたクラスターまたは Redshift Serverless ワークグループと名前空間を使用した場合は、次のコードを使用してこれらのオブジェクトを削除します。
まとめ
複数のステートメントを使用してデータを更新または挿入する場合、異なる操作間で矛盾が生じるリスクがあります。 MERGE 操作では、すべての操作が 1 つのトランザクションで同時に実行されるため、このリスクが軽減されます。 他のデータウェアハウスシステムから移行している Amazon Redshift のお客様や、急速に変化するデータを Redshift に定期的に取り込む必要がある Amazon Redshift のお客様にとって、MERGE 文は、既存および新しいソースデータに基づいてターゲットテーブルからデータを条件付きで挿入、更新、削除する簡単な方法です。
ウィンドウ関数を使用するほとんどの分析クエリでは、WHERE 句でもこれらのウィンドウ関数を使用する必要がある場合があります。 ただし、これは許可されていないため、必要なウィンドウ関数を含むサブクエリを作成し、その結果を親クエリの WHERE 句で使用する必要があります。 QUALIFY 句を使用するとサブクエリが不要になるため、SQL ステートメントが簡略化され、書き込みや読み取りが簡単になります。
これらの新機能を使い始めて、フィードバックをお寄せください。 詳細については、MERGE 文と QUALIFY 句のドキュメントを参照してください。
著者について
 Yanzhu Ji は Amazon Redshift チームのプロダクトマネージャーです。 業界をリードするデータ製品およびプラットフォームにおける製品ビジョンと戦略の経験があります。 彼女は、ウェブ開発、システムデザイン、データベース、および分散プログラミング技術を使用して優れたソフトウェア製品を構築する優れたスキルを持っています。 Yanzhu は私生活では、絵画、写真、テニスが好きです。
Yanzhu Ji は Amazon Redshift チームのプロダクトマネージャーです。 業界をリードするデータ製品およびプラットフォームにおける製品ビジョンと戦略の経験があります。 彼女は、ウェブ開発、システムデザイン、データベース、および分散プログラミング技術を使用して優れたソフトウェア製品を構築する優れたスキルを持っています。 Yanzhu は私生活では、絵画、写真、テニスが好きです。
 Ahmed Shehata は、トロントを拠点とする AWS のシニアアナリティクススペシャリストソリューションアーキテクトです。 彼は 20 年以上にわたり、お客様のデータプラットフォームの近代化を支援してきました。 Ahmed は、効率的でパフォーマンスが高く、スケーラブルな分析ソリューションをお客様が構築できるよう支援することに情熱を注いでいます。
Ahmed Shehata は、トロントを拠点とする AWS のシニアアナリティクススペシャリストソリューションアーキテクトです。 彼は 20 年以上にわたり、お客様のデータプラットフォームの近代化を支援してきました。 Ahmed は、効率的でパフォーマンスが高く、スケーラブルな分析ソリューションをお客様が構築できるよう支援することに情熱を注いでいます。
 Ranjan Burman は AWS のアナリティクススペシャリストソリューションアーキテクトです。 Amazon Redshift を専門とし、お客様がスケーラブルな分析ソリューションを構築できるよう支援しています。 彼はさまざまなデータベースおよびデータウェアハウステクノロジーで 16 年以上の経験があります。 クラウドソリューションによる顧客の問題の自動化と解決に情熱を注いでいます。
Ranjan Burman は AWS のアナリティクススペシャリストソリューションアーキテクトです。 Amazon Redshift を専門とし、お客様がスケーラブルな分析ソリューションを構築できるよう支援しています。 彼はさまざまなデータベースおよびデータウェアハウステクノロジーで 16 年以上の経験があります。 クラウドソリューションによる顧客の問題の自動化と解決に情熱を注いでいます。
翻訳はソリューションアーキテクトの小役丸が担当しました。元記事はこちらです。