ETL と ELT にはどのような違いがありますか?
ETL と ELT にはどのような違いがありますか?
抽出、変換、ロード (ETL) と抽出、ロード、変換 (ELT) は、分析のための 2 つのデータ処理アプローチです。大規模な組織には、アプリケーション、センサー、IT インフラストラクチャ、サードパーティパートナーなど、業務のあらゆる側面から数百または数千ものデータソースがあります。分析やビジネスインテリジェンスに役立つようにするには、この大量のデータをフィルタリング、ソート、クリーニングする必要があります。ETL アプローチでは、一元的な統合を行う前に、一連のビジネスルールを使用して複数のソースからのデータを処理します。ELT アプローチでは、データをそのままロードし、ユースケースや分析の要件に応じて後の段階で変換します。ETL プロセスでは、最初により多くの定義が必要です。ターゲットのデータ型、構造、関係を定義するには、最初から分析が必要となります。データサイエンティストは主に ETL を使用してデータウェアハウスにレガシーデータベースをロードしますが、現在では ELT が標準になっています。
ETL と ELT にはどのような類似点がありますか?
抽出、変換、ロード (ETL) と抽出、ロード、変換 (ELT) はどちらも、さらなる分析のためにデータを準備する一連のプロセスです。データを収集、処理、ロードして、3 つのステップに分けて分析します。
抽出
抽出は ETL と ELT の両方の最初のステップです。このステップでは、さまざまなソースから未加工データを収集します。これらには、データベース、ファイル、Software as a Service (SaaS) アプリケーション、モノのインターネット (IoT) センサー、またはアプリケーションイベントなどがあります。この段階では、半構造化データ、構造化データ、または非構造化データを収集できます。
トランスフォーメーション
ETL プロセスでは、変換は 2 番目のステップですが、ELT では 3 番目のステップです。このステップでは、未加工データを元の構造から、分析用にデータを保存する予定のターゲットシステムの要件を満たす形式に変更することに重点を置いています。変換の例は以下の通りです。
- データ型または形式の変更します
- 一貫性のない、または不正確なデータを削除します。
- 重複データを削除します。
ルールと関数を適用して、ターゲットシステムでの分析用データのクリーニングと準備を行います。
ロード
このフェーズでは、データをターゲットデータベースに保存します。ETL は最後のステップとしてロードデータを処理し、レポートツールはそのデータを直接使用して実用的なレポートやインサイトを生成できます。しかし、ELT では、抽出されたデータをロードした後に変換する必要があります。
ELT プロセスと ETL プロセスはどう違うのですか?
次に、抽出、変換、ロード (ETL) と抽出、読み込み、変換 (ELT) のプロセスの概要を説明します。歴史的背景を読むこともできます。
ETL プロセス
ETL の 3 つのステップは以下のとおりです。
- さまざまなソースから未加工データを抽出します
- そのデータを変換するため、二次処理サーバーを使用します
- そのデータをターゲットデータベースにロードします
変換段階では、ターゲットデータベースの構造要件への準拠が保証されます。データが変換されて準備が整った後にのみ、データを移動できます。
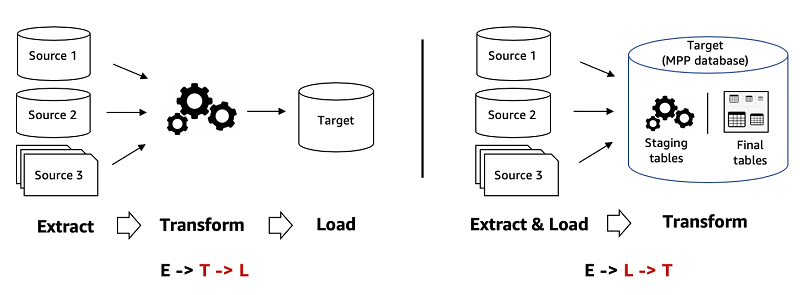
ELT プロセス
ELT の 3 つのステップは以下のとおりです。
- さまざまなソースから未加工データを抽出します
- データを自然な状態でデータウェアハウスまたはデータレイクにロードします
- ターゲットシステム内で必要に応じて変換します
ELT では、すべてのデータクレンジング、変換、エンリッチメントがデータウェアハウス内で行われます。未加工データを必要なだけ何度でも操作して変換できます。
ETL と ELT の歴史
ETL は 1970 年代から存在しており、特にデータウェアハウスの台頭とともに普及が進みました。しかし、従来のデータウェアハウスでは、データソースごとにカスタム ETL プロセスが必要でした。
クラウドテクノロジーの進化により、可能性が変化しました。企業は未加工データを無制限に大規模に保存し、必要に応じて後で分析できるようになりました。ELT は効率的な分析のための最新のデータ統合方法になりました。
主な相違点: ETL とELT
抽出、ロード、変換 (ELT) は、抽出、変換、ロード (ETL) をいくつかの点で改善したものです。
変換位置とロード位置
変換とロードは異なる位置で行われ、それぞれ異なるプロセスを使用します。ETL プロセスは、二次処理サーバー上のデータを変換します。
対照的に、ELT プロセスは未加工データをターゲットのデータウェアハウスに直接ロードします。一度ロードすれば、必要なときにいつでもデータを変換できます。
データ互換性
ETL は、行と列を含むテーブルで表現できる構造化データに最適です。ある構造化データセットを別の構造化形式に変換してからロードします。
対照的に、ELT は、表形式で保存できない画像や文書などの非構造化データを含む、あらゆる種類のデータを処理します。ELT では、プロセスによってさまざまなデータ形式がターゲットデータウェアハウスにロードされます。そこから、さらに必要な形式に変換できます。
スピード
ELT は ETL よりも高速です。ETL では、スケーリングが難しく、データサイズが大きくなるとシステムの速度が低下するターゲットにデータをロードする前に、追加の手順が必要になります。
対照的に、ELT はデータを宛先システムに直接ロードし、並行して変換します。クラウドデータウェアハウスが提供する処理能力と並列化を利用して、分析用のデータをリアルタイムまたはほぼリアルタイムで変換します。
コスト
ETL プロセスには、最初から分析の関与が必要です。アナリストは、生成したいレポートを事前に計画し、データ構造と形式を定義する必要があります。設定に必要な時間、コストが増加します。変換のためのサーバーインフラストラクチャの追加には、さらにコストがかかる場合があります。
すべての変換はターゲットのデータウェアハウス内で行われるため、ELT のシステムは ETL よりも少なくなります。システムが少なくなると、メンテナンスが少なくて済むため、データスタックがシンプルになり、設定コストが低下します。
セキュリティ
個人データを扱う際には、データプライバシー規制を遵守する必要があります。企業は、個人を特定できる情報 (PII) を不正アクセスから保護する必要があります。
ETL では、デベロッパーはデータをモニタリングおよび保護するために PII をマスキングするなどのカスタムソリューションを構築する必要があります。
一方、ELT ソリューションは、きめ細かなアクセス制御や多要素認証など、多くのセキュリティ機能をデータウェアハウス内で直接提供します。データ規制要件を満たす時間を減らして、分析により多くの時間を費やすことができます。
使用場面の比較: ETL とELT
最新の分析では、抽出、ロード、変換 (ELT) が標準的な選択肢です。ただし、次のシナリオでは、抽出、変換、ロード (ETL) を検討することもできます。
レガシーデータベース
ETL を使用して、あらかじめ決められたデータ形式のレガシーデータベースやサードパーティのデータソースと統合する方が有益な場合があります。一度の変換とシステムロードだけで完了します。一度変換すれば、今後のすべての分析でより効率的に使用できます。
実験
大規模な組織では、データエンジニアが分析用の隠れたデータソースを発見したり、ビジネス上の質問に答えるための新しいアイデアを試したりするなどの実験を行います。ETL は、特定のシナリオにおけるデータベースとその有用性を理解するためのデータ実験に役立ちます。
複雑な解析
ETL と ELT を併用すると、さまざまなソースからの複数のデータ形式を使用する複雑な分析を行うことができます。データサイエンティストは、一部のソースから ETL パイプラインを設定し、残りのソースでは ELT を使用する場合があります。これにより、分析の効率が向上し、場合によってはアプリケーションのパフォーマンスが向上します。
IoT アプリケーション
センサーデータストリームを使用するモノのインターネット (IoT) アプリケーションでは、多くの場合、ELT よりも ETL の方がメリットがあります。エッジでの ETL の一般的なユースケースの例は以下のとおりです。
- さまざまなプロトコルからデータを受信し、それをクラウドワークロードで使用するための標準データ形式に変換したい
- 頻度の高いデータをフィルタリングし、大規模なデータセットで平均化関数を実行してから、平均値またはフィルター処理された値を低レートでロードしたい
- ローカルデバイス上のさまざまなデータソースから値を計算し、フィルターされた値をクラウドバックエンドに送信したい
- 時系列データをクレンジング、重複排除し、欠落したエレメントの補填を行いたい
相違点の要約: ETL とELT
| カテゴリ |
ETL |
ELT |
|
以下の略です |
抽出、変換、ロード |
抽出、ロード、変換 |
|
プロセス |
未加工のデータを所定の形式に変換し、ターゲットのデータウェアハウスにロードします。 |
未加工のデータを取得してターゲットのデータウェアハウスにロードし、分析の直前に変換します。 |
|
変換位置とロード位置 |
変換は二次処理サーバーで行われます。 |
変換はターゲットのデータウェアハウスで行われます。 |
|
データ互換性 |
構造化データに最適です。 |
構造化データ、非構造化データ、および半構造化データを処理できます。 |
|
スピード |
ETL は ELT よりも低速です。 |
ELT は、データウェアハウスの内部リソースを使用できるため、ETL よりも高速です。 |
|
コスト |
使用する ETL ツールによっては、設定に時間とコストがかかる場合があります。 |
使用する ELT インフラストラクチャによっては、費用対効果が高くなります。 |
|
セキュリティ |
データ保護要件を満たすカスタムアプリケーションの構築が必要になる場合があります。 |
ターゲットデータベースの組み込み機能を使用してデータ保護を管理できます。 |
AWS は ETL と ELT の要件をどのようにサポートできますか?
Analytics on AWS では、お客様のあらゆるデータ分析ニーズを満たすアマゾンウェブサービス (AWS) の幅広い分析サービスについて説明しています。AWS を使用すると、あらゆる規模や業界の組織がデータを使用してビジネスを再構築できます。
ETL と ELT の要件に使用できる AWS のサービスの一部を以下に示します。
- Amazon Aurora は Amazon Redshift とのゼロETL統合をサポートしています。この統合により、Aurora からのペタバイト (PB) のトランザクションデータに対して、Amazon Redshift によるほぼリアルタイムの分析と機械学習が可能になります。
- AWS Glue は、イベント駆動型 ETL ジョブおよびコードなし ETL ジョブ用のサーバーレスデータ統合サービスです。
- AWS IoT Greengrass は、クラウド処理とロジックをローカルにエッジデバイスにもたらすことで、エッジ上の ETL ユースケースをサポートします。
- Amazon Redshift では、すべての ELT ワークフローを設定し、さまざまなソースのデータセットを直接クエリできます。
今すぐ無料アカウントを作成して、AWS で ELT と ETL を使い始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages