Amazon Web Services ブログ
ECS のアプリケーションを正常にシャットダウンする方法
この記事は Graceful shutdowns with ECS を翻訳したものです。
—
はじめに
Amazon Elastic Container Service (Amazon ECS) を利用することで、お客様はさまざまな方法でコンテナ化されたアプリケーションを柔軟にスケールできます。リクエストの急増に対してタスクをスケールアウトすることも、コスト削減のためにタスクをスケールインすることもできます。ECS ではさまざまなデプロイの選択肢があり、ローリングデプロイ・ブルー/グリーンデプロイ・カナリアデプロイなどがサポートされています。さらに、ECS では柔軟なコンピューティングの選択肢が用意されています。Amazon EC2 のオンデマンド/スポットのキャパシティ上や、マネージドでサーバーレスなコンピューティング環境である AWS Fargate 上でも ECS のタスクを実行することができます。
Amazon ECS が提供する動的なコンピューティングオプションを利用すると、タスクが定期的に終了することがあります。例えば、デプロイによって以前のバージョンのアプリケーションが終了します。スケールインイベントが起きることで、1つもしくは複数のタスクのレプリカが終了することもあるでしょう。また、障害が発生したハードウェアの交換や新しいバージョンの OS へのアップグレードなど、インスタンスのリタイアや交換によって、タスクが終了する場合もあります。スポットインスタンスは AWS のお客様にとってますます人気が高まっている選択肢ですが、このスポットインスタンスの中断でも同様にタスクが終了します。
このような状況においては、タスクを正常に終了処理できることが重要です。正常に終了処理をしていないと、ユーザー側でエラーやその他の問題が発生する可能性があります。たとえば、ロードバランサーがリクエスト送信を停止する前にコンテナが終了すると、レスポンスで HTTP 5xx エラーが返ってくる可能性があります。同様に、長いタスクの処理中に、ワークキューに接続されたジョブプロセッサを稼働させるコンテナが終了してしまい、再処理に多大な遅延が発生するかもしれません。最悪の場合、タスクがリトライされず、作業が失われたり、ビジネスプロセスが失敗したりする可能性があります。
この記事では、ECS でアプリケーションを構築および運用するエンジニアおよびサービスチームを対象に、終了処理に関するベストプラクティスを説明します。どのように ECS がタスクを終了するかについて詳しく説明し、エラーを最小限に抑えながらアプリケーションを安全にシャットダウンする方法について知っていただきたいと思います。
コンテナのライフサイクル
ECS エージェントは、タスクを開始するとタスク内のすべてのコンテナの作業環境を確立します。たとえば、タスクが awsvpc ネットワークモードを利用するように定義されている場合、ECS エージェントは pause コンテナをプロビジョニングし、ネットワークの namespace をタスク内の他のコンテナと共有します。完了すると、ECS エージェントはコンテナランタイムの API を呼び出して、ECS タスク定義で定義されているコンテナを実行します。
タスクが停止すると、各コンテナのエントリプロセス (通常は PID 1) に SIGTERM シグナルを送信します。タイムアウトが経過すると、今度は SIGKILL シグナルをプロセスに送信します。デフォルトでは、SIGTERM シグナルの送信後 30 秒のタイムアウトで SIGKILL シグナルを送信します。この値は、ECS タスクのパラメータの stopTimeout を更新することによってタスクのコンテナ単位で調整するか、ECS エージェントの環境変数 ECS_CONTAINER_STOP_TIMEOUT を設定して EC2 コンテナインスタンス単位で調整できます。この最初の SIGTERM シグナルを適切に処理して、正常にコンテナのプロセスを終了させる必要があります。SIGTERM シグナルを処理することを意識しておらずタイムアウトまでに終了しなかったプロセスは、SIGKILL シグナルが送信され、コンテナが強制的に停止されます。
エントリプロセスが全てを支配する
プロセスは子プロセスを生成し、その子プロセスの親になります。 SIGTERM のような停止シグナルによってプロセスが停止されると、親プロセスは、その子プロセスを正常にシャットダウンし、その後自身をシャットダウンする責任があります。親プロセスがそのように設計されていない場合、子プロセスが突然終了し、5xx エラーや作業が失われる可能性があります。コンテナでは、Dockerfile の ENTRYPOINT および CMD ディレクティブで指定されたプロセス (エントリプロセスと呼ぶ) が、コンテナ内の他のすべてのプロセスの親になります。
コンテナの ENTRYPOINT を /bin/sh -c my-app に設定している例を見ていきます。この例では、以下の理由から my-app は正常にシャットダウンしません。
shがエントリプロセスとして実行され、さらにmy-appプロセスを生成します。これはshの子プロセスとして実行されます。shは、コンテナが停止したときにSIGTERMシグナルを受信しますが、my-appに渡されず、このシグナルに対してアクションを実行するように設定されていません。- その後コンテナが
SIGKILLシグナルを受信すると、shとすべての子プロセスが直ちに終了します。
デフォルトでは、shell は SIGTERM を無視します。したがって、shell をアプリケーションのエントリポイントとして使用する場合は、細心の注意が必要です。エントリポイントで shell を安全に使用するには、2 つの方法があります。1) シェルスクリプトを介して実行される実際のアプリケーションに exec というプレフィックスをつける。2) tini (Amazon ECS-Optimized AMI の Docker ランタイムに同梱されている) や dumb-init などの専用のプロセスマネージャーを使用する。
exec はコマンドを実行したいときや、コマンド終了後に shell が不要になったときに便利です。あるコマンドを exec をつけて実行すると、子プロセスを生成するのではなく現在実行中のプロセス (この場合は shell ) の内容を新しい実行可能プロセスに置き換えます。これは、シグナル処理に関連するため重要です。例えば、exec server <arguments> と実行すると、shell が実行されたのと同じ PID で server のコマンドが実行されます。exec をつけていないと、server のコマンドは個別の子プロセスとして実行され、エントリプロセスに送信した SIGTERM シグナルも自動的に受信しません。
また、exec コマンドを、コンテナのエントリポイントとして機能するシェルスクリプトに組み込むこともできます。たとえばスクリプトの最後に exec "$@" を含めると、現在実行中の shell を "$@" が参照するコマンドに置き換えます。デフォルトではコマンドの引数です。
利用方法: ./entry.sh /app app arguement
#!/bin/sh
## Redirecting Filehanders
ln -sf /proc/$$/fd/1 /log/stdout.log
ln -sf /proc/$$/fd/2 /log/stderr.log
## Initialization
# TODO: put your init steps here
## Start Process
# exec into process and take over PID
>/log/stdout.log 2>/log/stderr.log exec "$@"tini や dumb-init などのプロセスマネージャーを使用すると、終了処理を少し簡単にできます。これらのプログラムは SIGTERM を受け取ると、アプリケーションを含むすべての子プロセスグループに SIGTERM を送信します。
これらのプロセスマネージャーは簡単に使うことができます。コンテナイメージにバイナリを含めておき、以下のようにコンテナの ENTRYPOINT でプロセスマネージャーにコマンドを引数として付加するだけです。
ご参考までに、InitProcessEnabled を有効にした ECS タスクを実行すると、ECS はコンテナの init プロセスとして tini を自動的に実行します。この機能を使用する場合は、コンテナの ENTRYPOINT で再設定する必要はありません。詳細については、ECS 開発者ガイドおよび Docker ドキュメントをご覧ください。
SIGTERM シグナルを処理する
タスクが停止すると、ECS はそのタスク内の各コンテナに停止シグナルを送信します。現在、ECS は必ず SIGTERM を送信しますが、将来的には Dockerfile やタスク定義に STOPSIGNAL ディレクティブを追加することで、これをオーバーライドできるようにする予定です。この停止シグナルは、シャットダウンの命令をアプリケーションに通知します。
リクエストを処理するアプリケーションは、SIGTERM シグナルを受信後、常に正常にシャットダウンする必要があります。シャットダウン処理の一環として、アプリケーションは未処理のリクエストの処理をすべて終了し、新しいリクエストの受け入れを停止する必要があります。
サービスが Application Load Balancer (ALB) を使用している場合、ECS は SIGTERM シグナルを送信する前に、ロードバランサーのターゲットグループから自動的にタスクを登録解除します。タスクが登録解除されると、新しいリクエストはすべてロードバランサーのターゲットグループに登録されている他のタスクに転送されます。そのタスクへの既存の接続は、登録解除の遅延の期限が切れるまで (draining 中は) 続行できます。ワークフローの図を以下に示します。

キュー内のメッセージの処理など、サービスがジョブを非同期的に処理する場合、既存のジョブの処理が終了した時点で速やかにコンテナもシャットダウンするのが良いでしょう。ジョブの終了までに時間がかかる場合は、進行中の作業内容を待避 (チェックポイントを設定) した上で迅速に終了することを検討し、犠牲を伴う強制終了を回避してください。120 秒を超える stopTimeout を設定することはできないため、FARGATE_SPOT タスクでは特に重要です。
- 注意点: 実行中の EC2 コンテナインスタンスが draining 状態になっても、タスクスケジューラまたは runTask を使用して実行されたタスクは自動的に draining されません。runTask を使用してタスクを実行している場合は、ASG ライフサイクルフックを使ったり、 Lambda 関数を EventBridge イベントでトリガーさせたりすると良いでしょう。終了するインスタンスで実行されているタスクを列挙および停止させます。このようにタスクを停止させると、インスタンスがスケールインまたは終了する前に、コンテナが Stop シグナルを受信できます。
以下に、いくつかの一般的なプログラミング言語で SIGTERM を処理する終了ハンドラーの例を示します。
Shell ハンドラー
利用方法: ./entry.sh /app app arguments
#!/bin/sh
## Redirecting Filehanders
ln -sf /proc/$$/fd/1 /log/stdout.log
ln -sf /proc/$$/fd/2 /log/stderr.log
## Pre execution handler
pre_execution_handler() {
## Pre Execution
# TODO: put your pre execution steps here
: # delete this nop
}
## Post execution handler
post_execution_handler() {
## Post Execution
# TODO: put your post execution steps here
: # delete this nop
}
## Sigterm Handler
sigterm_handler() {
if [ $pid -ne 0 ]; then
# the above if statement is important because it ensures
# that the application has already started. without it you
# could attempt cleanup steps if the application failed to
# start, causing errors.
kill -15 "$pid"
wait "$pid"
post_execution_handler
fi
exit 143; # 128 + 15 -- SIGTERM
}
## Setup signal trap
# on callback execute the specified handler
trap 'sigterm_handler' SIGTERM
## Initialization
pre_execution_handler
## Start Process
# run process in background and record PID
>/log/stdout.log 2>/log/stderr.log "$@" &
pid="$!"
# Application can log to stdout/stderr, /log/stdout.log or /log/stderr.log
## Wait forever until app dies
wait "$pid"
return_code="$?"
## Cleanup
post_execution_handler
# echo the return code of the application
exit $return_codeGo ハンドラー
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
sigs := make(chan os.Signal, 1)
done := make(chan bool, 1)
//registers the channel
signal.Notify(sigs, syscall.SIGTERM)
go func() {
sig := <-sigs
fmt.Println("Caught SIGTERM, shutting down")
// Finish any outstanding requests, then...
done <- true
}()
fmt.Println("Starting application")
// Main logic goes here
<-done
fmt.Println("exiting")
}Python ハンドラー
import signal, time, os
def shutdown(signum, frame):
print('Caught SIGTERM, shutting down')
# Finish any outstanding requests, then...
exit(0)
if __name__ == '__main__':
# Register handler
signal.signal(signal.SIGTERM, shutdown)
# Main logic goes hereNode ハンドラー
process.on('SIGTERM', () => {
console.log('The service is about to shut down!');
// Finish any outstanding requests, then...
process.exit(0);
});Java ハンドラー
import sun.misc.Signal;
import sun.misc.SignalHandler;
public class ExampleSignalHandler {
public static void main(String... args) throws InterruptedException {
final long start = System.nanoTime();
Signal.handle(new Signal("TERM"), new SignalHandler() {
public void handle(Signal sig) {
System.out.format("\nProgram execution took %f seconds\n", (System.nanoTime() - start) / 1e9f);
System.exit(0);
}
});
int counter = 0;
while(true) {
System.out.println(counter++);
Thread.sleep(500);
}
}
}EC2 スポットインスタンスおよび Fargate Spot での中断のハンドリング
ECS では、オンデマンドに加えて、EC2 スポットインスタンス上のタスクとし て、また FARGATE_SPOT タスクとしてアプリケーションを実行するオプションがあります。EC2 スポットインスタンスを使用する場合は、ECS エージェントの環境変数である ECS_ENABLE_SPOT_INSTANCE_DRAINING を true に設定することを強く推奨します。この環境変数を true に設定することで、中断の2分前に送付されるスポットインスタンスの中断通知を受信すると、ECS エージェントはインスタンスを DRAINING 状態にします。
インスタンスが DRAINING 状態になると、そのインスタンスのすべての ECS タスクがクラスター内の ACTIVE 状態のインスタンスに移行されます。この移行プロセスは、まず ACTIVE インスタンスで新しいタスクを実行し、ヘルスチェックに合格して healthy になるのを待機することから始まります。この新しいタスクが正常になると、DRAINING インスタンス上のタスクのシャットダウンを開始します。古いタスクがロードバランサーのターゲットグループに登録されている場合は先に登録解除され、停止する前に既存のリクエストの処理を完了できます。この移行プロセスにより、スポットインスタンスの中断に起因するものを含む、EC2 インスタンスの予期せぬシャットダウン中にアプリケーションが中断する可能性が低くなります。
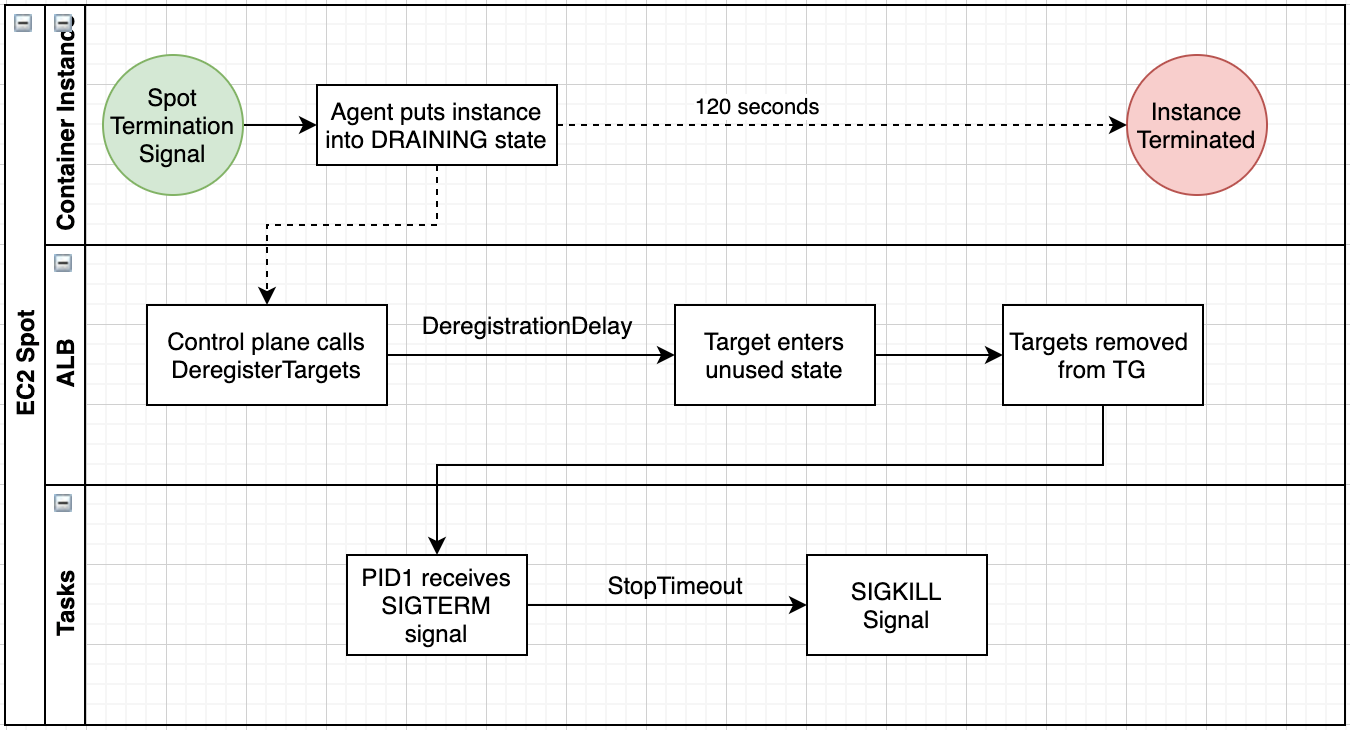
要注意: クラスターに空きキャパシティがある場合にのみ、タスクを他のインスタンスに移行できます。EC2 スポットインスタンスでミッションクリティカルなコンテナサービスをホストしている場合は、継続して実行される必要のある重要なタスクが最低限稼働できるように、ある程度のオンデマンドインスタンスを準備しておくことを検討してください。
スポットインスタンスの自動ドレイン機能は EC2 スポットインスタンスで機能しますが、FARGATE_SPOT として実行されるタスクでは、ロードバランサーのターゲットグループから登録解除されてからタスクが STOPPED 状態に移行するという保証はありません。望ましくないエラーを回避するために、必要な API を呼び出して、ロードバランサーのターゲットグループからタスクを登録解除することをお勧めします。これを処理する方法はいくつかあります。
SIGTERMハンドラーの中で、DeregisterTargets API を呼び出して、ターゲットグループからタスクを登録解除します。この方法では、AWS SDK をアプリケーションに組み込む必要があります。もしくは、ロードバランサーからタスクを登録解除するロジックを含むサイドカーコンテナを実行することもできます。- タスク状態変更イベントでトリガーされる Lambda 関数を実装します。GitHub の例を参考にできます。イベントの
stopCodeがTerminationNoticeのときに、Lambda 関数でロードバランサーからタスクを登録解除するようにします。
これらの方法は、複数のターゲットグループに登録されているタスクでも機能します。
スポットインスタンスおよび Fargate Spot を使用する上では、タスクに関連付けられたターゲットグループの登録解除の遅延の設定を知っておいてください。スポットインスタンスおよび Fargate Spot では、中断通知からタスクがシャットダウンされるまでに 2 分しかありません。そのため、関連付けられたターゲットグループの登録解除の遅延は、2 分未満に設定する必要があります。
ターゲットの登録解除時に実行中のリクエストがなく、アクティブな接続もない場合、Elastic Load Balancing は登録解除プロセスを直ちに完了します。ターゲットの登録解除自体が完了しても、登録解除の遅延期間が経過するまではターゲットのステータスは draining として表示されます。さらに、FARGATE_SPOT タスクが終了としてマークされると、タスク内のすべてのコンテナがすぐに SIGTERM シグナルを受信します。SIGTERM を受信したタイミングで、登録解除の遅延期間が満了するまでシグナルハンドラをスリープさせておくのも一つのアイデアです。これにより、すべての子プロセスが終了し、クライアントとの接続が終了するのを待機させることができ、より安全な終了処理を実現できます。

結論
SIGTERM シグナルを適切に処理しないと、アプリケーションが突然停止する可能性があります。これにより、4xx および 5xx エラーなどの重大な影響や、中断されたジョブの再実行を強制するような可能性があります。アプリケーションを ECS タスクとして実行する場合は、常に SIGTERM ハンドラーを含める必要があります。ただし、NGINX のようなアプリケーションを実行している場合は、コンテナの停止シグナルへの応答を調査したり、コンテナの STOPSIGNAL を変更したりする必要があります。ハンドラーが実行されると、コンテナが SIGKILL シグナルを受信する前に、実行中のリクエストの処理を完了させ、新しいリクエストの受け入れを停止する必要があります。
スポットインスタンスおよび Fargate Spot では、タスクが強制的に終了されるまで2分の猶予しかありません。ECS FARGATE_SPOT を使用するつもりなら、ロードバランサーのターゲットグループからタスクを登録解除するロジックをアプリケーションの SIGTERM ハンドラーに含める、または同様のロジックを Lambda 関数に実装して、タスク状態イベントを契機に実行することをお勧めします。EC2 スポットインスタンスの場合はスポットインスタンスの自動ドレイン機能を利用でき、コンテナに SIGTERM シグナルを送信する前に、ロードバランサーからターゲットをドレインしてくれます。
ボーイスカウトのモットーのように「備えよ常に」です。新しいバージョンのデプロイ時やスポットインスタンスおよび Fargate Spot での実行時の問題を回避するため、停止シグナルを受信したときにアプリケーションを正常にシャットダウンするようにしてください。
翻訳はソリューションアーキテクト濵が担当しました。原文はこちらです。