Amazon Web Services ブログ
Amazon Redshift で空間的なデータを活用
本日、Amazon Redshift が新しいネイティブなデータ型である GEOMETRY のサポートを開始したことを発表いたしました。この新しいデータ型では、二次元の地理的データに関する取り込み、保存、クエリが行えるようになり、さらに、これらのデータを空間関数で処理できるようになります。地理的データ (地理参照されたデータともいいます) では、地球上に位置する場所に関係性のあるデータを取り扱います。座標、海抜、住所、都市名、郵便番号、行政および社会経済学的な境界線などは、すべて地理的データの一例です。
GEOMETRY 型の導入により、テーブルの列に記録した緯度や軽度といった座標データが簡単に操作できるようになります。これらのデータは、空間関数を使うことで、他の地理的データへの変換や組合せが可能です。これは抽象型のデータです。つまり直接インスタンス化はできず、ポリモーフィックです。このデータが実際にサポートする (そして、テーブルの列で使用される) のは、ポイント、ラインストリング、ポリゴン、マルチポイント、マルチラインストリング、マルチポリゴン、および地理的コレクションなどになります。今回追加の新機能では、テーブル内に GEOMETRY 型のデータ列が作成できることに加えて、従来の COPY を使って、行で区切られたテキストファイルから地理的データを取り込むこともできます。このファイルは、地理的データの表現のために標準的に使用される形式である、16 進数の Extended Well-Known Binary (EWKB) 形式での記述を想定しています。
この新しいデータ型の働きをお見せするために、ドイツのベルリンで活動するパーソナルツアーコーディネーターを想定し、その顧客からは、訪問してみたい観光名所のリストが手渡されているというシナリオを考えてみます。コーディネーターとしての任務は、いくつかの観光名所にちょうど良く囲まれていて、適切な料金の宿泊先を見つけることです。地理的データは、こういったシナリオに解決策を与えるためには最適です。まずは、宿泊先の地域が限定できるように、各観光名所に対応した一連のポイントを組合せ、1 つ、ないしは複数のポリゴンを形成します。こうしておくと、これらのポリゴンと対応するデータを、いくつかの宿泊先と対応するデータと組合せて、結果に示すことができるようになります。こういった空間情報へのクエリを、Redshift では 1 秒以内に実行することが可能ではありますが、実際のところ CPU にとっては、かなりコストがかかる処理でもあります。
シナリオのサンプルデータ
