Data Pipeline คืออะไร
Data Pipeline คืออะไร
Data Pipeline คือชุดขั้นตอนการประมวลผลเพื่อเตรียมข้อมูลขององค์กรให้พร้อมสำหรับการวิเคราะห์ องค์กรมีข้อมูลจำนวนมากจากแหล่งต่างๆ เช่น แอปพลิเคชัน อุปกรณ์ Internet of Things (IoT) และช่องทางดิจิทัลอื่น ๆ อย่างไรก็ตาม ข้อมูลดิบจะไม่สามารถใช้ประโยชน์ได้ จึงต้องย้าย จัดเรียง กรอง จัดรูปแบบใหม่ และวิเคราะห์เพื่อระบบุรกิจอัจฉริยะ Data Pipeline ประกอบด้วยเทคโนโลยีต่างๆ ในการตรวจสอบ สรุป และค้นหารูปแบบในข้อมูลเพื่อใช้ประกอบการตัดสินใจทางธุรกิจ Data Pipeline ที่จัดระเบียบเป็นอย่างดีรองรับโปรเจกต์ Big Data หลากหลายประเภท เช่น การแสดงข้อมูลเป็นภาพ การวิเคราะห์ข้อมูลเชิงสำรวจ รวมถึงงานด้านแมชชีนเลิร์นนิง
ประโยชน์ของ Data Pipeline มีอะไรบ้าง
Data Pipeline ช่วยให้คุณรวมข้อมูลจากแหล่งต่างๆ และแปลงข้อมูลเพื่อการวิเคราะห์ ช่วยขจัด Data Silo และทำให้การวิเคราะห์ข้อมูลของคุณน่าเชื่อถือและแม่นยำยิ่งขึ้น ต่อไปนี้คือประโยชน์หลักบางประการของ Data Pipeline
ปรับปรุงคุณภาพข้อมูล
Data Pipeline ทำการล้างข้อมูลและปรับแต่งข้อมูลดิบ และปรับปรุงประโยชน์สำหรับผู้ใช้ปลายทาง ช่วยกำหนดรูปแบบมาตรฐานสำหรับช่องต่างๆ เช่น วันที่และหมายเลขโทรศัพท์ พร้อมกับตรวจหาข้อผิดพลาดในการป้อนข้อมูล นอกจากนี้ยังลบความซ้ำซ้อนและรับประกันคุณภาพของข้อมูลที่สอดคล้องกันทั่วทั้งองค์กร
การประมวลผลข้อมูลที่มีประสิทธิภาพ
วิศวกรข้อมูลต้องทำงานซ้ำๆ หลายอย่างไปพร้อมกับแปลงและโหลดข้อมูล Data Pipeline ช่วยให้พวกเขาทำงานแปลงข้อมูลได้โดยอัตโนมัติ และมุ่งเน้นไปที่การค้นหาข้อมูลเชิงลึกทางธุรกิจที่ดีที่สุดแทน Data Pipeline ยังช่วยให้วิศวกรข้อมูลสามารถประมวลผลข้อมูลดิบที่สูญเสียคุณค่าเมื่อเวลาผ่านไปได้รวดเร็วยิ่งขึ้น
การผสานรวมข้อมูลที่ครอบคลุม
Data Pipeline สรุปฟังก์ชันการแปลงข้อมูลเพื่อรวมชุดข้อมูลจากแหล่งข้อมูลที่แตกต่างกัน สามารถตรวจสอบข้ามค่าของข้อมูลเดียวกันจากหลายแหล่งและแก้ไขความไม่สอดคล้องกัน ตัวอย่างเช่น สมมติว่าลูกค้ารายเดียวกันซื้อสินค้าจากแพลตฟอร์มอีคอมเมิร์ซและบริการดิจิทัลของคุณ แต่พวกเขาสะกดชื่อผิดในบริการดิจิทัล Pipeline สามารถแก้ไขความไม่สอดคล้องนี้ได้ก่อนที่จะส่งข้อมูลไปวิเคราะห์
Data Pipeline ทำงานอย่างไร
เช่นเดียวกับท่อส่งน้ำที่ย้ายน้ำจากอ่างเก็บน้ำไปยังก๊อกน้ำของคุณ Data Pipeline จะย้ายข้อมูลจากจุดรวบรวมไปยังพื้นที่เก็บข้อมูล Data Pipeline จะแยกข้อมูลจากแหล่งที่มา ทำการเปลี่ยนแปลง แล้วบันทึกลงในปลายทางที่กำหนด เราอธิบายองค์ประกอบที่สำคัญของสถาปัตยกรรม Data Pipeline ไว้ด้านล่าง
แหล่งที่มาของข้อมูล
แหล่งที่มาของข้อมูลอาจเป็นแอปพลิเคชัน อุปกรณ์ หรือฐานข้อมูลอื่น แหล่งที่มาที่แตกต่างกันอาจส่งข้อมูลไปยัง Pipeline Pipeline อาจแยกจุดข้อมูลโดยใช้การเรียก API เว็บฮุค หรือกระบวนการทำสำเนาข้อมูล คุณสามารถซิงโครไนซ์การดึงข้อมูลสำหรับการประมวลผลตามเวลาจริงหรือรวบรวมข้อมูลในช่วงเวลาที่กำหนดจากแหล่งที่มาของข้อมูลของคุณ
การแปลง
เมื่อข้อมูลดิบไหลผ่าน Pipeline ข้อมูลดังกล่าวจะเปลี่ยนไปเป็นประโยชน์มากขึ้นสำหรับระบบธุรกิจอัจฉริยะ การแปลงคือการดำเนินการต่างๆ เพื่อเปลี่ยนแปลงข้อมูล เช่น การเรียงลำดับ การจัดรูปแบบใหม่ การขจัดข้อมูลซ้ำซ้อน การตรวจสอบ และการตรวจสอบความถูกต้อง Pipeline ของคุณสามารถกรอง สรุป หรือประมวลผลข้อมูลเพื่อให้ตรงกับข้อกำหนดในการวิเคราะห์ของคุณ
การพึ่งพา
เมื่อการเปลี่ยนแปลงเกิดขึ้นตามลำดับ อาจมีการพึ่งพาเฉพาะที่ลดความเร็วในการย้ายข้อมูลใน Pipeline การพึ่งพามี 2 ประเภทหลัก ได้แก่ ด้านเทคนิคและธุรกิจ ตัวอย่างเช่น หาก Pipeline ต้องรอคิวกลางให้เต็มก่อนดำเนินการต่อ นั่นก็ขึ้นอยู่กับเทคนิค ในทางกลับกัน หาก Pipeline ต้องหยุดชั่วคราวจนกว่าหน่วยธุรกิจอื่นจะตรวจสอบข้อมูลข้ามกัน นั่นหมายถึงการพึ่งพาของธุรกิจ
จุดหมายปลายทาง
ตำแหน่งข้อมูลของ Data Pipeline ของคุณสามารถเป็นคลังข้อมูล, Data Lake หรือแอปพลิเคชันระบบธุกิจอัจฉริยะหรือการวิเคราะห์ข้อมูลอื่นๆ บางครั้ง จะเรียกปลายทางอีกอย่างว่า Data Sink
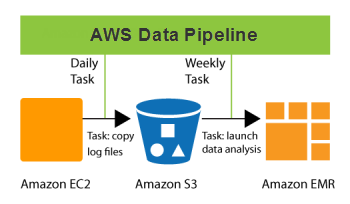
Data Pipeline มีกี่ประเภท
Data Pipeline มี 2 ประเภทหลัก ได้แก่ การประมวลผลแบบเรียลไทม์และการประมวลผลแบบเป็นชุด
Pipeline การประมวลผลแบบสตรีม
Data Stream เป็นลำดับที่เพิ่มขึ้นอย่างต่อเนื่องของแพ็กเก็ตข้อมูลขนาดเล็ก โดยปกติจะเป็นชุดของเหตุการณ์ที่เกิดขึ้นในช่วงเวลาที่กำหนด ตัวอย่างเช่น Data Stream สามารถแสดงข้อมูลเซ็นเซอร์ที่มีการวัดในช่วงชั่วโมงที่แล้วได้ การกระทำเดียว เช่น ธุรกรรมทางการเงิน สามารถเรียกได้อีกอย่างว่าเหตุการณ์ Pipeline แบบสตรีมจะประมวลผลชุดเหตุการณ์เพื่อนำไปวิเคราะห์แบบเรียลไทม์
ข้อมูลการสตรีมต้องการเวลาแฝงต่ำและความทนทานต่อข้อผิดพลาดสูง Data Pipeline ของคุณควรสามารถประมวลผลข้อมูลได้ แม้ว่าแพ็กเก็ตข้อมูลบางส่วนจะสูญหายหรือมาถึงในลำดับที่แตกต่างจากที่คาดไว้
Pipeline การประมวลผลแบบเป็นชุด
Data Pipeline การประมวลผลแบบเป็นชุดจะประมวลผลและเก็บข้อมูลปริมาณมากหรือเป็นชุด เหมาะสำหรับงานปริมาณมากที่มาเป็นครั้งคราว เช่น การทำบัญชีรายเดือน
Data Pipeline ประกอบด้วยชุดคำสั่งเรียงลำดับต่างๆ ซึ่งทุกคำสั่งจะทำงานบนชุดข้อมูลทั้งหมด Data Pipeline ให้เอาต์พุตของคำสั่งหนึ่งเป็นอินพุตไปยังคำสั่งต่อไป หลังจากการแปลงข้อมูลทั้งหมดเสร็จสิ้น Pipeline จะโหลดชุดข้อมูลทั้งหมดลงในคลังข้อมูลบนระบบคลาวด์หรือที่เก็บข้อมูลอื่นที่คล้ายกัน
อ่านเกี่ยวกับการประมวลผลเป็นชุด »
ความแตกต่างระหว่าง Data Pipeline แบบสตรีมและแบบเป็นชุด
Pipeline การประมวลผลแบบชุดจะทำงานไม่บ่อยนัก และโดยปกติจะเป็นช่วงนอกชั่วโมงเร่งด่วน เพราะต้องใช้พลังการประมวลผลสูงในช่วงเวลาสั้นๆ เมื่อทำงาน ในทางตรงกันข้าม Pipeline การประมวลผลแบบสตรีมจะทำงานอย่างต่อเนื่องและใช้พลังการประมวลผลต่ำ แต่จำเป็นต้องเชื่อมต่อกับเครือข่ายที่เชื่อถือได้และมีเวลาแฝงต่ำ
Data Pipeline และ ETL Pipeline ต่างกันอย่างไร
Pipeline กระบวนการ Extract, Transform and Load (ETL) เป็น Data Pipeline ชนิดพิเศษ เครื่องมือ ETL แยกหรือคัดลอกข้อมูลดิบจากหลายแหล่งและจัดเก็บไว้ในตำแหน่งชั่วคราวที่เรียกว่าบริเวณที่จัดเตรียมไว้ โดยแปลงข้อมูลในพื้นที่จัดเตรียมไว้และโหลดลงใน Data Lake หรือคลังข้อมูล
Data Pipeline บางรายการไม่เป็นไปตามลำดับ ETL บ้างอาจดึงข้อมูลจากแหล่งที่มาและโหลดไปไว้ที่อื่นโดยไม่มีการแปลง Data Pipeline อื่นๆ จะเป็นไปตามลำดับกระบวนการ Extract, Load and Transform (ELT) ซึ่งจะแยกและโหลดข้อมูลที่ไม่มีโครงสร้างลง Data Lake โดยตรง ซึ่งจะเปลี่ยนแปลงหลังจากย้ายข้อมูลไปยังคลังข้อมูลบนระบบคลาวด์แล้ว
AWS รองรับข้อกำหนด Data Pipeline ของคุณได้อย่างไร
AWS G lue เป็นบริการรวมข้อมูลแบบไร้เซิร์ฟเวอร์ซึ่งทำให้ผู้ใช้การวิเคราะห์ค้นพบ เตรียม ย้าย และรวมข้อมูลจากหลายแหล่งข้อมูลสำหรับการวิเคราะห์ การเรียนรู้ของเครื่อง และการพัฒนาแอปพลิเคชันได้ง่ายขึ้น
- คุณสามารถค้นพบและเชื่อมต่อกับที่เก็บข้อมูลที่หลากหลาย 80+ แห่ง
- คุณสามารถจัดการข้อมูลของคุณในแคตตาล ็อกข้อมูลส่วน กลาง
- วิศวกรข้อมูล นักพัฒนา ETL นักวิเคราะห์ข้อมูล และผู้ใช้ธุรกิจสามารถใช้ AWS Glue Studio เพื่อสร้าง เรียกใช้ และตรวจสอบท่อ ETL เพื่อโหลดข้อมูลลงในทะเลสาบข้อมูล
- AWS Glue Studio นำเสนอ อินเทอร์เฟซ Visual ETL, Notebook และโปรแกรมแก้ไขโค ้ด ดังนั้นผู้ใช้จึงมีเครื่องมือที่เหมาะสมกับชุดทักษะของพวกเขา
- ด้วย Interactive Sessions วิ ศวกรข้อมูลสามารถสำรวจข้อมูลรวมถึงงานผู้เขียนและทดสอบโดยใช้ IDE หรือสมุดบันทึกที่ต้องการได้
- AWS Glue เป็นแบบไม่ต้องใช้เซิร์ฟเวอร์และปรับขนาดตามความต้องการโดยอัตโนมัติ ดังนั้นคุณจึงสามารถเน้นที่การรับข้อมูลเชิงลึกจากข้อมูลขนาดเพตะไบต์โดยไม่ต้องจัดการโครงสร้างพื้นฐาน
เริ่มต้นใช้งาน AWS Glue โดยการสร้าง บัญชี AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages