至福のおうちコーヒーを極めるために、AI にドリップを分析してもらう Web サービスを作ってみた
2022-11-02 | Author : 岡本 晋太朗

はじめに
こんにちは。ソリューションアーキテクトの岡本です。秋も一段と深まり、コーヒーが美味しい季節になってきました。アマゾン ウェブ サービス ジャパンではキャリア採用のアソシエイトソリューションアーキテクト向けのトレーニングプログラムとして、「疑似プロジェクト」を実施しています。
本記事では、私が「疑似プロジェクト」にて取り組んだ「至福のおうちコーヒーを極める」ための Web サービスの製作過程をご紹介いたします。
builders.flash メールメンバー登録
「疑似プロジェクト」とは
アマゾン ウェブ サービス ジャパンでは、新人ソリューションアーキテクトは入社後に、まず座学やロールプレイ、OJT などのトレーニングプログラムを経験します。
「疑似プロジェクト」とは、クラウド開発経験が少ない新人ソリューションアーキテクト向けに実施しているトレーニングで、Amazon 流の企画手法である Working Backwards に従って、約 1 ヶ月間で実際に Web サービスを企画・構築するプログラムです。詳細は「疑似プロ・Working Backwardsとは ?」をご覧ください。
PR/FAQ の作成
Working Backwards のプロセスでは、サービスを利用するお客様の課題やニーズを整理し、サービスリリース時に発表するプレスリリース (PR) と、PR を読んだ人が抱くであろう質問に回答する FAQ、お客様の体験変革のイメージを関係者間で共有する Visual を開発着手に先駆けて作成します。
PR にはフォーマットがあり、最初の段落ではサービスの価値を端的にお客様に伝え、その後の文中には開発責任者の話、利用者の声などを含めて作成していきます。
ドラフトが完成したら、社内関係者を集めて、より良い企画にしていくためのレビューセッションを実施します。
私はコーヒーが大好きで、好きが高じて国内外の有名コーヒー店を巡ったり、生のコーヒー豆を購入して自宅で焙煎をしたりしています。従来は外出先でコーヒーを楽しむことが多かったのですが、在宅時間が増加し、自宅でコーヒーを淹れる機会が増えたこともあり、どうすればカフェのように安定して美味しいコーヒーを淹れられるのか ? が大きな関心事項となっていました。
今回のプロジェクトではそんな自分を想定顧客に設定し、コーヒー好きな友人たちにもヒアリングを行いつつ、機械学習を用いてコードレビューを自動化する Amazon CodeGuru をモチーフに、あったらいいな〜と思うサービスを考えてみました。実際に私が作成した「至福のおうちコーヒーを極める」ための Web サービスの PR をご紹介します。

=== Internal Press Release ===
=== Internal Press Release ===
『Amazon CoffeeGuru☕』
“至福のおうちコーヒー” 抽出技術習得支援サービス
