- AWS Builder Center
- builders.flash
AWS アーキテクチャで学ぶ The Twelve Factors App 本格入門
2022-08-02 | 新井 雅也 (株式会社野村総合研究所 / AWS Container HERO)
はじめに
こんにちは。AWS Container Hero の新井です。
本日は、AWS 上のモダンなワークロードを実現する上で代表的な Amazon ECS と AWS Fargargte を主軸としたアーキテクチャを前提に、優れたソフトウェア開発を支える方法論である「The Twelve-Factor App」をご紹介します。
builders.flash メールメンバー登録
1. The Twelve-Factor Appとはなにか ?
The Twelve-Factor App (以降、「12FA」といいます) とは、Heroku の共同創設者である Adam Wiggins 氏が提唱した、優れたソフトウェアを開発するための方法論です。
2011 年頃に提唱されてからすでに 10 年以上経過していますが、クラウド上の分散アーキテクチャとしてソフトウェアを開発する上で、12FA はアプリケーションの移植性を最大化し、継続的なデプロイを可能とし、レジリエンスや堅牢性を高めるための優れたプラクティスとして、今でも多くの開発者に親しまれています。
2016 年に開催された AWS re:Invent では、Amazon CTO の Werner Vogels 氏による キーノートスピーチ においても、ソフトウェア開発の変革に必要かつクラウドの利点を最大化するためのベストプラクティスとして 12FA が紹介されています。
その名のとおり、12FA は、次の 12 の項目から成るプラクティスで構成されています。
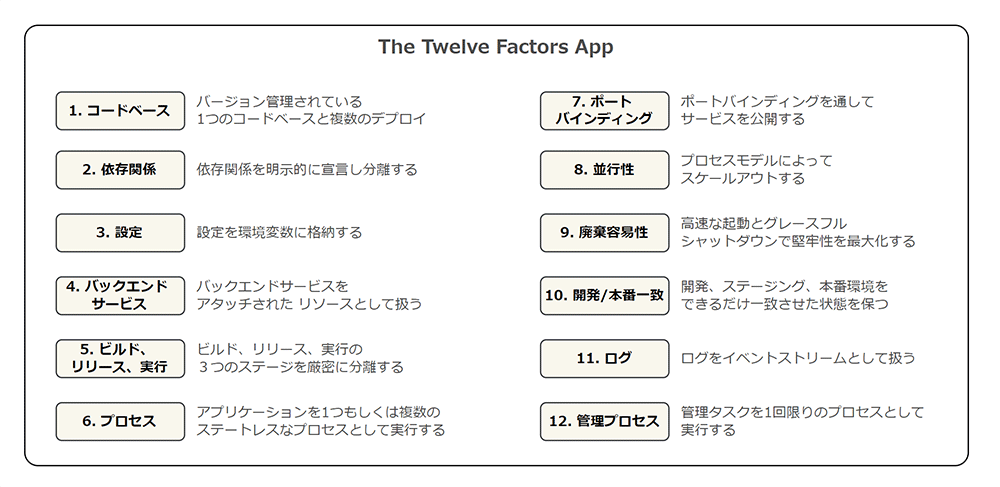
2. なぜ、12FA を解説するのか ?
読者の皆さまの中には、12FA について聞いたことがある、もしくは内容に触れたことがある方も多いのではないでしょうか ?
原文を読んでみるとわかりますが、12FA は方法論であり、特定の開発言語に依存しないように記述されています。
そのため、ぱっとみ内容が抽象的でわかりにくいと感じた方も多いのではないでしょうか (少なくとも、筆者は初見で内容を十分に理解できませんでした)。
また、12FA はベストプラクティスそのものが中心に記述されており、「なぜその方法が良いとされているのか ?」という点について、十分触れられているとは言えません (読み手のアーキテクチャやビジネスニーズによって、「ベスト」の解釈が多少異なる背景を考慮しているのだろう、と推察しています)。
そこで本投稿では、この抽象的で少々とっつきにくい 12FA に関して、Amazon ECS / AWS Fargate を軸としたコンテナワークロードを前提に、「なぜそのプラクティスが優れているものと解釈され、そしてどのような課題を解決するのか」という点について、できるだけ丁寧に解説してみたいと思います。
具体的には、12 項目それぞれに対して、What (どういうプラクティスか ?)、Why (なぜ、それが求められるのか ?)、How (AWS 上で実践する場合、どうすればよいか ?) の観点で説明します。
12 項目に対して 1 つずつ説明及び考察しているため少々長い記事となりますが、お時間ある方や内容にご興味ある方はぜひお付き合いください。
3. 対象者
- Amazon ECS / AWS Fargate によるアプリケーションを運用しており、開発プラクティスを見直したい方
- 12FA について理解を深めたい方
4. 前提
- AWS 上での主要なワークロードである Amazon ECS / AWS Fargate を中心としたアーキテクチャを前提とします。
- 各プラクティスの解釈は読者のビジネス要件により変わります。本稿の内容はあくまでも代表的な一例としてお考えください。
5. 各プラクティスの解説
5-1. コードベース (Codebase)
What
「コードベース」では、コード (それを保持するリポジトリ)とアプリケーションは常に「1:1」の関係であるべき、と定義されています。
図で示すと、次のようになります。
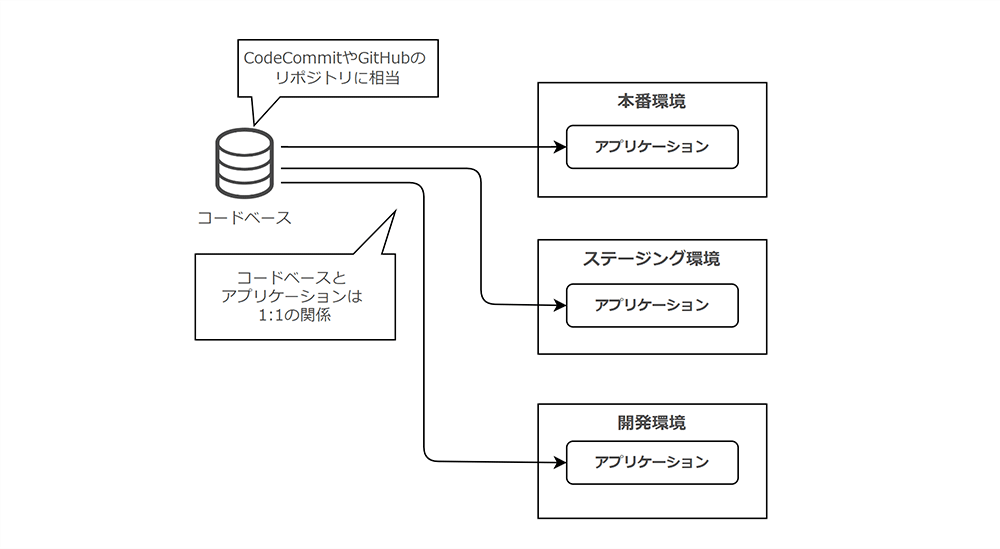
Why
なぜ、「コードとアプリケーションの関係性を 1:1 に保つべき」なのでしょうか ?
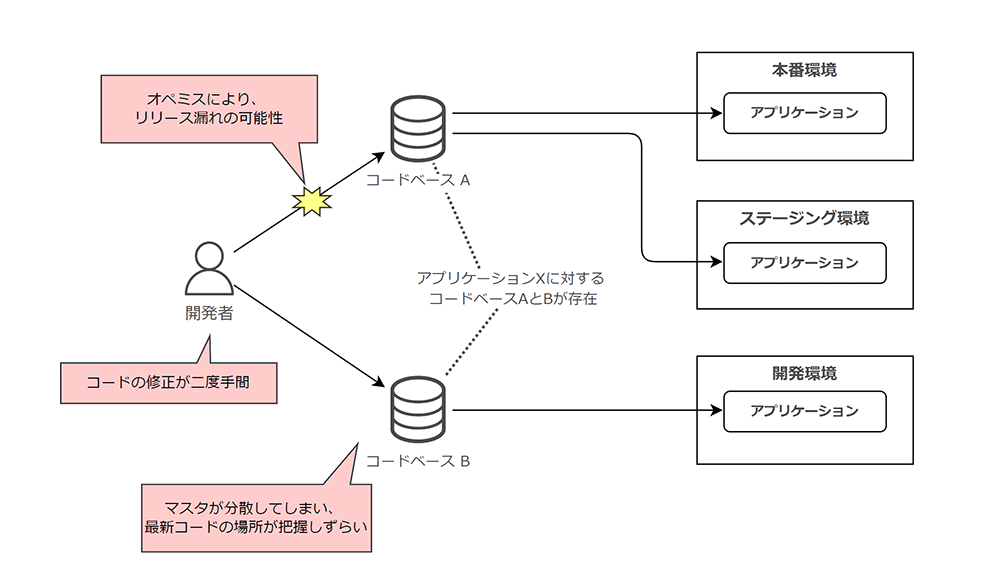
この点を理解するためには、「コードとアプリケーションの関係性が N:1 である」ケースを考えてみると理解しやすくなります。次のような例を考えてみましょう。
まず、「コードとアプリケーションの関係性が N:1 である」ということは、コードを管理するマスタが複数存在することになります。そのため、開発者はどのコードベースに最新のコードが格納されているかわかりづらくなります。
また、開発者は複数のコードベースに対してコードを反映する必要があり、二度手間になります。
さらには、一部のコードベースに対するオペミス (更新漏れ等) により、アプリケーションのリリース漏れが発生してしまう可能性もあるでしょう。
アプリケーションのコードベースを単一にすることで、環境間の差異を最小限にし、開発アジリティを高めることに寄与するのです。
How
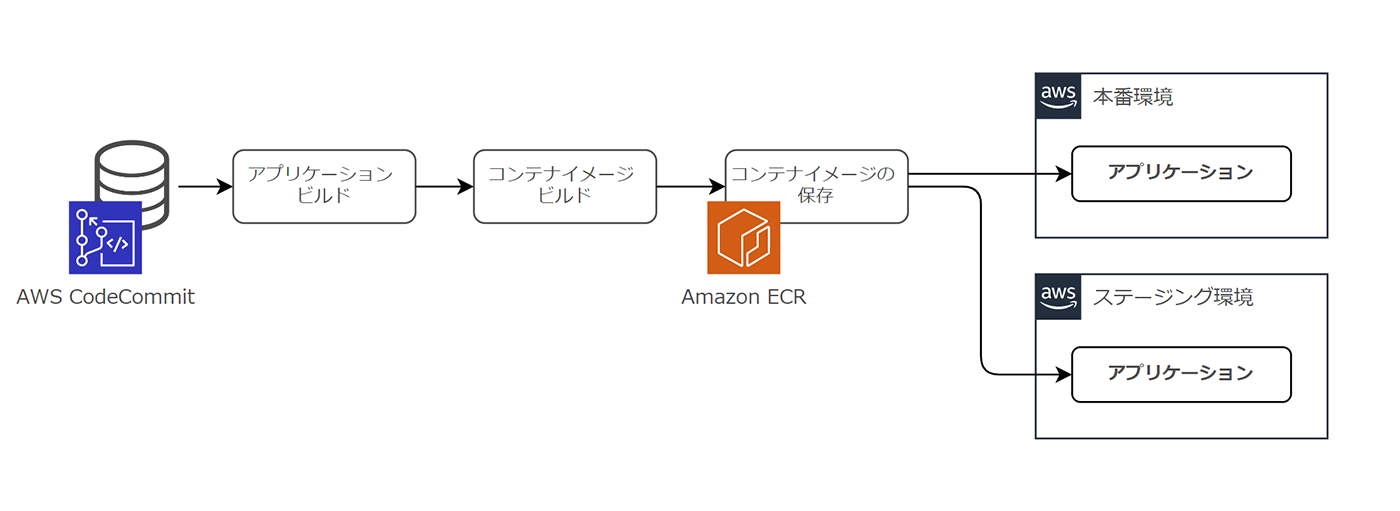
コードリポジトリとして AWS CodeCommit を利用する場合、AWS CodeCommit のリポジトリをコードベースとみなし、アプリケーションと 1:1 で定義することで実現できます。
ここで、コンテナワークロードを扱う場合に考慮すべきことがあります。それはコンテナイメージの保存です。
コンテナワークロードでは、アプリケーションを同梱してコンテナをビルドし、イメージレジストリ内のリポジトリ上にコンテナイメージを保存します。コンテナイメージを格納するサービスとして Amazon ECR を利用することが多いでしょう。
ビルドされたコンテナイメージは、Amazon ECR 内リポジトリにてタグが付与されることでバージョン管理されています。
コンテナのイメージが異なれば、アプリケーションライブラリやOSネイティブライブラリのバージョンが異なる可能性があります。
そのため、理想的にはコンテナリポジトリをコードベースみなし、環境ごとに同一イメージを利用することが、差異をより小さくできるといえるでしょう。
この点については、ビジネス上の要件やブランチ戦略など自分たちが重視する開発プラクティスと大きく関わるテーマとなります。
5-2. 依存関係(Dependencies)
What
「依存関係」では、アプリケーション内で利用されるライブラリ等の依存関係を明示的に宣言し、その定義を分離するべき、とされています。
具体的には、次のように依存関係を定義したファイルと管理ツールを利用し、定義に従ってライブラリを取得することで、アプリケーションの可搬性や動作保証を高めることができます。
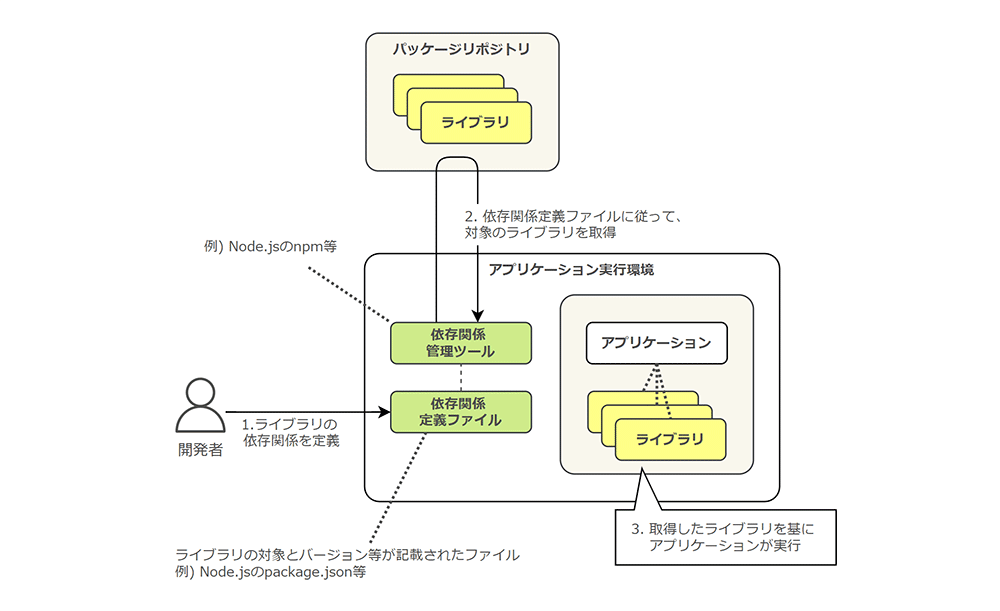
Why
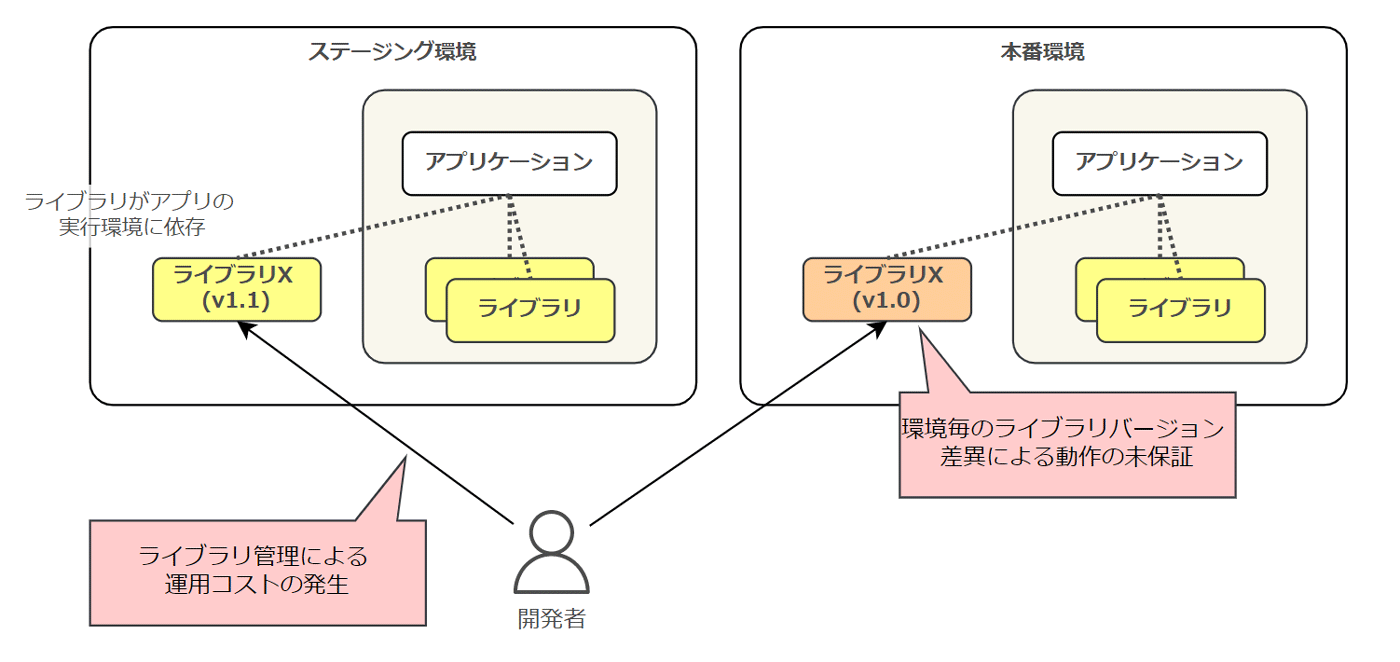
アプリケーションの依存関係を定義ファイル上に対して明示的に宣言せず、実行環境に依存したライブラリを利用した場合、実行環境毎にライブラリのバージョンが異なったり、存在しないライブラリを参照してしまう可能性があります。
そのような状況下においては、アプリケーション動作に差異が生じてしまい、品質が保証されません。
また、ライブラリが実行環境に依存している場合、開発者が該当するバージョンのライブラリを都度取得し、実行環境上に配置するという運用上の手間も発生してしまいます。
アプリケーション開発のアジリティを高めることができないだけでなく、オペミスによりライブラリのバージョン差異が発生してしまう可能性もあります。
How
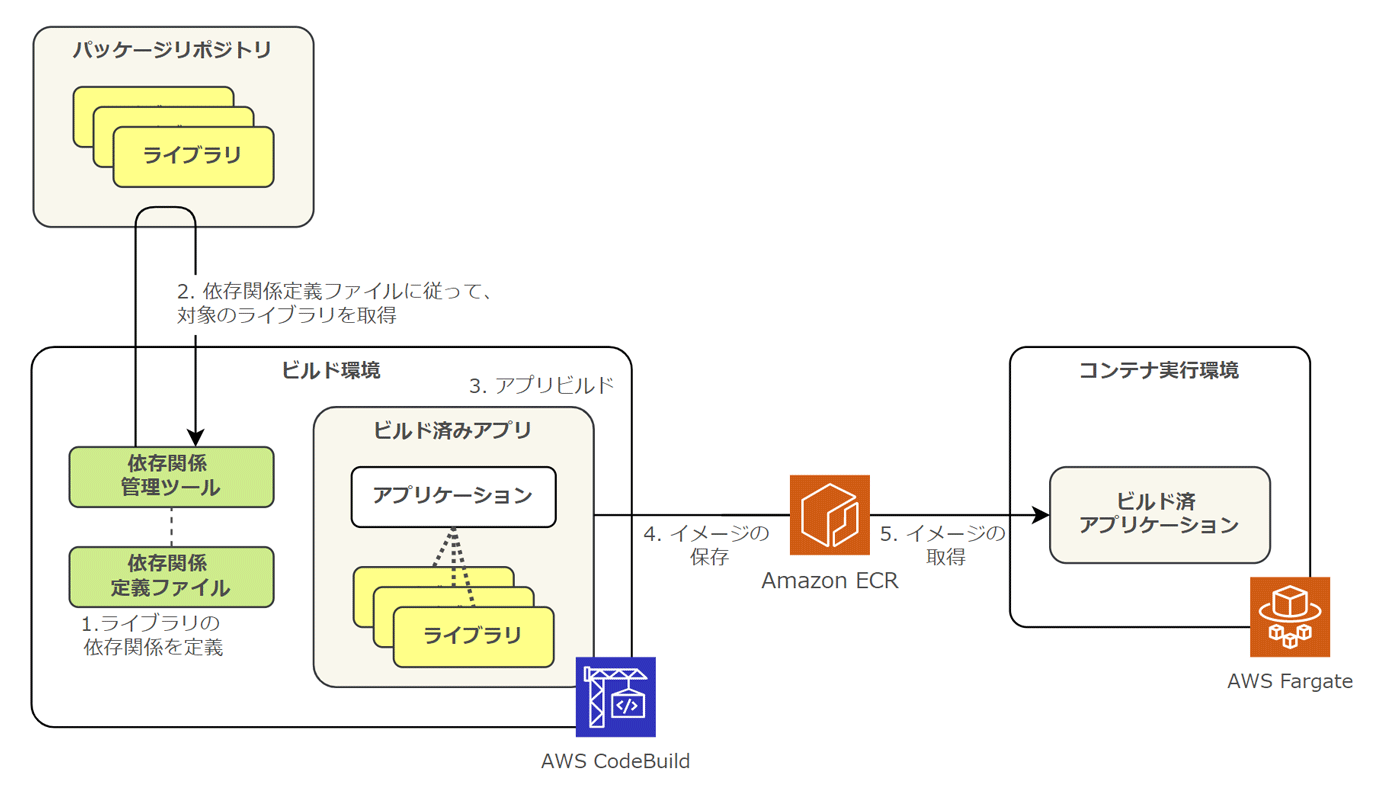
どのような実行環境においても依存関係が常に一致するように、アプリケーションの開発言語で用意された依存管理の仕組みを利用しましょう。
AWS 上では、AWS CodeBuild 内のビルドタイミングで依存関係管理ツールを実行し、適切なライブラリを取得することで、依存関係を維持することができます。
一方、コンテナアプリケーションにおいては、アプリケーションだけでなくコンテナのイメージビルドも必要です。
コンテナイメージを生成する際に必要となる Dockerfile 内に、ベースイメージやランタイム、OS 上のネイティブライブラリ等を定義しますが、これらに関してもアプリケーションを実行するために必要な依存関係となります。
コンテナ技術により、アプリケーションの稼働に関する依存関係がより適切に管理できるようになったと言えるでしょう。
一方、ベースイメージを latest として定義する場合、OS 上のネイティブライブラリ (例として openssl 等) のバージョンを指定しない場合、常に最新のバージョンが取得されてしまい、依存関係の相違が発生する要因となります。
この点は、アプリケーションの動作保証に影響を及ぼす可能性があります。運用負荷とのバランスを見極めつつ、アプリケーションの依存関係を管理しましょう。
5-3. 設定 (Config)
What
「設定」では、開発環境やステージング環境など、環境毎に異なるアプリケーションの設定値はコード上から分離すべき、と定義されています。
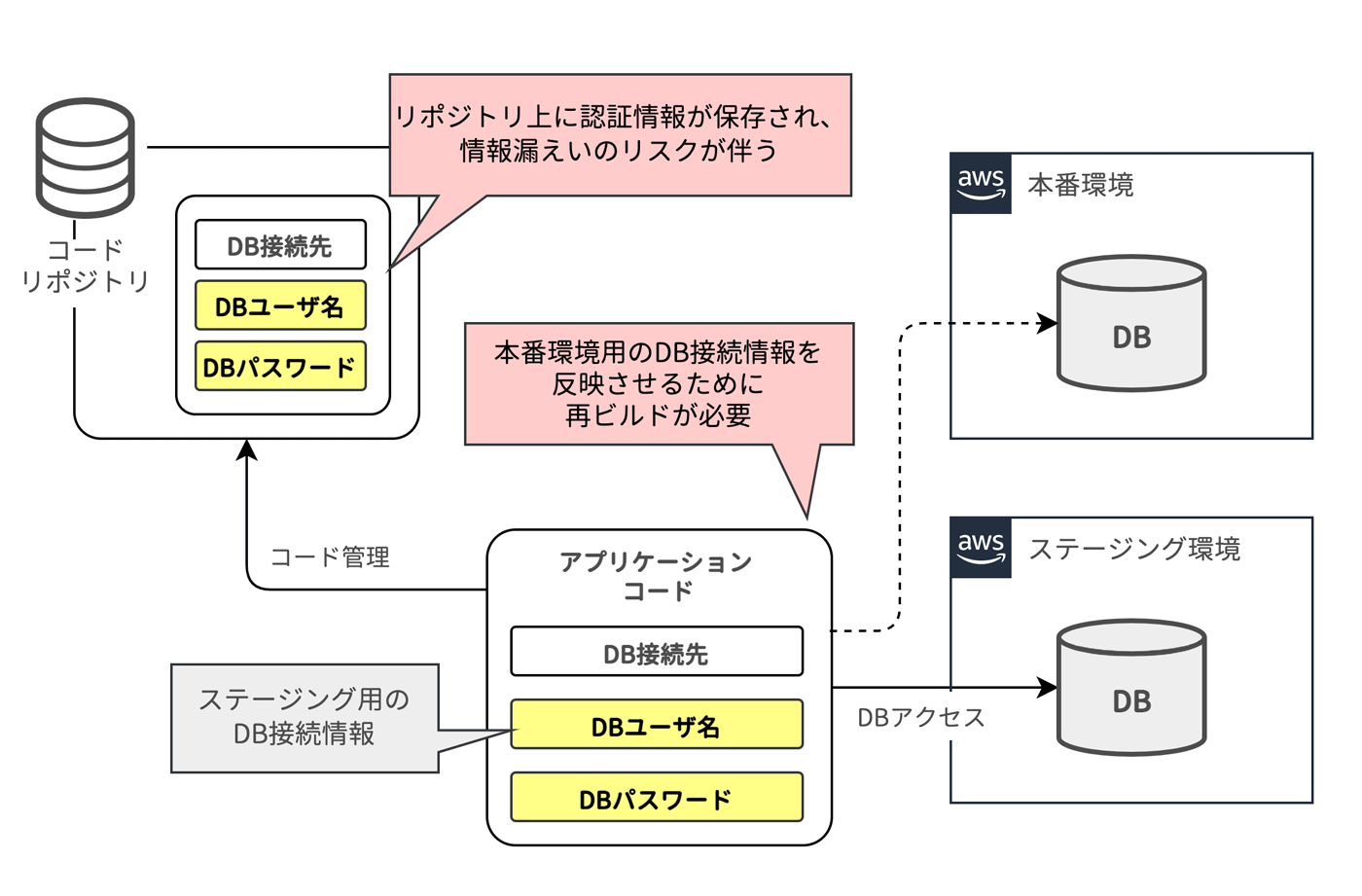
例えば、データベースへの接続ホスト名や認証情報などの設定値は、コードの外から与えることが推奨されています。
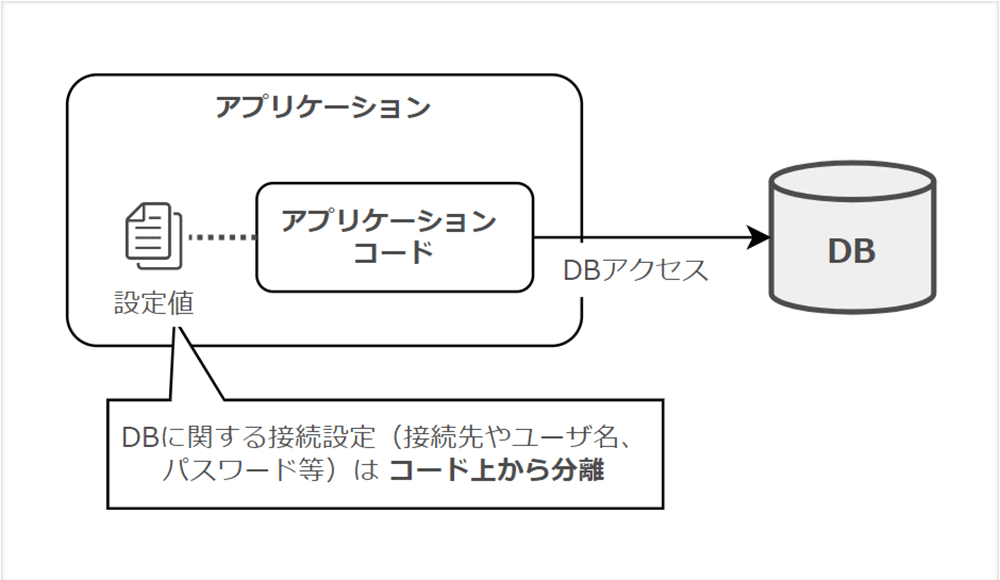
Why
設定をコード上に埋め込んだ場合、環境ごとにアプリケーションをビルドしなければなりません。また、ステージング環境でテストしたアプリケーションを本番環境用にもう一度ビルドすることになり、アプリケーションは別のバイナリとなってしまうため、ステージング環境で確認したテストが厳密に保証されるわけではありません。
また、例として挙げたデータベースの認証情報をコード上に埋め込んでしまうと、コードを保存するリポジトリ上に機密情報が保持されてしまいます。この点はセキュリティ観点上からも望ましくありません。
How
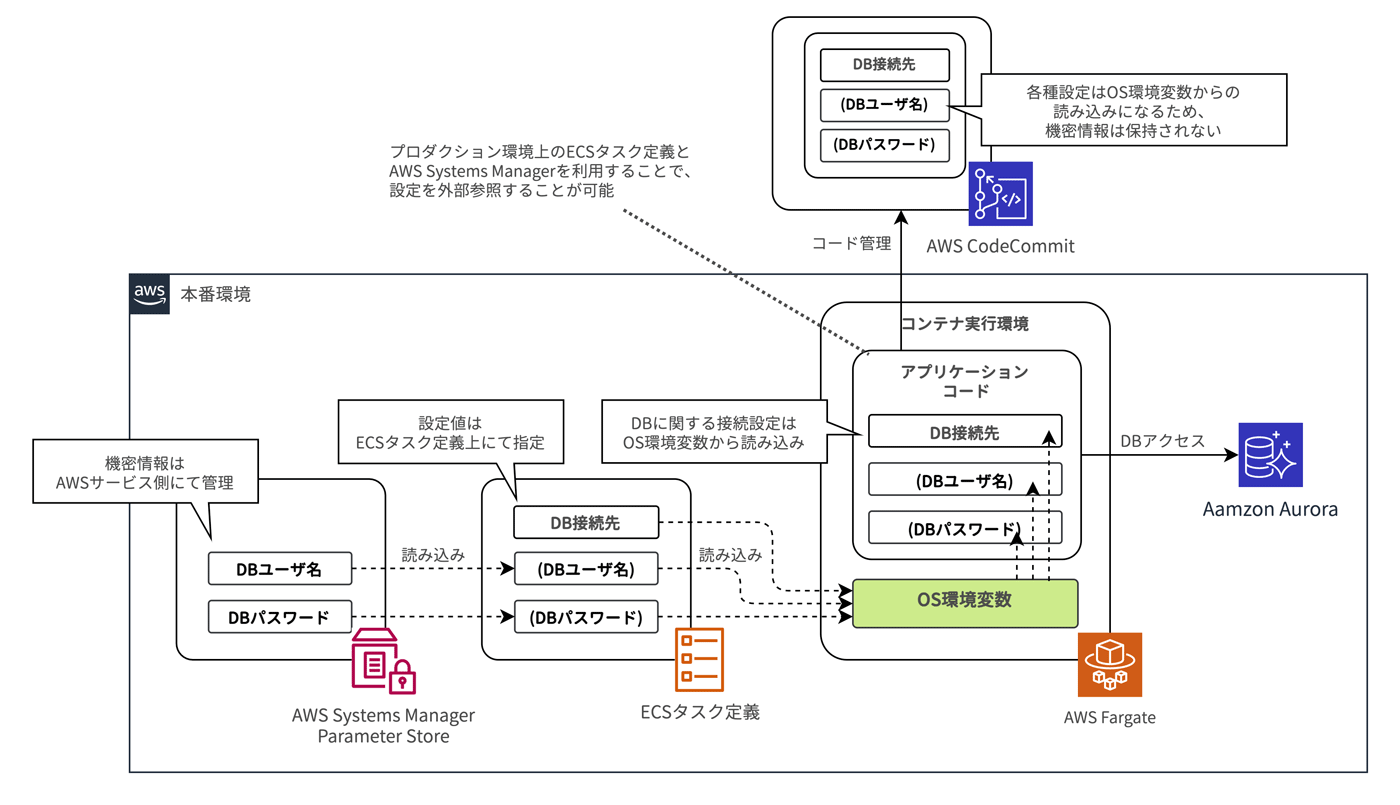
Amazon ECS では ECS タスク定義内のコンテナ定義パラメータとして環境変数を指定 できます。環境毎に異なる設定値はコンテナ定義パラメータとして記述し、アプリケーションコード上から環境変数を読み込むことで、設定を外部に持たせることが可能です。
このようにすることで、環境ごとにアプリケーションのビルドは不要となり、環境間のアプリケーションに対する可搬性を高めることができます。
さらに、コンテナ定義パラメータはセキュリティ情報を安全に管理する AWS Systems Manager Parameter Store (Secure String) や AWS Secrets Manager 上の定義を参照できます。機密情報に該当する情報はこれらサービスに保持することで、安全な情報の受け渡しを実装できます。
5-4. バックエンドサービス (Backing services)
What
「バックエンドサービス」では、ネットワーク越しに利用するサービスは、アプリケーション上のリソースとして考えることでコードを変更することなく切り替えられるべき、とされています。
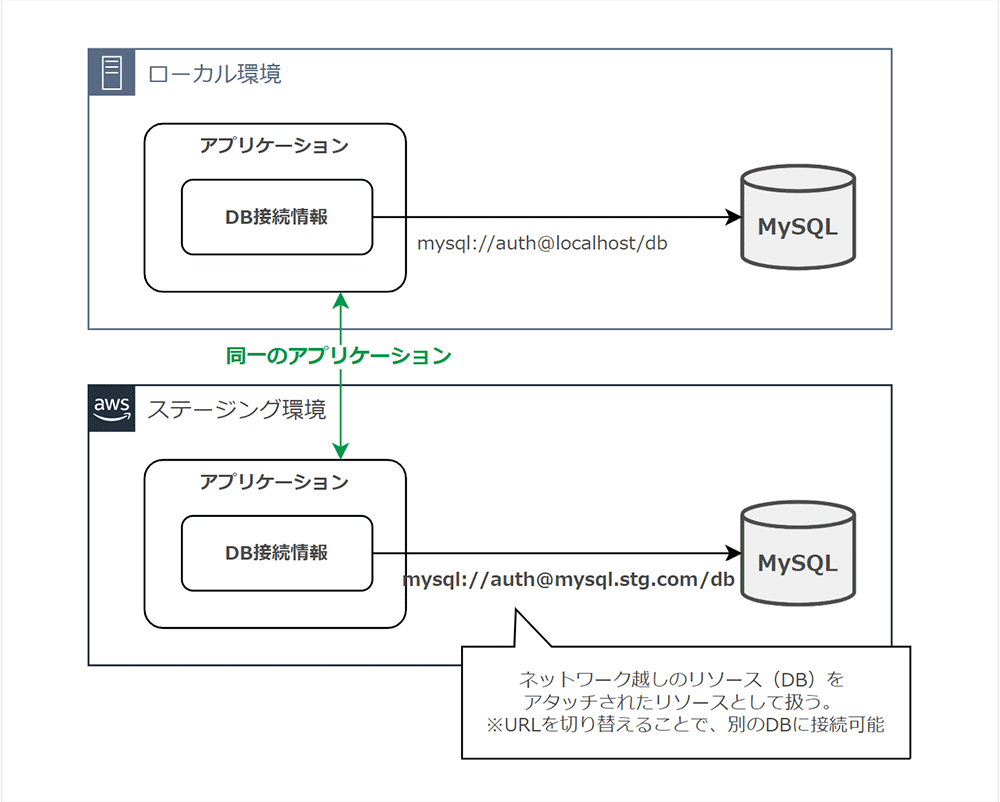
次の例では、アプリケーションからデータベースへの接続に関して URL を変更することで、コード自体を変更することなく連携先を切り替えできます。
Why
アプリケーションを開発する際、開発者のローカル PC 上にデータベースを構築し、開発中のアプリケーションから接続するケースを考えてみましょう。
ローカル PC 上のデータベースの接続先がコード上に直接埋め込まれている場合、ステージング環境へのデプロイ時にどうなるのでしょうか ?
