高度な AutoML ライブラリ、AutoGluon-Tabular を使ってみた
Author : 藤川 のぞみ
皆さんこんにちは、機械学習ソリューションアーキテクトの藤川です。
前回、「3 行のコードが実現する機械学習の自動化。「AutoGluon」が見据える未来とは ?」というブログ記事をお届けましました。そこでは AutoML の OSS のフレームワークである AutoGluon の開発者へのインタビューを取り上げたのですが、今回は、実際にこの AutoGluon を使ってみるチュートリアルをご紹介したいと思います。
今回は特にテーブルデータを対象とした AutoML ライブラリの AutoGluon-Tabular を取り上げます。AutoGluon-Tabular は 論文 でその精度の良さを発表して以来注目を集めているライブラリです。論文で報告されていることとして、Otto Group [2015 年] と BNP Paribas [2016 年] という 2 つの有名な Kaggle コンペティションで、AutoGluon は参加しているデータサイエンティストの 99% よりも高い精度を実現できたといった内容があります。AutoGluon は 2020 年にこのスコアを達成しており、本番のコンペティションには出場していませんが、それでもトップ 1 % を獲得したということは強力な結果と言えるかと思います。
AutoGluonでは、下記のように最短 3 行の Python コードを書くだけで高精度なモデルの構築を実現できるというのが大きな特徴でした。
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label=COLUMN_NAME).fit(train_data=TRAIN_DATA.csv)
predictions = predictor.predict(TEST_DATA.csv)2021 年 12 月 15 日現在、AutoGluon-Tabular の stable モデルのオプションで対応しているモデル は、以下のものです。
LightGBM, CatBoost, XGBoost, random forest, extremely randomized trees, k-nearest neighbors, linear regression, neural network with MXNet backend, neural network with FastAI backend
AutoGluon-Tabular では、上記の各モデルを構築するだけでなく、それらを基本的なモデルとして積み重ねる、多層スタックアンサンブルにより新たなモデルを構築します。ユーザーはそれらさまざまなモデルの中で最も良いと思われるモデルを利用することができます。AutoGluon についてはこちらの「AutoML のための機械学習 フレームワーク AutoGluon のご紹介」という資料もご参考になるかと思います。
今回は 国際会議 (KDD) でのチュートリアル や こちらのノートブック を参考に、AutoGluon-Tabular の基本的な使い方やカスタマイズ方法を体験していただくためのチュートリアルをご紹介していきます。
今回題材にするのは、銀行のダイレクトマーケティングです。具体的には、電話でのダイレクトーマーケティングのキャンペーンを一回以上行った後、顧客が銀行の定期預金に申し込むかどうかを機械学習で予測する問題に取り組みます。
チュートリアルではまず基本的な設定やデータの準備をした後、AutoGluon-Tabularの基本的な使い方を説明していきます。AutoGluon-Tabular を簡単にお使いいただけることを体験していただきたいと思います。その後、短いコードを実行したときに何が行われていたのかの解説や、カスタマイズの方法などを詳しく説明していきます。また、モデルの解釈やデプロイについても説明します。長編となりますが、基本的な使い方を知るだけであれば、「基本的な使い方」というセクションだけ見ていただければ十分ですので、ぜひ読んでいただければと思います。
目次
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
チュートリアル
1. 導入
今回は Jupyter ベースで解説をしていきます。
AutoGluon は OSS でありさまざまな環境で利用することができますが、Amazon SageMaker では必要なライブラリなどが予め設定された環境を利用できるため 今回はSageMaker での利用方法もご紹介します。SageMaker のセットアップについては最後のセクションで記述します。
以下では、SageMaker Studio ノートブックで実行した結果を表示していますが、必要なライブラリ等がインストールされていれば、Jupyter 環境で同様に実行いただけるかと思います。各コードは Jupyter ノートブックのセルの中で実行していただく想定です。
2. セットアップ
AutoGluon をインストールします。
インストールについては こちら に記載がありますが、SageMaker Studio ノートブックで Python 3 (MXNet 1.8 Python 3.7 CPU Optimized) のカーネルが選択されていれば、以下のコマンドだけでインストールが可能でしょう。
Jupyter 環境では、冒頭に ! を付けることでコマンドを実行できますね。
ipynb
!pip install autogluon==0.3.1このノートブックで使用するライブラリをインポートします。
ipynb
# AutoGluonをインポートする。
from autogluon.tabular import TabularDataset, TabularPredictor
# その他のライブラリをインポートする。
import pprint
from IPython.display import display
from IPython.display import HTML
import pandas as pd3. データの準備
AutoGluon-Tabular では、 pandas の DataFrame を読み込むことができます。あるいは、ヘッダーのついた適切にフォーマットされた CSV ファイルや Parquet ファイルを読み込むこともできます。適切にデータセットが用意できればあとは 最短 3 行のコード でモデルの学習から予測まで実行できます。データの準備部分は AutoGluon と直接関係しませんが、ここでは実際のデータを利用して AutoGluon を使ってみるため、データの準備についても一つのサンプルデータを対象に紹介していきます。
このチュートリアルでは、銀行のダイレクトマーケティングに機械学習を活用する問題に取り組みます。具体的には、電話でのダイレクトーマーケティングのキャンペーンを一回以上行った後、顧客が銀行の定期預金に申し込むかどうかを予測するタスクです。データセットの詳細は こちら をご確認ください。
まずはデータをダウンロードします。今回使用するデータセットは Amazon S3 のバケットで zip ファイルとして公開されていますが、 AWS のリージョンによってパスが変わっています。今回使用するノートブックと同じリージョンに公開されているデータをダウンロードします。
以下では、 sagemaker というライブラリをインポートしています。これは SageMaker の Python SDK です。この SDK を使用することで、このノートブックが起動しているリージョンを下記のようなメソッドで簡単に取得することができます。
ipynb
# 必要なライブラリをインポートする。
import sagemaker
session = sagemaker.Session()
region = session.boto_region_nameAWS CLI を利用して S3 のデータをダウンロードし、 pandas の DataFrame オブジェクトを作成します。
ipynb
# データをダウンロードして解凍する。
!aws s3 cp --region {region} s3://sagemaker-sample-data-{region}/autopilot/direct_marketing/bank-additional.zip .
!unzip -qq -o "bank-additional.zip"
# pandasのDataFrameオブジェクトを作成する。
local_data_path = "./bank-additional/bank-additional-full.csv"
data_org = pd.read_csv(local_data_path)データを確認してみます。
ipynb
data_org
クリックすると拡大します
このデータセットでは、現実的な設定の上では利用が難しい特徴量が含まれています。具体的には、 duration という特徴量で、通話時間ですが、これは電話をかける前には知り得ないため、電話をかける前にこの予測モデルを活用しようとする際には使用できない特徴量となります。この特徴量を除いておきましょう。
ipynb
# 予測時に使用できないカラムを除く。
data = data_org.drop(columns=["duration"])続いて、学習とテストデータに分割します。
ipynb
# 学習とテストデータに分割する。
train_data = data.sample(frac=0.7, random_state=42)
test_data = data.drop(train_data.index)
# テストデータの入力と出力を分割する。
label_column = "y"
y_test = test_data[label_column]
X_test = test_data.drop(columns=[label_column])今回予測するのは、電話をかけたあとに顧客が定期預金に申し込んだかどうかで、これは y というカラム名に相当します。このカラムの頻度を見てみます。
ipynb
print("ターゲット変数の値と頻度: \n", train_data[label_column].value_counts().to_string())
クリックすると拡大します
4. 基本的な使い方
まずは、AutoGluon-Tabular を簡単にお使いいただけることを体験していただきたいと思います。
データと、予測したいカラム名、モデルを保存するパスを指定し、デフォルト設定で実行してみます。
デフォルトでは、精度とコスト (メモリ使用量、推論速度、ディスク容量等) においてバランスが取られた設定となっています。もし精度を優先してモデル構築したい場合には、 fit() メソッドの引数で、presets='best_quality' を使うなどを検討して下さい。チュートリアル後半ではこのオプションでの実行も行います。詳細はこちら をご確認ください。
ipynb
# 学習したモデルを保存するディレクトリを指定する。
dir_base_name = "agModels"
dir_default = f"{dir_base_name}_default"それでは、学習を実行します。
下記はひとまとまりのセルとして実行してください。今回は時間計測のために %%time というマジックコマンドを入れています。このマジックコマンドはセルの冒頭にないとエラーが出るでしょう。
ipynb
%%time
predictor = TabularPredictor(label=label_column, path=dir_default).fit(train_data=train_data)“AutoGluon infers your prediction problem is: ‘binary’”というような記述があります。AutoGluon が自動で、今回のタスクが二値分類問題であると推論したようです。自動で判定していてすごいですね !

クリックすると拡大します
さらにスクロールしていくと、以下のように、LightGBM など複数のモデルを学習していることが分かります。

クリックすると拡大します
上記では、少ない設定で、予測対象のカラム名、データセット、モデルの保存パスのみ指定して学習を実行しました。しかし、AutoGluon ではさまざまな設定を行なうことが可能です。これらを設定していない場合、デフォルト設定が適用されます。
たとえば、分類問題ではデフォルトで accuracy を性能の評価指標にしますが、これは後ほどご紹介するように、TabularPredictor の eval_metric 引数でカスタマイズできます。 また、デフォルトで presets は medium_quality_faster_train です。これは、学習と推論時間を短縮し、予測精度は medium なモデルを構築することを意図した設定です。もちろんこれらを変えることもできます。詳しくはこちら をご確認ください。
それでは、テストデータで推論を行い評価してみましょう。
さきほど fit() メソッドの結果を predictor という変数に格納したと思います。これは AutoGluon の TabularPredictor オブジェクトになっていて、predict() というメソッドで予測をしたり、evaluate_predictions() というメソッドで性能を確認したりすることができます。
ipynb
# predictor = TabularPredictor.load(dir_default) # 今回は不要ですが、過去に学習したモデルをファイルからロードする方法をお見せする目的でこのコードを追加しています。
y_pred = predictor.predict(X_test)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
print("Predictions:\n", y_pred)
クリックすると拡大します
5. fit() で行われたことや評価について
ここでは、fit() メソッドで行われたことについて見ていきたいと思います。
AutoGluon は、タスクを指定しなくても二値分類問題だと推論していました。
また、特徴量の種類も numerical か categorical かなどを自動で推論し、必要に応じて欠損値への対処や正規化を行います。
まずは、タスクや元の特徴量の種類をどのように推論したかを確認してみましょう。
ipynb
print("AutoGluonが推察した問題のタイプ:", predictor.problem_type)
print("AutoGluonが各特徴量に対して推察したデータの型:")
pprint.pprint(predictor.feature_metadata.to_dict())
クリックすると拡大します
fit() メソッドは TabularPredictor オブジェクトを返します。これは推論だけでなく、fit() の最中に何が起きていたかを確認するのにも使えます。
fit_summary() メソッドを使い、学習の過程においてどのような探索を行ったか、確認してみましょう。
ipynb
results = predictor.fit_summary()
クリックすると拡大します
学習したそれぞれのモデルについて検証データでの性能、学習にかかった時間などが表示されています。モデルの名前がいくつか表示されており、AutoGluon が様々なモデルを学習したことが分かります。
Types of models trained というところを確認すると、モデルのタイプは LGBModel などを含む複数のベースとなるモデルとそれらをアンサンブルしたモデルになっています。
※ ランダム性などのため実際に実行した際に上記と同一の結果となっていないかもしれません。
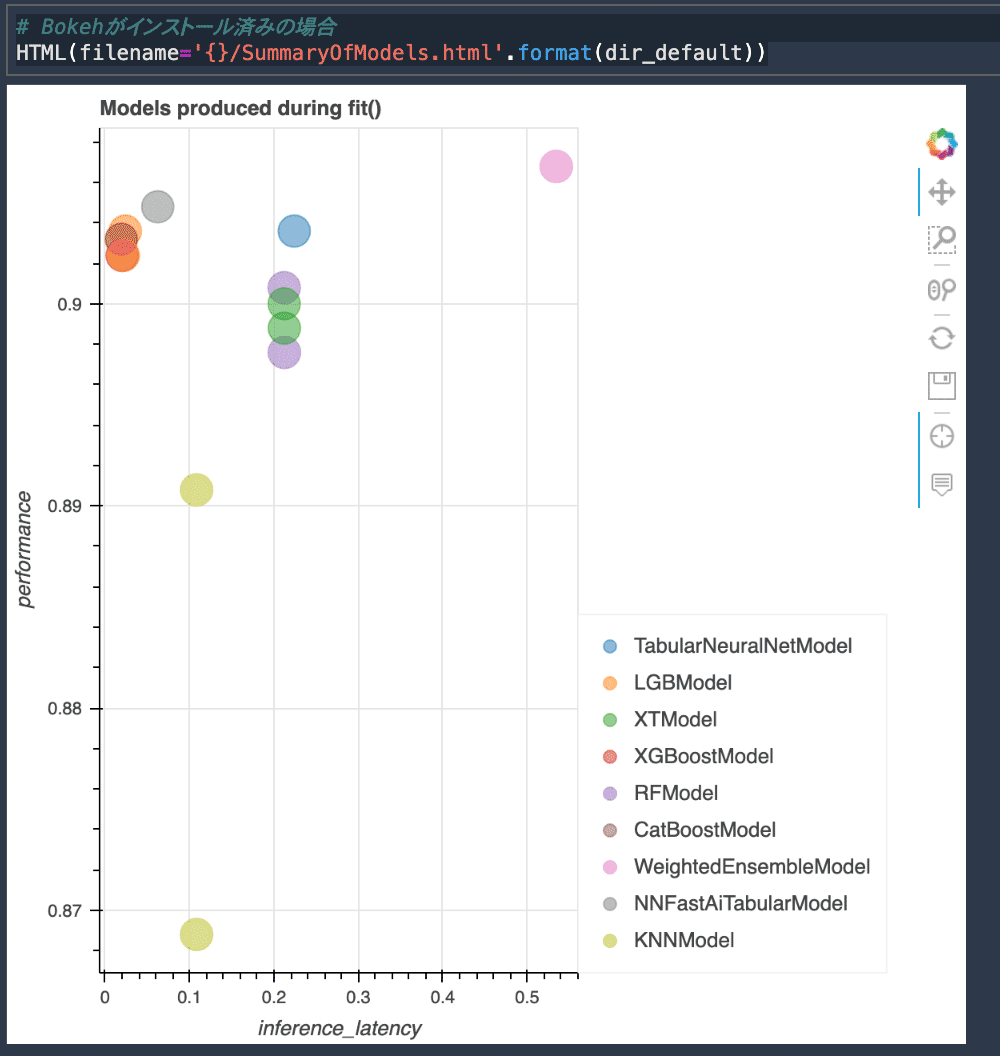
また、Bokeh がインストールされていれば、 path に指定したディレクトリに学習の結果が HTML ファイルとして保存され、その結果を下記のコードで表示できるかと思います。Studio ノートブックで、Python 3 (MXNet 1.8 Python 3.7 CPU Optimized) のカーネルを選択して頂いていれば、インストールされているかと思います。もし何も表示されない場合、もう一度クリックしてみてください。
ipynb
# Bokehがインストール済みの場合。
HTML(filename=f"{dir_default}/SummaryOfModels.html")学習したそれぞれのモデルについて、縦軸に性能 (今回は二値分類のデフォルトの性能指標の accuracy)、横軸に推論のレイテンシをマップした図が表示されているかと思います。今回は、モデルの精度としてはアンサンブルしたモデルが最も良いようです。
leaderboard() メソッドを使いテストデータを引数として渡すと、学習の過程で生成されたそれぞれのモデルについて、テストデータ、検証データでの性能、時間などが表示されます。
ipynb
model_perf = predictor.leaderboard(test_data, silent=True)
display(model_perf)
クリックすると拡大します
テストデータを渡さない場合、学習時の結果を表示してくれます。
fit_summary() より見やすいので、性能だけを確認したい場合はこちらの方が良いかもしれません。
predict_proba() メソッドを用いると、テストデータに対して各クラスの確率を出力することもできます。
ipynb
y_predprob = predictor.predict_proba(test_data)
display(pd.DataFrame(y_predprob,columns=predictor.class_labels))
クリックすると拡大します
predict() メソッドを実行すると、最良のモデルが使用されますが、どのモデルを利用するかを指定することもできます。
XGBoost のモデルを使って予測をしたい場合、このように、model という引数で指定するだけで実行できます。
ipynb
predictor.predict(test_data[:20], model="XGBoost")
クリックすると拡大します
6. カスタマイズを加える
ここでは、アンサンブルされたモデルの詳細を確認してみましょう。
先ほどと少し設定を変えて、性能の評価指標として roc_auc を指定してみましょう。
更に、モデルの詳細を出力するように verbosity を設定してみましょう。
ipynb
eval_metric = "roc_auc"
dir_auc = f"{dir_base_name}_auc"
predictor = TabularPredictor(label=label_column, path=dir_auc, eval_metric=eval_metric, verbosity=3).fit(train_data=train_data)
test_perf = predictor.leaderboard(test_data, silent=True)
display(test_perf)詳細なログが出力されており、たとえば、ニューラルネットワークでは、どの特徴量について one-hot エンコーディングをしたのか embedding したのかなどが分かります。

クリックすると拡大します
続いて、アンサンブルモデルを詳しく見てみましょう。
ipynb
ensemble = predictor._trainer.load_model("WeightedEnsemble_L2")
display(ensemble.get_info())最後に出力される model_weights から、今回は特定の種類のモデルしかアンサンブルで使用されなかったことが分かります。

クリックすると拡大します
7. 性能を重視する
スタッキングやバギングについて、オプションを細かく設定することもできますが、AutoGluon-Tabular を使うにあたって性能を重視する場合、まずは presets オプションの変更を検討してみるのが良いでしょう。
ここでは、そのような基本的な方針に従って精度を重視したモデルを構築してみます。
presets オプションで、best_quality を指定するというのが精度を重視しているときにまず推奨される方法です。
今回はチュートリアルであり長時間の学習を行わないよう、時間制限を設けて実行してみます。これは、time_limit オプションで設定することができます。今回は 5 分 = 300 秒に設定してみます。
ipynb
# 制限時間を設定する。
time_limit = 300
dir_best = f"{dir_base_name}_best"それでは下記を実行してみてください。
ipynb
%%time
predictor = TabularPredictor(label=label_column, eval_metric=eval_metric, path=dir_best).fit(train_data=train_data, presets='best_quality', time_limit=time_limit) 概ね time_limit に設定した制限時間内で実行されているかと思います。
それでは、テストデータ含め、モデルの性能を確認してみましょう。
ipynb
test_perf = predictor.leaderboard(test_data, silent=True)
display(test_perf)今回はデフォルト設定とあまり変わらない結果でした。
8. モデルの解釈
学習されたモデルの解釈を行います。
下記のメソッドで計算される特徴量の重要度スコアは、その特徴量がランダムにシャッフルされた場合の性能の低下度合いです。特徴量のスコアが高いほど、その特徴量がモデルの性能に重要であると考えられます。スコアがマイナスの場合、その特徴量がモデルの性能にとってマイナスである可能性があります。詳しくは こちら をご確認ください。
ipynb
feature_importances = predictor.feature_importance(test_data)
print("特徴量の重要度:")
display(feature_importances)こちらの上位の特徴量が予測に貢献していると考えられます。スコアがマイナスであるものはモデルの性能にマイナスの影響を与えている可能性があります。

クリックすると拡大します
9. モデルをデプロイする場合
モデルを実際にデプロイし運用していく際には、精度だけではなく、モデルのサイズ、推論のレイテンシなども重要になってくるかと思います。
いくつかの方法があります。
まずは、presets で計算コストを重視したオプションを検討するのが良いでしょう。optimize_for_deployment、medium_quality_faster_train、good_quality_faster_inference_only_refit などが候補になるでしょう。詳しくはこちら の presets に関する記述もご確認ください。
精度も重視したい場合、たとえば以下のように他の引数を調整してモデルサイズを小さくする方法もあります。
presets = "high_quality_fast_inference_only_refit"
keep_only_best = True
save_space = True10. ノートブックを停止する
AutoGluon ではまだまだカスタマイズできる点がありますが、今回は基本的な使い方を知っていただけたところで終わりとしたいと思います。Studio ノートブックが起動中は課金対象となるので、今回のチュートリアルを終えたらノートブックを停止しましょう。
こちらの RUNNNIG INSTANCES 名の右側にあるアイコンをクリックすることで、当該インスタンスを停止させることができます。

