- AWS Builder Center
- builders.flash
Amazon Kendra で簡単に検索システムを作ってみよう !
2023-02-02 | Author : 高橋 佑里子

はじめに
みなさんこんにちは ! ソリューションアーキテクトの高橋佑里子です。
突然ですが、「社内の書類が多すぎて必要な情報を探すのに毎回時間がかかっている」といったお悩みはありませんか ? このようなお悩みは、検索システムを導入することで解決できる可能性があります。社内に検索システムを導入することで、過去の資料や回答を素早く見つけることができるようになるため、生産性の向上が期待できます。
また、検索システムは、社内向けだけでなく社外向けにも適用できるソリューションです。例えば、提供しているサービスの複数のマニュアルページに対して検索機能を追加することで、ユーザーは知りたい情報をすぐに手に入れることができるようになるため、顧客体験の向上に繋がります。
AWS にはこのような場合にご利用いただける、Amazon Kendra という AI サービスがあります。Amazon Kendra を使うと、機械学習を使ったドキュメントの検索システムを簡単に構築することができます。
本記事では、この Amazon Kendra について、実際に検索を体験する手順を含めてご紹介します ! 今まで Amazon Kendra を知らなかった、という方もこれを機に興味を持っていただけると嬉しいです。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
1. Amazon Kendra とは?
Amazon Kendra は、機械学習を活用したマネージドな検索サービスです。このサービスを使用することで、誰でも簡単に検索システムを構築することが可能です。
実は、英語版の AWS のドキュメント検索機能の裏側は Amazon Kendra が担っています。こちらは実際の検索画面ですが、「Powered by Amazon Kendra」と書かれています。

次に、Amazon Kendra がどのような検索をすることができるかご説明します。Amazon Kendra は、以下の 3 つのタイプの質問および検索に対応しています。
-
Factoid 型の質問
Factoid 型の質問は、誰が、何を、いつ、どこで、といったことを問う質問です。Factoid 型の質問に対しては、1 単語または 1 語句で事実ベースで回答することができます。例えば、「Kendra が一般利用可能になったのはいつですか ?」という質問が Factoid 型の質問となります。 -
Non-Factoid 型の質問
Non-Factoid 型の質問は、1 文、1 節、またはドキュメント全体が答えとなる質問です。Non-Factoid 型の質問に対しては、理由や事象の説明に基づく回答が必要になります。例えば、「Kendra はどのようなサービスですか ?」という質問が Non-Factoid 型の質問となります。 -
キーワードまたは自然言語による検索
複数の単語をスペース区切りにしたり、文章の形で入力して検索する方法です。例えば、「Kendra インデックス 作り方」と入力するのがキーワードによる検索で、「Kendra のチュートリアル」と入力するのが自然言語による検索です。自然言語による検索では、後ほどご説明するセマンティックサーチ機能もご利用いただけます。
1-1. Amazon Kendra で検索できるデータ
Amazon Kendra では、構造化テキストおよび非構造化テキストを検索対象として利用することができます。構造化テキストは、特定の形式に則ったテキストデータのことで、非構造化テキストは、一般的な書類のような特定の形式をもたないテキストデータのことです。
以下は、2023 年 1 月時点でサポートしているファイル形式の一部です。サポートされているファイル形式の詳細については こちら のページをご確認ください。
-
構造化テキスト
-
よくある質問 (詳細は後ほどご説明します)
-
-
非構造化テキスト
-
HTML ファイル (.html)
-
Microsoft PowerPoint プレゼンテーション (.pptx)
-
Microsoft Excel ブック (.xlsx)
-
Microsoft Word ドキュメント (.docx)
-
PDF ファイル (.pdf)
-
続いて、検索対象データの置き場所となるデータソースとしてどのようなサービスが利用できるかご説明します。データソースには、AWS サービスをはじめ、3rd Party も含む様々なサービスをサポートしています。1 つのインデックスに対して複数のデータソースを設定することで、異なるサービスに格納されたデータを横断的に検索することも可能です。
以下は、2023 年 1 月時点でサポートしているデータソースの一部です。サポートされているデータソースの詳細については こちら のページをご確認ください。
-
Amazon S3
-
RDB
-
Amazon RDS for MySQL
-
Amazon RDS for PostgreSQL
-
Amazon Aurora MySQL
-
Amazon Aurora PostgreSQL
-
-
Amazon FSx
-
Box
-
Dropbox
-
GitHub
-
Google Drive
-
Jira
-
Microsoft OneDrive
-
Microsoft SharePoint
-
Salseforce
-
Slack
-
Zendesk
1-2. 利用可能なリージョン
Amazon Kendra は、2023 年 1 月現在、以下の 7 つのリージョンでご利用いただけます。
-
米国東部 (バージニア北部)
-
米国東部 (オハイオ)
-
米国西部 (オレゴン)
-
欧州 (アイルランド)
-
アジアパシフィック (シンガポール)
-
アジアパシフィック (シドニー)
-
カナダ (中部)
2. 主な機能紹介
ここでは、Amazon Kendra の主な機能について紹介していきます。この記事を執筆している 2023 年 1 月時点で日本語に対応している機能については、機能名の後に「(日本語対応) 」と書いています。
2-1. セマンティックサーチ (日本語対応)
セマンティックサーチは、入力された自然言語の意味を理解して、その意味に沿った回答をする技術です。言い換えると、検索をする際にキーワードではなく会話文のような文章を入力しても適切な回答が返ってくる、ということです。このセマンティックサーチ機能は、AWS re:Invent 2022 で発表されたアップデートにより、日本語での利用が可能になりました。
2-2. よくある質問の設定 (日本語対応)
Amazon Kendra では、CSV または JSON ファイル形式で S3 バケットにアップロードし、そのファイルの S3 URI を指定することでよくある質問を設定をすることが可能です。検索対象のデータソースにその質問に関する回答がない場合や、その名の通り頻出な質問に対して確実な回答を提供したい場合に有効です。
2-3. メタデータを付与した検索 (日本語対応)
Amazon Kendra ではデータソースに対してメタデータを付与することができ、それを使用して検索をすることができます。例えば、PDF ファイルのみを検索対象とする、といったことができます。
2-4. チューニング (日本語対応)
Amazon Kendra では、検索結果のチューニングができます。例えば、データソースの種類や作成者、ドキュメントの鮮度に基づいて結果の質を向上させる、といったことが可能です。
2-5. 増分学習
Amazon Kendra には、ユーザーの検索パターンとフィードバックに基づいて検索結果を継続的に最適化する機能があります。あるキーワードに対する検索結果の 2 番目に表示される結果を多くのユーザーが選択した場合、その結果が 1 番目に出てくるようになる、という機能です。
2-6. クエリの自動補完
Amazon Kendra には、ユーザーが入力したクエリに対して自動で補完する機能があります。例えば、「IT デスクは」と入力し始めると、「IT デスクはどこですか ?」や「IT デスクは何階ですか ?」などのオプションや、その他関連するよくある質問を提案する、という機能です。
2-7. 類義語検索
類義語検索は、あいまい検索とも呼ばれる、指定されたキーワードに一致しない要素も候補として使用して検索を行う方式です。例えば、「家」というキーワードが検索で使用されたときに、「住宅」というキーワードも使用して検索を行うということです。現時点では日本語に対応していませんが、Amazon DynamoDB にカスタムシノニムを登録することで実現する方法が こちら のブログで紹介されていますので、興味のある方は併せてご覧ください。
ここで挙げたもの以外にも、細かい機能としてフィルタリング機能やソート機能などを備えています。
3. Edition と料金
Amazon Kendra には、Developer Edition と Enterprise Edition の 2 つの Edition が存在します。これらの主な違いとして、インデックス化できるドキュメントのファイルサイズや数、1 日にクエリできる最大回数、設定できるデータソースの数、冗長化の有無があります。また、Enterprise Edition では追加料金をお支払いいただくことで、より大規模なご利用に対応することが可能です。
次に料金についてです。2023 年 1 月時点での基本料金は、Developer Edition の場合は 1 ヶ月で $ 810、Enterprise Edition の場合は 1 ヶ月で $ 1,008 となっており、Developer Edition には 30 日間の無料枠があります。料金に関する詳細は こちら のページをご確認ください。
4. Amazon Kendra での検索を実際に試してみる
ここから先は、Amazon Kendra での検索を実際に試して理解を深めていきましょう!Amazon Kendra でデータを取り込んで検索する、という一連の流れを 2 時間程度で体験できる簡単なサンプルをご用意しましたので、画面のキャプチャと共に手順をご説明します。所々で待ち時間が発生するため所要時間が長くなっていますが、実際の作業量としては 1 時間程度です。
このサンプルの全体的な流れは、以下の通りです。
-
インデックスの作成
-
データソースとなる S3 バケットの作成と検索対象データの準備
※ 検索対象データとして、AWS のサービスのドキュメントの PDF ファイルを使用します -
データソースの追加
-
よくある質問の追加
-
検索
また、このサンプルはバージニア北部リージョンを使用して行っています。
4-1. インデックスの作成
まずは、Amazon Kendra のインデックスを作成していきます。インデックスは、ドキュメントの内容を保持し、ドキュメントを検索できるようにするために必要な核となる部分です。それでは早速作っていきましょう !
Amazon Kendra コンソールを開く
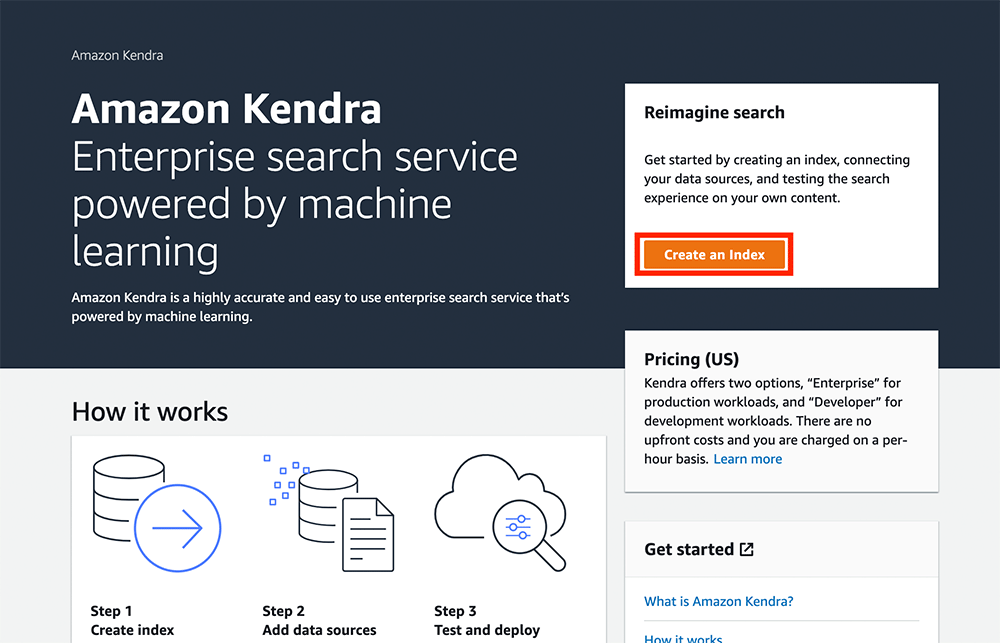
Amazon Kendra のコンソール画面 を開いて、「Create Index」をクリックします。
インデックスを作成
クリックすると、インデックスを作成する画面に移ります。
Step 1 では、インデックスの詳細の設定を行います。こちらのように設定を行います。
-
Index name を「sample-index」に設定します。
-
IAM role で「Create a new role (Recommended)」を選択します。
-
Role name を AmazonKendra-us-east-1-sample-index-role に設定します。(自動的に prefix がつくので、sample-index-role と入力すればOKです。)
-
「Next」をクリックします。
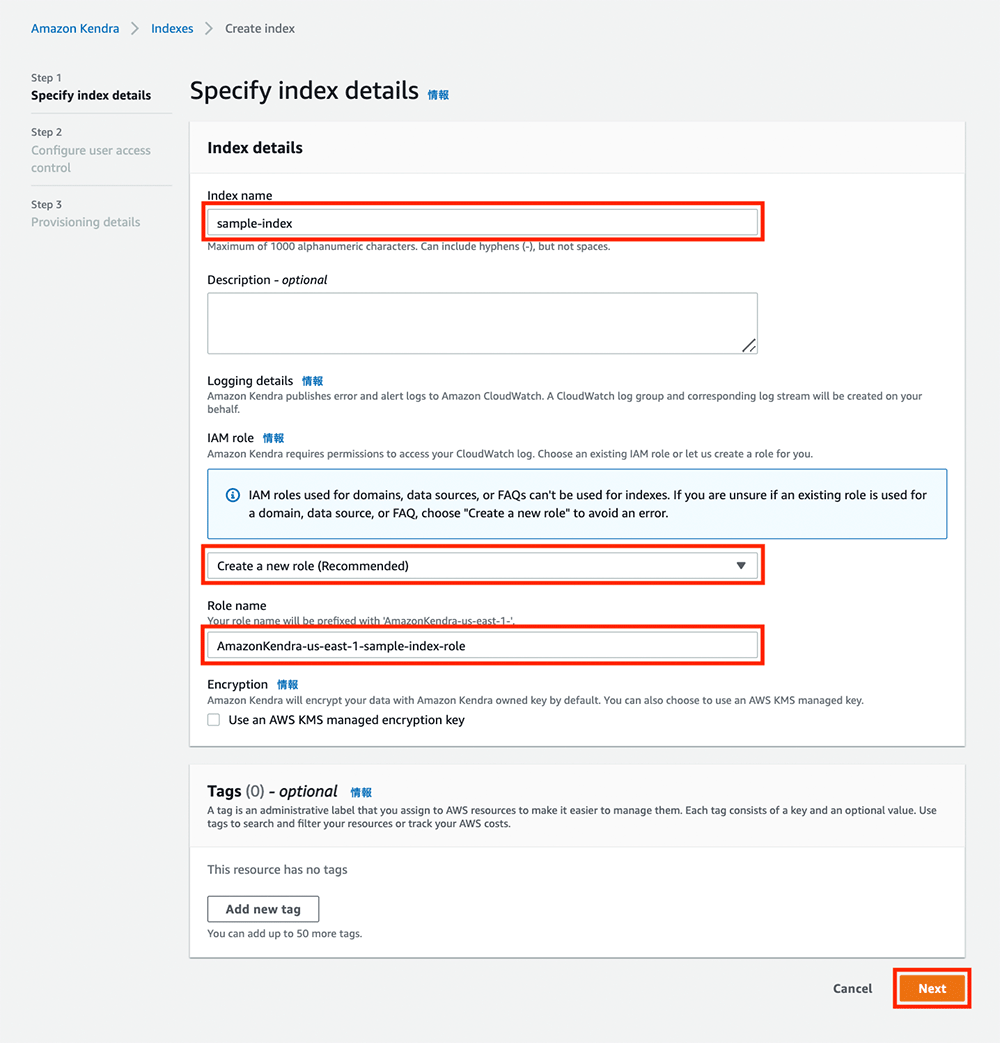
アクセスコントロールの設定
Step 2 では、アクセスコントロールの設定を行います。ここではデフォルトの状態のまま何もせずに「Next」をクリックします。
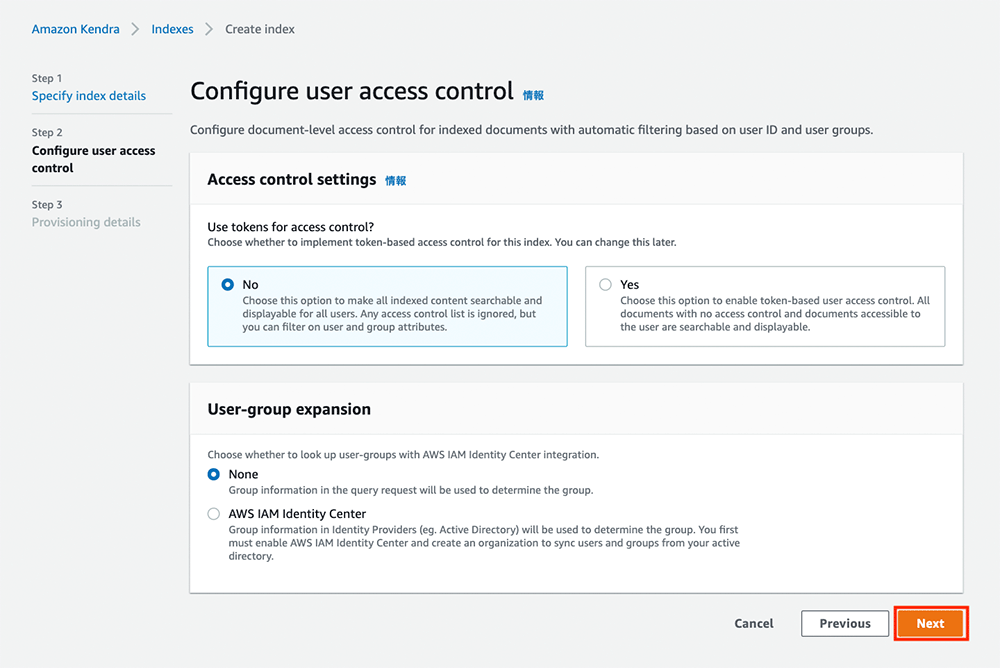
エディションの設定
Step 3 では、エディションの設定を行います。今回は Developer Edition を使用するので、そのまま「Create」をクリックします。
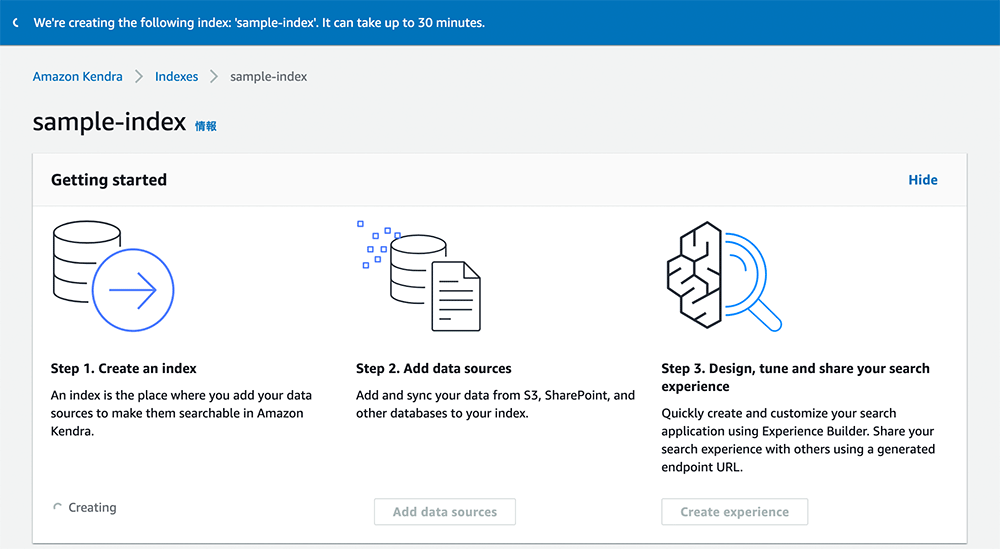
作成中の画面
IAM role の作成とインデックスの作成が始まり、こちらのような画面になります。完了するまで 30 分程度かかります。
インデックスの作成が完了するまでの間に、検索対象とする S3 バケットを作成していきましょう !
4-2. データソースとなる S3 バケットの作成と検索対象データの準備
ここでは、AWS CloudShell でコマンドを実行することで、データソースとなる S3 バケットの作成と検索対象となるデータのダウンロード、アップロードまでを一気に行います。AWS CloudShell は、マネジメントコンソールから直接起動することができるシェルです。
AWS CloudShell を開く
マネジメントコンソール上部にある赤枠で囲ったアイコンをクリックして、AWS CloudShell を開きます。

AWS CloudShell 画面
アイコンをクリックして少し待つとこちらのような画面が表示されます。

コマンドを CloudShell にコピーアンドペースト
以下のコマンドを CloudShell にコピーアンドペーストします。<バケット名> は、ご自身で設定してください。(下の画像の例では、kendra-sample-data-source-yurikooo としています。)
# S3 バケット名を設定
BUCKET_NAME=<バケット名>
# S3 バケットを作成
aws s3 mb s3://${BUCKET_NAME}
# AWS の公式ドキュメントの PDF ファイルをダウンロード
mkdir awsdoc
pushd awsdoc
wget https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-dg.pdf -O Lambda.pdf
wget https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-ug.pdf -O VPC.pdf
wget https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/kendra-dg.pdf -O Kendra.pdf
wget https://docs.aws.amazon.com/ja_jp/Route53/latest/DeveloperGuide/route53-dg.pdf -O Route53.pdf
popd
# S3 バケットに PDF ファイルをアップロード
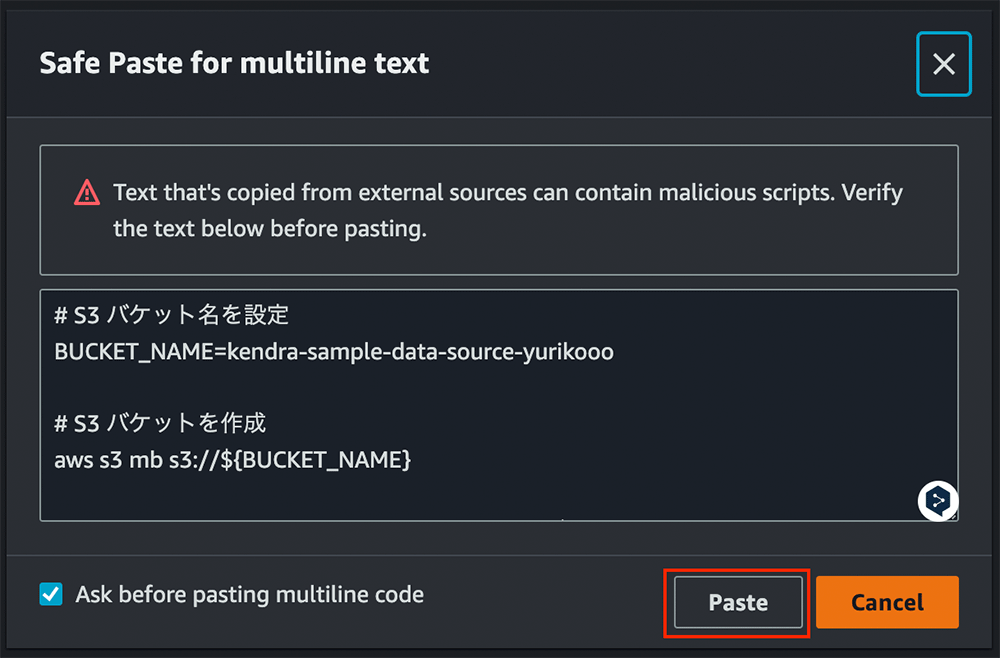
aws s3 cp awsdoc s3://${BUCKET_NAME}/awsdoc/ --recursive確認画面の表示について
※ 複数行にわたるコマンドをコピーアンドペーストするとこちらのような画面が出てくる場合があります。その場合は、左側の「Paste」をクリックしてください。
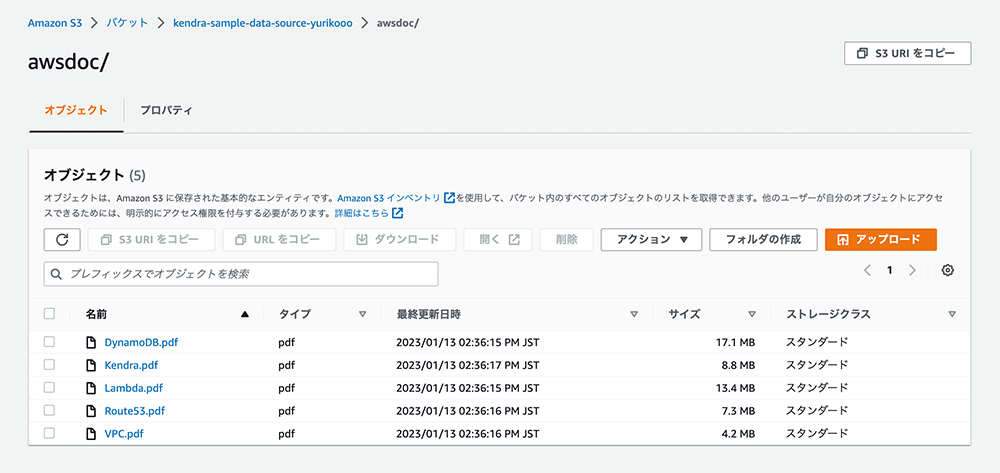
S3 バケットを確認
すべてのコマンドの実行が完了したら、マネジメントコンソールから作成された S3 バケットを確認します。該当 S3 バケットを開くと、awsdoc という名前のフォルダがあり、その中にドキュメントの PDF ファイルが格納されていることが確認できます。
4-3. データソースの追加
次に、先ほど作成したインデックスに対してデータソースを追加していきます。
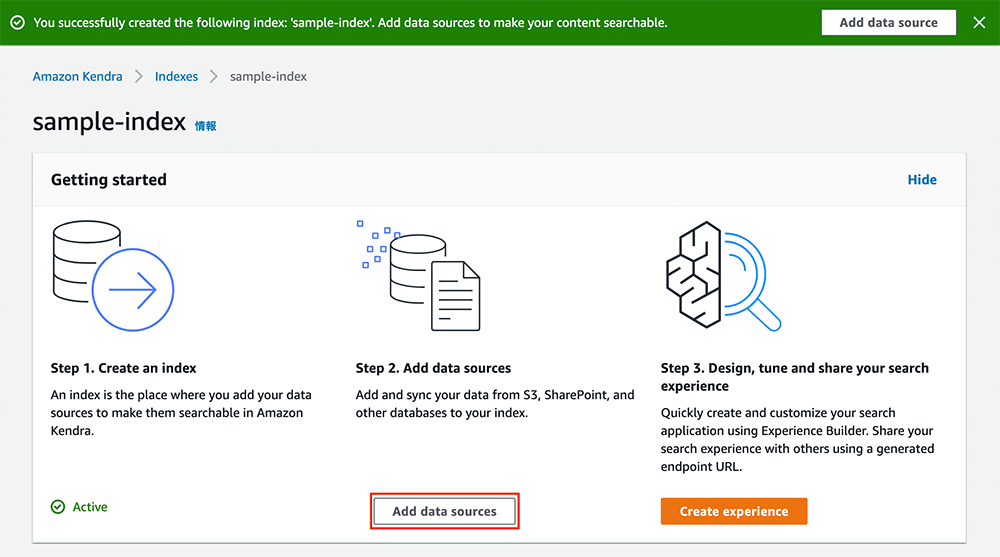
データソースを追加
インデックスの作成が完了するまで待ちます。インデックスの作成が完了すると、緑色のバーが表示され、「Step 1. Creating an index」の下に Active と表示されます。この画面になったら、「Step 2. Add data sources」 の下にある「Add data sources」をクリックします。
データソースを選択
データソースを設定する画面に移ります。少し下にスクロールすると「Available data sources」とあるので、その中の「Amazon S3 connector」の「Add connector」をクリックします。
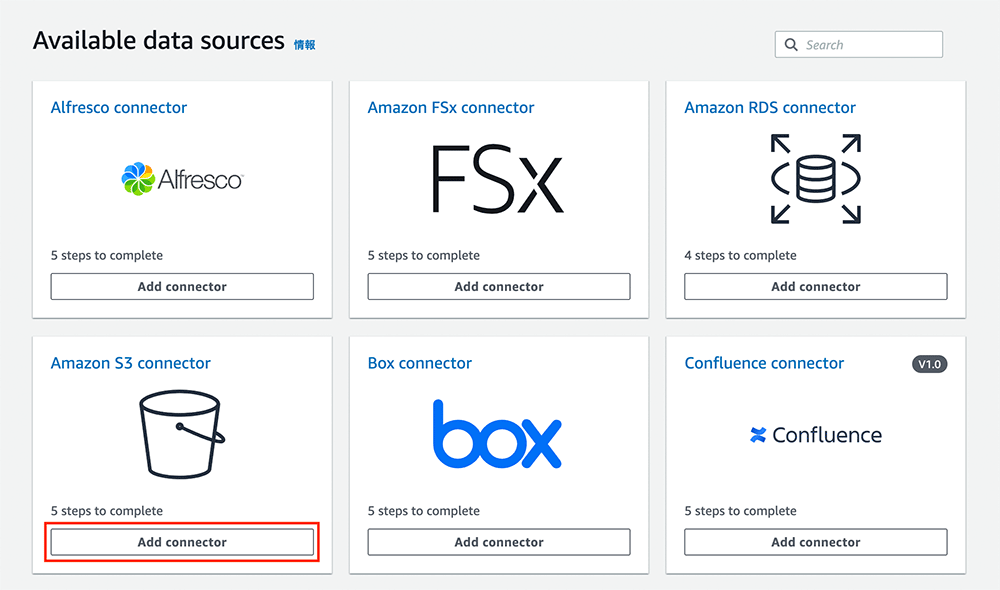
データソースの詳細設定
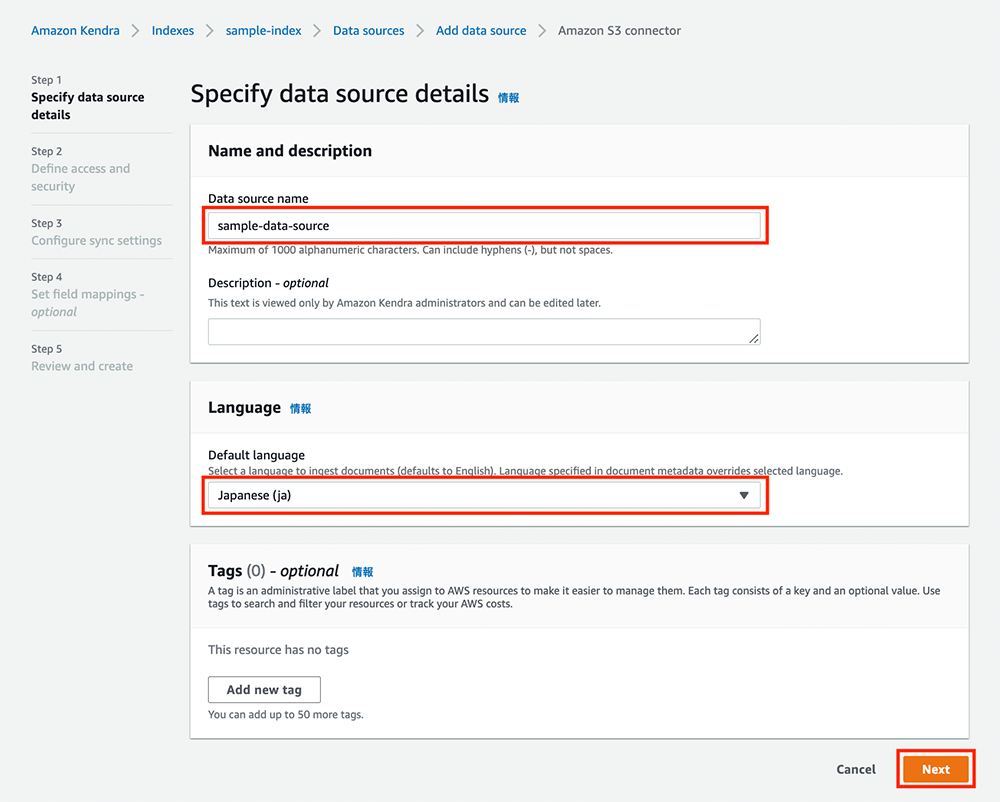
Step 1 では、データソースの詳細の設定を行います。以下のように設定を行います。
-
Data source name を「sample-data-source」に設定します。
-
Default language で「Japanese (ja)」を選択します。
-
「Next」をクリックします。
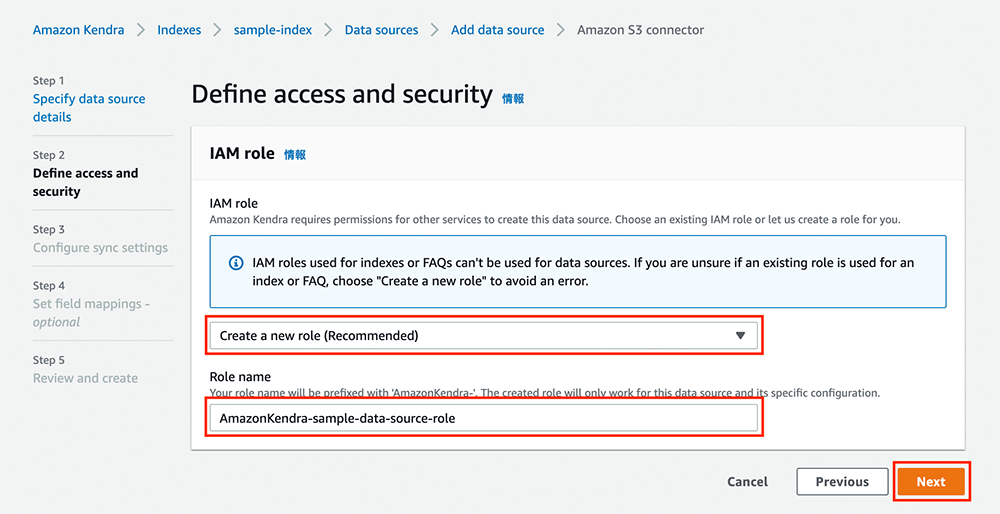
アクセスとセキュリティの設定
Step 2 では、アクセスとセキュリティの設定を行います。以下のように設定を行います。
-
IAM role で「Create a new role (Recommended)」を選択します。
-
Role name を「AmazonKendra-sample-data-source-role」に設定します。(自動的に prefix がつくので、sample-data-source-role と入力すれば OK です)
-
「Next」をクリックします。
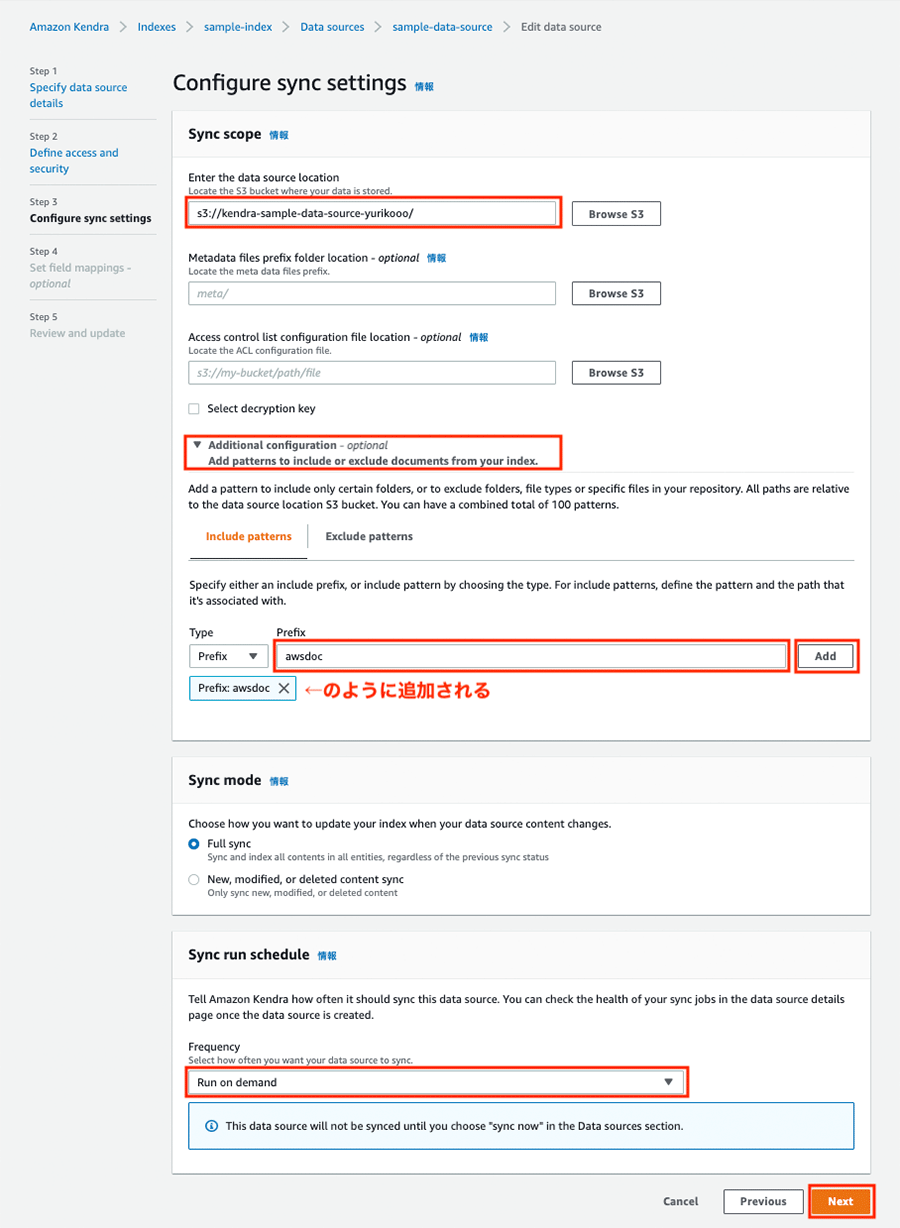
データの同期設定
Step 3 では、データの同期の設定を行います。以下のように設定を行います。
-
Enter the data source location を「s3://<バケット名>」に設定します。<バケット名> は、ご自身で設定したバケット名にしてください。直接入力する形でもいいですし、右側の「Browse S3」ボタンをクリックして該当 S3 バケットを選択する形でも OK です。
-
「Additional configuration - optional Add patterns to include or exclude documents from your index.」をクリックします。
-
Include patterns タブで、Type で Prefix が選択された状態で、Prefix に「awsdoc」と入力して「Add」をクリックします。
-
Frequency で「Run on demand」を選択します。
-
「Next」をクリックします。
フィールドマッピングの設定
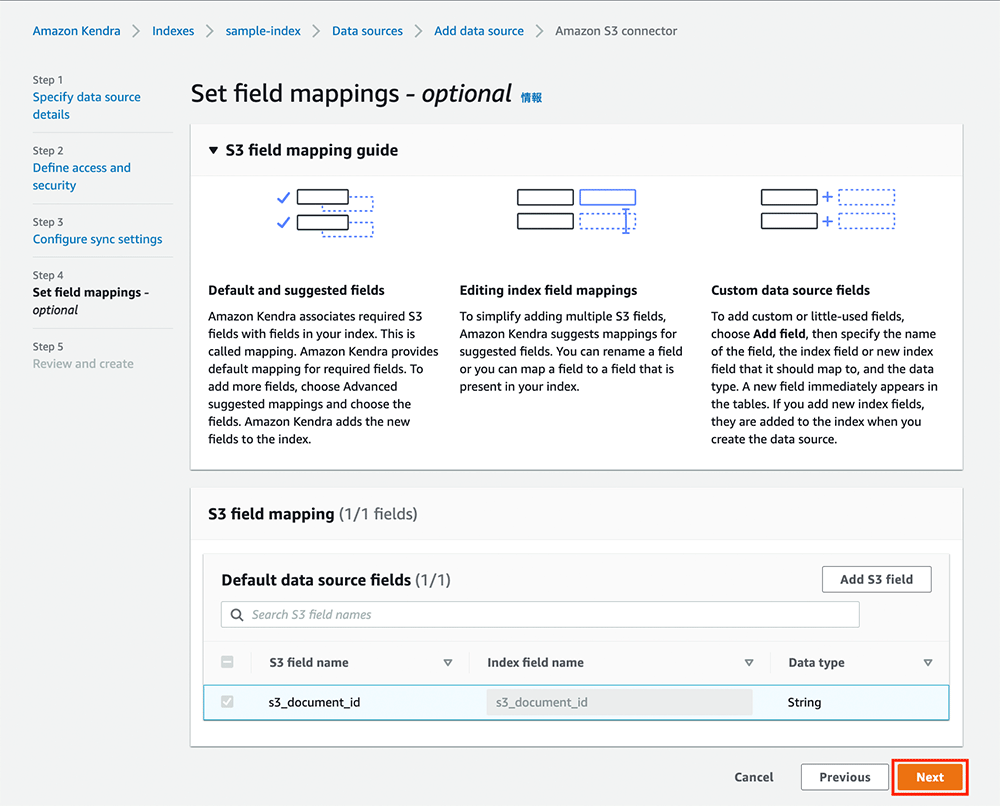
Step 4 では、フィールドマッピングの設定を行います。ここはデフォルトの状態のまま「Next」をクリックします。
確認画面
Step 5 は確認画面なので、内容を確認して一番下にある「Add data source」をクリックします。
データ同期
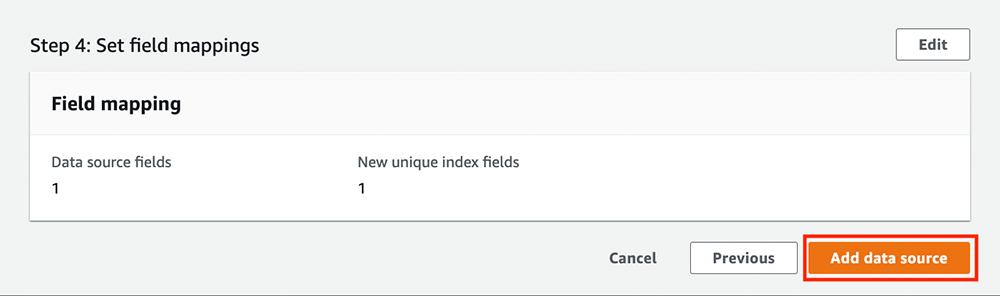
IAM role の作成とデータソースの追加が始まります。完了するとこちらのような画面になります。データソースの追加が終わったら、データの同期を行うために「Sync now」をクリックします。
同期中の画面
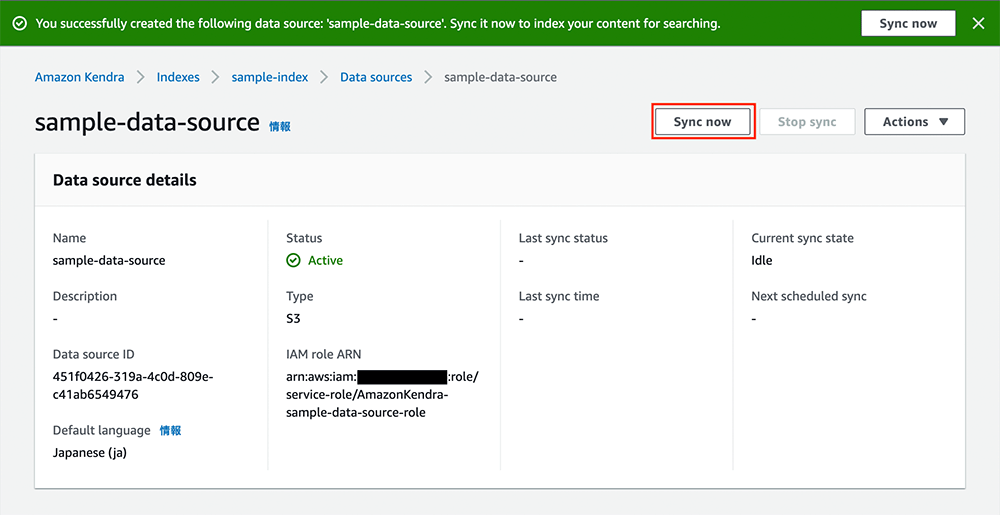
データの同期が始まるとこちらのような画面になります。同期に 30 分程度かかります。
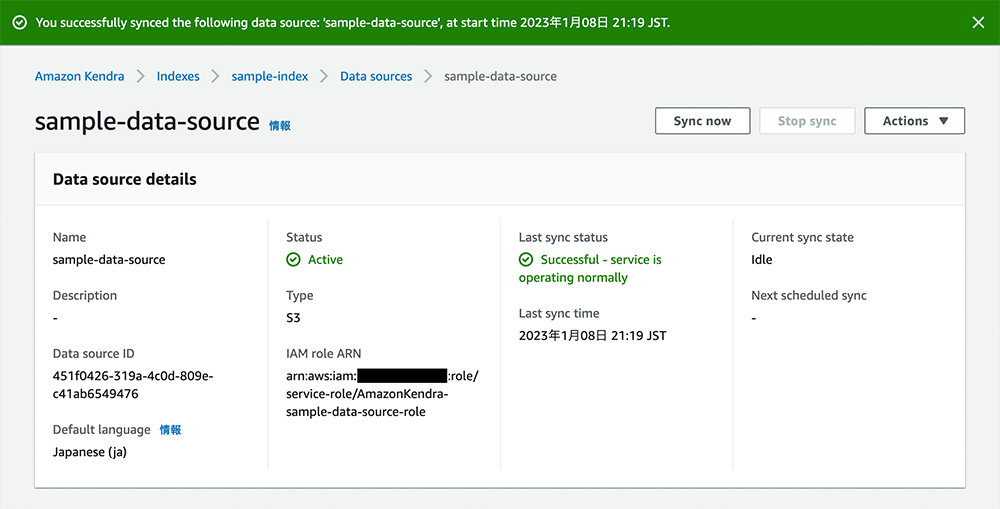
同期の完了
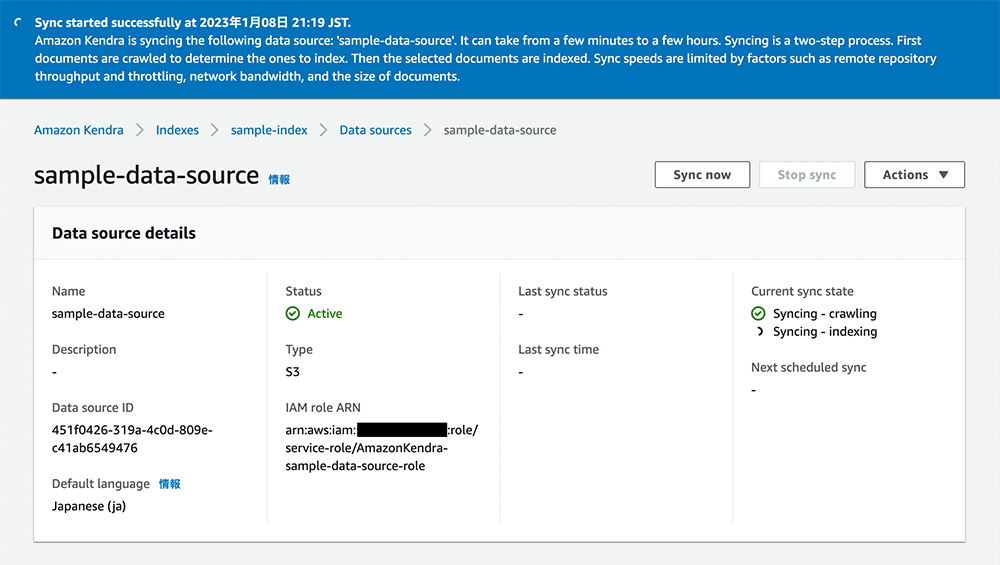
同期が完了すると以下のような画面になります。Current sync state が Idle になっていることを確認してください。
4-4. よくある質問の追加
ここまでで既に検索ができる状態になっていますが、最後によくある質問を追加していきましょう。冒頭でも触れましたが、よくある質問は CSV ファイルを S3 バケットにアップロードして、その URI を指定することで追加できます。
CSV ファイルの形式は、質問内容(必須), 回答 (必須), 参考 URL (オプション) とする必要があります。今回作成する質問の内容は以下の通りです。
-
質問内容 : Amazon Kendra の月額料金はいくらですか ?
-
回答 : Developer Edition は $ 810、Enterprise Edition は $ 1008 です。
コマンドを貼り付け
CloudShell を開いて、以下のコマンドをコピーアンドペーストします。<バケット名> は最初に設定した値で置き換えてください。
# S3 バケット名を設定
BUCKET_NAME=<バケット名>
# sample-faq.csv という名前の CSV ファイルを作成
mkdir faqs
pushd faqs
echo "Amazon Kendra の月額料金はいくらですか?,Developer Edition は $ 810、Enterprise Edition は $ 1008 です。,https://aws.amazon.com/jp/kendra/pricing/" > sample-faq.csv
popd
# CSV ファイルを該当 S3 バケットにアップロード
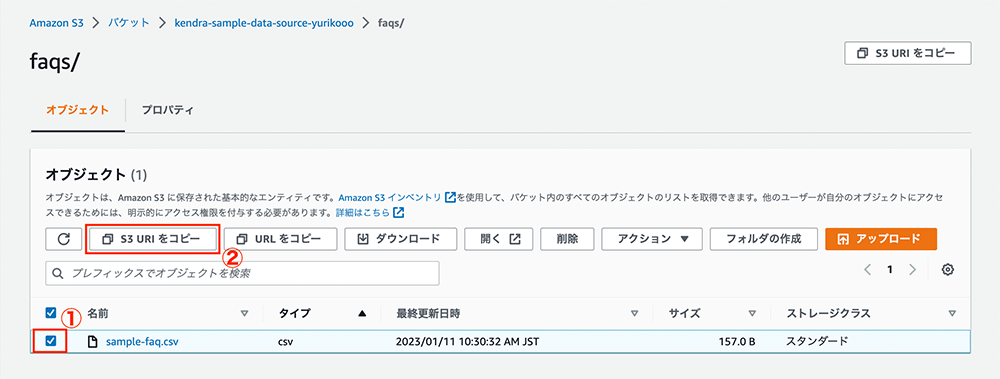
aws s3 cp faqs s3://${BUCKET_NAME}/faqs/ --recursiveS3 URI をコピー
該当 S3 バケットを見ると、faqs というフォルダが作成され、その中に sample-faq.csv が格納されていることが確認できます。「sample-faq.csv」横のチェックボックスにチェックを入れ、「S3 URI をコピー」をクリックします。
よくある質問の設定ページへ遷移
Amazon Kendra のよくある質問を設定するページを開きます。sample-index が選択されている状態で、サイドバーにある「FAQs」をクリックします。
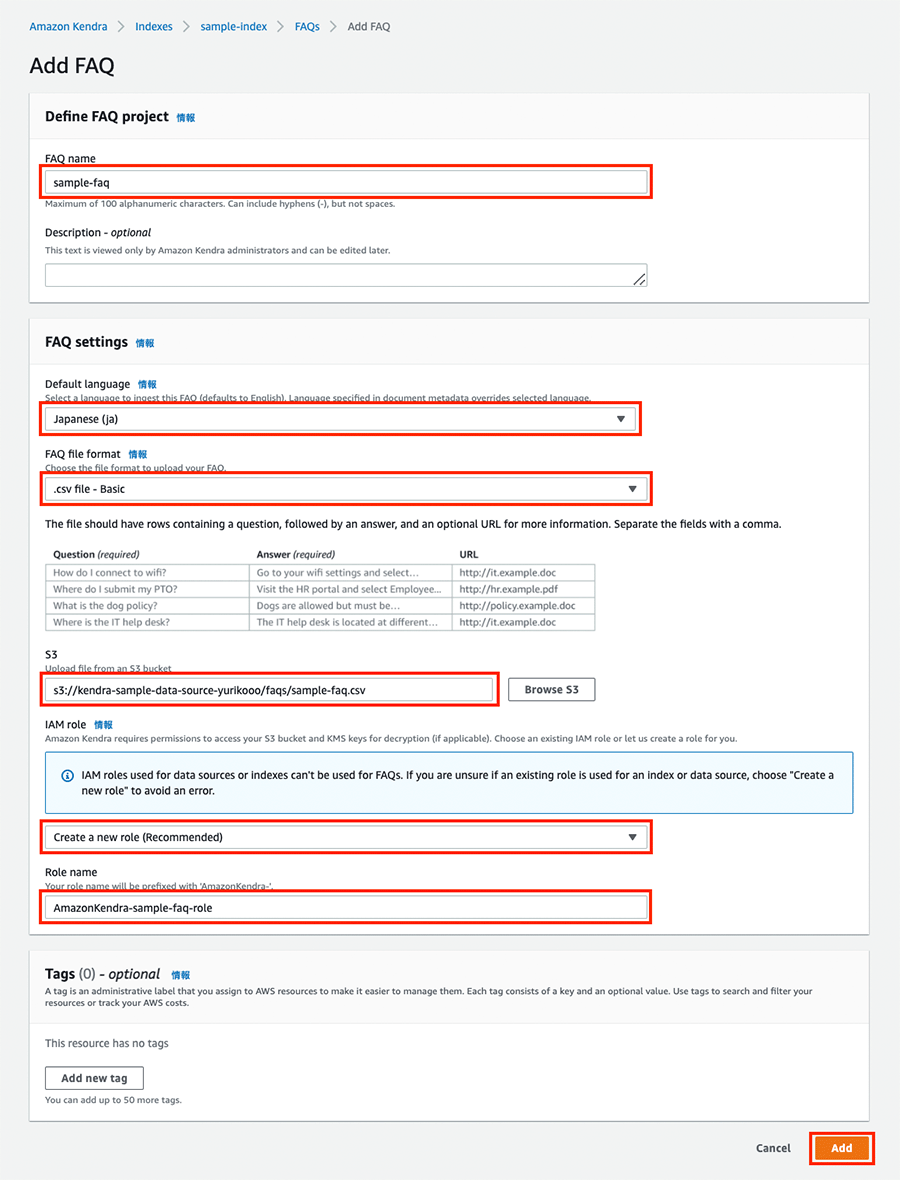
よくある質問を追加
よくある質問を追加します。以下のように設定を行います。
-
FAQ name を「sample-faq」に設定します。
-
Default language で「Japanese (ja)」を選択します。
-
FAQ file format で「.csv file - Basic」を選択します。
-
S3 に先ほどコピーした S3 URI をコピーアンドペーストします。(s3://<バケット名>/faqs/sample-faq.csv と入力します。)
-
IAM role で「Create a new role (Recommended)」を選択し、Role name を「AmazonKendra-sample-faq-role」に設定します。(自動的に prefix がつくので、sample-faq-role と入力すればOKです。)
-
「Add」をクリックします。
作成中の画面
IAM role の作成とよくある質問の追加が始まります。1-2 分ほどかかります。
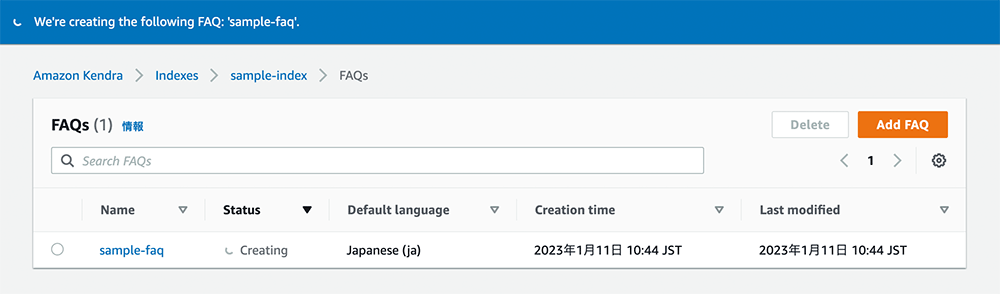
作成完了
IAM role の作成とよくある質問の追加が始まります。1-2 分ほどかかります。
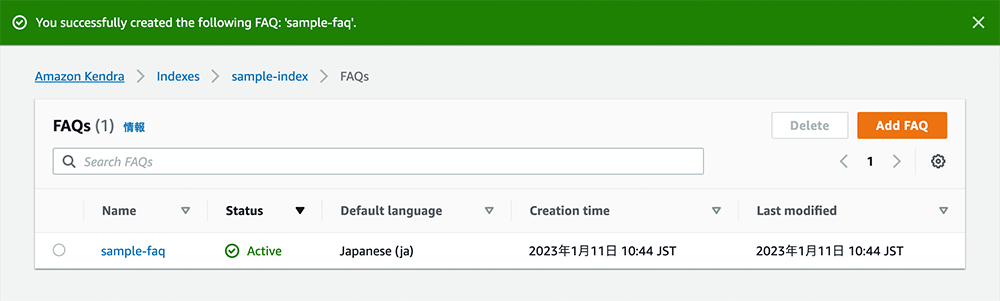
4-5. 検索
ここからは、作成したインデックスで実際に検索を行ってみましょう !
検索するページを開く
Amazon Kendra のインデックスに対して検索をすることができるページを開きます。sample-index が選択されている状態で、サイドバーにある「Search indexed content」をクリックします。
言語設定画面
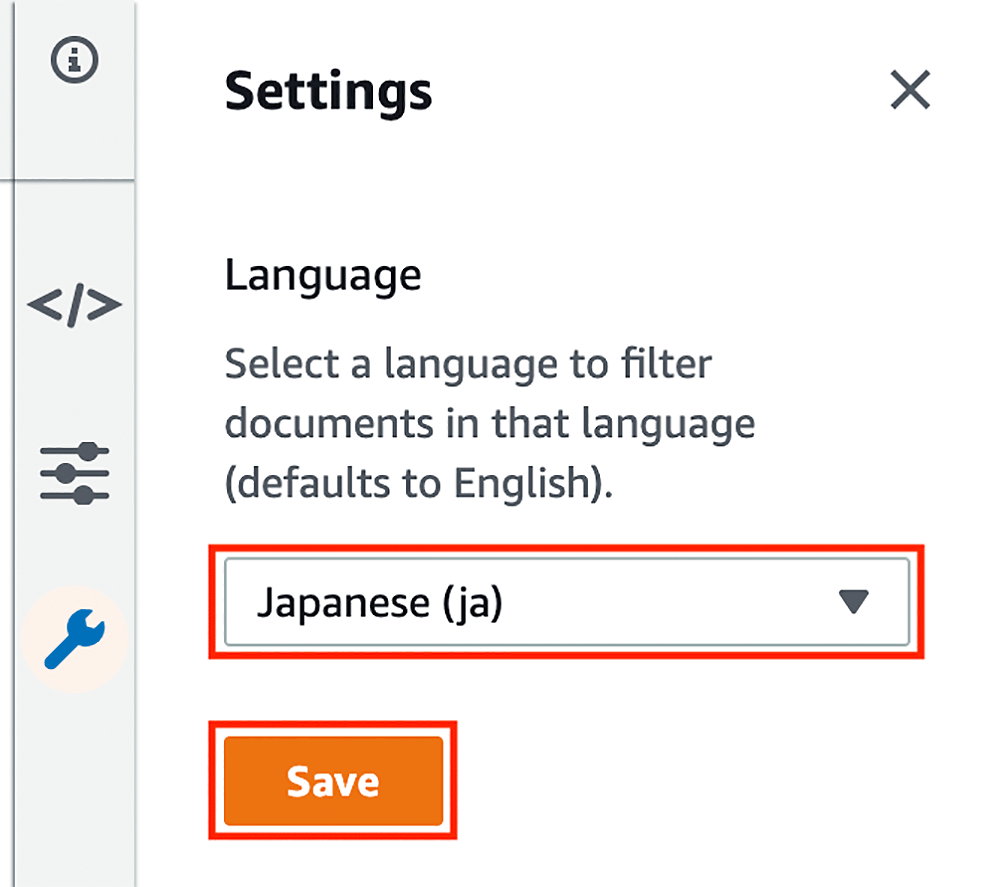
クリックすると、こちらのような画面が開きます。
検索をする前に、言語を日本語に設定する必要があるので、右側の赤枠で囲った設定アイコンをクリックします。
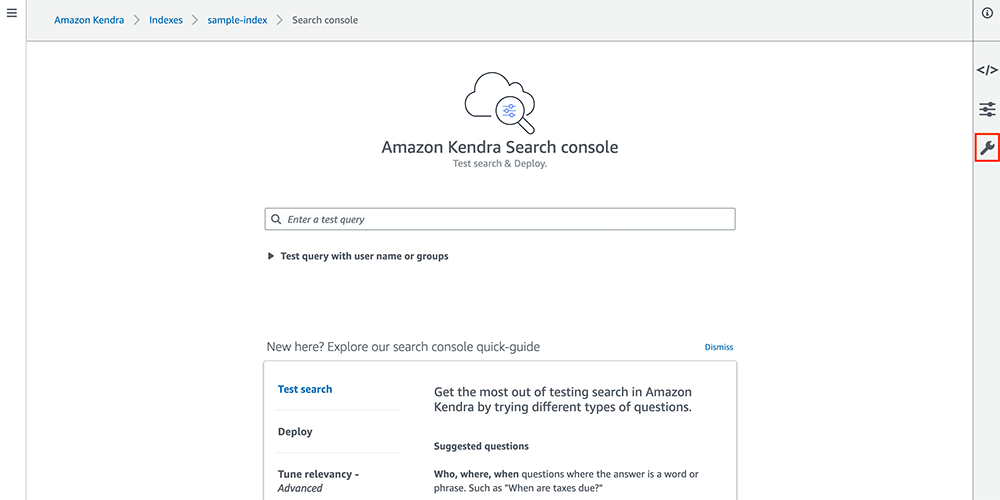
日本語に変更
Language で「Japanese (ja)」を選択し、 「Save」をクリックします。上に Settings applied. と出てきたら設定完了なので、「X」をクリックしてこの画面は閉じてしまって OK です。
キーワード検索を試す
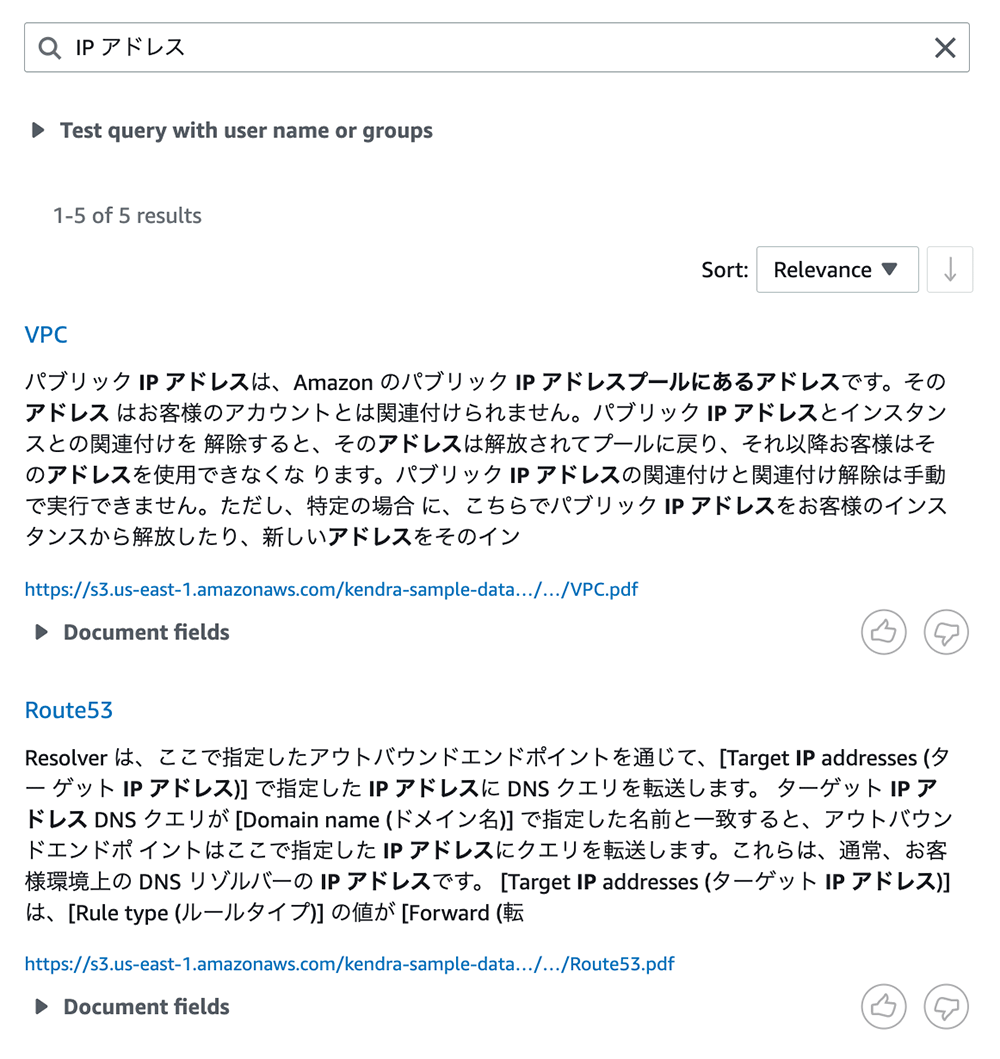
それでは検索していきましょう。まずは、通常のキーワード検索をしていきます。検索バーに「IP アドレス」と入力して、「Enter」キーを押します。そうすると、「IP」と「アドレス」の両方のキーワードが含まれているドキュメントがヒットします。
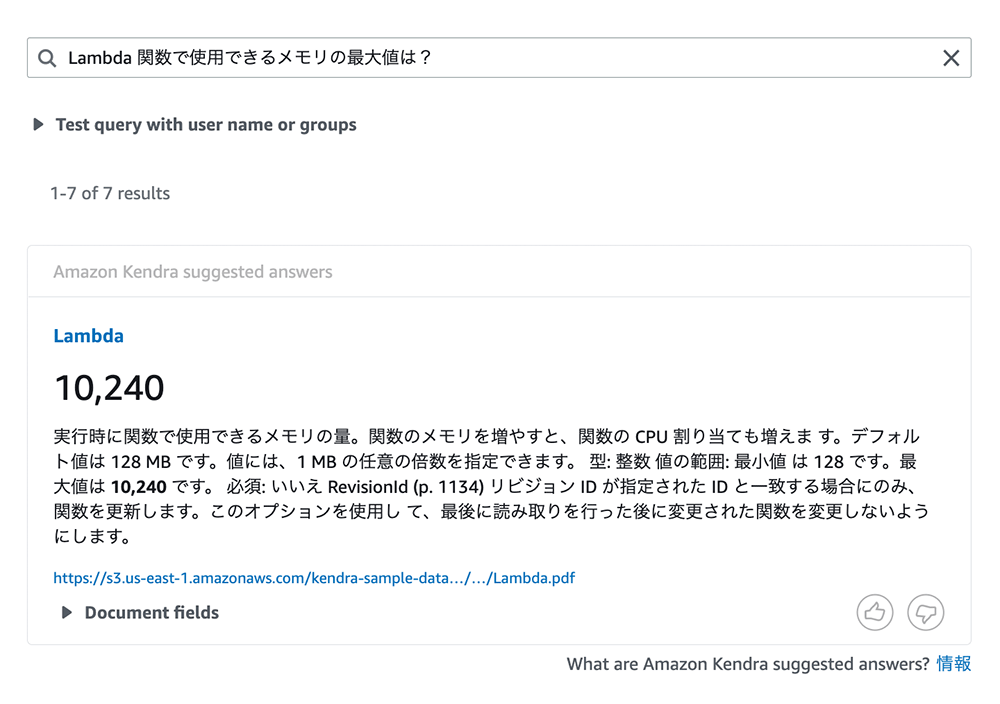
セマンティックサーチを試す
次に、セマンティックサーチの機能を試していきます。検索バー「Lambda 関数で使用できるメモリの最大値は ?」と入力して、「Enter」キーを押します。そうすると、10,240 MB であるという回答が返ってきます。
このことから、キーワード検索だけでなく、文章の意味を理解した検索ができていることが分かります。また、この質問は Factoid 型の質問であるため、単語ベースで回答が返ってきていることも分かります。
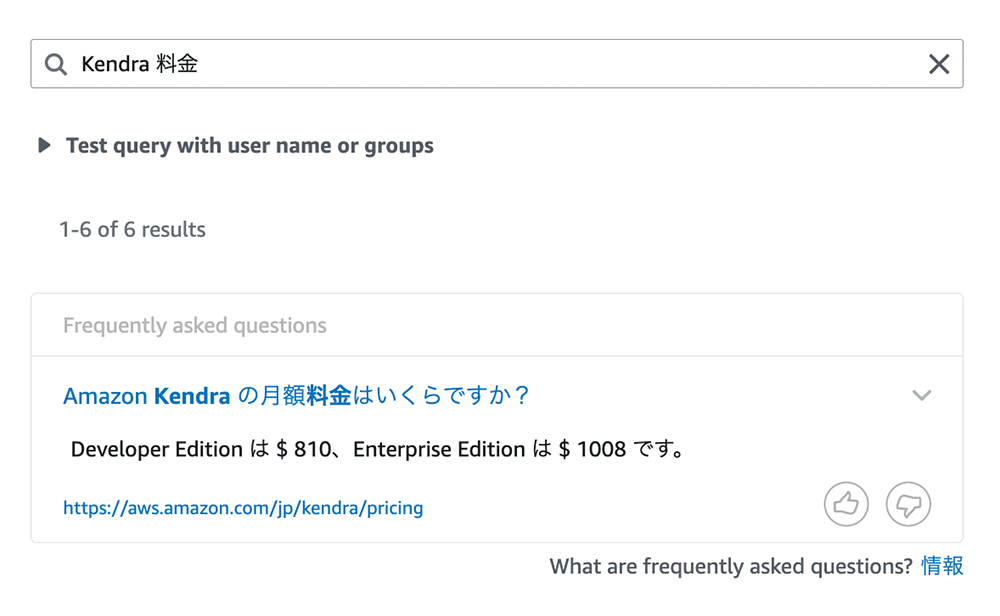
検索結果によくある質問が表示されるか試す
最後に、設定したよくある質問が検索で反映されるかどうかを確認します。検索バーに「Kendra 料金」と入力して、「Enter」キーを押します。そうすると、先ほど登録した質問の内容が回答として表示されます。
5. リソースの削除
作成したリソースを削除します。リソースを作成したまま放置すると課金対象となるので、削除しておきましょう。
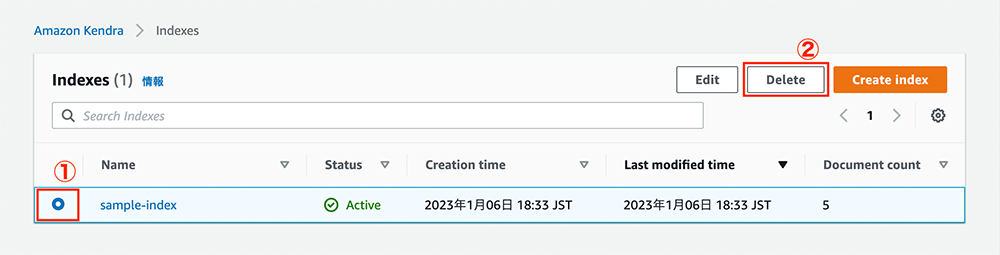
Amazon Kendra のインデックス削除
まず、Amazon Kendra のインデックスを削除します。インデックス一覧の画面を開き、sample-index を選択した状態で「Delete」をクリックします。
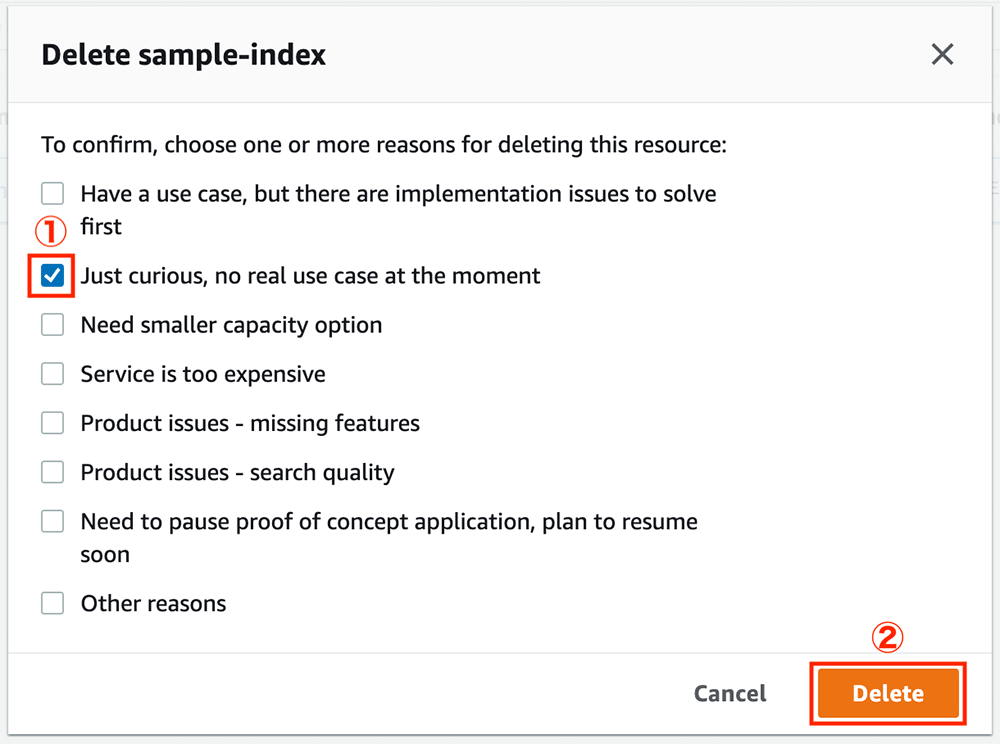
削除確認画面
その後このような画面が表示されるので、Just curious, no real use case at the moment の横のチェックボックスにチェックを入れて「Delete」をクリックします。
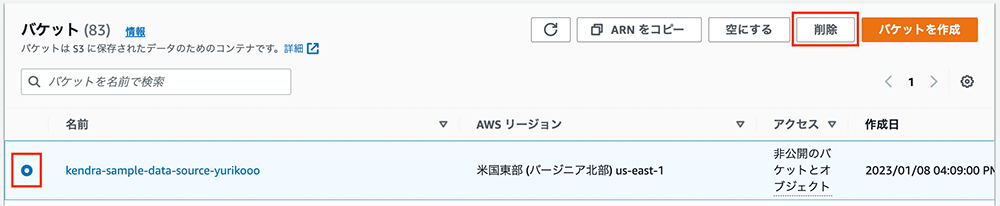
S3 バケットの削除
次に、作成した S3 バケットを削除します。S3 バケット一覧の画面を開き、該当のバケットを選択して「削除」をクリックします。
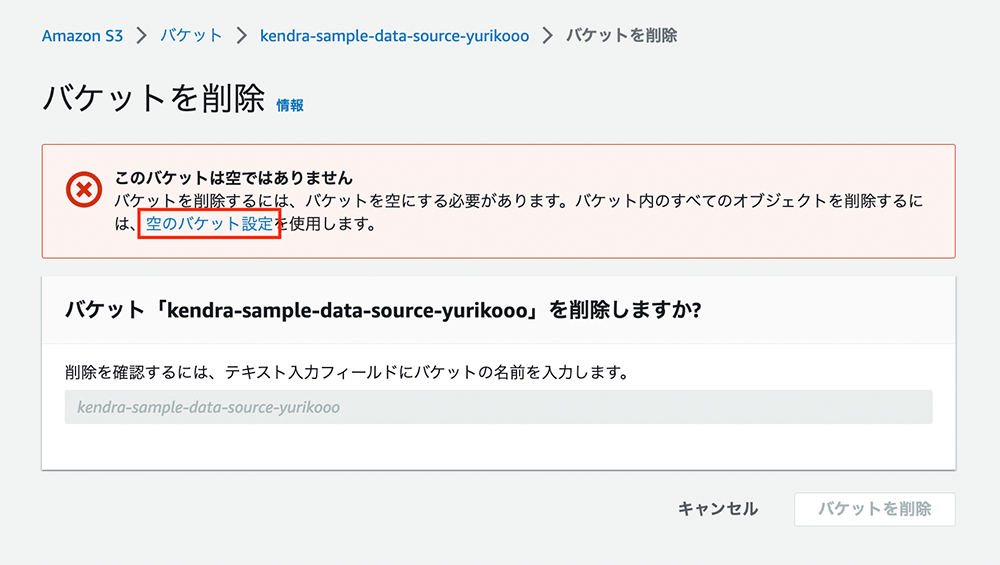
空のバケット設定
削除をする前にバケットの中身を空にするよう指示されるので、「空のバケット設定」をクリックします。
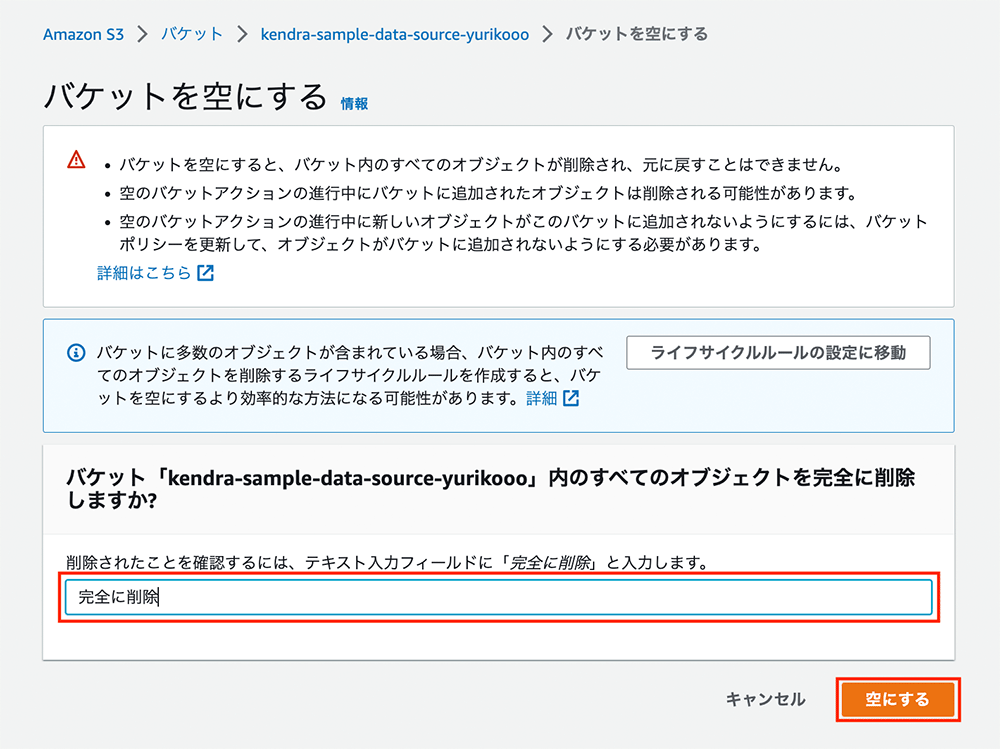
確認画面
バケットを空にする画面で、「完全に削除」と入力して「空にする」をクリックします。
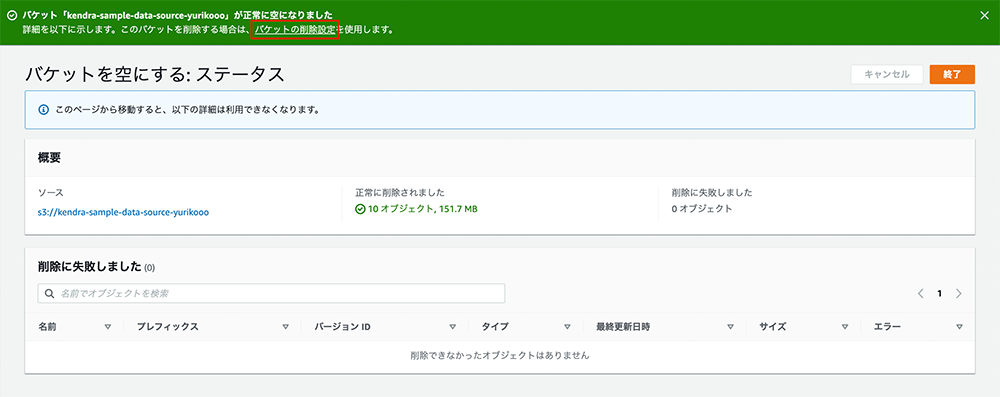
バケットの削除設定
バケットが空になったら、バケットを削除することができます。「バケットの削除設定」をクリックします。
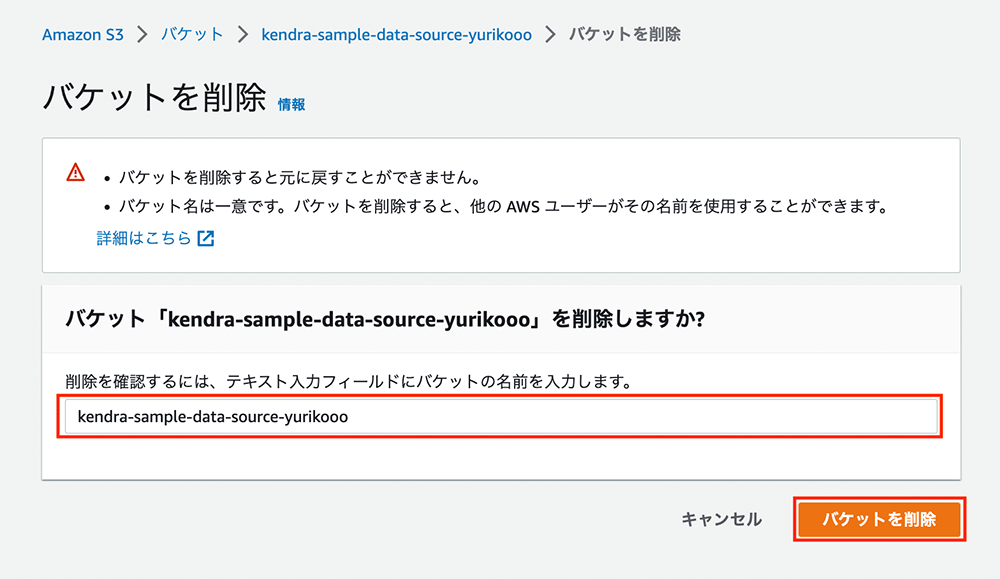
バケットの削除
バケット名を入力して「バケットを削除」をクリックします。
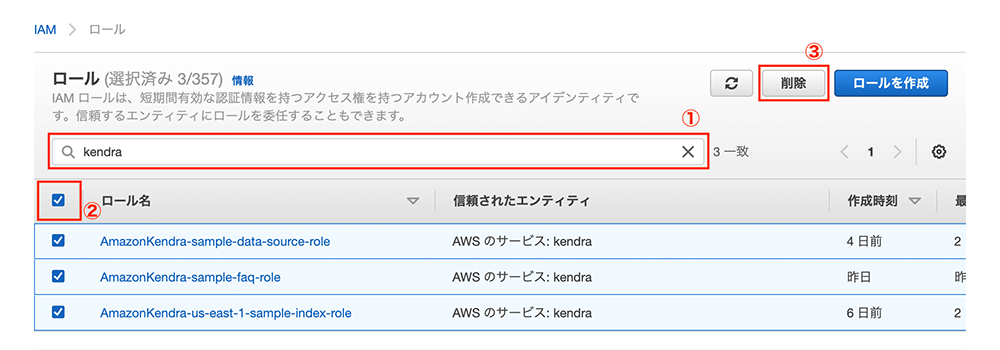
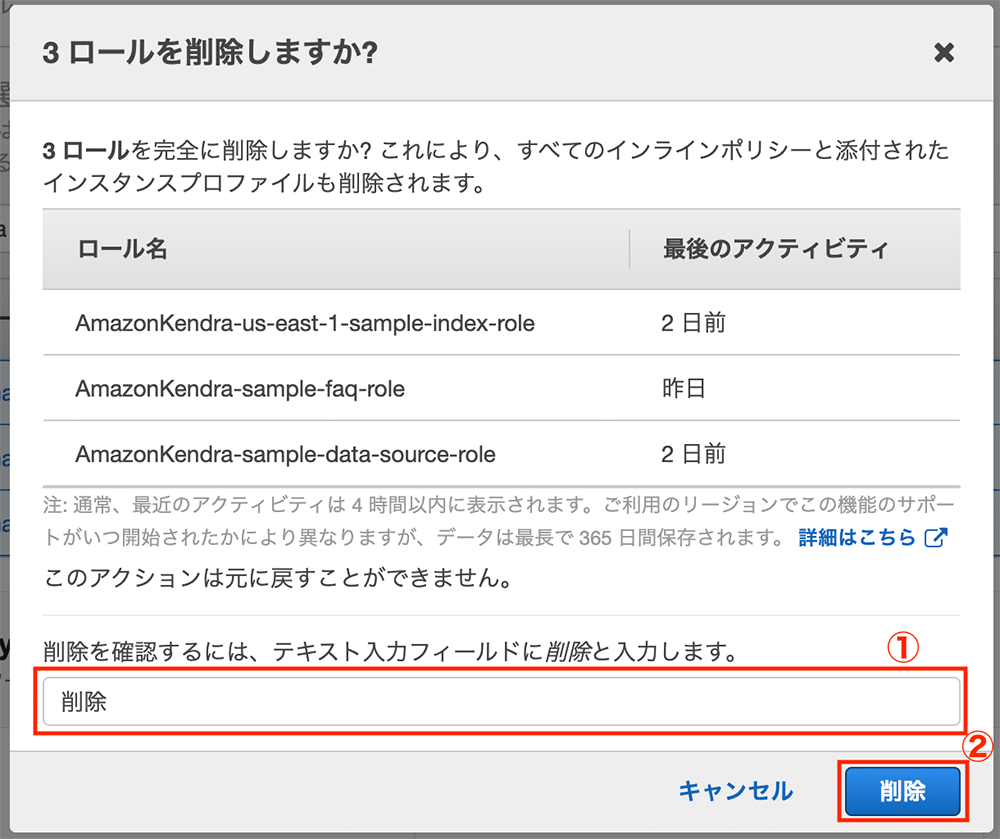
削除する IAM role の選択
最後に、作成した IAM role を削除します。IAM role の画面を開き、検索欄に「kendra」と入力します。すると、今回作成した 3 つのロールがヒットするので、それらをすべて選択して「削除」をクリックします。
IAM role の削除
確認画面が表示されたら 削除 と入力して「削除」をクリックします。
以上で作成したリソースの削除は完了です。
6. まとめ
本記事では、機械学習を活用した検索サービスである Amazon Kendra について、特徴や機能、手軽に検索体験をすることができる手順のご紹介をさせていただきました ! Amazon Kendra には、検索システムを構築する際に便利な機能が多数ありますので、機会があればご利用を検討いただけますと幸いです。
今回はマネジメントコンソールを利用した使い方をご紹介しましたが、実際にご利用いただく際はブラウザからチャットボットなどと組み合わせて利用するシーンも考えられます。AWS のチャットボットサービスである Amazon Lex と組み合わせた GUI つきソリューションもあり、AWS Cloud Development Kit (CDK) を利用してすぐにデプロイすることができますので、是非 こちらのソリューション もお試しください !
最後まで読んでいただき、ありがとうございました !
筆者プロフィール
高橋 佑里子
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
2022 年 4 月 に AWS Japan に入社したソリューションアーキテクト。趣味はテニスとゴルフで、実家の犬と触れ合う時間が一番の癒しです。