「8. 設定 (Config)」でも触れたとおり、接続先を切り替えるためにコードを書き換え、アプリケーションの再ビルドが必要です。
ローカル PC 上のデータベースもステージング環境のデータベースも、それぞれ 1 つのリソースとして URL として扱い、かつ URL を設定値として環境変数化しておくと、切り替え時においてもアプリケーションのコード自体の変更は不要です。
すなわち、環境に依存しない疎結合なアプリケーションコードとなり、可搬性が高めることができるのです。
How
Amazon Aurora や Application Load Balancer (ALB) を介した ECS タスクなど、ネットワーク越しに利用するサービスは設定値として定義しましょう。また、それら設定が環境毎に異なる場合、「8. 設定 (Config)」にて述べたとおり、ECS タスク定義内のコンテナ定義パラメータとして環境変数化することで、コードを変更することなくこれら差分を吸収することが可能です。
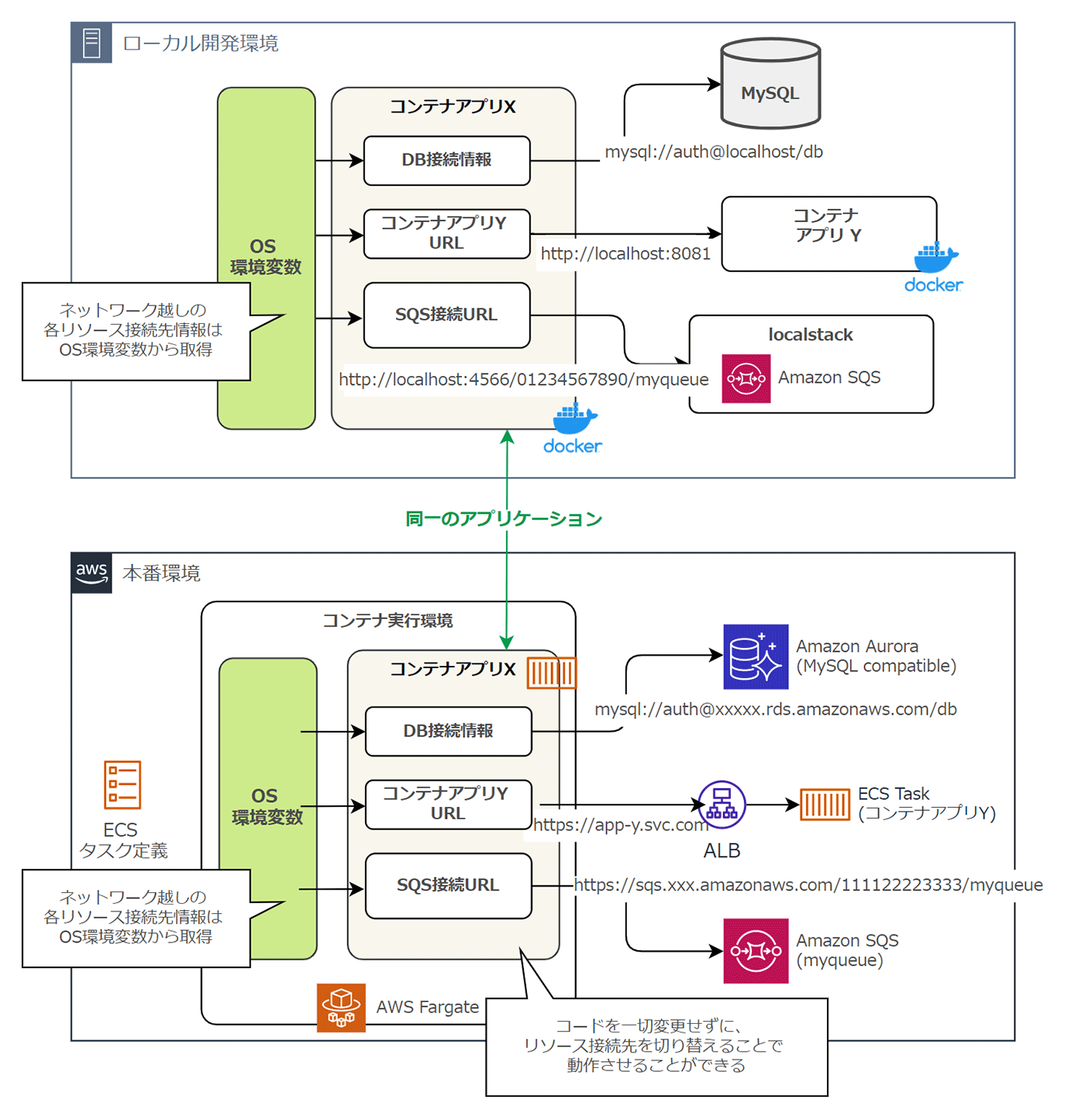
例えば、Fargate 上のコンテナから Amazon SQS のキューにリクエストする処理を考えましょう。このケースでは、Localstack を利用することで、開発者がローカル PC 環境上で SQS に関する処理を開発できます。
設定により、SQS のリクエスト先URLを切り替えることで、コードを変更することなく、シームレスにステージング環境上で動作させることも可能です。
5-5. ビルド、リリース、実行 (Build, release, run)
What
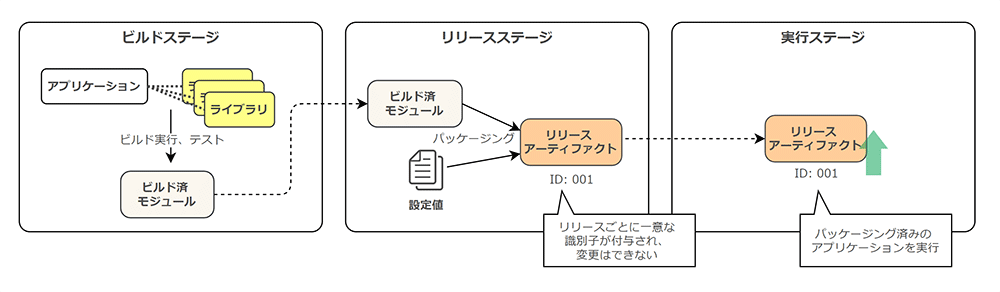
「ビルド、リリース、実行」では、アプリケーションはコードベースから厳密に分離されたビルドステージ、リリースステージ、実行ステージを経て本番環境にデプロイされるべき、とされています。具体的に、各ステージは次のように定義されています。
-
ビルドステージ : アプリケーションと関連するライブラリ等から、実行可能なバイナリが生成されるフェーズ
-
リリースステージ : ビルドステージで作成された実行バイナリに対し、必要な設定情報を追加してパッケージングするフェーズ
-
実行ステージ : リリースステージで作成されたパッケージを選択し、プロセスとして実行環境上にデプロイさせるフェーズ
ここでリリースステージでは、パッケージ毎に一意な識別子を付けて管理されます。
また、一度作成されたパッケージの変更は許容されません。そのため、設定情報等の変更が必要になる場合は、再度リリースステージでパッケージングが必要となります。
実行ステージでは、ビルドステージやリリースステージと異なり、何らかの変更を加えることは避けるべきとされています。まとめると、次のようになります。
Why
そもそもなぜ、「ビルド」、「リリース」、「実行」を厳密に分ける必要があるのでしょうか ? まずは、「ビルド」と「リリース」の分離に関する理由を推察してみます。
ビルドステージではアプリケーションに必要なライブラリ追加などの "変更" が加わることを前提とし、テストが実行されるフェーズです。
仮に、リリースステージにおいてもアプリケーションに対する"変更"を許容してしまうと、ビルドステージで生成済みのバイナリの稼働性が保証されません。
そのため、アプリケーションの変更が許容されるフェーズ (=ビルドステージ) と、アプリケーションの変更は許容されずに環境毎に必要な差分のみが適用されるフェーズ (=リリースフェーズ) に分離すべきなのです。
次に「リリース」と「実行」の分離に関する理由を考えてみます。
仮にアプリケーションが稼働する実行環境が何らかの要因でクラッシュし、その後に再起動が必要となった場合、パッケージング済みのアプリケーションが再度実行されることが理想です。
同じ条件下の起動が望ましく、わざわざ設定値を再度追加する必要はありません。
アプリケーションに対する可変処理を排除する (シンプルに実行のみを行う) ことで再起動時の同一動作が保証され、復旧の自動化が可能となるのです。
How
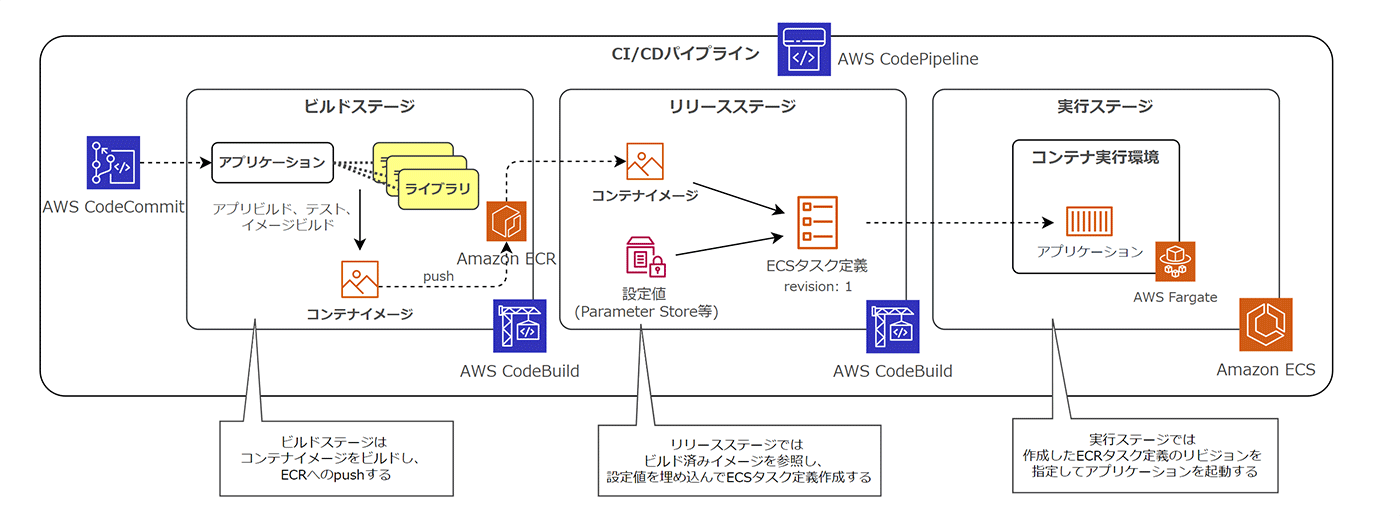
AWS では Code シリーズと呼ばれる各種サービスを活用することで、「ビルド、リリース、実行」のプラクティスを実現できます。具体的には、AWS CodePipeline や AWS CodeBuild を組み合わせることで、ビルドステージやリリースステージ、実行ステージを分離して定義できます。
Amazon ECS を利用している場合、各ステージは以下のような処理にマッピングできます。
-
ビルドステージ : アプリケーションのビルド、テスト、及びコンテナイメージのビルドとAmazon ECRへのイメージプッシュ
-
リリースステージ : Amazon ECS のタスク定義作成 (ビルド済みコンテナイメージを指定し、新しいリビジョンによるタスク定義生成)
-
実行ステージ : Amazon ECS により、Amazon Fargate 上にタスクをデプロイ
このように、AWS の各種サービスを組合わせることで、「ビルド、リリース、実行」のステージを厳密に分離しつつ設計できました。
このプラクティスは、各ステージが求められる背景と対応するための実現方法が割と混乱しがちです。ステージ毎に要点を整理して、アプリケーションを開発するように心掛けると良いでしょう。
5-6. プロセス (Processes)
What
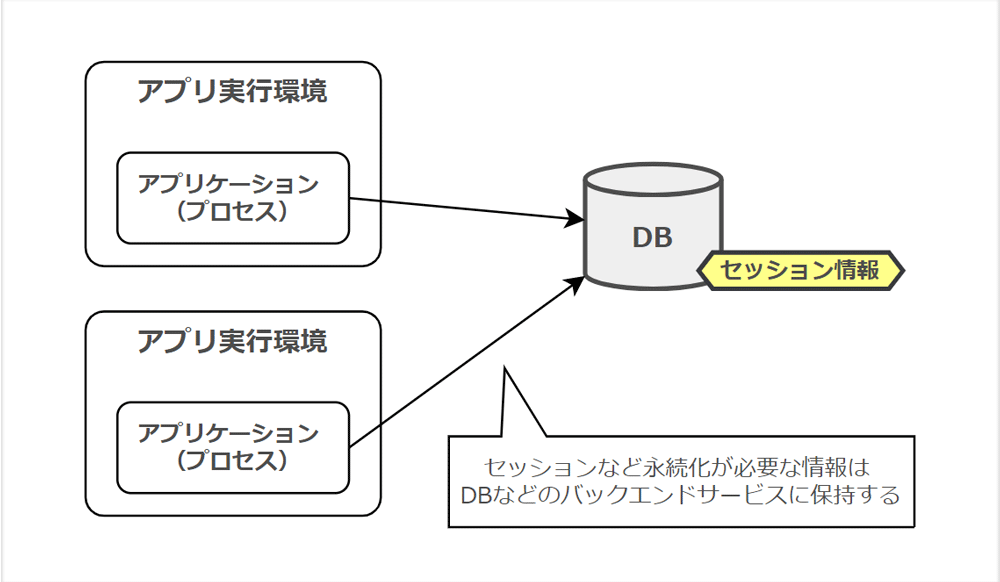
「プロセス」では、アプリケーションは 1 つもしくは複数のステートレスなプロセスとして実行すべき、と定義されています。
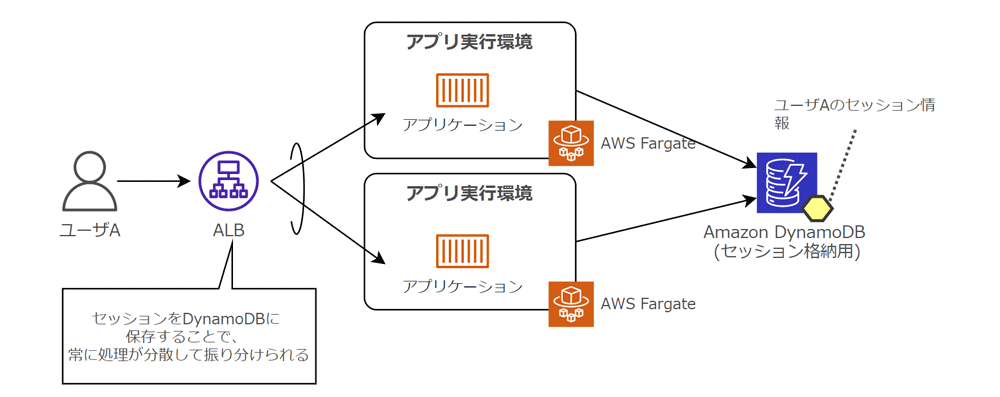
ユーザーのセッション情報などは、アプリケーション実行環境上に保存せず、独立したデータストア上に保持することで、ステートレスに扱えます。
Why
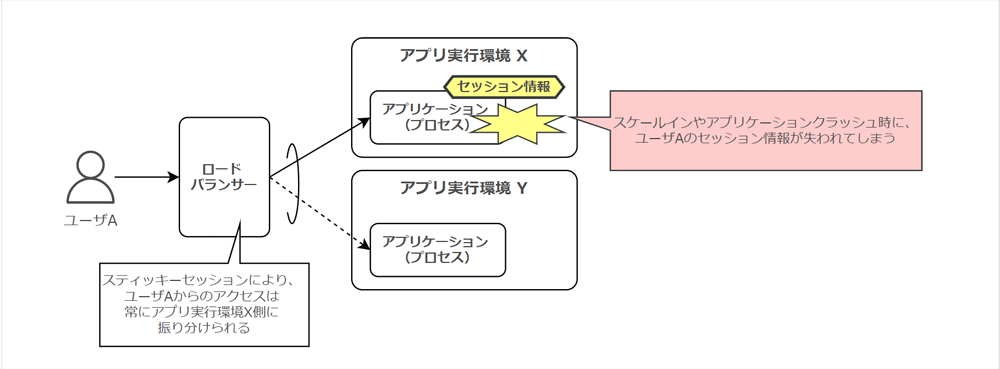
アプリケーションをステートフル (セッション情報をアプリケーション実行環境上に保持) なプロセスとして扱う場合、どのような弊害が生じるのでしょうか ?
ステートフルなアプリケーションである場合、スケールアウト時には既存のセッションを有するリソースに対して、リクエストを振り分けなければなりません。このような構成では、負荷が正しく分散されず偏ってしまいます。
また、スケールイン時に関しては、アプリケーション実行環境が停止するため、同時にセッション情報が失われてしまいます。アプリケーションがクラッシュして実行環境が停止した場合においても、同様にセッション情報が失われてしまうでしょう。
How
Amazon ECS / AWS Fargate を利用するワークロード上で永続化が必要な情報は、Amazon ElastiCache や Amamzon DynamoDB、Amazon RDS 等のバックエンドサービスに保存しましょう。
特にセッション情報に関しては、ALB のスティッキーセッション機能は利用せずに、バックエンドサービスに保持しましょう。
このような構成とすることで、スケールインやクラッシュ、ECS タスクの置き換え時においても情報が失われることはなく、処理を継続できます。
5-7. ポートバインディング (Port binding)
What
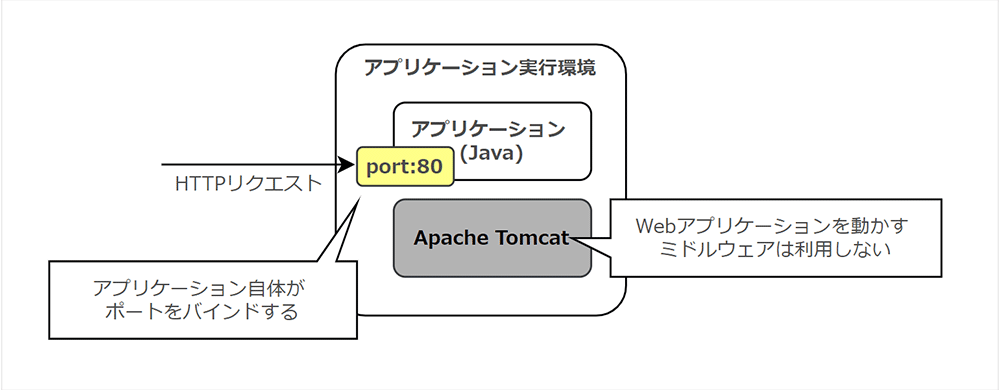
「ポートバインディング」では、アプリケーション自体がポートをバインドして Web アプリケーションとして公開できるようにすべき、とされています。
言い換えれば、12FA では Apache や Tomcat といったような Web サーバーを担うソフトウェアを利用せず、アプリケーション自身がポートを持っている状態とすべき、ということです。
Why
Web サーバーを担うミドルウェアを必要とせずにアプリケーション自身がポートをバインドできるようにすることで、必要な依存関係を減らすことができます。
また、管理すべき要素も少なくなるため、構成管理がシンプルになります。
さらに、ミドルウェアの導入作業やプロセス立ち上げも不要となり、サービス立ち上げの高速化が期待できます。アプリケーション単体で他のアプリケーションの「バックエンドサービス」として担うことも容易となります。
比較的新しく登場した開発言語では、Web サーバー機能を持つライブラリが提供されており、アプリケーション自体がポートをバインディングできるケースも多いでしょう。
How
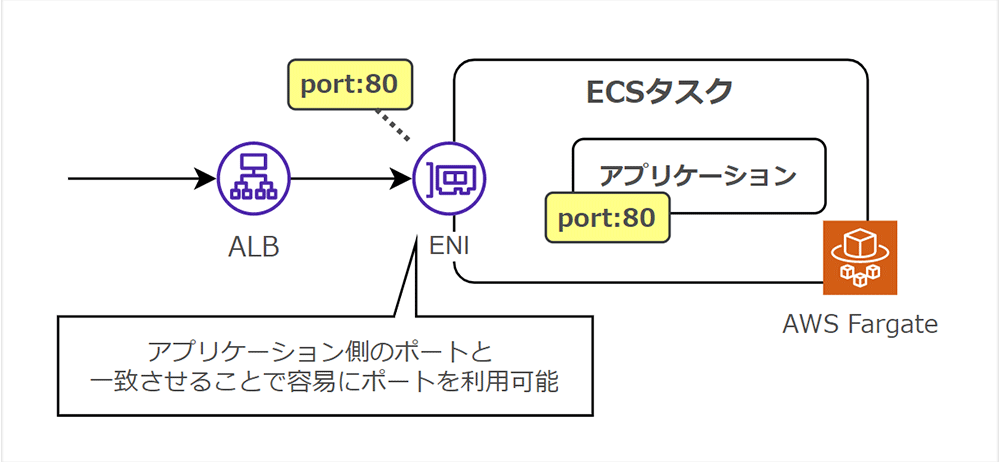
Fargate 上で稼働するアプリケーションでは、各 ECS タスクごとに独自の ENI (Elastic Network Interface) が割り当てられます。ENI により、ECS タスクが直接IPアドレスを持てるようになります。
タスク定義にてアプリケーションのポート番号を指定することで、ECS タスクに対してポートがバインディングされます。
5-8. 並行性 (Concurrency)
What
アプリケーションはリクエストの需要に応じて、適切なコンピューティングリソースを与えることで処理が継続できます。
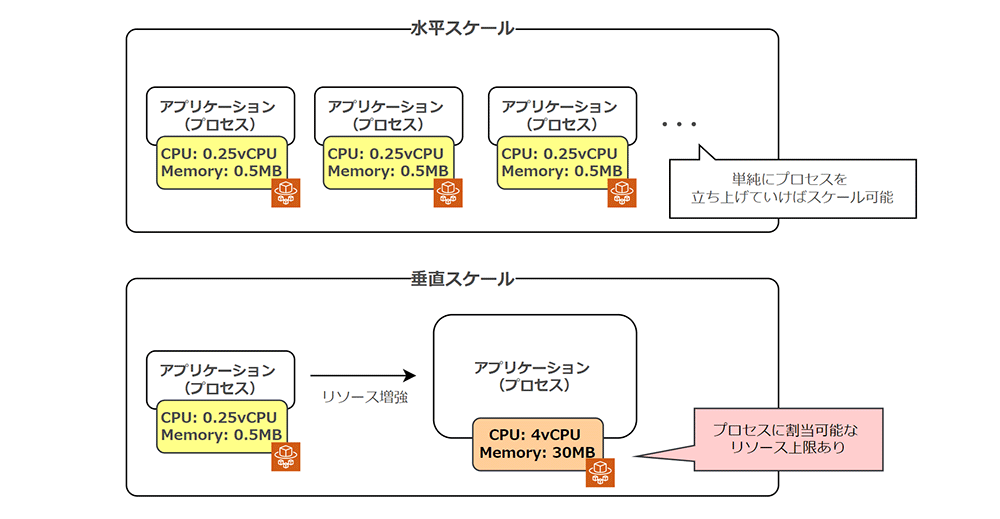
12FA の「並行性」では、アプリケーションをプロセスとして扱い、プロセス単位で水平にスケール可能とするべき、と主張しています。
Why
「水平スケール」の対比として、アプリケーション単体のコンピューティングリソースを増加させる「垂直スケール」があります。一方、「垂直スケール」で割当て可能なコンピューティングリソースは、「水平スケール」で賄うことが可能なリソース量と比較すると限定的です。
例えば、AWS Fargate 上のタスクに割り当て可能な CPU・メモリの上限は 4vCPU/30GB となっています。
「プロセス」にて解説したステートレスな特性と併用し、スケール戦略として水平スケールを基本とすることでパフォーマンス性・耐障害性を高められます。
How
Amazon ECS / AWS Fargate によるワークロードでは、ECS タスクを増やしていくことで水平にスケールできます。
また、Application Auto Scaling を組み合わせることで、リクエスト負荷に応じた水平スケールが可能となります。
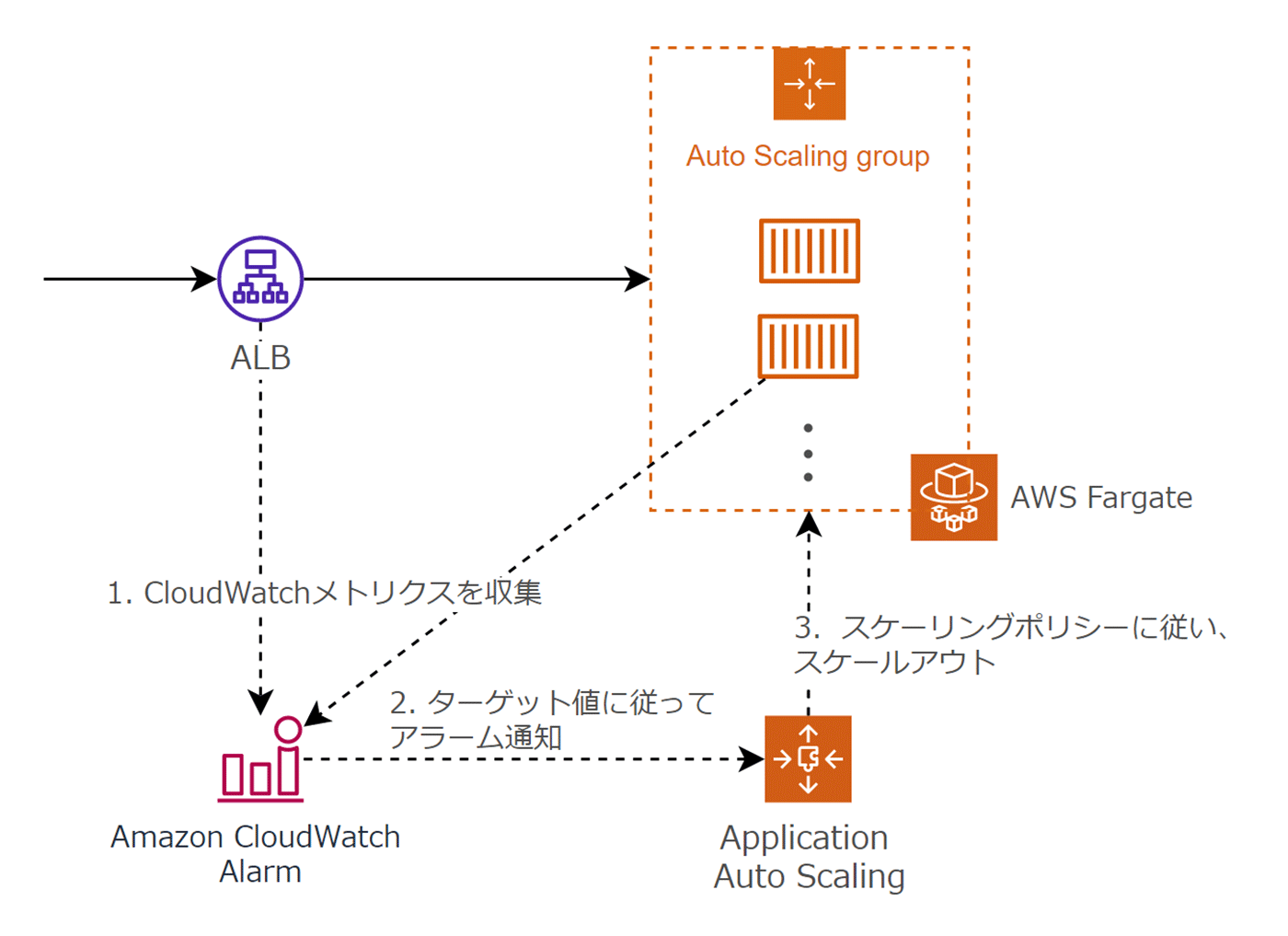
5-9. 廃棄容易性 (Disposability)
What
前述した「プロセス」や「並行性」では、アプリケーションをプロセスとして扱うことのメリットを述べてきました。
12FA では、この「廃棄容易性」に関して、このプロセスに関する起動や終了時間を最小化するように努めるべき、と述べています。
Why
「起動や終了時間を最小化するように努めるべき」とは、そもそもどういうことでしょうか ?
例えば、Amazon ECS では、スケールイン時や正常なアプリケーション終了動作時において、アプリケーションプロセスに対して SIGTERM と呼ばれるシグナルが発行されます。
SIGTERMを受け取ったアプリケーションは、サービスを停止させるようにポートの受付を停止したり、仕掛かり中のデータベース書き込み処理等を適切に終了することで、安全に停止できます。これにより、障害が発生しても堅牢なアプリケーションを実現できます。
もし、この SIGTERM シグナルに対するハンドリングが実装されていない場合、アプリケーションが安全に停止できる猶予時間が与えられていたにも関わらず、何もしないことと同じです。
SIGTERM 発行から一定時間が経過すると、アプリケーションプロセス自体をクラッシュさせて再起動によりリカバリするために、プロセスを強制終了する SIGKILL シグナルが発行されます。これにより、仕掛中の処理が強制的に中断されます。
アプリケーションの状態が不安定になったり、データの不整合が発生する可能性もあるので、注意が必要です。
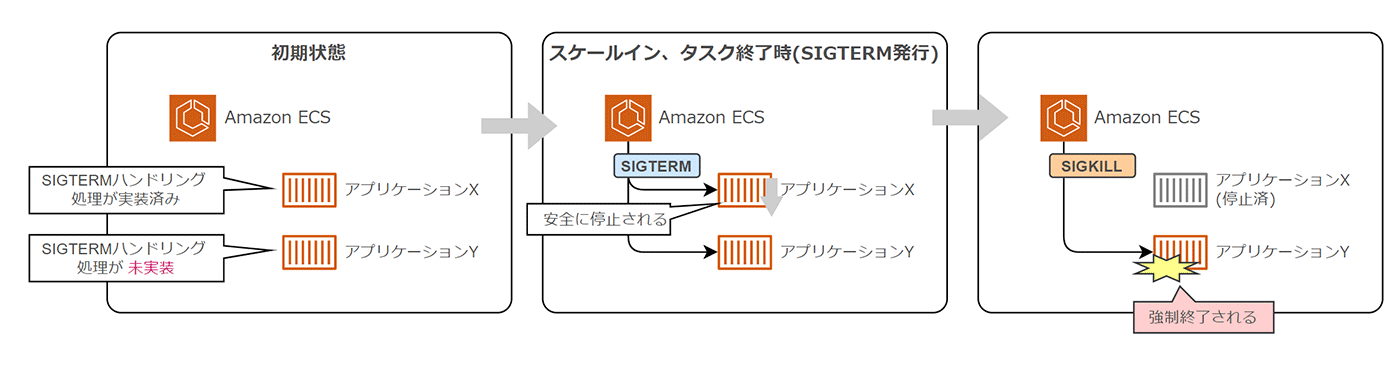
How
前述の通り、Amazon ECS ではアプリケーションプロセスに停止を要求する際、SIGTERM 及び SIGKILL シグナルを発行します。この仕様に関して 詳細解説している AWS Blog がありますので、適宜参考にしてください。
高速かつ安全な処理を実現するために、アプリケーションを開発する際はシグナルをハンドリングする考慮を忘れないようにしてください。
5-10. 開発 / 本番一致 (Dev/prod parity)
What
「開発 / 本番一致」プラクティスでは、アプリケーションの継続的なデプロイが実現できるように、開発環境と本番環境の差を可能な限り小さく保つべき、と述べています。
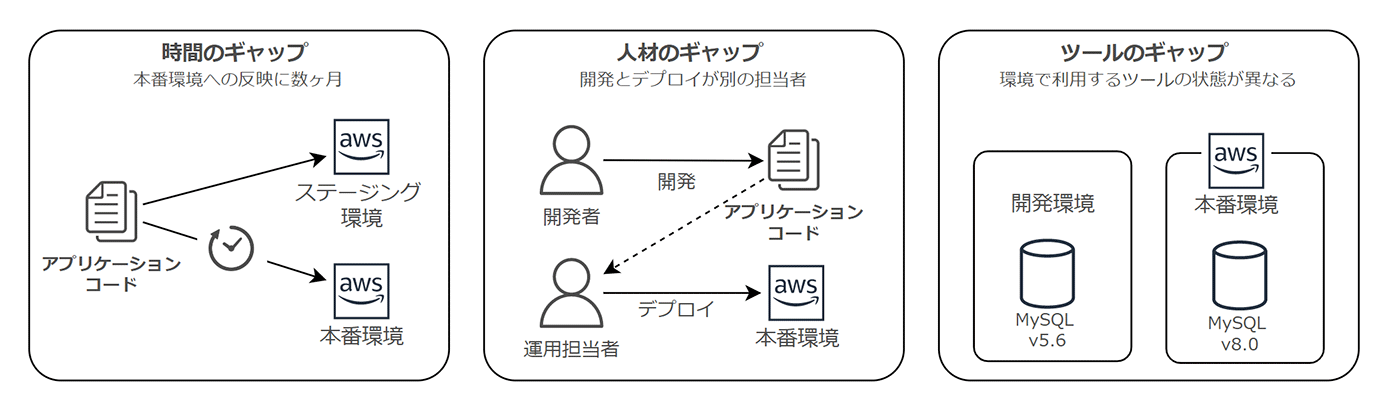
12FA では、環境間の差は次の 3 つのギャップから生じると述べています。
Why
このプラクティスが重要である理由について、各ギャップの考察から順番に探っていきましょう。
まずは「時間のギャップ」に関する理由です。本番環境に対するコードの反映に時間がかかるような体制や仕組みでは、その間に様々なコードの変更が蓄積されます。
デプロイする時には多数の変更点を含む状態となってしまうでしょう。
そのような状態ではデプロイするアプリケーションの複雑性が増し、バグなどの問題が発生するリスクや、発生した際の特定に時間を要する傾向が高まります。
また、本番環境の反映に対して、開発者はより慎重な作業やデプロイ後の確認が求められます。そのため、デプロイ後の確認に要する時間が増大したり、作業に対する心理的な障壁ができてしまいます。
小さく、早く、本番環境に変更することで時間のギャップを解消し、これらの問題を解消することが理想でしょう。
次に、「人材のギャップ」に関する理由です。コードの開発者とは別の運用担当者がデプロイに携わる場合、デプロイ後の確認や問題発生時の切り分けに関して、アプリケーションの仕組みを熟知している開発者より時間を要してしまう可能性があります。
理想はコードを開発したエンジニアが本番環境のデプロイを見届けることです。当事者自身が自律性を持ってデプロイまで見届けられるような組織や仕組み作りが、結果的に開発アジリティの最大化やオペミス・判断ミスの最小化に寄与します。
最後に「ツールのギャップ」ですが、そもそも扱うソフトウェアが異なると、テストから得られたアプリケーションの品質は厳密に保証されません。
よくあるのが、環境間でツールのバージョンが異なるケースです。わずかな挙動の違いがアプリケーションの動作に影響を及ぼします。あるべき絵姿として、開発環境と本番環境でツールの状態が一致していることが望ましい、という点は言うまでもないでしょう。
How
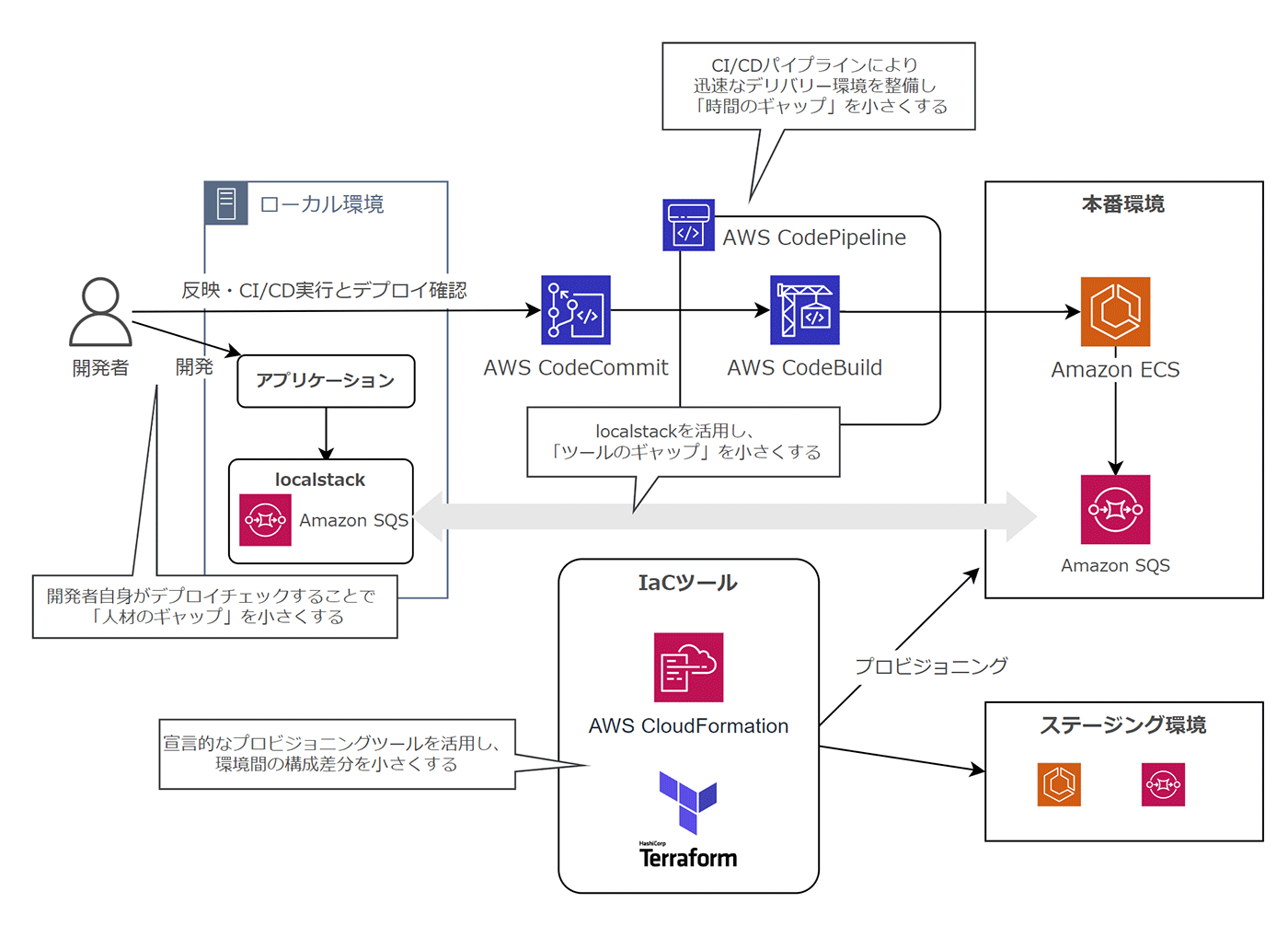
これらのギャップを埋めるためには、開発者自身がコードの変更を素早く本番環境にデプロイできるための仕組み作りが有効です。
「ビルド、リリース、実行」プラクティスで述べたように、まずは、Codeシリーズ等を活用して CI/CD パイプラインを整備することがプラクティスに則る第一歩です。そして、開発者自身が積極的に CI/CD に関わることで、アプリケーションがデプロイされ、本番環境での挙動が適切かどうか判断するところまでの状態を目指しましょう。
開発者のローカル環境に関しては、Docker コンテナを活用することで、環境の再現性をより近づけることが可能です。また、「バックエンドサービス」プラクティスで触れた localstack を活用することで、ローカル環境上で擬似的に AWS のサービスを動作させることも可能です。
ステージング環境と本番環境の差異に関しては、AWS CloudFormation や Terraform 等の宣言的なプロビジョニングを活用することで、環境間の構成をより近づけることも有効です。
ただ、筆者の個人的な意見として、本プラクティスの実践は組織構造や文化上の制約からすべてのギャップを埋めるのはなかなか難しい、と考えています。
特に SI やエンタープライズ領域では、お客様側や自社の統制ルールに依存するケースも多く、特に「人のギャップ」に関して改善するには難しい状況もあるかと推察されます。
そのような場合、まずは、CI/CD の導入やローカル環境の整備から取り組むことで「時間のギャップ」や「ツールのギャップ」を改善し、徐々に文化を醸成していくことをおすすめします。
5-11. ログ (Logs)
What
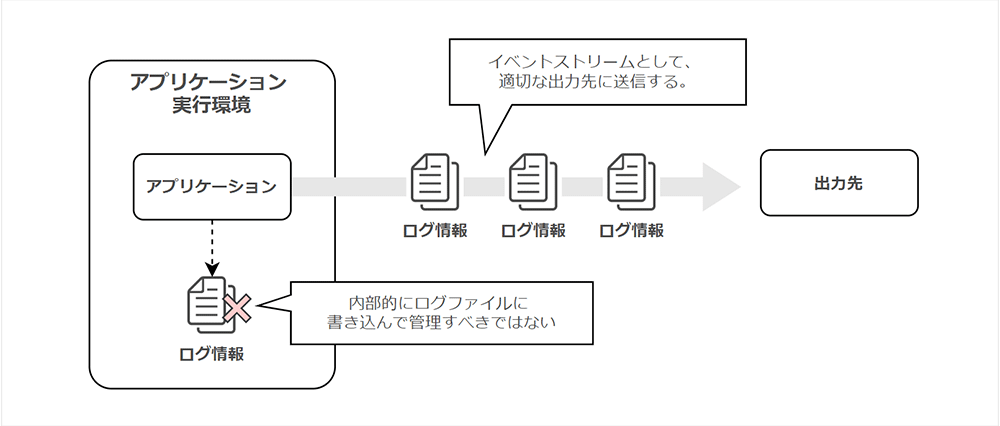
12FA の「ログ」では、ログをイベントストリームとして扱うべき、と述べています。
これは、アプリケーションの稼働と併せてログを連続したイベント情報として捉え、アプリケーション自体がログを保持するのではなくストリームとして送信すべきである、という解釈になります。
Why
そもそも「ストリーム処理」とは、リアルタイムにデータを収集・変換・分析する処理を指します。
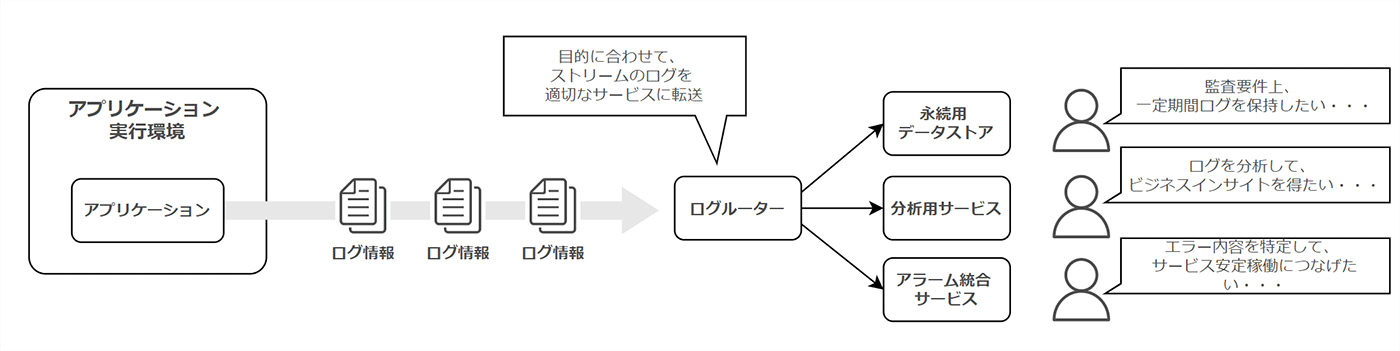
ストリームとして扱うべき背景の一つは、分析用途です。過去の特定のイベントに関する傾向を確認したり、リアルタイムでリクエストに対する状況やサービスの状況を把握するために、アプリケーション自体がログを保持している状態では扱いずらい状態となります。分析用サービスに対してログをストリームで転送できる状態を作り出すことが理想でしょう。
また、ログ内容の関心は、そのログの使い手によって異なります。例えば、監査証跡の観点であれば、情報が失われないように永続的なストレージに保存するのが適切です。一方、アプリケーションエラーの発生有無に関心があるケースでは、ログの内容をチェックしてアラームが発報可能なコンポーネントに対して転送が求められます。
この点で 12FA では、「ログの出力先やストレージに関しては一切関与しない」旨が記載されています。
すでに述べたように、利用者の目的に合わせて要件が変わることから、12FA ではこのように表現されているものと考えています。
以上をまとめると、「利用目的に合わせて、ストリームイベントであるログを適切な場所にルーティングできるような仕組みを作りましょう」、ということですね。
ところで、コンテナアプリケーションに関して、スケールインやクラッシュが発生すると対象のコンテナは破棄されます。
ログをコンテナ上のディスク領域に出力すると欠損する可能性があるため、この観点でもストリームとして外部出力する構成が望ましいと言えるでしょう。
How
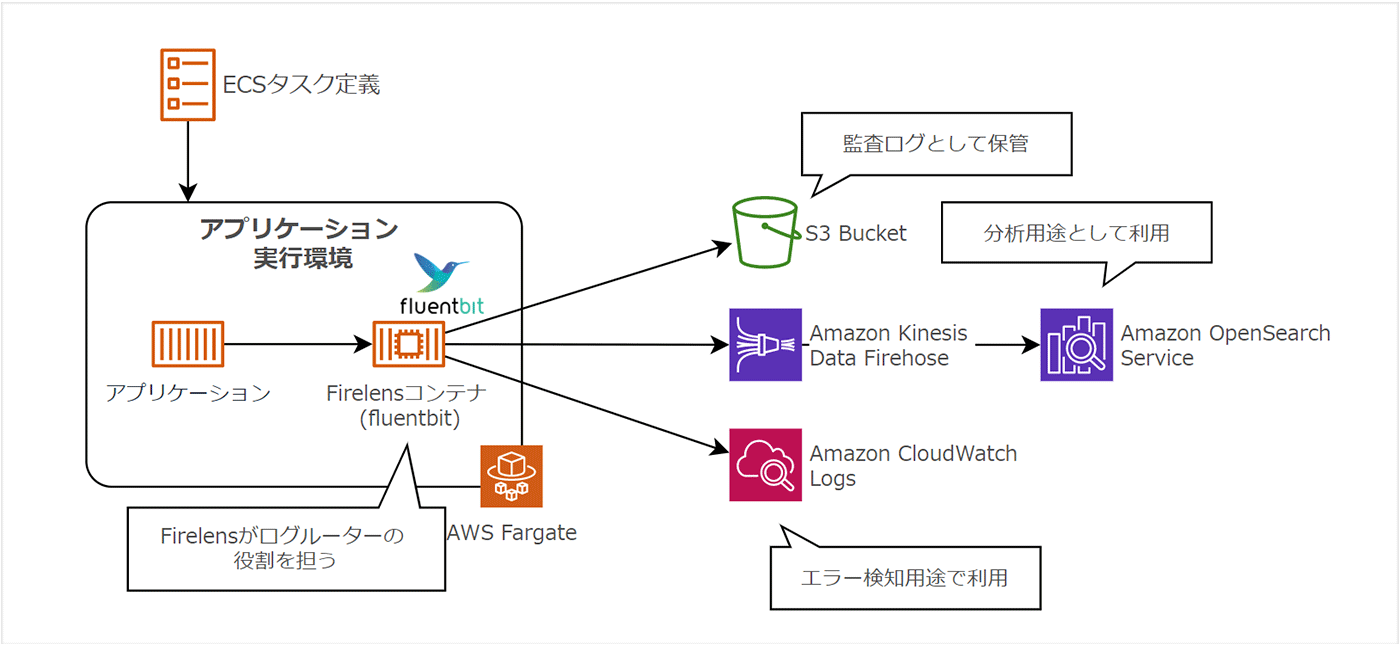
Amazon ECS では、タスク定義上の logConfiguration にログドライバーを指定できます。
例えば、awslogs を指定することで、コンテナのログを Amazon CloudWatch Logs 上にストリーム転送できます。
また、awsfirelens を指定し、オープンソースとして提供されている Fluent bit と組み合わせることで、Amazon S3 含めた様々な転送先にログを渡すことが可能となります。
コンテナを基本とするアーキテクチャでは、ログは静的ファイルとしてコンテナ上に出力するのではなく、標準出力し、ログルーターを通して各種サービスに送出することが望ましい構成であることを理解しておきましょう。
5-12. 管理プロセス (Admin processes)
What
12FA 最後のプラクティスは「管理プロセス」です。12FA では、管理タスクを 1 回限りのプロセスとして実行すべき、と主張しています。「管理プロセス」と言われると少しわかりにくいと思うのですが、端的に言えば、「管理作業の自動化」です。
すなわち、アプリケーション管理や運用関連の作業は手動で実施されるのではなく自動化しておくべき、という理解でよいでしょう。
Why
運用に関連する作業を自動化せずに、手順書等でマニュアル実行していくと、当然ながら人的ミスの発生を誘発します。また、手順書作成のコストや手順書の妥当性を判断するコストも発生します。
複雑な運用作業や慎重に行うべきタスクに関してはスクリプト等で自動化しておくと、これらの課題解消が期待できます。作成したスクリプトを開発環境やステージング環境で事前に検証し、本番環境でアプリケーションと同じように実行されるよう、組み込むことで管理作業の効率化と動作保証が両立できます。
How
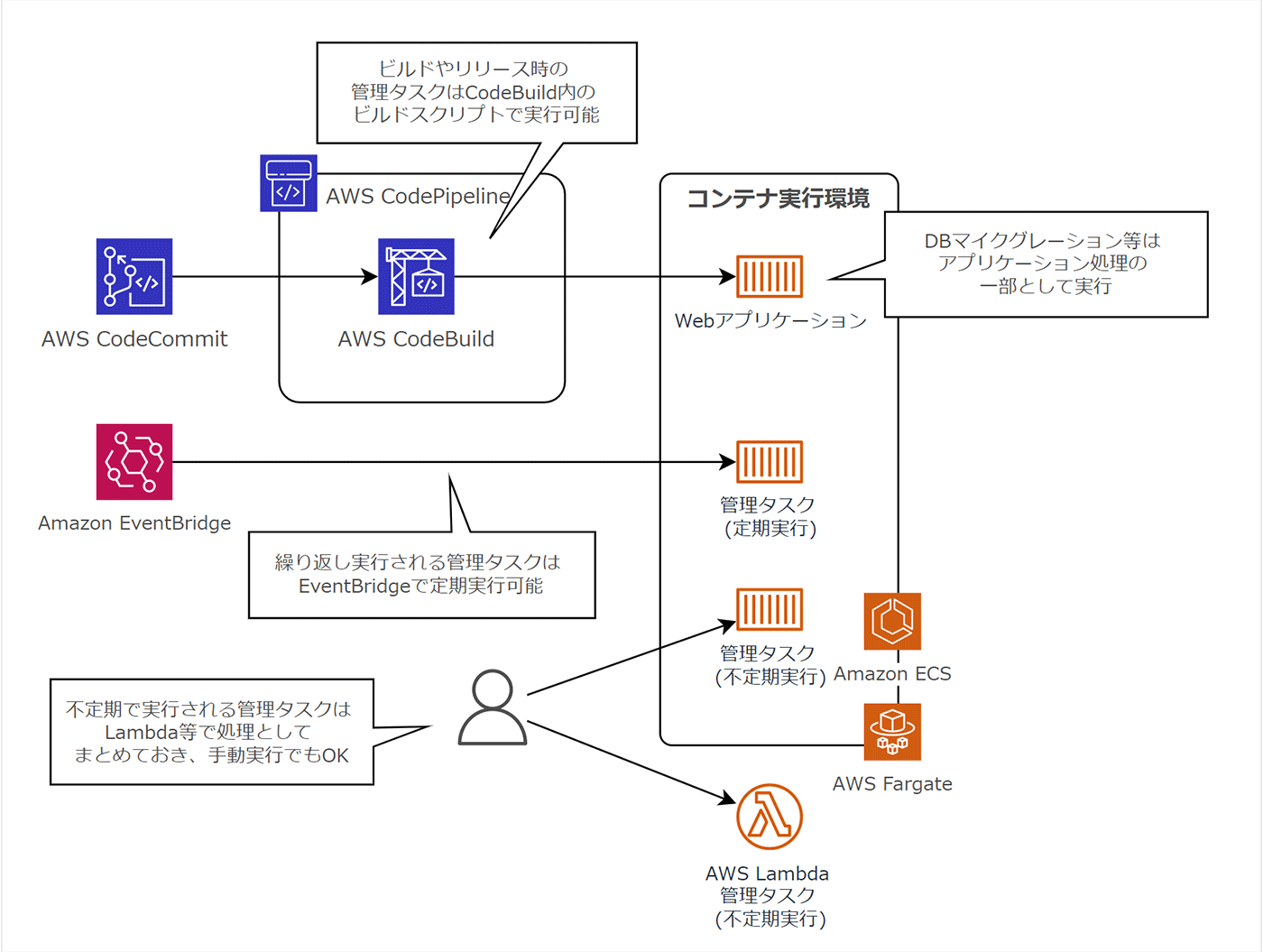
ビルドやリリース時に必要な管理タスクは AWS CodeBuild のビルドスクリプトに組み込むことで自動化可能です。また、デプロイ時に実行されるべきアプリケーション管理作業は、Dockerfile 内における初期化処理やアプリケーション初期化処理としてコード内に記述することで処理できます。
日々繰り返し行われるメンテナンス作業は、Amazon EventBridge と組み合わせることで cron 実行のように制御できます。
また、不定期に行われるメンテナンス作業は、ECS タスクや AWS Lambda 等で処理を定義しておき、必要に応じて実行するだけの状態としておくことが理想です。
ただし、筆者の意見として、クラウド上の管理作業によっては、わざわざ自動化せず、マネジメントコンソールを利用して手作業で実施した方が簡単かつ効率的なことも多々あると考えています。
この点に関しては、管理タスクの頻度やリスク度合い、複雑さなどから、自動化すべきかどうかの判断をすべきでしょう。
6. さいごに
いかがでしたでしょうか。今回は 12FA の各プラクティスについて、「なぜその方法が良いとされているのか ?」という点について掘り下げて解説をしてみました。
また、Amazon ECS / AWS Fargate を主軸としたワークロードにおいて、プラクティスがどのように実践されるのか、という点についても触れてみました。
読者の皆さまのビジネス内容やアーキテクチャによっては多少異なるとは考えていますが、本稿が少しでも12FA理解の手助けになれば幸いです。
改めて、最後まで読んでいただきありがとうございました。
筆者プロフィール
新井 雅也 (@msy78)
株式会社野村総合研究所 エキスパートアーキテクト | NRI認定ITアーキテクト
AWS Container HERO | 2021-2022 AWS APN Ambassador | JAWS-UG コンテナ支部 運営メンバー
2012 年、株式会社野村総合研究所に入社。
入社以来、アーキテクト兼エンジニアとして、主に金融業界のお客様に向けたビジネス提案やシステム設計、開発、運用を担当。
UI/UX デザインやスマホ App、バックエンド API など、フルスタック領域な守備範囲を持ちつつ、クラウドを活用した全体のアーキテクチャ設計・開発が得意。
コンテナ技術が大好きで、コンテナに纏わるブログや書籍執筆、寄稿、登壇、コミュニティ運営等の活動を経て、2022 年に AWS Container HERO に認定。
最近の趣味はビザールプランツ集めとそのお世話。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages