Tutorials & Training for Big Data
Overview
Amazon Web Services provides many ways for you to learn about how to run big data workloads in the cloud. For instance, you will find reference architectures, whitepapers, guides, self-paced labs, in-person training, videos, and more to help you learn how to build your big data solution on AWS. If you are brand new to AWS, please start with our getting started page.
Tutorials & Training for Big Data
Analyst Report: 451 Research


Reference Architectures
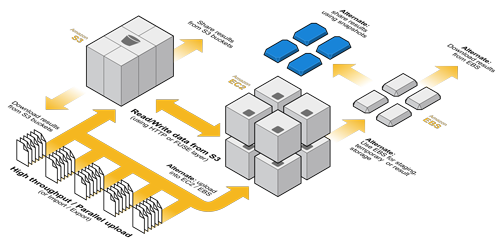
Getting Started
Amazon Web Services Getting Started Guides help you quickly learn what you need to know about starting up your first big data application on AWS. Instructions guide you through each of the steps you need to take while explanations help you understand what you are doing and why. Images in the guides help you visualize what you will see on the screen when you follow along so that you can learn by reading, seeing, and doing.
With the AWS Getting Started Guides you will:
- Learn how to easily start and run a big data application on AWS
- Get hands on experience launching your chosen application
- Read explanations of each step as you go
- Understand the importance of why you are taking each action
Whitepapers
The whitepapers section features a comprehensive list of technical AWS whitepapers, covering topics such as architecture, security and economics. These whitepapers have been authored by the AWS Team, independent analysts or the AWS Community (Customers or Partners).
Check out the following big data related whitepapers to learn more about how AWS can help you solve your big data challenges.
Self-Paced Labs
Amazon Web Services self-paced labs enable you to test products, acquire new skills, and gain practical experience working with AWS. Designed by AWS subject matter experts, these hands-on training labs provide you step-by-step instructions to help you gain confidence working with AWS technologies and learn more about building your big data project on AWS.
Available to anyone, self-paced labs enables you to:
- Gain hands-on experience working with technology in a practice environment without needing an AWS account
- Practice using AWS from your own machine
- Explore and experiment with new products and solutions
- Acquire new and practical skills in a convenient, flexible, and consumable format
- Learn on your own time and at your own pace
Featured Self-Paced Labs
Big Data on AWS
View
Recorded Webinars
Building and running an application on AWS is easy. Every month AWS employees host webinars to help you learn more about AWS and how you can get the most out of the cloud. These webinars are also saved online so you can share a webinar you have enjoyed with others as well as view previous webinars that look interesting.
Watching an AWS Webinars can help you by:
- Giving you a chance to learn about new AWS services, features, and solutions
- Providing question and answer time to help you clarify your understanding of AWS
- Making recorded webinars available to watch when you want, see the Featured Getting Started big data webinars to the left
- Discussing and demonstrating how to use AWS services so you can see how AWS services work and what your experience will be like
Featured Getting Started Webinar
Featured Getting Started Webinar
Building Your First Big Data Application on AWS
Learn how to build a Big Data application using Amazon Elastic MapReduce and other AWS Big Data Services. Hear best practices and architecture design patterns for Big Data.
Watch the recording here »
Big Data Technology Fundamentals web-based training
The Big Data Technology Fundamentals course is perfect for getting started in learning how to run big data applications in the AWS Cloud. This is a free, online training course and is intended for individuals who are new to big data concepts, including solutions architects, data scientists, and data analysts.
The course covers the development of big data solutions using the Hadoop ecosystem, including MapReduce, HDFS, and the Pig and Hive programming frameworks.
NEW - Big Data on AWS in-person training
The Big Data on AWS course is designed to teach you with hands-on experience on how to use Amazon Web Services for big data workloads. AWS will show you how to run Amazon Elastic MapReduce jobs to process data using the broad ecosystem of Hadoop tools like Pig and Hive. Also, AWS will teach you how to create big data environments in the cloud by working with Amazon DynamoDB and Amazon Redshift, understand the benefits of Amazon Kinesis, and leverage best practices to design big data environments for analysis, security, and cost-effectiveness.
Learn more about the Big Data on AWS course »
NEW - The Big Data course just got a big update.
Read the Big Data blog to learn more »
Featured re:Invent Sessions
AWS re:Invent is the largest gathering of the global Amazon Web Services community. The conference allows you to gain a deeper knowledge of AWS services and learn best practices that you can’t find anywhere else. This year, the big data track at re:Invent, included over 30 sessions covering big data development on Amazon Web Services. Watch the sessions below or check out a list of more featured big data sessions in the Big Data blog.
Building a Data Lake on AWS
AWS provides many of the building blocks required to help organizations implement a data lake. In this session, we introduce key concepts for a data lake and present aspects related to its implementation. We discuss critical success factors, pitfalls to avoid as well as operational aspects such as security, governance, search, indexing and metadata management. We also provide insight on how AWS enables a data lake architecture.
A Technical Introduction to Amazon Elastic MapReduce
Since Amazon Redshift launched last year, it has been adopted by a wide variety of companies for data warehousing. In this session, learn how customers NASDAQ, HauteLook, and Roundarch Isobar are taking advantage of Amazon Redshift for three unique use cases: enterprise, big data, and SaaS. Learn about their implementations and how they made data analysis faster, cheaper, and easier with Amazon Redshift.
Building Real-time Streaming Applications with Amazon Kinesis
Amazon Kinesis is a fully managed, cloud-based service for real-time data processing over large, distributed data streams. Customers who use Amazon Kinesis can continuously capture and process real-time data such as website clickstreams, financial transactions, social media feeds, IT logs, location-tracking events, and more. Watch this session to learn best practices for building a real-time streaming data architecture with Amazon Kinesis, and get answers to technical questions frequently asked by those starting to process streaming events.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages