教師あり学習と教師なし学習はどのように異なりますか?
教師あり機械学習と教師なし機械学習の相違点は何ですか?
機械学習アルゴリズムには、教師あり機械学習と教師なし機械学習 (ML) の 2 つのカテゴリがあります。ML アルゴリズムは大量の履歴データを処理し、推論によってデータパターンを特定します。
教師あり学習アルゴリズムは、アルゴリズムの入力と出力の両方を指定するサンプルデータに基づいてトレーニングされます。たとえば、データは手書きの数字の画像で、それがどの数字を表しているかを示す注釈が付けられている場合があります。ラベル付けされたデータが十分にある場合、教師あり学習システムは最終的に、手書きの各数字に関連付けられたピクセルと形状のクラスターを認識します。
一方、教師なし学習アルゴリズムは、ラベルのないデータをトレーニングします。このアルゴリズムは新しいデータをスキャンし、不明な入力と所定の出力の間に意味のあるつながりを確立します。たとえば、教師なし学習アルゴリズムは、さまざまなニュースサイトのニュース記事を、スポーツや犯罪などの一般的なカテゴリにグループ化できます。
手法: 教師あり学習と教師なし学習
機械学習は、予測や推論を実行することをコンピュータに教えます。まず、アルゴリズムとサンプルデータを使用してモデルをトレーニングします。次に、モデルをアプリケーションに統合して、リアルタイムで大規模に推論を生成します。教師あり学習と教師なし学習は、アルゴリズムの異なる 2 つのカテゴリです。
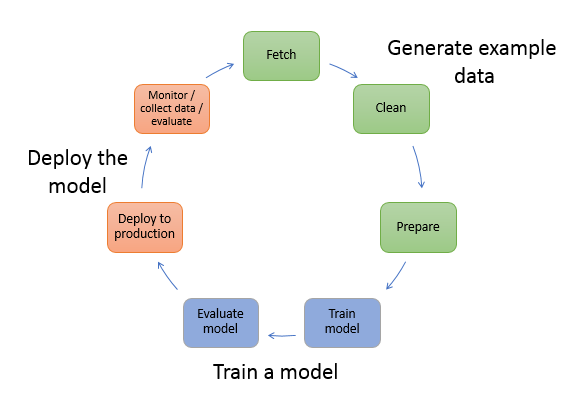
教師あり学習
教師あり学習では、入力データのセットとそれに対応するペアのラベル付き出力データのセットを使用してモデルをトレーニングします。ラベル付けは通常、手動で行われます。次に、教師あり機械学習の手法をいくつか紹介します。
ロジスティック回帰
ロジスティック回帰は、1 つ以上の入力に基づいてカテゴリ出力を予測します。二項分類とは、出力が「はい」または「いいえ」、「合格」または「不合格」などの 2 つのカテゴリのいずれかに当てはまる場合です。複数クラス分類とは、出力が 2 つ以上のカテゴリ (猫、犬、ウサギなど) に当てはまる場合です。 ロジスティック回帰の例としては、コースウェアへのログイン数に基づいて、学生がユニットに合格するか不合格になるかを予測することが挙げられます。
線形回帰
線形回帰とは、1 つ以上の入力に基づいて連続的なスケールから値を予測する教師あり学習モデルを指します。線形回帰の例としては、住宅価格の予測があります。これらの変数を使用して過去の販売トレーニングデータに基づいてモデルをトレーニングすることで、その場所、築年数、部屋数に基づいて住宅価格を予測できます。
ディシジョンツリー
決定木の教師あり機械学習手法は、与えられた入力の一部を受け取り、if-else 構造を適用して結果を予測します。決定木の問題の例としては、お客様離れの予測があります。たとえば、お客様がサインアップ後にアプリケーションにアクセスしなかった場合、モデルはお客様離れを予測する可能性があります。また、お客様が複数のデバイスでアプリケーションにアクセスし、平均セッション時間が所定のしきい値を超えている場合、モデルは保持を予測する可能性があります。
ニューラルネットワーク
ニューラルネットワークソリューションは、より複雑な教師あり学習手法です。与えられた結果を出すには、与えられた入力をいくつか取り、データの重みの調整に基づいて 1 つ以上の層の数学的変換を行います。ニューラルネットワーク手法の例としては、手書きの画像から数字を予測することが挙げられます。
教師なし学習
教師なし機械学習とは、ラベル付きの出力データなしでアルゴリズムに入力データを与えることです。そして、アルゴリズムが独自に、データ内およびデータ間のパターンと関係を識別します。次に、いくつかの種類の教師なし学習手法を紹介します。
クラスタリング
教師なし学習のクラスタリング手法では、特定のデータ入力がグループ化されるため、全体として分類できます。入力データに応じて、さまざまなタイプのクラスタリングアルゴリズムがあります。クラスタリングの例としては、さまざまなタイプのネットワークトラフィックを識別して潜在的なセキュリティインシデントを予測することが挙げられます。
アソシエーションルール学習
アソシエーションルール学習手法により、データセット内の入力間のルールベースの関係が明らかになります。たとえば、Apriori アルゴリズムはマーケットバスケット分析を行い、コーヒーと牛乳を一緒に購入することが多いなどのルールを特定します。
確率密度
教師なし学習における確率密度手法は、出力の値が入力に対して正常と見なされる範囲内にある傾向または可能性を予測します。たとえば、サーバールームの温度計は通常、ある程度の温度範囲を記録します。しかし、確率分布に基づいて突然低い数値を測定した場合、機器の誤動作を示している可能性があります。
次元削減
次元削減は、データセット内の特徴数を減らす教師なし学習手法です。他の機械学習機能のデータを前処理したり、複雑さやオーバーヘッドを軽減したりするためによく使用されます。たとえば、画像認識アプリケーションで背景の特徴がぼやけたり、トリミングされたりすることがあります。
使用場面の比較: 教師あり学習と教師なし学習
教師あり学習の手法を使うと、結果が分かっている、ラベル付けされたデータが利用可能な問題を解決できます。たとえば、E メールのスパム分類、画像認識、既知の履歴データに基づく株価予測などがあります。
教師なし学習は、データにラベルが付いておらず、その目的がパターンの発見、類似するインスタンスのグループ化、または異常の検出であるシナリオに使用できます。また、ラベル付けされたデータがない探索的なタスクにも使用できます。たとえば、大規模なデータアーカイブの整理、推奨システムの構築、購入行動に基づくお客様のグループ化などがあります。
教師あり学習と教師なし学習の両方を一緒に使用できますか?
半教師あり学習とは、教師あり学習と教師なし学習の両方の手法を共通の問題に適用することです。それ自体が機械学習のもう一つのカテゴリです。
データセットのラベルを取得するのが難しい場合は、半教師あり学習を適用できます。ラベル付けされたデータの量は少ないが、ラベル付けされていないデータは大量にある場合などです。ラベル付きデータセットのみを使用する場合と比較して、教師あり学習手法と教師なし学習手法を組み合わせると、精度と効率が向上します。

半教師あり学習アプリケーションの例をいくつかご紹介します。
不正の識別
大量の取引データの中には、専門家が不正取引を確認したラベル付きデータのサブセットがあります。より正確な結果を得るために、機械学習ソリューションは最初にラベルのないデータでトレーニングし、次にラベル付けされたデータでトレーニングします。
感情分析
組織のテキストベースのお客様とのやりとりの幅を考えると、すべてのチャネルで感情を分類したりラベル付けしたりするのは費用対効果が低い場合があります。組織は、最初にラベルのないデータの大きい部分でモデルをトレーニングし、次にラベルが付けられたサンプルでモデルをトレーニングできます。これにより、組織はビジネス全体のお客様感情に対する信頼度を高めることができます。
文書の分類
大きな文書ベースにカテゴリを適用する場合、文書の数が多すぎて物理的にラベル付けできない場合があります。たとえば、これらは無数の報告書、トランスクリプト、または仕様書などです。ラベル付けされていないデータについて最初にトレーニングを行うことで、ラベル付けの対象となる類似文書を特定しやすくなります。
相違点の要約: 教師あり学習と教師なし学習
|
|
教師なし学習 |
|
|
内容 |
入力データのセットとそれに対応するペアのラベル付き出力データのセットを使用してモデルをトレーニングします。 |
ラベル付けされていないデータに隠れたパターンを発見するようにモデルをトレーニングします。 |
|
手法 |
ロジスティック回帰、線形回帰、決定木、ニューラルネットワーク。 |
クラスタリング、アソシエーションルール学習、確率密度、次元削減。 |
|
目的 |
既知の入力に基づいて出力を予測します。 |
入力データポイント間の貴重な関係情報を特定します。これを新しい入力に適用して、同様のインサイトを引き出すことができます。 |
|
アプローチ |
予測された出力と真のラベルとの間の誤差を最小限に抑えます。 |
データ内のパターン、類似点、または異常を見つけます。 |
AWS は教師あり学習と教師なし学習にどのように役立ちますか?
Amazon Web Services (AWS) では、教師付き、教師なし、半教師ありの機械学習 (ML) に役立つ幅広いサービスを提供しています。規模、複雑さ、ユースケースを問わず、ソリューションを構築、実行、統合できます。
Amazon SageMaker は、機械学習ソリューションをゼロから構築するための完全なプラットフォームです。SageMaker には、教師あり学習モデルと教師なし学習モデル、ストレージとコンピューティング機能、フルマネージド環境がすべて揃っています。
たとえば、仕事で使用できる SageMaker の機能は以下のとおりです。
-
Amazon SageMaker Canvas を使用すると、さまざまなソリューションを自動的に検討し、特定のデータセットに最適なモデルを見つけることができます。
-
Amazon SageMaker データラングラーを使用してデータを選択し、データインサイトを理解し、データを変換して機械学習に備えましょう。
-
Amazon SageMaker Experiments を使用して ML トレーニングのイテレーションを分析および比較し、最もパフォーマンスの高いモデルを選択してください。
-
Amazon SageMaker Clarify を使用して、潜在的なバイアスを検出して測定してください。これにより、ML デベロッパーは潜在的なバイアスに対処し、モデル予測を説明することができます。
今すぐアカウントを作成して、AWS での教師あり機械学習と教師なし機械学習を始めましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages