
Sold by: Wallarm
Deployed on AWS
Wallarm AI Hypervisor is the runtime governance layer for every LLM call, agent action, and MCP tool invocation running in AWS. Deploy and within minutes every outbound AI call is captured in-kernel and attributed to the originating end-user across every service hop. Built on patented non-invasive memory analysis, AIH covers AI interactions without requiring a single application code change. Review the prompt that produced a bad answer. Block a session in real time without restarting pods. Prove to auditors what data left for which model provider, on whose behalf. Recognizes Anthropic, OpenAI, AWS Bedrock, Azure OpenAI, Hugging Face, Together, and more than 11 others out of the box. Part of the Wallarm AI Control Platform.
Overview
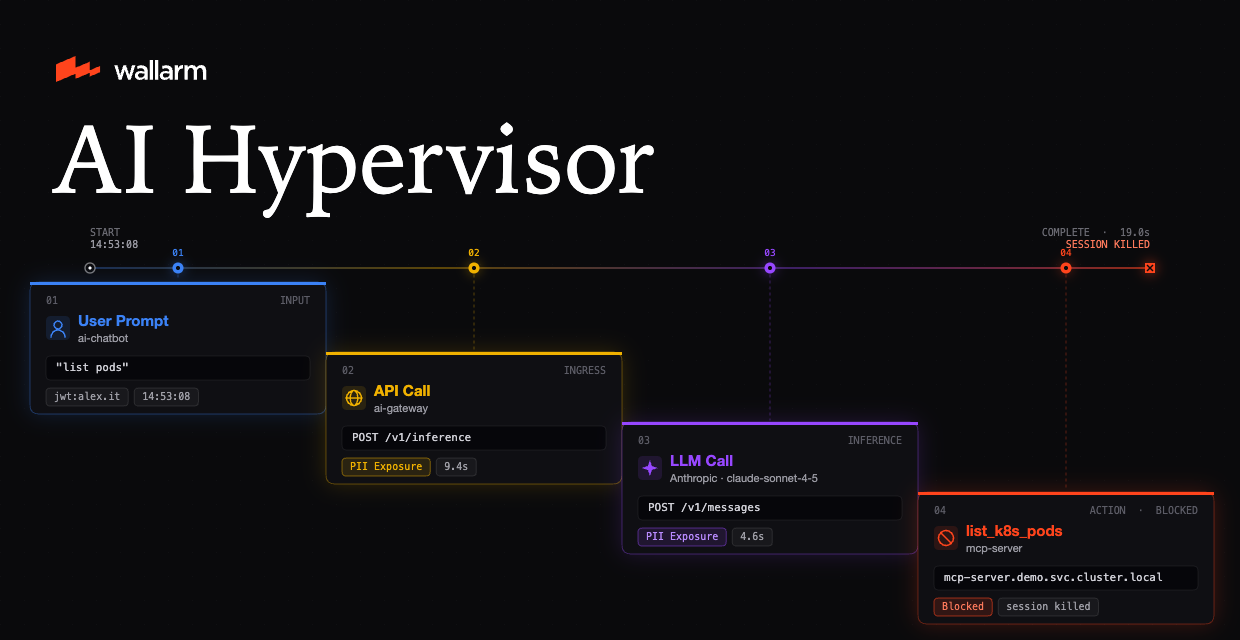
Wallarm AI Hypervisor is the runtime governance layer for AI workloads running in Kubernetes, and the Observe, Enforce, and Govern engine of the Wallarm AI Control Loop. Where Infrastructure Discovery maps your AWS estate, AI Hypervisor watches what your AI is actually doing: every LLM call, agent action, and MCP tool invocation, attributed to the user who triggered it, with enforcement and audit evidence built in.
KNOW WHAT AI IS RUNNING
Stop discovering model providers by reading commit messages and auditing cloud bills. AI Hypervisor gives you a live inventory of every LLM provider, agent, MCP server, and tool your applications are actually using, updated continuously from real traffic. Anthropic, OpenAI, AWS Bedrock, Azure OpenAI, Hugging Face, Together, and over 11 others recognized out of the box. Shadow AI surfaces next to the AI you officially approved.
KNOW WHO TRIGGERED IT
When a model returns something wrong, leaks something it shouldn't, or runs up a surprise bill, you need to know which end-user caused it. AI Hypervisor attributes every model call, agent step, and tool invocation back to the originating end-user across every internal service hop. Replay the exact prompt that produced a bad answer. Attribute LLM costs to individual users and teams. Reconstruct an AI-related incident timeline in minutes instead of days.
STOP THE BAD ONES IN REAL TIME
A misbehaving session should not wait for the next deploy. Block a session, revoke a user, or stop a pattern instantly. No pod restart. No deploy cycle. No disruption to the workloads sharing the cluster. Enforcement is opt-in per namespace so platform teams can roll out one tenant at a time, while security gets a working off-switch for the rest of the estate.
PROVE IT TO AUDITORS
Whether the next conversation is EU AI Act review, SOC 2, an internal audit, or a customer security questionnaire, the evidence is already built. A current inventory of providers and tools, PII flow records traced from origin to model, an AI supply chain inventory with CVE enrichment, and full session replay. Compliance comes out of the same console your on-call team uses, not from spreadsheets assembled the week before.
ONE INSTALL COVERS EVERY RUNTIME
AI Hypervisor covers Python, Node, Go, Rust, Java, and Ruby workloads in the same view, without application code changes, without an SDK to adopt, and without a per-language tool to operate. It supplements your existing APM, log pipeline, and SIEM rather than replacing them, ships connectors to the SOC tools you already run, and lives inside your own Kubernetes clusters.
WHO IT'S FOR
Highlights
- Stop discovering model providers from commit messages and cloud bills. AI Hypervisor gives you a live inventory of every LLM provider, agent, MCP server, and tool your applications are actually using, updated continuously from real traffic. Anthropic, OpenAI, AWS Bedrock, Azure OpenAI, Hugging Face, Together, and more than 11 others are recognized out of the box. Shadow AI surfaces next to the AI you officially approved. The side projects and vendor trials show up too.
- When a model returns something wrong, leaks something it shouldn't, or runs up a surprise bill, you need to know which end-user caused it. AI Hypervisor attributes every model call, agent step, and tool invocation back to the originating end-user across every service hop. Replay the exact prompt that produced a bad answer. Attribute LLM costs by user and by team. Coverage spans Python, Node, Go, Rust, Java, and Ruby in a single view.
- A misbehaving session shouldn't wait for the next deploy. Block a user, kill a session, or stop a traffic pattern instantly. No pod restart. No change management ticket. No disruption to the workloads sharing the cluster. Enforcement is opt-in per namespace, so platform teams can roll out one tenant at a time while security gets a working off-switch for the rest of the estate. Built for production where downtime isn't an option.
Details
New
Introducing multi-product solutions
You can now purchase comprehensive solutions tailored to use cases and industries.

Features and programs
Financing for AWS Marketplace purchases
AWS Marketplace now accepts line of credit payments through the PNC Vendor Finance program. This program is available to select AWS customers in the US, excluding NV, NC, ND, TN, & VT.

Pricing
Pricing is based on the duration and terms of your contract with the vendor. This entitles you to a specified quantity of use for the contract duration. If you choose not to renew or replace your contract before it ends, access to these entitlements will expire.
Additional AWS infrastructure costs may apply. Use the AWS Pricing Calculator to estimate your infrastructure costs.
Dimension | Description | Cost/12 months |
|---|---|---|
Starter Tier - AIH | Licensed for up to 500 vCPUs per month of monitored Kubernetes, with a capacity attribute of up to 2B requests per month (RPM). Actual vCPU and RPM use is measured at the 95th percentile of the maximum used values over a rolling 30 day window. Step-up to Enterprise Tier AIH is required if vCPU or RPM counts exceed the capacity for two consecutive months. AIH is a private-offer only listing. | $75,000.00 |
Enterprise Tier - AIH | Licensed for up to 2,000 vCPUs per month of monitored Kubernetes, with a capacity attribute of up to 6B requests per month (RPM). Actual vCPU and RPM use is measured at the 95th percentile of the maximum used values over a rolling 30 day window. Step-up to Enterprise+ Tier AIH is required if vCPU or RPM counts exceed the capacity for two consecutive months. AIH is a private-offer only listing. | $250,000.00 |
Enterprise+ Tier - AIH | Licensed for up to 5,000 vCPUs per month of monitored Kubernetes, with a capacity attribute of up to 15B requests per month (RPM). Actual vCPU and RPM use is measured at the 95th percentile of the maximum used values over a rolling 30 day window. Step-up to a Strategic Tier AIH is required if vCPU or RPM counts exceed the capacity for two consecutive months. AIH is a private-offer only listing. | $500,000.00 |
Strategic Tier - AIH | Licenses above 5,000 vCPUs per month of monitored Kubernetes, and a capacity attribute over 15B requests per month (RPM) is a Strategic Tier requiring a private offer. Please contact Wallarm or a Wallarm partner. | $1,000,000.00 |
Vendor refund policy
AI Hypervisor is sold through annual private offers on AWS Marketplace. Contract terms, including renewal, step-up, and step-down mechanics, are defined in the executed private offer. Step-up tier movement is required when Licensed Capacity or RPM exceeds the contracted cap for two consecutive 30-day measurement periods. Step-down to a lower tier is permitted under the same measurements, never below the minimum commitment floor. No refunds are issued for capacity below the contracted tier.
Custom pricing options
Request a private offer to receive a custom quote.

Legal
Vendor terms and conditions
Upon subscribing to this product, you must acknowledge and agree to the terms and conditions outlined in the vendor's End User License Agreement (EULA) .
Content disclaimer
Vendors are responsible for their product descriptions and other product content. AWS does not warrant that vendors' product descriptions or other product content are accurate, complete, reliable, current, or error-free.
Delivery details
Software as a Service (SaaS)
SaaS delivers cloud-based software applications directly to customers over the internet. You can access these applications through a subscription model. You will pay recurring monthly usage fees through your AWS bill, while AWS handles deployment and infrastructure management, ensuring scalability, reliability, and seamless integration with other AWS services.
Support
Vendor support
24/7 Global Support
For questions about Wallarm product offerings or capabilities (pre-purchase), please contact our specialist team at the following email: productquestions@wallarm.com
Free API Security Certification: https://www.wallarm.com/api-security-certification
Documentation:
AWS infrastructure support
AWS Support is a one-on-one, fast-response support channel that is staffed 24x7x365 with experienced and technical support engineers. The service helps customers of all sizes and technical abilities to successfully utilize the products and features provided by Amazon Web Services.
Similar products

Protect APIs and AI agents by integrating Wallarm with your existing NGINX traffic management, enabling real-time threat mitigation, full API visibility, and risk detection.

Protect APIs and AI agents handled by Cloudflare, CloudFront, MuleSoft, and similar platforms in synchronous or asynchronous mode, with full API visibility and risk detection.

Wallarm protects your entire API portfolio with advanced API security capabilities.

Wallarm Infrastructure Discovery continuously inventories your AWS estate across every connected account and region, with no agent to install. Connect an AWS account via cross-account IAM role with external ID, AWS SSO profile, or static access key, and the first scan delivers a live, searchable inventory of EC2 instances, VPCs and their networking, EKS clusters, Lambda functions, load balancers, and API Gateway deployments. Drift detection records every field-level change so you can answer "what changed since last week." Built-in detection rules and customer-authored CEL rules surface exposure and misconfiguration. HTTP endpoints are detected automatically across EC2 instances, EKS pods, and load balancers on every scan. Built for security, platform, and compliance teams who need a defensible answer to what they have, what changed, and what is exposed. On-ramp to the Wallarm AI Control Platform.
Customer reviews
No customer reviews yet
Be the first to review this product . We've partnered with PeerSpot to gather customer feedback. You can share your experience by writing or recording a review, or scheduling a call with a PeerSpot analyst.