2022 年 11 月 2 日 – Team Okamoto は、コーヒーマニアのための ”至福のおうちコーヒー” を支援する「Amazon CoffeeGuru☕」をリリースします。このサービスは、お客様による高品質で安定したコーヒー抽出技術の習得を支援します。本サービスはスマートフォンとコーヒー抽出機材があれば、すぐに利用開始できます。コーヒーの味に大きな影響を与えるにもかかわらず、従来測定が困難だった抽出時のお湯の流量・流速・時間を自動でグラフ化し、味の評価やコメントとあわせて記録することができます。抽出レシピと味の関係をセルフフィードバックいただくことで、お客様のコーヒー抽出技術向上を支援します。
COVID-19 の感染拡大にともなうリモートワークの普及により、カフェや職場ではなく、ご自宅でコーヒーを楽しむ方が急増しています。ある調査 (*1) では、リモートワーク経験者の 4 割が、コロナ禍によって自宅でコーヒーを飲む頻度が増えた、と回答しています。これにともなって自宅で飲むコーヒーでもカフェのような味・香りにこだわったコーヒーを楽しみたい、というニーズが増加しています。また別の調査 (*2) では、6 割以上の方が、コーヒーについてより詳しくなりたいと考えています。
ご自宅で高品質なコーヒーを楽しむには、焙煎と鮮度管理が適切に行われているコーヒー豆の入手に加え、抽出に係るパラメータ (豆重量・豆挽き目・使用器具・湯温・注湯量など) を測定・記録し、お好みの味わいに応じた抽出を高い再現性で実行することが重要です。とくに、お湯の流量・流速・時間がコーヒーの味を決定付ける重要なパラメータとされている一方、これを正確に記録するためには、高額な専用機材が必要でした。この味を左右するパラメータは、抽出後に省みることが難しいため、コーヒー愛好家は数多くの試行を経て感覚的に体得することでしか、適切な抽出技術を身に着けることができませんでした。
Amazon CoffeeGuru☕ はこの課題を解決するため、お客様のスマートフォンとお手持ちのキッチンスケールを利用し、ご自宅でのコーヒー抽出における、お湯の流量・流速・時間を含む各種パラメータと、お客様による飲用後の味の評価を記録する Web サービスです。お客様は、記録した抽出を過去の類似抽出と比較することで、安定したコーヒー抽出のためのセルフフィードバックにご活用いただけます。また、オプションツールとして、手が塞がるコーヒー抽出時に、ハンズフリーで安定したお湯の流量・流速・時間の記録を実現するため、専用スマートフォンスタンド「Amazon Coffee Recipe Recorder (CR2)」を、オープンソース 3D モデルとしてご提供いたします。本スタンドは組み立て式で、お客様のキッチンスケールに合わせたパーツを印刷していただくことで、適切な動画記録にご利用いただけます。
お手持ちのスマートフォンから Amazon CoffeeGuru☕ にアクセスし、スマートフォンを Amazon CR2 上にセットして、キッチンスケールの重量指示値を動画撮影しながらコーヒーの抽出を行います。抽出後、Amazon CoffeeGuru☕ は動画を解析し、お湯の流量・流速・時間を自動でグラフ化します。グラフに紐つけて、主要な抽出レシピ (豆、豆重量、豆挽き目、ドリッパー、グラインダー、湯温) と飲用後の味評価を記録することができます。