クリックすると拡大します
11. SageMaker の環境準備について
最後に、SageMaker を使った今回の環境のセットアップ方法を説明します。SageMaker のノートブックインスタンスや SageMaker Studio ノートブックを利用することができます。SageMaker Studo Lab でも環境設定すれば使えるでしょう。プルリクエスト がマージされています。
ノートブックインスタンスを利用する場合 :
Studio ノートブックを利用する場合 :
AWS コンソールで SageMaker を検索して SageMaker のページに遷移した後、左ペインの Amazon SageMaker Studio をクリックするとこちらのような画面が表示されるかと思います。

クリックすると拡大します
「デフォルトの実行ロール」をクリックして表示される画面で、こちらのように「指定する S3 バケット」で「任意の S3 バケット」にチェックして、右下の「ロールの作成」をクリックして下さい。

クリックすると拡大します
Studio のセットアップに数分時間がかかるかと思います。このセットアップは Studio を最初にセットアップするときだけ必要なものです。セットアップが完了したらこちらのように、作成したユーザーの右側にある「アプリケーションを起動」をクリックして「Studio」を選択してクリックして下さい。

クリックすると拡大します
しばらくこちらのような画面が表示されるかと思いますがお待ちください。

Studio に遷移したら、こちらのように上の 「FIle」メニューから「New」をクリックして、「Notebook」をクリックして下さい。

クリックすると拡大します
イメージやカーネルを選択するこちらのような画面が表示されるかと思います。
「Image」は MXNet 1.8 Python 3.7 CPU Optimized を選択し、「Kernel」は「Python 3」を選択し、右下の「Select」をクリックしてください。

クリックすると拡大します
ノートブックが開きますが、インスタンスのタイプを変更するために、右上にある「2 vCPU + 4 GiB」をクリックして下さい。

クリックすると拡大します
こちらのような画面でインスタンスタイプを選択できます。「Fast Launch Only」のチェックを外して、表示させるインスタンスタイプを増やしましょう。

クリックすると拡大します
インンスタンスタイプは今回は ml.m5.xlarge を選択しました。右下の 「Save and continue」をクリックしてください。
インスタンスの変更を行なうので、しばらく時間がかかります。変更が終わり、右上の表示が「4 vCPU + 16 GiB」に変わったら、準備完了です。今回解説したコードをこのノートブック上で実行いただけるでしょう。
12. おわりに
今回は SageMaker のノートブックで実行する方法をご紹介しました。しかし、プロダクション環境でデプロイする場合や、様々な実験条件で試行錯誤を行う際の時間を削減するためにクラウドのリソースを柔軟に活用したいといった場合、コンテナ化したい状況が出てくるかと思います。SageMaker で利用できる コンテナイメージ が公開されていますので、コンテナイメージを活用する方法については こちら や こちらのブログ記事 をご参照ください。
AutoGluon の詳細については、論文 や 公式ドキュメント、GitHub のレポジトリ の他、国際会議 (ICML) での AutoML に関するワークショップ でのいくつかの発表や、国際会議 (KDD) でのチュートリアル、国内イベント などありますので、ご興味を持たれた方はそちらも合わせてご参照いただければと思います。
本記事が皆様の機械学習の活用の一助となれば幸いです。
脚注 :
※ 公式ドキュメント の記述にあるとおり、Experimental モデルのオプション では、テキストとテーブルデータを合わせたマルチモーダルな設定や、Tabular Transformer を利用することができます。
※ こちらのページ の「Details regarding the hyperparameters you can specify for each model are provided in the following files」という箇所で、各モデルについて、参考URLが記載されています。
※ AutoGluon については活発な OSS 活動が行われており、日々さまざまな改善が行われていますので、最新の情報は上記公式ページをご確認ください。
筆者プロフィール

藤川のぞみ
アマゾン ウェブ サービス ジャパン合同会社
機械学習スペシャリスト ソリューションアーキテクト
機械学習の研究で博士号を取得後、企業研究所や大学などでの研究職を経て 2020 年から現職。
好きなものは珈琲とジャズと山。
AWS を無料でお試しいただけます