このシナリオでの動作をお見せする前に、まずは、ベルリン市内に関する各種の地理的データを入手する必要があります。始めに、旅行サイトにある「見ておくべき場所トップ X」のページを使いながら、いくつかの観光名所について、その住所と緯度/経度の座標などを取得します。宿泊先に関しては、ウェブページにある Airbnb のデータを、Creative Commons 1.0 Universal “Public Domain Dedication” のライセンスの下で利用させてもらいました。これに、Creative Commons Attribution 3.0 Germany (CC BY 3.0 DE) のライセンスにより、ベルリンの郵便番号を加えていきます。このデータは、Amt für Statistik Berlin-Brandenburg さんから提供されたものです。
良いツアーコーディネーターであれば、誰でも、ウェブサイトかインタラクティブな地図を備えたアプリケーションを用意していると思います。顧客が提示する基準に当てはまる宿泊先の場所を表示できるようにするためです。現実世界では、私自身は (家族に対する場合を除き) ツアーコーディネーターではありません。従ってここでは、純粋にバックエンドの処理 (データのローディング、最終的に顧客の要求を満たすため行う Redshift コンソールを使ってのクエリ) に焦点を当てます。
Redshift クラスターの作成
最初に取りかかるのは、Redshift クラスター内のテーブルに、各種のサンプルデータソースをロードするという作業です。これを行うには、Redshift コンソールのダッシュボードを開き、[Create cluste] をクリックします。これで、新しいクラスターでの一連の設定作業をガイドするウィザードが開始されるので、作成したいノードのタイプや数から設定していきます。
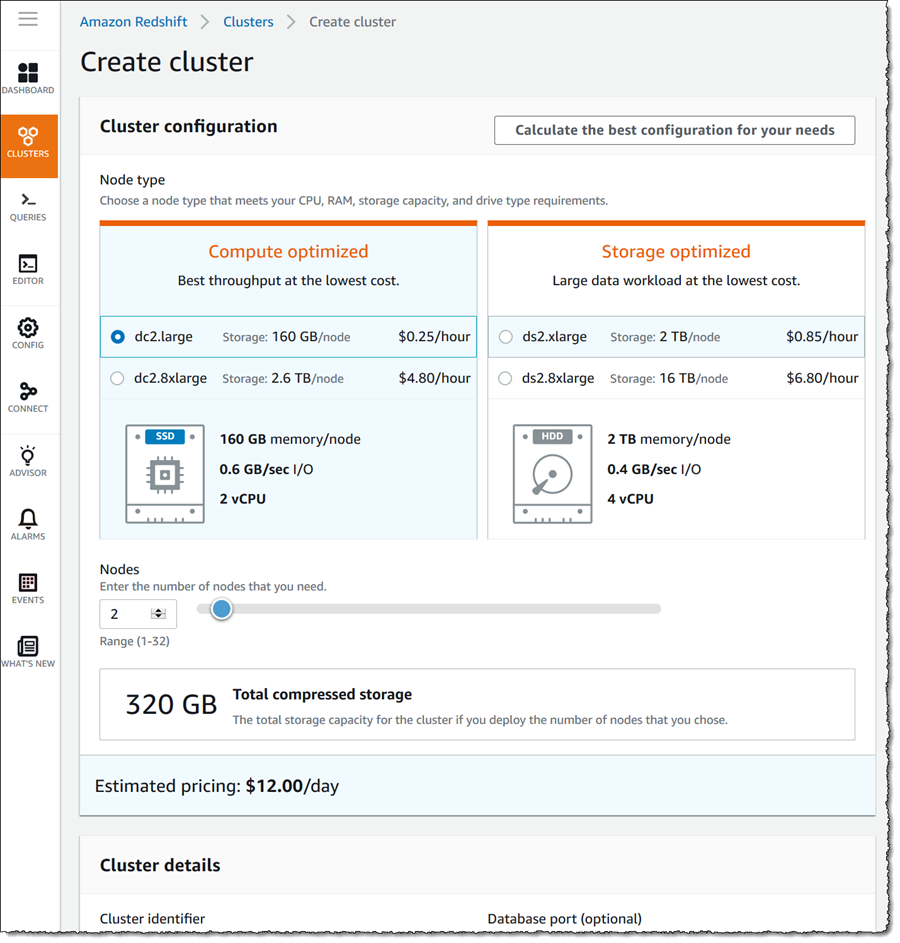
[Cluster details] において、作成するクラスターの名前を入力しマスターユーザーのパスワードを指定します。後にサンプルデータを取り出すときのために、Redshift に対し Amazon Simple Storage Service (S3) 内のバケットへの読み込み専用モードでのアクセス許可を付与する、AWS Identity and Access Management (IAM) を選択します。この新しいクラスターは、リージョンでデフォルトに設定している Amazon Virtual Private Cloud に作成されます。同時に、ノードの数やタイプに関しても、デフォルト設定を選択します。クラスター作成で利用可能なオプションの詳細については、「Amazon Redshift とは?」をご参照ください。最後に、[Create cluster] をクリックし処理を開始します。これは、ほんの数分で完了します。

サンプルデータのローディング
これでクラスターの使用準備ができましたので、サンプルデータをデータベースへローディングできます。[Query editor] へ移動して、ポップアップを使いデフォルトのデータベースとクラスターを接続します。

使用するサンプルデータは、既に S3 バケットにプライベートオブジェクトとしてアップロードしてある、行区切りされたテキストファイルから読み込みます。これらは、次のような 3 つのテーブルにロードされます。1 つめの accommodations は Airbnb からのデータを保持します。2 つめの zipcodes は市内の郵便番号を保持します。最後のテーブルである attractions には、顧客による選択が可能なように、市内の観光名所の座標が保持されます。宿泊先データの作成とロードを行うには、次に示すようなステートメントを、クエリエディタのタブへと、各処理につき 1 つずつコピーし実行していきます。ここで、データベースのスキーマにアクセスコントロールセマンティクスがあり、テーブル名に public のプレフィックスが付いているということは、単純に、使用するデータベースの全ユーザーがアクセス可能であるパブリックスキーマを参照しているという意味である、ということをご明記ください。
accommodations の作成には次を使います。
CREATE TABLE public.accommodations (
id INTEGER PRIMARY KEY,
shape GEOMETRY,
name VARCHAR(100),
host_name VARCHAR(100),
neighbourhood_group VARCHAR(100),
neighbourhood VARCHAR(100),
room_type VARCHAR(100),
price SMALLINT,
minimum_nights SMALLINT,
number_of_reviews SMALLINT,
last_review DATE,
reviews_per_month NUMERIC(8,2),
calculated_host_listings_count SMALLINT,
availability_365 SMALLINT
);S3 からのデータロードには次を使います。
COPY public.accommodations
FROM 's3://my-bucket-name/redshift-gis/accommodations.csv'
DELIMITER ';'
IGNOREHEADER 1
CREDENTIALS 'aws_iam_role=arn:aws:iam::123456789012:role/RedshiftDemoRole';次に、同じ処理を zipcodes テーブルに対して繰り返します
CREATE TABLE public.zipcode (
ogc_field INTEGER,
wkb_geometry GEOMETRY,
gml_id VARCHAR,
spatial_name VARCHAR,
spatial_alias VARCHAR,
spatial_type VARCHAR
);
COPY public.zipcode
FROM 's3://my-bucket-name/redshift-gis/zipcode.csv'
DELIMITER ';'
IGNOREHEADER 1
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftDemoRole';
最後に、attractions テーブルを作成し、それにデータをローディングします。
CREATE TABLE public.berlin_attractions (
name VARCHAR,
address VARCHAR,
lat DOUBLE PRECISION,
lon DOUBLE PRECISION,
gps_lat VARCHAR,
gps_lon VARCHAR
);COPY public.berlin_attractions
FROM 's3://my-bucket-name/redshift-gis/berlin-attraction-coordinates.txt'
DELIMITER '|'
IGNOREHEADER 1
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftDemoRole';宿泊すべき場所を検索してみます
データのローディングが完了したので、ここまでしてきたトラベルコーディネーターの仕事は終わりです。ベルリンでの宿泊先として顧客が検討できるように、いくつかのプロパティを選択してみましょう。 繰り返しですが、現実の社会でのこれらのプロパティは、通常、ウェブサイトやその他のアプリケーションを使って顧客に表示する情報です。しかしここでは単純に、クエリエディタを継続使用します。
顧客の人は、市内にある博物館や美術館を尋ねることを旅の主な目的としており、宿泊には 1 泊 200 EUR までという予算枠があります。エディターで新しくタブを開き、次のクエリをコピーして実行します。
WITH museums(name,loc) AS
(SELECT name, ST_SetSRID(ST_Point(lon,lat),4326) FROM public.berlin_attractions
WHERE name LIKE '%Museum%')
SELECT a.name,a.price,avg(ST_DistanceSphere(m.loc,a.shape)) AS avg_distance
FROM museums m,public.accommodations a
WHERE a.price <= 200 GROUP BY a.name,a.price ORDER BY avg_distance
LIMIT 10;
このクエリにより、博物館などを訪問するのにもっとも便利な場所にあり、同時に予算の範囲内で宿泊費が収まるような宿泊施設を見つけ出します。ここでいう「もっとも便利な場所」とは、選択したすべての博物館からの平均距離が最短な場所という定義です。このクエリには、利用可能な空間関数の内いくつかが使われているのが分かると思います。ST_SetSRID や ST_Point により GEOMETRY 列にある観光名所の経度および緯度を処理したり、ST_DistanceSphere により距離を測ったりしています。
これにより、次のような結果が表示されます。
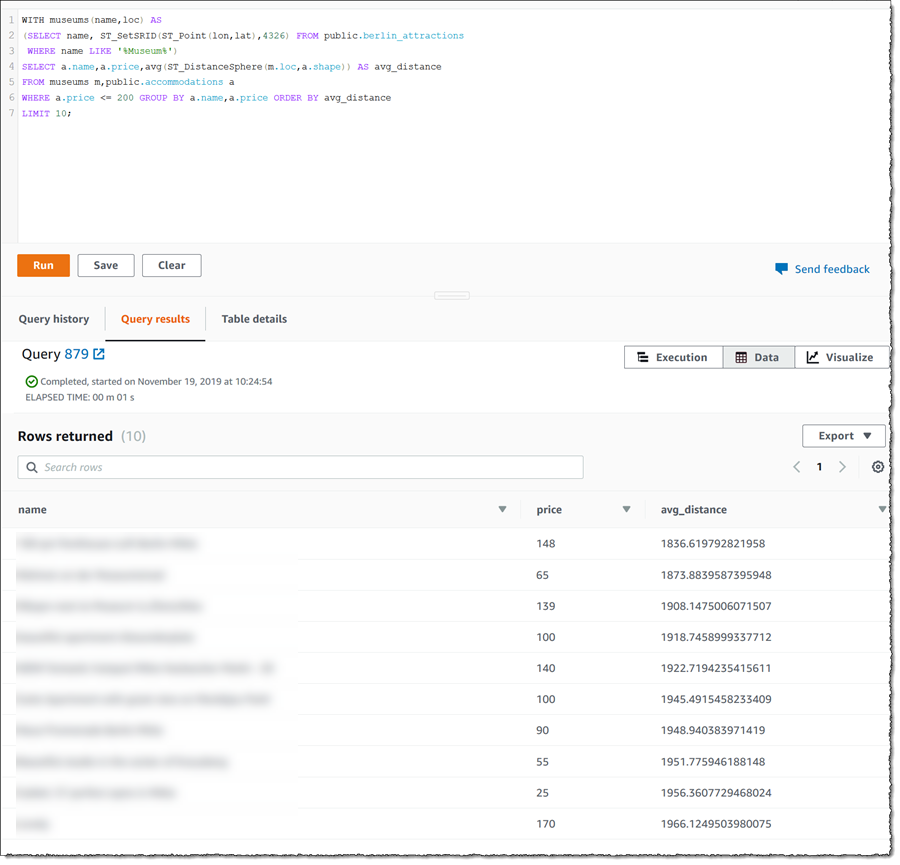
この結果をウェブぺージやネイティブアプリケーションのフロントエンドで覆うことで、地理情報のデータベースを基本にした新たなアプリケーションを実現できます。それにより、市内で訪れたい場所が明確で、またそれを実現するための最良の場所にある便利で予算範囲に収まる宿泊先を求めている顧客を、喜ばせることが可能になります。
では、他のシナリオについても考察してみましょう。顧客の 1 人に、ベルリン中心部に宿泊したいという希望があるものの、その人は、どのような観光名所や宿泊施設が市内中央にあるのか詳しくなく、1 泊の予算にも 150 EUR という制限がある場合を考えます。この場合はどうしたらよいでしょうか? そのため最初に必要なのは、ベルリンの中心だと想定できるポイントの座標、つまり、緯度 52.516667、緯度 13.388889 です。zipcode テーブルを使用すると、この座標が示す場所をポリゴンに変換し、市内でのその地域を囲むことができます。そうしてクエリを実行すると、ポリゴン内にあるすべての観光名所が取得できるはずです。さらに、すべての (予算枠に収まる) 宿泊施設を、観光名所からの平均距離順に整列させて抽出できます。使用するクエリは次のようなものです。
WITH center(geom) AS
(SELECT wkb_geometry FROM zipcode
WHERE ST_Within(ST_SetSRID(ST_Point(13.388889, 52.516667), 4326), wkb_geometry)),
pois(name,loc) AS
(SELECT name, ST_SetSRID(ST_Point(lon,lat),4326) FROM public.berlin_attractions,center
WHERE ST_Within(ST_SetSRID(ST_Point(lon,lat),4326), center.geom))
SELECT a.name,a.price,avg(ST_DistanceSphere(p.loc,a.shape))
AS avg_distance, LISTAGG(p.name, ';') as pois
FROM pois p,public.accommodations a
WHERE a.price <= 150 GROUP BY a.name,a.price ORDER BY avg_distance
LIMIT 10;
これをクエリエディタで実行すると、得られる結果は次のようになります。指定した地域内にある観光名所の一覧が、郵便番号を基に抽出され、pois 列に表示されています。
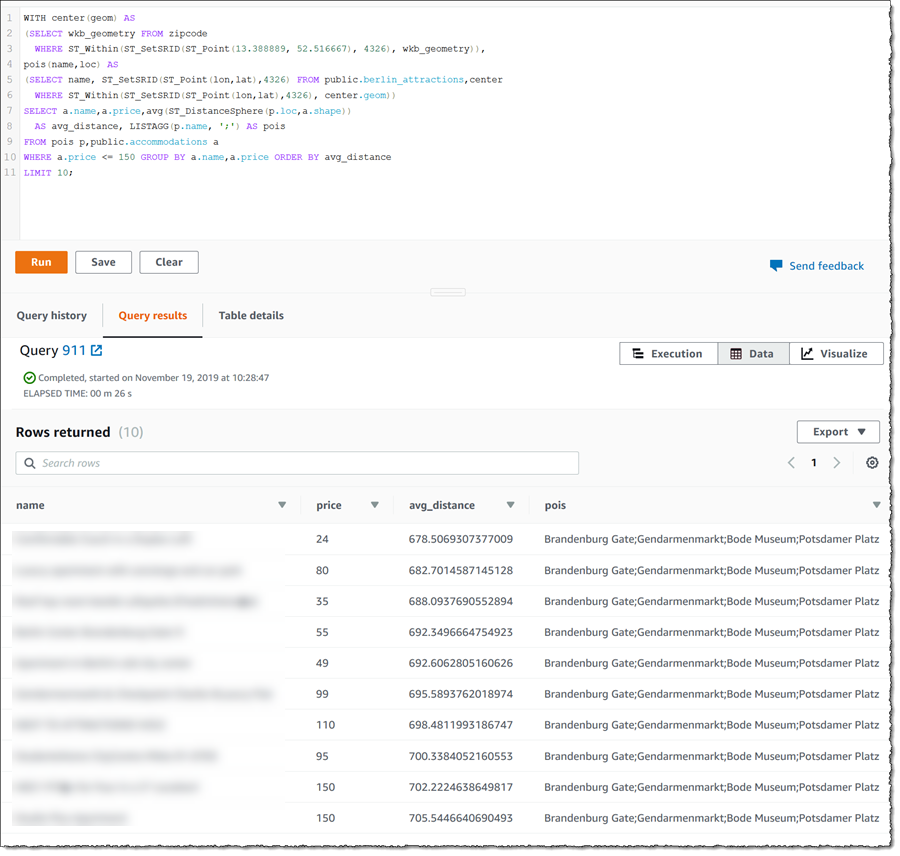
ここまで、新たに加わった GEOMETRY 型とそれに関連する空間関数を使い Amazon Redshift にある地理的データを活用するための、いくつかのシナリオをご紹介してきました。そしてもちろん、もっとたくさんの機能があります。 この新しいデータ型および関数は、現在、すべての AWS リージョンにおいて、すべてのお客様に追加の料金なしでご利用いただけます。