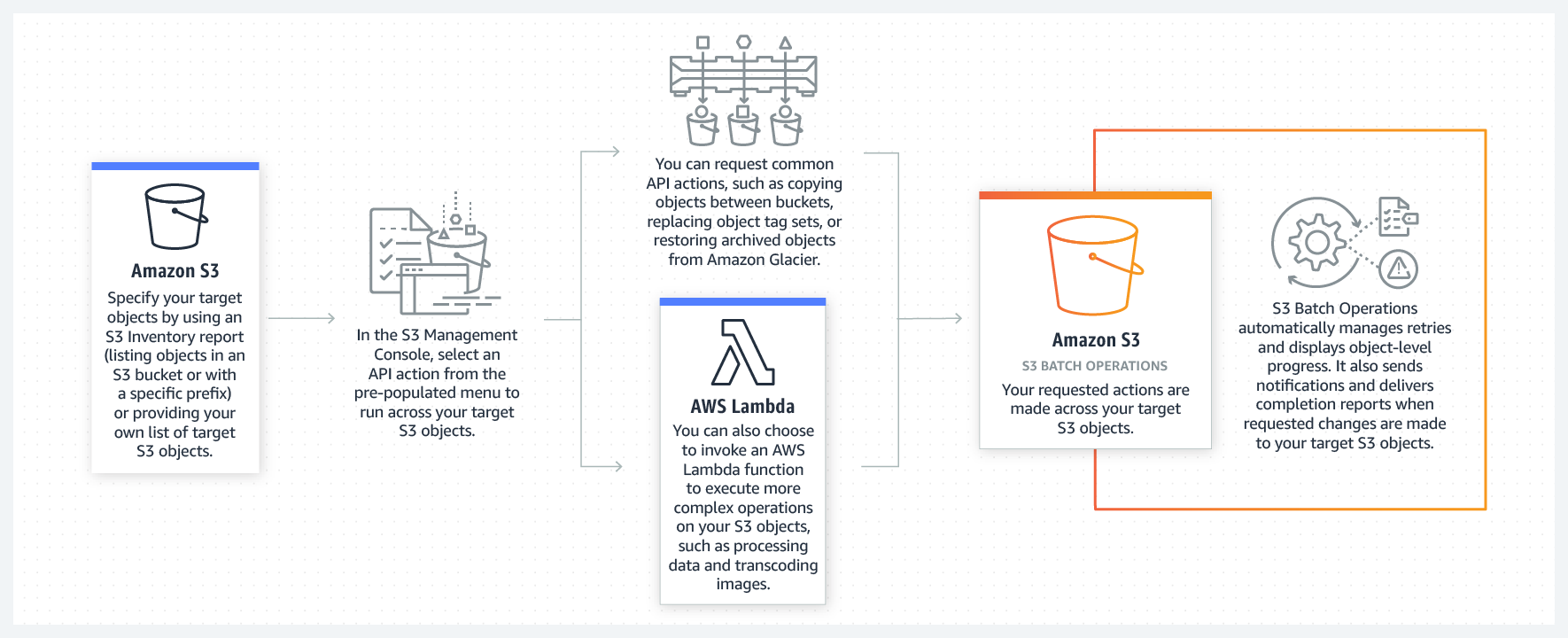
S3 Batch Operations is an Amazon S3 data management feature that lets you manage billions of objects at scale with just a few clicks in the Amazon S3 Management Console or a single API request. With this feature, you can make changes to object metadata and properties, or perform other storage management tasks, such as copying objects between buckets, replacing object tag sets, modifying access controls, and restoring archived objects from S3 Glacier — instead of taking months to develop custom applications to perform these tasks.
How to use Amazon S3 Batch Operations
In this video, learn how to set up permissions, create a job, and manage and track your jobs.
For more information, visit Amazon S3 Batch Operations in the S3 User Guide.
Ready to get started?
Instantly get access to the AWS Free Tier and start experimenting with Amazon S3.