「Amazon CoffeeGuru☕ により、お客様はコーヒー抽出の結果に大きな影響を与える、お湯の流量・流速・時間の各パラメータと味の関係について洞察を得ることができ、コーヒー専門店で飲むような高品質のコーヒーを、ご自宅で安定して体験できるようになります」と開発責任者の岡本晋太朗氏は語ります。「普段お使いの抽出機材とスマートフォンを組み合わせていただくだけで、コーヒードリップを極めたいと思う方が、さらなる高みを目指すことができるようになりました。高額な専用機材の導入は不要です。また、将来のアップデートによって、知識や経験がなくても、気軽に人気バリスタのコーヒーレシピをご自宅で試し、習得することができるようになります」
ベータ版ユーザーのコーヒー愛好家 A 氏は次のようにコメントしています。「これまでも自宅でコーヒーを飲んでいましたが、豆の状態やグラインダーなどに気を使っても、安定して納得できるレベルのコーヒーを淹れられないことが悩みでした。Amazon CoffeeGuru☕ を使うことで、自分のコーヒーの淹れ方にかなりブレがあることに気づきました。人気バリスタのおすすめ抽出レシピを参考にして練習を重ねることで、いつでも至福のコーヒータイムを自宅で楽しめるようになりました」
本サービスは、お客様のキッチンスケールをご用意いただき、https://coffeeguru.example/ にアクセスすることで、無料でご利用いただけます。コーヒー抽出器具やキッチンスケールをお持ちでない方は、amazon.co.jp の幅広い品ぞろえからお好きなものをご購入いただけます。また、専用スマートフォンスタンド Amazon CR2 は、サービス Web サイトにてオープンソースで無償公開されており、お手持ちの 3D プリンタ等で印刷いただくことで今すぐにご利用いただけるほか、ご自宅のスケールに合わせて改変の上ご利用いただくこともできます。今後のアップデートにて、お客様のお気に入りのコーヒー抽出レシピを他のお客様と共有したり、人気バリスタや他のユーザーよる人気の抽出レシピを参照し、お客様の抽出結果と比較してセルフフィードバックに活用したり、気に入った抽出レシピのコーヒー豆をワンクリックで注文する SNS 機能や、基準抽出レシピとの比較機能、リアルタイムでの抽出ガイダンス機能が追加される予定です。
(*1) ~ 10 月 1 日はコーヒーの日 コロナ禍におけるコーヒーの飲用調査 ~ コロナ禍でリモートワーク経験者の約 4 割が自宅でコーヒーを飲む頻度が増加!
(*2) 2020 年版 コーヒー事情に関する調査レポート
Note: PR 文中に登場する「Amazon CoffeeGuru☕」「Amazon Coffee Recipe Recorder (CR2)」は架空のサービス名です。
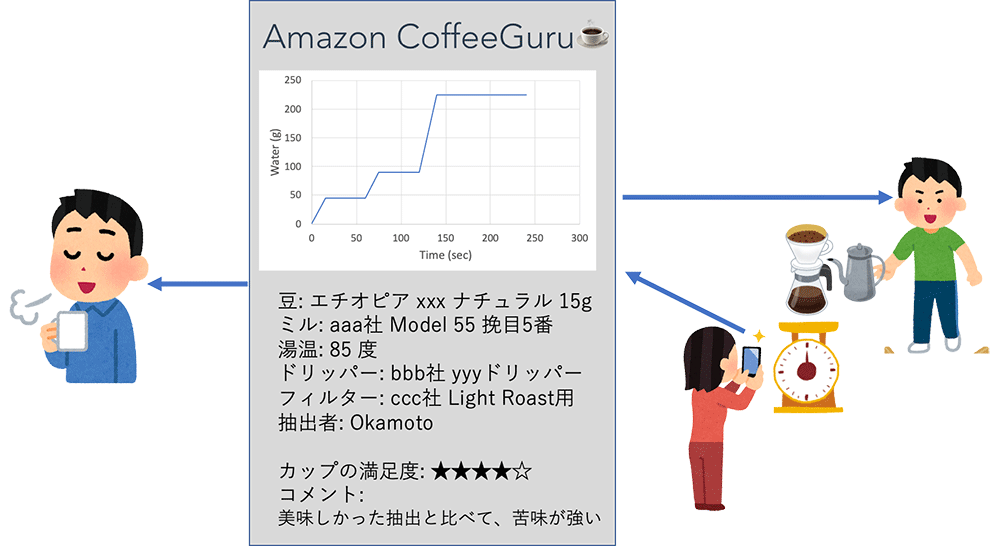
Visual
このように、実際のデータも示しつつ、サービスリリースによりお客様体験がどのように変化するのかを PR のなかで説明していきます。しかし、実際のサービスの完成イメージは、文章だけでは理解が難しいかもしれません。
そこで、Working Backwards のプロセスではお客様体験を視覚的に表す Visual を作成して、関係者間でお客様への提供価値を共有します。私が作成した「Amazon CoffeeGuru☕」の Visual を図 1 に示します。
Visual を通じて、サービスのイメージを持っていただけたでしょうか。PR/FAQ と Visual を作成し、関係者とプロジェクト実施の合意を得られたら、いよいよサービスを試作して、アイディアのビジネス価値と事業化に向けた課題を確かめる PoC (Proof of Concept; 概念実証) のフェーズに進みます。まずは、アーキテクチャの検討を行います。
アーキテクチャ
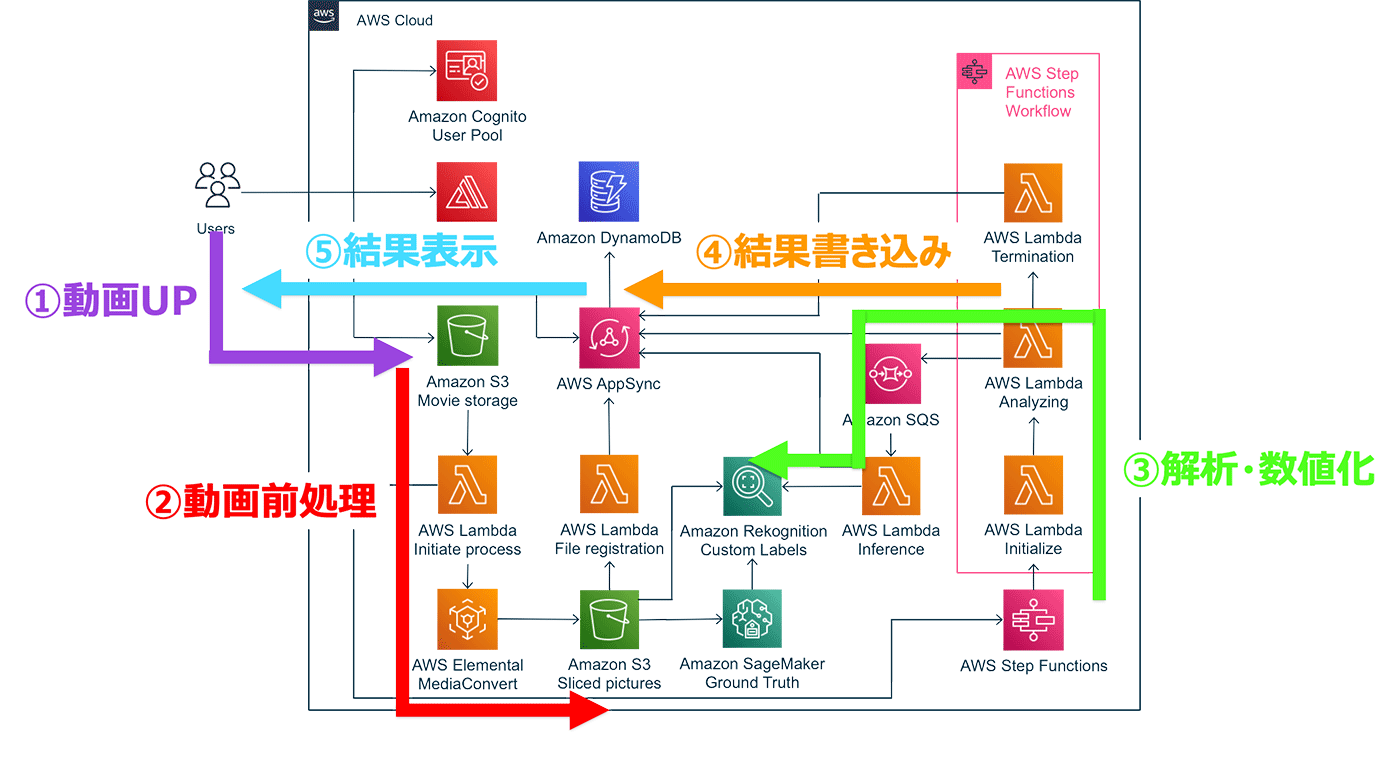
本プロジェクトで採用したアーキテクチャは下図のとおりです。11 種類のサーバーレスな AWS サービスを組み合わせて、一つのアプリケーションを実現しました。以下、順を追って全体の流れを説明します。
全体の流れ
図に、ユーザーが投稿したデータの流れを示しています。ユーザーは Web アプリにアクセスし、コーヒー豆の種類などの情報を AWS AppSync 経由で Amazon DynamoDB に格納し、同時に (1) コーヒー抽出中のキッチンスケールの液晶画面を撮影した動画をアップロードします。
アップロードされた動画はオブジェクトストレージ Amazon S3 に格納され、(2) イベント駆動で AWS Lambda 関数が起動され、ノーコードで動画を変換できる AWS Elemental MediaConvert を実行し、入力動画から 1 秒あたり 4 枚の静止画像を生成して Amazon S3 に格納します。
静止画像が生成されると、(3) 動画を解析するための AWS Step Functions ワークフローが実行され、画像認識サービスの Amazon Rekognition を利用して静止画像からキッチンスケールの指示値を数値化します。
(4) 解析結果は AWS AppSync 経由で Amazon DynamoDB に時系列で保存され、(5) 保存されたデータは AWS Amplify を利用して構築した Web アプリ上で可視化され、ユーザーへのフィードバックが行われます。
アーキテクチャの工夫
工夫が必要だった点として、Amazon Rekognition による液晶画面の数値認識について補足説明します。Amazon Rekognition では画像中のテキスト検出を行うことができますが、事前に検証してみたところ、この機能では 7 セグメント液晶ディスプレイの数値を読み取ることができませんでした。そこで、独自の画像分析モデルをノーコードで構築できる Amazon Rekognition カスタムラベル を活用し、学習用の教師データとして数字にラベルを付けた画像を用意して、7 セグメントディスプレイの数値を読み取るカスタム画像分析モデルを作成しました。
教師データのラベル付け (アノテーション) は、AWS Elemental MediaConvert で生成した静止画像をインプットとして、データラベリングサービスの Amazon SageMaker Ground Truth を活用して作成しました。
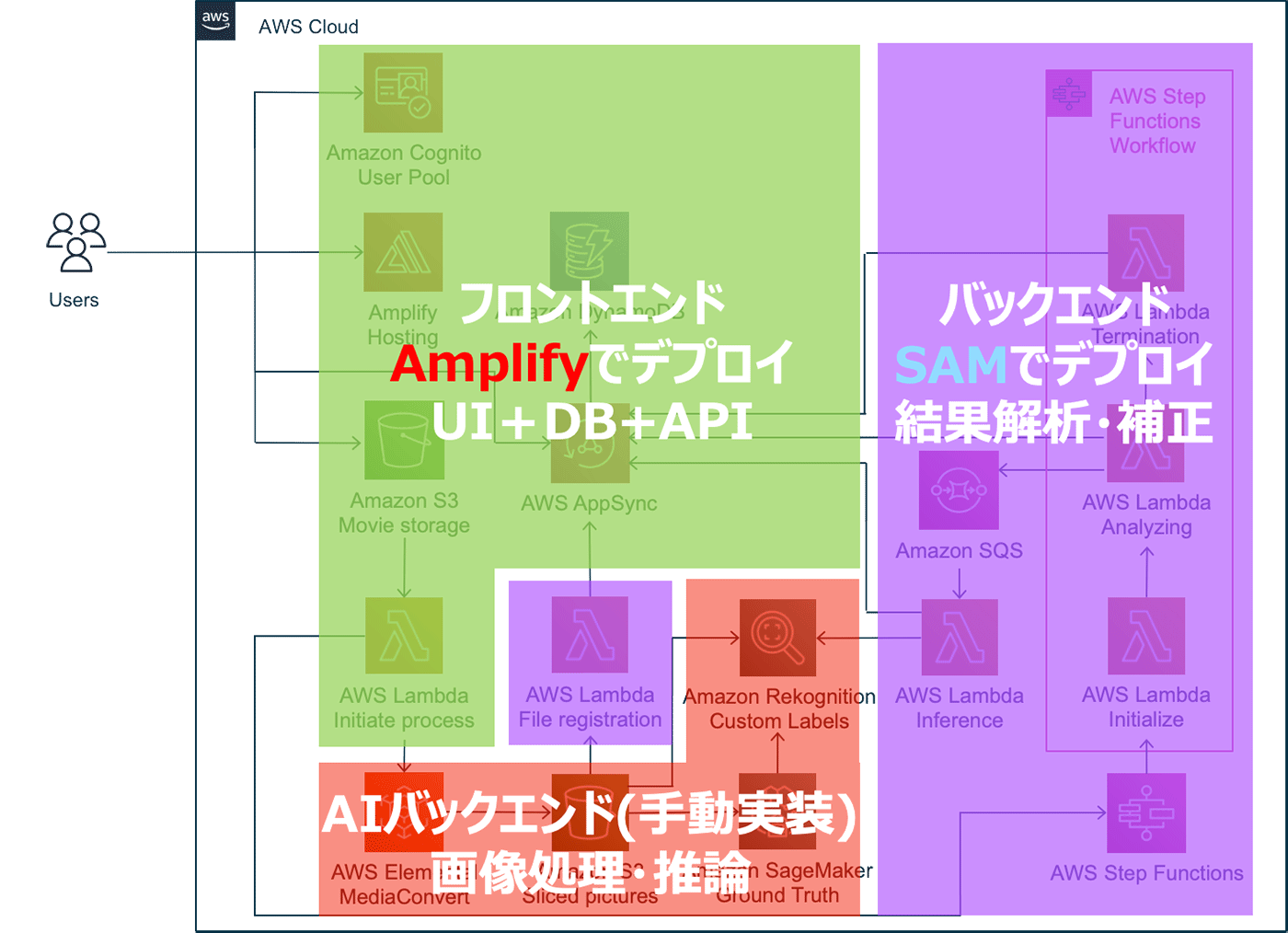
構築にあたっては、アプリケーション全体を下図の通り 3 パートに切り分けて作成していきました。まず動画ファイルを切り分けて、Amazon Rekognition カスタムラベルでカスタム画像分析モデルの作成を行う AI バックエンド (赤色部分) では、設定調整やアノテーションなどの手動作業が多いため、マネジメントコンソール上より設定を行いながら実装を行いました。ユーザーが直接アクセスするフロントエンド (緑色部分) は、フレームワークとして Vue.js を採用し、フロントエンドアプリと AWS サービスの統合を簡単に行える AWS Amplify を用いて、ユーザー認証を担う Amazon Cognito、解析データを保存する Amazon DynamoDB とサーバーレスで GraphQL API を構築できる AWS AppSync、ユーザーがアップロードした動画ファイルを保存する Amazon S3 バケットなどの各種リソースを作成しました。最後に、登録された動画ファイルを解析するバックエンド (紫色部分) は、サーバーレスアプリケーションの構築フレームワークである AWS Serverless Application Model (SAM) を利用しました。
このように、Amplify や SAM といったフレームワークを活用し、AWS のリソース構成をできるだけコード化することで、アプリケーションロジックとクラウドインフラをまとめて Git によりバージョン管理でき、CI/CD パイプラインを構築して開発負荷の低減を図ることができます。
Amazon CR2 (スマホ台) の製作とテスト用動画の撮影
アーキテクチャが固まったので、いよいよ開発に取り掛かります。
まずは、AI 構築のための教師データを作るため、テスト用動画の撮影を行いたいのですが、PR にも記載したとおり、片手にヤカンを持ってコーヒー抽出を行いながら、キッチンスケールの液晶画面を撮影するのは至難の業です。また、安定した画像分析のためには、動画の画角や光の反射具合などの撮影条件をなるべく同一にしたい、という技術課題がありました。
3D プリンターの活用
そこで、数年前に興味本位で購入したものの、押し入れに眠ったままになっていた 3D プリンターを活用して、動画撮影のためのスマホ台、Amazon Coffee Recipe Recorder (Amazon CR2) の製作を行いました。3D モデルのデザインは初めてだったので、ツールの使い方に苦労しつつ何度か試作を重ねた結果、最終的に、様々なキッチンスケールに対応できるよう、パーツの追加によって大きさが調節できる組み立て式のスマホ台 (CR2v2) に落ち着きました。

3D モデルのデザイン

3D プリンターで製作

出来上がったスマホ台
コーヒー抽出中のキッチンスケールを撮影

動画の前処理
撮影した動画の前処理には、AWS Elemental MediaConvert を利用しました。このサービスは、動画ファイルを様々なフォーマットにノーコードで変換できる動画変換サービスで、出力フォーマットの一つとして静止画 (JPEG) に対応しています。また、他の AWS サービスと同様に API 連携で自作のアプリケーションに組み込むことが可能です。
今回使用したキッチンスケールは、約 0.5 秒ごとに液晶の数値が更新されます。試しに 0.5 秒ごとに 1 回のフレームキャプチャを行い、生成された画像を確認してみました。するとこちらの図のように、液晶の濃淡が切り替わっている最中のために、人間でも数値の読み取りが困難な画像が多数キャプチャされることがわかりました。
読み取るフレーム数を増やせば数値を正しく読み取れる画像を確実にキャプチャすることが可能ですが、画像枚数が増えると、AI による数値読み取りにかかる時間も増大します。調整の結果、今回は 0.25 秒ごとに 1 回のフレームキャプチャを行うことで、確実に液晶数値を読み取りつつ、最小限の画像枚数とできることがわかりました。

画像のアノテーション
生成した静止画を、Amazon SageMaker Ground Truth を使ってラベル付け (アノテーション) しました。機械学習用データセットのラベル付けを簡単に行えるデータラベリングサービスで、同僚やサードパーティのワーカーにラベル付けタスクを依頼し、ブラウザ上で作業を行うことができます。
今回は私一人で 1000 枚以上のラベル付けを行う必要があったため、Amazon SageMaker Ground Truthと統合されている Amazon Mechanical Turk を活用してラベル付けを実施しました。
このサービスでは、コンピュータでは不可能な処理を第三者のワーカーに任せることができます。一人で行うと丸一日以上かかってしまうアノテーション作業を多数のワーカーに協力してもらうことで、作業開始から 3 時間でラベル付けを完了することができました。なお、アノテーション作業を外部委託する際には、ワーカーに正しくアノテーション作業を実施してもらうために、アノテーション依頼時の説明文に正しいラベルの例と間違ったラベルの例の画像を含めるなどの工夫が重要です。ラベル付けの精度を高めるためには、一枚の画像に対し複数人でのラベル付けを実施し、多数意見を採用するなどの品質コントロールを行うことも検討しましょう。
これで、ラベルの付いた画像ファイル一式、つまり機械学習用のデータセットが完成しました ! 次はいよいよ学習です。

Amazon Rekognition カスタムラベルでの AI 学習
Amazon Rekognition カスタムラベルでは、はじめにカスタム画像分析モデルを管理するプロジェクトを作成し、データセットを登録します。データセットは、S3 やブラウザからの画像アップロードや、SageMaker Ground Truth で作成したラベル付き画像のインポートを行うことでプロジェクトに追加できます。
Rekognition のコンソールでも、データセットのプレビューやラベル付けが可能ですが、大量の画像を登録する場合は、SageMaker Ground Truth を活用して複数人でラベル付け作業を行うことをお勧めします。ここまで準備できれば、あとはブラウザ上で数クリックするだけで、モデルの学習が開始されます。学習開始後数時間待つと構築が完了し、モデルの性能テスト結果が生成されます。
今回作成した 7 セグメントディスプレイの数値読み取りモデルは、用意したテスト画像に対し 98% の正答率で正しく数値を認識できることが確認できました。
今回のアプリケーションでは、動画に映っている液晶の数値をグラフ化するために、 0.25 秒ごとにフレームキャプチャし、一度の推論で数百枚の画像を読み込みます。そのうち数枚で誤認識が発生しても、アプリケーション側のロジックで異常値をフィルタリングすれば、本来の目的であるグラフの描画には大きな影響はないと考え、このモデルを組み込んで開発を継続することにしました。
このように、作成した AI が 100% の精度を叩き出すことはまずないため、誤認識が発生しても実装の工夫でビジネス上の支障がないようにすることが重要です。

AWS Amplify によるフロントエンド構築
ここまでで、ようやく AI バックエンド部の開発が完了しました。続いては、フロントエンドの構築を行います。今回は、AWS Amplify を活用して、フロントエンドに直接紐付く認証機能や API といった一部クラウドリソース部分の構築も実施しました。まず、Vue.js のプロジェクトを作成して Amplify の初期設定を行い、Auth カテゴリ、API (GraphQL) カテゴリ、Storage カテゴリの初期設定を行います。自動作成された GraphQL スキーマファイルを編集し、amplify push コマンドで AWS のリソースの構築が完了します。設定したリソースを組み合わせ、フロントエンドの構築が完了しました。
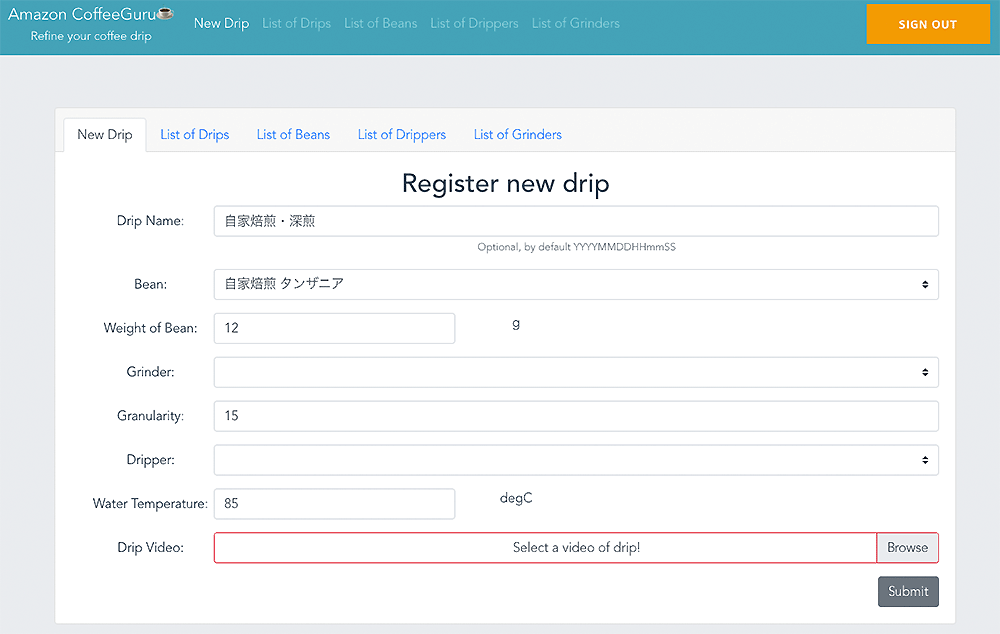
フロントエンド画面 1
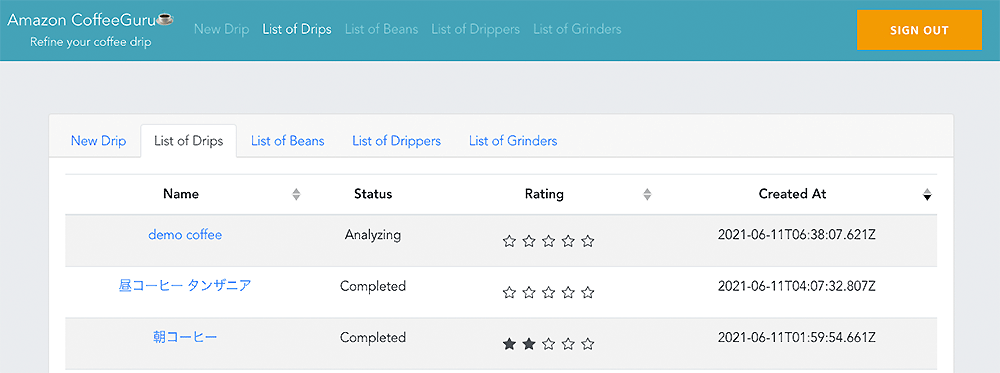
フロントエンド画面 2
AWS SAM によるバックエンド構築
最後に、AWS SAM を使って、アップロードされた画像をイベント駆動で推論するロジックを構築しました。
今回は PoC なので、経費節約のため、動画がアップロードされたときに Rekognition カスタムラベルのエンドポイントを立ち上げ、推論が終わったら終了させる設計にしました。このように複数の操作を連携して行いたい場合には、ローコードで AWS サービスのワークフローを作成できる AWS Step Functions が便利です。Step Functions では、ブラウザ上で 200 以上の AWS サービスを視覚的に連携できる ワークフロースタジオ を利用して、迅速にステートマシンの構築ができます。本プロジェクトの実行時 (2021 年 5 月) にはまだこの機能がリリースされていなかったため、4 つの Lambda 関数をステートマシンで連携することで、推論結果をデータベースに書き込むバックエンドアプリケーションを構築することができました。
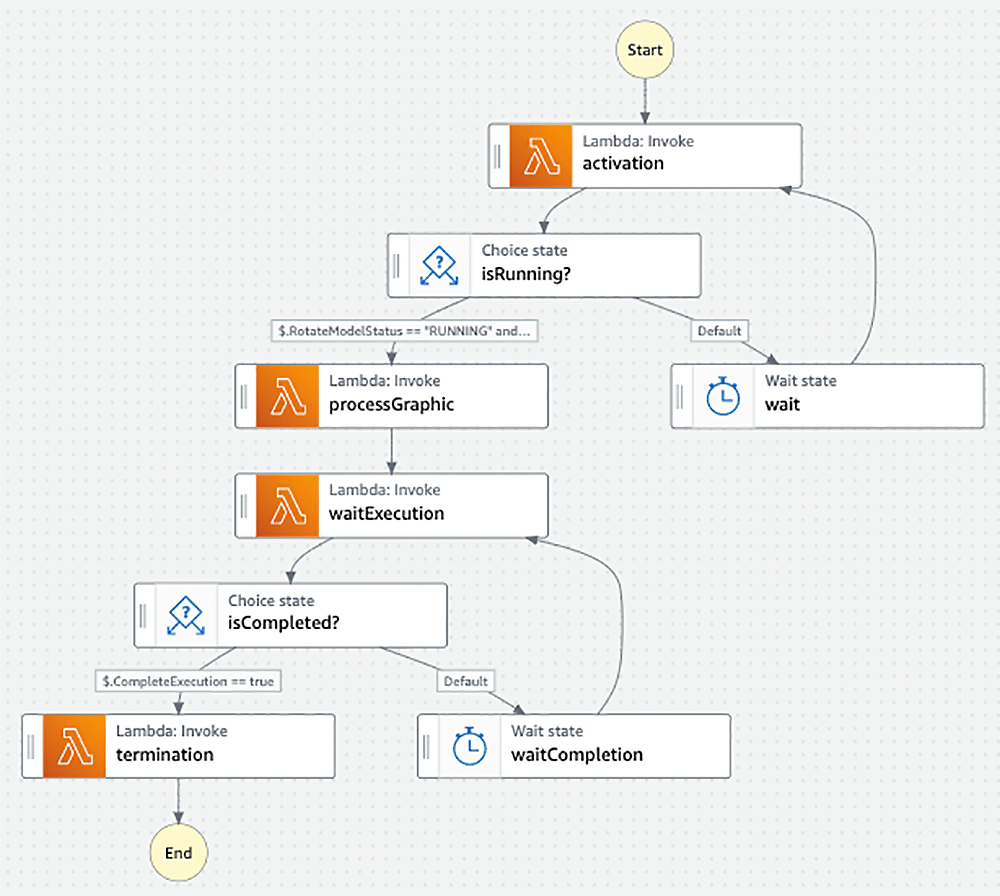
完成!
以上で、すべての開発が終了しました。
実際に、コーヒー抽出を行って動画を登録してみると、ちゃんと冒頭の VIsual に描いた通りの注湯プロファイルを記録することに成功しました ! アプリ上に、淹れたコーヒーの香りの特徴や味の感想をメモすることで、美味しいコーヒーを淹れるための秘訣を蓄積でき、データドリブンなコーヒー生活が楽しめそうです ! コーヒー好きの友人たちにデモをしてみたところ、使ってみたいと好評でした。これはビジネス化も期待できそうです。
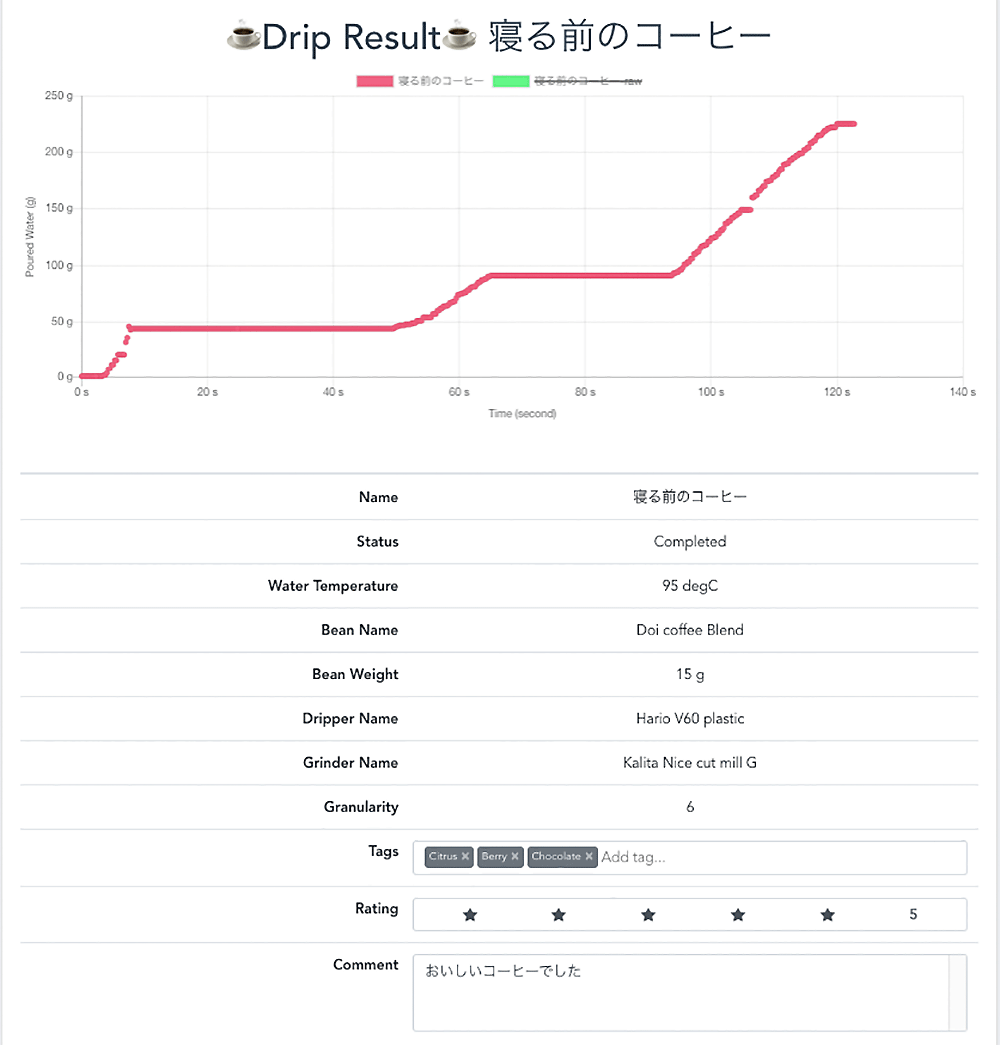
プロジェクトを通じてわかったこと
PoC を行うことで、技術面の課題がいくつか明らかになりました。
今回の実装では、実は一杯のコーヒー抽出 (約 2 分) の動画分析に 12 分もの時間を要してしまっています。原因を分析したところ、毎秒 4 フレームという大量の画像推論を実施する部分がボトルネックとなっていました。また、実装に非効率な部分が多く、一杯あたりの AI 費用が約 100 円かかることもわかりました。我が家でふだん飲んでいるコーヒー豆代 (一杯 65 円) よりも高価であり、これではとても、ユーザーに使ってもらえません。
今回の PoC では、Rekognition カスタムモデルを活用して機械学習のコードを書かずに短期間でのプロトタイピングを実現することができましたが、事業化にむけては、画像枚数の削減による推論ロジックの高速化や、SageMaker Serverless Inference の活用による推論費用の最適化など、ユーザー体験や費用を考慮したアーキテクチャの最適化を検討する必要がありそうです。
このように、マネージドなクラウドサービスを活用して高速にプロトタイピングを行うことで、ビジネスアイディアの価値の確認や技術課題の洗い出しをスピーディに行い、新サービスの事業化を速やかに進めていくことができます。
まとめ
本記事では、Amazon 流のビジネス企画手法である Working Backwards を適用して「至福のおうちコーヒーを極める」ための Web サービスを企画し、概念実証を実行する過程をご紹介しました。本記事で紹介した各種サービスを実際に触ってみたい ! という方は JP Contents Hub から様々なハンズオンを体験いただけます。
また、アマゾン ウェブ サービス ジャパンでは、キャリア採用アソシエイトソリューションアーキテクトの研修プログラムとして、お客様起点のサービス開発を実際に体験する「疑似プロジェクト」を実施しています。ソリューションアーキテクトチームでは様々なバックグラウンドを持った方が働いており、AWS 未経験でジョインし、研修を通じてスキルを身につけ活躍しているソリューションアーキテクトも多く在籍しています。興味を持っていただけた方は、ぜひ ソリューションアーキテクト キャリア採用 ページをご覧ください。皆様のチャレンジをお待ちしています !
筆者プロフィール
岡本 晋太朗
アマゾン ウェブ サービス ジャパン 合同会社
ソリューションアーキテクト
石油化学プラントの計装制御エンジニアとして東南アジアを駆けずり回った後、プラントデジタルツインソリューションの開発エンジニアに転身し、その過程で触ったクラウドが面白くなりアマゾン ウェブ サービス ジャパンに入社。現在は、製造業のお客様を中心に、クラウド活用の技術支援を担当しています。
趣味はコーヒーと中国茶、好きなコーヒー豆はイエメンモカです。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages