
Sold by: Cerebras Systems Inc.
Fast inference API for open-source models like Llama, Qwen, OpenAI GPT-OSS, and more, powered by the revolutionary Cerebras Wafer-Scale Engine.
5
Overview
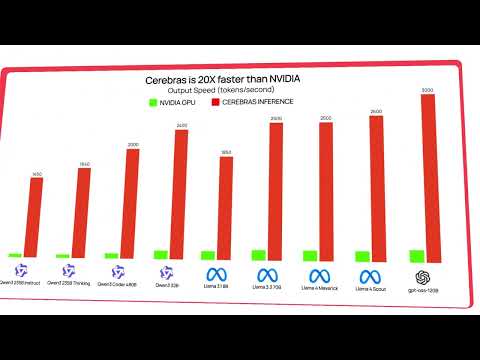
Cerebras Inference Cloud on AWS Marketplace brings lightning-fast, on-demand performance to the latest open-source LLMs, including Llama, Qwen, OpenAI GPT-OSS, and more.
Built for real-time interactivity, multi-step reasoning, and complex agentic workflows, Cerebras delivers the speed, scale, and simplicity needed to go from API key to production in under 30 seconds.
Powered by a fast AI accelerator, the Wafer-Scale Engine (WSE), and the CS-3 system, the Cerebras Inference Cloud offers ultra-low latency and high-throughput inferencing via a drop-in, OpenAI-compatible API.
Start today with our self-service offering. Pricing can be found here: https://www.cerebras.ai/pricing
For custom pricing or other questions please contact partners@cerebras.net
Highlights
- Up to 70X faster than GPUs: With throughput exceeding 2,500 tokens per second, Cerebras eliminates lag, delivering near-instant responses, even from large models.
- Full reasoning in under 1 second: No more multi-step delays, Cerebras executes full reasoning chains and delivers final answers in real time.
- Instant API access to top open-source models: Skip GPU setup and launch models like Llama, Qwen, OpenAI GPT-OSS in seconds, just bring your prompt.
Details
New
Introducing multi-product solutions
You can now purchase comprehensive solutions tailored to use cases and industries.

Features and programs
Trust Center

Access real-time vendor security and compliance information through their Trust Center powered by Drata or Vanta. Review certifications and security standards before purchase.
Financing for AWS Marketplace purchases
AWS Marketplace now accepts line of credit payments through the PNC Vendor Finance program. This program is available to select AWS customers in the US, excluding NV, NC, ND, TN, & VT.

Pricing
Pricing is based on actual usage, with charges varying according to how much you consume. Subscriptions have no end date and may be canceled any time.
Additional AWS infrastructure costs may apply. Use the AWS Pricing Calculator to estimate your infrastructure costs.
Dimension | Description | Cost/unit |
|---|---|---|
Cerebras Consumption Units | Pricing is based on actual usage | $0.0000001 |
Vendor refund policy
Payment obligations are non-cancelable once incurred, and Fees paid are non-refundable.
Custom pricing options
Request a private offer to receive a custom quote.

Legal
Vendor terms and conditions
Upon subscribing to this product, you must acknowledge and agree to the terms and conditions outlined in the vendor's End User License Agreement (EULA) .
Content disclaimer
Vendors are responsible for their product descriptions and other product content. AWS does not warrant that vendors' product descriptions or other product content are accurate, complete, reliable, current, or error-free.
Delivery details
Software as a Service (SaaS)
SaaS delivers cloud-based software applications directly to customers over the internet. You can access these applications through a subscription model. You will pay recurring monthly usage fees through your AWS bill, while AWS handles deployment and infrastructure management, ensuring scalability, reliability, and seamless integration with other AWS services.
Resources
Vendor resources
Support
Vendor support
Learn more about our supported models, rate limits, pricing, and more in our documentation (docs.cerebras.ai/cloud). For 24x7 technical support, contact support@cerebras.net or +1 (650) 933-4980.
AWS infrastructure support
AWS Support is a one-on-one, fast-response support channel that is staffed 24x7x365 with experienced and technical support engineers. The service helps customers of all sizes and technical abilities to successfully utilize the products and features provided by Amazon Web Services.
Similar products

Cerebra offers customized AI-powered Digital Assistants for specific use cases that help operations, production and quality teams manage day-to-day industrial operations and improve their decision making while managing large-scale, complex operations
Customer reviews
ParthasarathyT
Instant AI responses have kept developers in flow and have accelerated real-time decision making
Reviewed on Apr 16, 2026
Review provided by PeerSpot
What is our primary use case?
Since I mentioned AI writing for email and client communication, I'm actually referring to the other one which you have told me about—AI for developer tools. To confirm, I have not worked with Cerebras Fast Inference Cloud , so can you list the options once again? The second one involves AI model tools, something you started with. Specifically, the model-related tool I am referring to is model development.
What is most valuable?
Cerebras Fast Inference Cloud offers extreme inference speed and ultra-low latency, which means it can generate AI responses tens of times faster than GPU cloud solutions. The speed is truly unmatched, with single-chip execution and no networking delay, and it feels real-time to users. The chatbot feels very instant and the coding assistant does not break a developer's flow. The agent does not pause between steps, and the answer speed is nearly instant. Tokens are available even in the free trial, and the architecture is best for real-time AI batch processing and general use.
Cerebras Fast Inference Cloud has positively impacted my organization by being quite intelligent and fast, improving our productivity in terms of getting output quicker. The developers stay in flow, which is a huge productivity gain I can confirm. The lag is zero and it maintains responsiveness without freezing during multi-step tasks. Additionally, the AI agent does not stall during multi-step flow, which is a normal GPU problem where there is a timeout and passing between steps disrupts workflow. With Cerebras Fast Inference Cloud, agents can reason, call tools, and respond without delay, making multi-step tasks feel continuous and not fragmented. This has led to faster decision-making for business teams such as product managers, analysts, customer support, and sales and marketing. We see instant document summarization, real-time data analysis, faster customer response times, and shorter feedback cycles, all while reducing infrastructure and operational overhead compared to traditional GPU cloud solutions.
What needs improvement?
While Cerebras Fast Inference Cloud is much faster, there are areas for improvement, and the real benefit comes from how organizations use it. It is best to use it only where speed truly matters and not everywhere. Often, some teams try to move all AI workloads to Cerebras Fast Inference Cloud, but a better approach is to avoid offline batch jobs, nightly report generation, and cheap background inference. Integrating AI directly into daily tools without context switching allows it to become invisible, dramatically increasing productivity and adoption.
What other advice do I have?
I rate Cerebras Fast Inference Cloud ten out of ten. My advice for someone considering Cerebras Fast Inference Cloud is that if you want serious productivity in terms of quick code generation, quick development, quick debugging, and quick responses, I would recommend it.
reviewer2787606
Fast inference has enabled ultra-low-latency coding agents and continues to improve
Reviewed on Dec 12, 2025
Review from a verified AWS customer
What is our primary use case?
I use the product for the fastest LLM inference for LLama 3.1 70B and GLM 4.6.
How has it helped my organization?
We use it to speed up our coding agent on specific tasks. For anything that is latency-sensitive, having a fast model helps.
What is most valuable?
The valuable features of the product are its inference speed and latency.
What needs improvement?
There is room for improvement in supporting more models and the ability to provide our own models on the chips as well.
For how long have I used the solution?
I have used the solution for one year.
Which solution did I use previously and why did I switch?
I previously used Groq and Sambanova, but I switched because they were serving a spec dec model that had worse intelligence than the listed model.
What's my experience with pricing, setup cost, and licensing?
They are more expensive, but if you need speed, then it is the only option right now.
Which other solutions did I evaluate?
I evaluated Groq and Sambanova.
What other advice do I have?
Their support has been helpful, and I've had a few outages with them in the past, but they were resolved quickly. I recommend using it for speed and having a good fallback plan in case there are issues, but that's easy to do.
reviewer2787414
High-speed parallel inference has transformed quantitative finance decisions and expands model diversity
Reviewed on Dec 11, 2025
Review from a verified AWS customer
What is our primary use case?
Our primary use case is high TPS-burst inference, executed in parallel across many large parameter language models.
How has it helped my organization?
The throughput increase has extended decision-making time by over 50 times compared to previous pipelines when accounting for burst parallelism. This has improved both end-to-end performance and opened new use cases within our domain, specifically in the field of quantitative finance.
What is most valuable?
The most valuable features for us are the speed (TPS) and the diversity of models.
What needs improvement?
There is room for improvement in the integration within AWS Bedrock.
For how long have I used the solution?
We have been using the solution since its launch on AWS .
Which solution did I use previously and why did I switch?
We previously used a combination of Bedrock and local LLM compute.
Which other solutions did I evaluate?
We considered alternate solutions such as Groq, Bedrock, Local Inference, and lambda.ai.
What other advice do I have?
I recommend giving it a try!
reviewer2758185
Has enabled faster token inference to improve customer response times
Reviewed on Sep 23, 2025
Review from a verified AWS customer
What is our primary use case?
I use it for fast LLM token inference.
How has it helped my organization?
Cerebras' token speed rates are unmatched. This can enable us to provide much faster customer experiences.
What is most valuable?
One of the most valuable features is the very fast token inference.
For how long have I used the solution?
I have used the solution for one week.
Which solution did I use previously and why did I switch?
I am currently leveraging most top models from Google, OpenAI, Anthropic, and Meta.
What's my experience with pricing, setup cost, and licensing?
I have no advice to give regarding setup cost.
Which other solutions did I evaluate?
I also considered Sonnet , GPT, Gemini, and Scout.
What other advice do I have?
Cerebras has a great collection of team members who genuinely want to help you get up and going.