AWS Cloud Essentials
Introduction
Taking the first steps as you start building on the cloud can seem overwhelming. Adjusting to a cloud-native approach can take time, especially if you are accustomed to the traditional on-premises way of provisioning hardware and building applications. Gaining familiarity with core concepts of cloud computing and the AWS Cloud will help give you confidence as you begin your cloud journey. In the following sections, we answer common questions about cloud computing and explore best practices for building on AWS.
What is cloud computing?
On-premises and cloud computing
Cloud computing is the on-demand delivery of compute power, database, storage, applications, and other IT resources through a cloud services platform through the internet with pay-as-you-go pricing. Traditionally, a developer looking to build an application had to procure, set up, and maintain physical infrastructure and the application. This is where cloud computing comes in.
A cloud services platform provides rapid access to flexible and low-cost IT resources that you can use to build and maintain software and databases, and create applications to delight customers. You don’t need to make large upfront investments in hardware and spend a lot of time on the heavy lifting of managing that hardware. You can access as many resources as you need, almost instantly, and only pay for what you use. On-demand, pay-as-you-go access to services is fundamental to the cloud computing model.
Advantages of cloud computing
The cloud provides developers with greater flexibility, scalability, and faster time to innovation. With cloud computing, you can
-
Pay as you go - Pay only when you use computing resources, and only for how much you use.
-
Benefit from massive economies of scale - AWS aggregates usage from hundreds of thousands of customers in the cloud, which leads to higher economies of scale. This translates into lower pay-as-you-go prices.
-
Stop guessing capacity - When you make a capacity decision prior to deploying an application, you often end up either sitting on expensive idle resources or dealing with limited capacity. With cloud computing, you can access as much or as little capacity as you need, and scale up and down as required with only a few minutes notice.
-
Increase speed and agility - IT resources are only a click away, which means that you reduce the time to make resources available to your developers from weeks to minutes. This dramatically increases agility for the organization, because the cost and time it takes to experiment and develop is significantly lower.
-
Realize cost savings - Companies can focus on projects that differentiate their business instead of maintaining data centers. With cloud computing, you can focus on your customers, rather than on the heavy lifting of racking, stacking, and powering physical infrastructure.
-
Go global in minutes - Applications can be deployed in multiple Regions around the world with a few clicks. This means that you can provide lower latency and a better experience for your customers at a minimal cost.
What is AWS Cloud?
AWS provides on-demand delivery of technology services through the Internet with pay-as-you-go pricing. This is known as cloud computing.
The AWS Cloud encompasses a broad set of global cloud-based products that includes compute, storage, databases, analytics, networking, mobile, developer tools, management tools, IoT, security, and enterprise applications: on-demand, available in seconds, with pay-as-you-go pricing. With over 200 fully featured services available from data centers globally, the AWS Cloud has what you need to develop, deploy, and operate your applications, all while lowering costs, becoming more agile, and innovating faster.
For example, with the AWS Cloud, you can spin up a virtual machine, specifying the number of vCPU cores, memory, storage, and other characteristics in seconds, and pay for the infrastructure in per-second increments only while it is running. One benefit of the AWS global infrastructure network is that you can provision resources in the Region or Regions that best serve your specific use case. When you are done with the resources, you can simply delete them. With this built-in flexibility and scalability, you can build an application to serve your first customer, and then scale to serve your next 100 million.
This video explores how millions of customers are using AWS to take advantage of the efficiencies of cloud computing.
Dive deeper with these additional resources
Cloud Computing with AWS
A full list of AWS Services by category

On-premises and cloud computing
Before the cloud, companies and organizations hosted and maintained hardware in their own data centers, often allocating entire infrastructure departments to take care of their data centers. This resulted in costly operations that made some workloads and experimentation impossible.
The demand for compute, storage, and networking equipment increased as internet use became more widespread. For some companies and organizations, the cost of maintaining a large physical presence was unsustainable. Cloud computing emerged to solve this problem.
To help differentiate between running workloads on premises compared to in the cloud, consider a scenario in which a team of developers wants to deploy a few new features in their app. Before they deploy, the team wants to test the features in a separate quality assurance (QA) environment that has the same configurations as production.
In an on-premises solution, an additional environment requires you to buy and install hardware, connect the necessary cabling, provision power, install operating systems, and more. These tasks can be time consuming and expensive. Meanwhile, the team needs to delay the release of the new features while they wait for the QA environment. In contrast, if you run your application in the cloud, you can replicate an entire production environment, as often as needed, in a matter of minutes or even seconds. Instead of physically installing hardware and connecting cabling, the solution is managed over the internet.
Using cloud computing saves time during setup and removes the undifferentiated heavy lifting. If you look at any application, you’ll see that some of its aspects are very important to your business, like the code. However, other aspects are no different than any other application you might make – for instance, the computer the code runs on. As a developer, you likely want to focus on what is unique to your app, not the common tasks, like provisioning a server, that don’t differentiate your app. As one example, a group of researchers from Clemson University achieved a remarkable milestone while studying topic modeling, an important component of machine learning associated with natural language processing (NLP). In the span of less than 24 hours, they created a high-performance cluster in the cloud by using more than 1,100,000 vCPUs on Amazon EC2 Spot Instances running in a single AWS Region. This is just one example of how AWS can help you innovate faster.
Try it out: Deploy a LAMP Web App on Amazon Lightsail
Dive deeper with these additional resources
Cloud Computing Deployment Models
IaaS, PaaS, and SaaS
Cloud computing provides developers with the ability to focus on what matters most and avoid infrastructure procurement, maintenance, and capacity planning, or undifferentiated heavy lifting.
With the growing popularity of cloud computing, several different service models have emerged to help meet specific needs of different users. Each type of cloud service provides you with different levels of abstraction, control, flexibility, and management. Understanding the differences between Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS) can help you decide what service type is right for your needs as a developer.
Infrastructure as a Service (IaaS)
Infrastructure as a Service (IaaS) contains the basic building blocks for cloud IT, and typically provides access to networking features, computers (virtual or on dedicated hardware), and data storage space. IaaS provides you with the highest level of flexibility and management control over your IT resources and is most like existing IT resources that many developers are familiar with today.
Try it out: Deploy a LAMP Web App on Amazon Lightsail
Platform as a Service (PaaS)
Platform as a Service (PaaS) removes the need for you to manage the underlying infrastructure (usually hardware and operating systems) and allows you to focus on the deployment and management of your applications. This helps you be more efficient because you don’t need to worry about resource procurement, capacity planning, software maintenance, patching, or any of the other undifferentiated heavy lifting involved in running your application.
Try it out: Getting started with AWS Elastic Beanstalk
Software as a Service (SaaS)
Software as a Service (SaaS) provides you with a completed product that is run and managed by the service provider. In most cases, people referring to SaaS are referring to end-user applications. With a SaaS offering you do not have to think about how the service is maintained or how the underlying infrastructure is managed; you only need to think about how you will use that piece of software. A common example of a SaaS application is web-based email which you can use to send and receive email without having to manage feature additions to the email product or maintain the servers and operating systems that the email program is running on.
Dive deeper: Software-as-a-Service (SaaS) on AWS
Dive deeper with these additional resources
Types of Cloud Computing
Software-as-a-Service (SaaS) on AWS
Global infrastructure
With the cloud, you can expand to new geographic regions and deploy globally in minutes. For example, AWS has infrastructure all over the world, so developers can deploy applications in multiple physical locations with just a few clicks. By putting your applications in closer proximity to your end users, you can reduce latency and improve the user experience.
AWS is steadily expanding global infrastructure to help our customers achieve lower latency and higher throughput, and to ensure that their data resides only in the AWS Region they specify. As our customers grow their businesses, AWS will continue to provide infrastructure that meets their global requirements.
AWS Cloud infrastructure is built around AWS Regions and Availability Zones. A Region is a physical location in the world where we have multiple Availability Zones. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity, housed in separate facilities. These Availability Zones offer you the ability to operate production applications and databases that are more highly available, fault tolerant, and scalable than would be possible from a single data center.
AWS Cloud infrastructure is extensive, offering 200 fully featured services from data centers globally. With the largest global infrastructure footprint of any cloud provider, AWS provides you the cloud infrastructure where and when you need it.
Developer tools
How to interact with AWS
When infrastructure becomes virtual, as with cloud computing, the way developers work with infrastructure changes slightly. Instead of physically managing infrastructure, you logically manage it, through the AWS Application Programming Interface (AWS API). When you create, delete, or change any AWS resource, you will use API calls to AWS to do that.
You can make these API calls in several ways, but we will focus on these to introduce this topic:
- The AWS Management Console
- The AWS Command Line Interface (AWS CLI)
- IDE and IDE toolkits
- AWS Software Development Kits (SDKs)
The AWS Management Console
When first getting started with AWS, people often begin with the AWS Management Console, a web-based console that you log in to through a browser. The console comprises a broad collection of service consoles for managing AWS resources. By working in the console, you do not need to worry about scripting or syntax. You can also select the specific Region you want an AWS service to be in.
After working in the console, you may want to move away from manual deployment of AWS service, perhaps because you have become more familiar with AWS or are working in a production environment that requires a degree of risk management. This is where the AWS Command Line Interface (CLI) comes in.
AWS CLI
The AWS CLI is an open source tool that enables you to create and configure AWS services using commands in your command-line shell. You can run commands in Linux or macOS using common shell programs such as bash, zsh, and tcsh, or on Windows, at the Windows command prompt or in PowerShell. One option for getting up and running quickly with the AWS CLI is AWS CloudShell, a browser-based shell that provides command-line access to AWS resources. CloudShell is pre-authenticated with your console credentials. Common development and operations tools are pre-installed, so no local installation or configuration is required.
By moving to the AWS CLI, you can script or program the API calls. Instead of using a GUI, you create commands using a defined AWS syntax. One benefit of the CLI is that you can create single commands to create multiple AWS resources, which could help reduce the chance of human error when selecting and configuring resources. With the CLI, you need to learn the proper syntax for forming commands, but as you script these commands, you make them repeatable. This should save you time in the long run
IDE and IDE Toolkits
AWS offers support for popular Integrated Development Environments (IDEs) and IDE toolkits so you can author, debug, and deploy your code on AWS from within your preferred environment. Supported IDEs and toolkits include AWS Cloud9, IntelliJ, PyCharm, Visual Studio, Visual Studio Code, Azure DevOps, Rider, and WebStorm.
SDKs
Software Development Kits (SDKs) are tools that allow you to interact with the AWS API programmatically. AWS creates and maintains SDKs for most popular programming languages, including those shown in the diagram.
SDKs come in handy when you want to integrate your application source code with AWS services. For example, you might use the Python SDK to write code to store files in Amazon Simple Storage Service (Amazon S3) instead of on your local hard drive. The ability to manage AWS services from a place where you can run source code, with conditions, loops, arrays, lists, and other programming elements, provides a lot of power and creativity.
These are just some of the tools available to developers on AWS. For a full list of AWS tools for developing applications faster and easier, see Tools to Build on AWS.
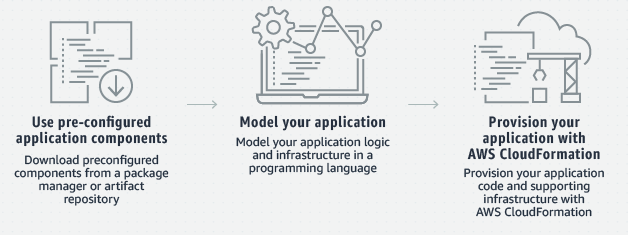
Infrastructure as code (IaC)
Similar to the way software developers write application code, AWS provides services that enable the creation, deployment, and maintenance of infrastructure in a programmatic, descriptive, and declarative way.
AWS CDK
The AWS Cloud Development Kit (AWS CDK) is a software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. The AWS CDK supports familiar programming languages, such as TypeScript, JavaScript, Python, Java, C#/.Net, and Go (in developer preview).
Provisioning cloud applications can be challenging, requiring you to write custom scripts, maintain templates, or learn domain-specific languages. AWS CDK uses the familiarity and expressive power of programming languages for modeling your applications. It provides high-level components called constructs that preconfigure cloud resources with proven defaults, so you can build cloud applications with ease. AWS CDK provisions your resources in a safe, repeatable manner through AWS CloudFormation. It also allows you to compose and share your own custom constructs incorporating your organization's requirements, helping you expedite new projects.
Dive deeper with these additional resources
AWS CloudFormation
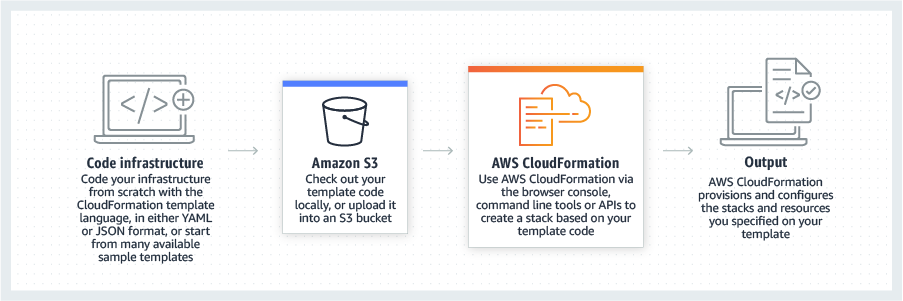
Modeling and setting up AWS resources can be time-consuming. This is where AWS CloudFormation can help. CloudFormation helps you model and set up your AWS resources so that you can spend less time managing resources and more time focusing on your applications. Using CloudFormation, you create a template that describes all the AWS resources that you want (like Amazon EC2 instances or Amazon RDS DB instances). Once you create the template, CloudFormation takes care of provisioning and configuring those resources for you. You don't need to individually create and configure AWS resources and figure out what's dependent on what; CloudFormation handles that. CloudFormation can help you simplify infrastructure management, quickly replicate your infrastructure, and easily control and track changes to your infrastructure.
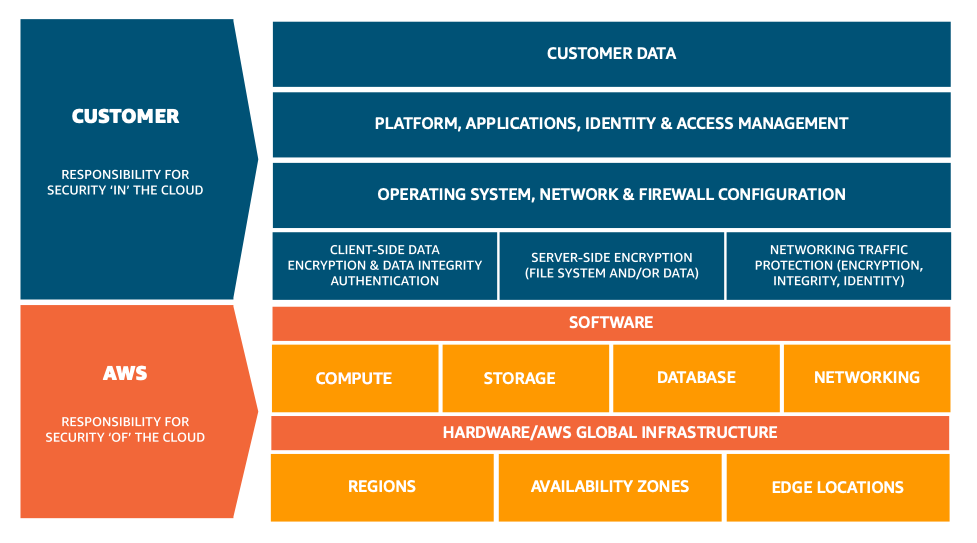
AWS responsibility
Being responsible for security of the cloud means that AWS protects and secures the infrastructure that runs the services offered in the AWS Cloud. AWS is responsible for:
- Protecting and securing AWS Regions, Availability Zones, and data centers, down to the physical security of the buildings
- Managing the hardware, software, and networking components that run AWS services, such as the physical servers, host operating systems, virtualization layers, and AWS networking components.
Well-Architected infrastructure
Dive deeper with these additional resources
Customer responsibility
Customers, or anyone building on the cloud, are responsible for security in the cloud. When using any AWS service, you’re responsible for properly configuring the service and your applications, in addition to ensuring that your data is secure.
Your level of responsibility depends on the AWS service. Some services require you to perform all the necessary security configuration and management tasks, while other more abstracted services require you to only manage the data and control access to your resources.
Due to the varying levels of effort, customers must consider which AWS services they use and review the level of responsibility required to secure each service. They must also review how the shared security model aligns with the security standards in their IT environment, in addition to any applicable laws and regulations.
A key concept is that customers maintain complete control of their data and are responsible for managing the security related to their content.
This short summary of cloud security introduces core concepts only. Browse the Security Learning page to learn more about key topics, areas of research, and training opportunities for cloud security on AWS.
Getting started
Launch your first app
AWS provides building blocks that you can assemble quickly to support virtually any workload. With AWS, you’ll find a complete set of highly available services that are designed to work together to build sophisticated scalable applications.
To get started, pick one of the following topics for a step-by-step tutorial to get you up and running in less than 30 minutes, or visit the AWS Developer Center to explore other tutorials.
Explore the Free Tier
The AWS Free Tier allows you to gain hands-on experience with a broad selection of AWS products and services. Within the AWS Free Tier, you can test workloads and run applications to learn more and build the right solution for your organization.
Explore more than 100 products and start building on AWS using the Free Tier. Three different types of free offers are available depending on the product used. Click a link below to explore our offers.
- Free trials: Short-term free trial offers start from the date you activate a particular service
- 12 months free: Enjoy these offers for 12 months following your initial sign-up date to AWS
- Always free: These free tier offers do not expire and are available to all AWS customersNote: The sign-up process requires a credit card, which will not be charged until you start using services. There are no long-term commitments and you can stop using AWS at any time.
Note: The sign-up process requires a credit card, which will not be charged until you start using services. There are no long-term commitments and you can stop using AWS at any time.
AWS Educate
AWS Educate offers hundreds of hours of free, self-paced online training resources and the opportunity for hands-on practice on the AWS Management Console. Designed specifically for the curious, new-to-cloud learner, AWS Educate provides simple, barrier-free access to learn, practice, and evaluate your cloud skills. No credit card or Amazon.com or AWS account is required.
- Simple, barrier-free access: Learners as young as 13 can register for AWS Educate with just an email address, gaining access to free hands-on labs in the AWS Console to learn, practice, and evaluate cloud skills in real-time. No credit card needed.
- Content designed for beginners: AWS Educate offers hundreds of hours of learning resources focused on the new-to-cloud learner. Prefer to learn by video or by tinkering in the AWS Cloud? We’ve got something for everyone.
- Connection to employment: Learners can access the AWS Educate Job Board to explore, search for, and apply to thousands of in-demand jobs and internships with organizations of all types all over the world.
- Build your network: Complete courses with hands-on labs to earn digital badges and score an invitation to the AWS Emerging Talent Community, your place to connect with other early career talent.
Start building
You can start building on AWS right away using the AWS Free Tier and our library of hands-on tutorials.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages