亚马逊AWS官方博客
使用 Amazon SageMaker 在生产环境中对机器学习模型 A/B 测试
Original URL: https://aws.amazon.com/cn/blogs/machine-learning/a-b-testing-ml-models-in-production-using-amazon-sagemaker/
Amazon SageMaker是一项全托管服务,能够将快速构建、训练以及部署机器学习(ML)模型的能力交付至每一位开发人员及数据科学家手中。目前,包括Intuit、Voodoo、ADP、Cerner、道琼斯以及Thomson Reuters在内的成千上万家客户都在使用Amazon SageMaker以减轻ML流程的运营负担。在Amazon SageMaker的帮助下,您可以在托管端点上部署自己的ML模型,并实时获取推理结果。大家也可以通过Amazon CloudWatch轻松查看端点的性能指标、启用autoscaling以根据流量变化自动扩展端点,并在生产期间更新模型且不造成任何可用性影响。
在电子商务应用等多种实际环境中,单靠离线评估并不足以保证模型质量,我们需要在生产期间对模型进行A/B测试,并据此做出模型更新决策。借助Amazon SageMaker,大家可以在端点之上运行多个生产模型变体,轻松对ML模型执行A/B测试。这些生产模型变体可以分别对应由不同训练数据集、算法以及ML框架训练而成的ML模型,再配合不同的云实例类型,即可建立起多种测试因素组合。
现在,大家已经可以将实际流量分发至同一端点上的各个变种当中,并由Amazon SageMaker根据指定的分发方式在各变体之间分配推理流量。对于希望控制发送至各个变体的流量的用户,这项功能有助于摆脱指向特定变体的请求路由操作,显著简化实现流程。例如,大家可能需要更新生产环境中的模型,并将部分流量定向至新模型以测试其与原有模型间的性能差异。此外,在某些特定用例中,我们也需要使用特定模型处理推理请求,并调用系统中的特定变体。例如,大家可能希望测试并比较ML模型在不同客户群体中的性能表现,并对来自客户的请求做出进一步细分,将其中特定部分完全交由某一特定变体进行处理。
现在,大家可以选择使用哪个变体处理推理请求。我们只需要在每项推理请求上添加TargetVariant标头,即可由Amazon SageMaker保证由指定的变体处理该项请求。
用例:Amazon Alexa
Amazon Alexa使用Amazon SageMaker管理各类ML工作负载。Amazon Alexa团队会频繁更新其ML模型,借此应对各种新兴安全威胁。为此,在使用Amazon SageMaker中的模型测试功能向生产环境发布新的模型版本之前,该团队会测试、比较并确定哪个版本更符合其安全性、隐私性以及业务需求。关于Alexa团队在客户安全与隐私保护方面的更多详细研究信息,请参阅在文本中使用分层结构表示形式保持隐私与实用程序。
Alexa体验与设备团队软件开发经理Nathanael Teissier表示,“Amazon SageMaker中提供的模型测试功能使我们得以测试隐私保护模型的最新版本,并保证这些模型都能符合我们在客户隐私方面提出的最高标准。作为一项新功能,SageMaker能够根据各项请求选择所需要的生产变体,从而在无需修改当前设置的前提下为A/B测试的部署策略带来新的可能性。”
在本文中,我们将向大家展示如何通过指向变体的流量分配与特定变体调用,轻松在Amazon SageMaker当中对ML模型执行A/B测试。我们的测试模型已经配合不同训练数据集完成训练,且所有生产变体皆部署在Amazon SageMaker端点之上。
使用Amazon SageMaker进行A/B测试
在生产ML工作流当中,数据科学家与工程师们经常尝试各种方式以改进现有模型,例如执行超参数调优,或者引入更多或最新数据进行训练或改善特征选择等。而对新模型以及处理生产流量的旧模型上执行A/B测试,往往是模型验证流程中的最后一个环节。在A/B测试中,我们需要测试模型朱同变体,并比较各个变体的相对性能。如果新版本带来的性能优于或者等同于原有版本,即可使用新模型替换新模型。
Amazon SageMaker允许用户通过生产变体,在同一端点之后测试多种模型或者模型的多个版本。每个 ProductionVariant 都会标识一个ML模型以及托管该模型所对应的部署资源。我们可以为每个生产变体提供流量分配,或者在各项请求中直接调用目标变体以将端点调用请求分配给多个生产变体。在以下各章节中,我们将具体介绍测试ML模型的两种方法。
向各变体分配流量以测试模型
要通过向多个模型分配流量以测试各模型,我们需要在端点配置中为各生产变体指定权重,从而规划路由至各个模型的流量百分比。Amazon SageMaker会根据大家提供的具体权重,在各生产变体之间分配流量。这也是生产变体在实际使用中的默认方式。下图所示,详细介绍了整个测试流程的具体实现方式。请注意,我们还应在每个推理响应中包含处理请求的变体名称。

通过调用各变体进行模型测试
要通过调用各变体进行模型测试,我们需要在请求当中设置TargetVariant标头。如果您已经提供了权重并指定TargetVariant以分配流量,则目标路由将覆盖掉原有流量分发方式。下图所示,详细介绍了这种方法的运作方式。在这里,我们在推理请求中调用ProductionVariant3,您也可以同时在各项请求中调用不同的变体。
解决方案概述
本文将通过示例向大家介绍如何使用这项新功能。我们可以在Amazon SageMaker中使用Jupyter notebook以创建用于托管两套模型的端点(使用ProductionVariant)。两套模型皆通过Amazon SageMaker内置的XGBoost算法配合用于预测移动运营商客户流失的数据集训练而成。关于模型训练的更多详细信息,请参阅XGBoost客户流失预测。在以下用例中,我们将使用同一数据集中的不同子集进行模型训练,并在各模型中使用不同的XGBoost算法版本。
通过使用Amazon SageMaker Jupyter notebook中的A/B测试示例,大家也可以自己尝试整个过程。您可以在Amazon SageMaker Studio或者Amazon SageMaker notebook实例中实际运行。我们使用的数据集完全公开可用,Daniel T. Larose也曾在《从数据中发现知识(Discovering Knowledge in Data)》一书中提到这套数据集。作者称,其为来自加州大学尔湾分校的机器学习数据集。
本次演练包含以下操作步骤:
- 创建并部署模型。
- 调用已部署模型。
- 评估变体性能。
- 将推理流量导向您所选定的生产变体。
创建并部署模型
首先,我们需要定义模型在Amazon Simple Storage Service(Amazon S3)中的位置。在后续模型部署步骤当中,我们需要使用这些位置。具体请参见以下代码:
接下来,使用容器镜像与模型数据创建模型对象。我们可以将这些模型对象作为生产变体部署在端点之上。模型的具体设定,可以匹配不同的数据集、不同算法、不同的ML框架以及不同的超参数设置。具体请参见以下代码:
创建2个生产变体,每个变体都对应特定的模型与资源需求(即实例类型与数量)。要在2个变体之间平均分发推理请求,请将二者的 initial_weight设置为0.5,具体参见以下代码:
使用以下代码,将这些生产变体部署在Amazon SageMaker端点上:
调用部署完成的模型
现在,我们可以将数据发送至此端点并实时获取推理结果。在本文中,我们使用Amazon SageMaker支持的两种方法进行模型测试:将流量分发至各变体,以及调用特定变体。
将流量分发至各变体
Amazon SageMaker会根据用户在之前变体定义中配置的各项权重,在端点上的生产变体之间分配流量。具体参见以下端点调用代码:
Amazon SageMaker会将各变体中的延迟及调用等指标提交至Amazon CloudWatch。关于端点指标的完整列表,请参阅使用Amazon CloudWatch监控Amazon SageMaker。大家可以查询Amazon CloudWatch以获取各变体的调用次数,了解默认情况下如何各变体接收到的调用量。我们得出的结果应类似于下图:
调用特定变体
以下用例使用新的Amazon SageMaker变体功能以调用特定变体。在具体操作中,我们只需使用新参数定义希望调用的特定ProductionVariant即可。以下代码将在所有请求中调用Variant1,大家也可以通过相同的流程调用其他变体:
要确认已经Variant1处理了所有新调用,请查询CloudWatch以获取每个变体的调用次数。通过下图可以看到,Variant1已经完成了最近所有请求中的调用(最新时间戳),且不存在指向Variant2的调用。
评估变体性能
下图评估了Variant1的准确率、精准率、召回率、F1得分以及ROC/AUC。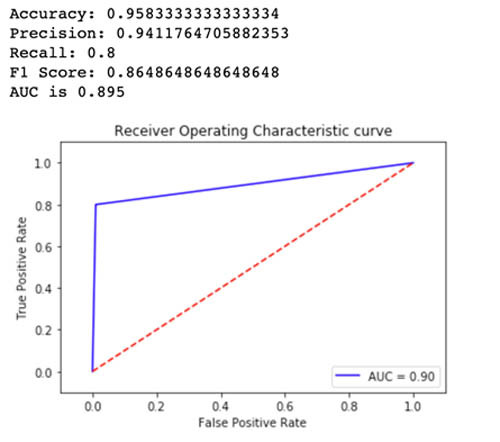
下图评估了Variant2中的相同预测指标。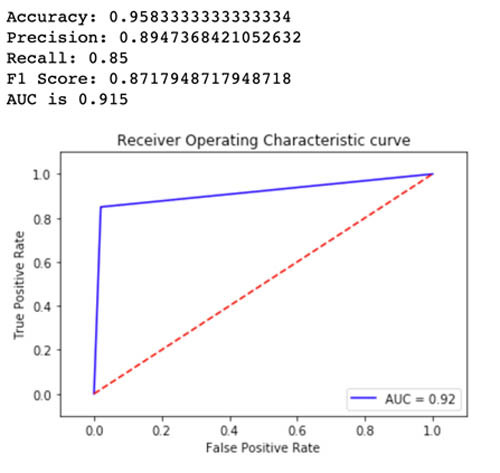
对于大多数已定义的指标,Variant2的效果都更好,因此大家可以选择它作为生产环境中的推理流量处理方案。
将推理流量导向您所选定的生产变体
现在,我们已经确定了 Variant2模型比 Variant1效果更好,接下来就是将更多流量转移至 Variant2。
大家当然可以继续使用TargetVariant调用选定的变体。但更简单的处理方法,是使用UpdateEndpointWeightsAndCapacities对分配给各变体的权重进行更新。如此一来,无需修改端点即可更改指向各生产变体的流量分配。
大家应该还记得,之前创建模型与端点配置时,我们在变体权重中将流量分配比例设定为50/50。下图所示,为指向各变体总调用数量的CloudWatch指标,我们可以由此看到各变体的调用模式。
要将75%的流量转移到Variant2,请使用UpdateEndpointWeightsAndCapacities为各变体分配新的权重。具体参见以下代码:
Amazon SageMaker现在会将75%的推理请求导向Variant2,只为Variant1保留25%请求。
下图中的CloudWatch指标为各变体的总调用次数,可以看到Variant2的调用次数明显高于Variant1。
我们可以继续监控各项指标,并在某一变体的性能达到理想水平后将100%流量路由至该变体。在本用例中,我们使用UpdateEndpointWeightsAndCapacities更新针对变体的流量分配。将Variant1的权重设定为 0.0,Variant2的权重设置为 1.0。如此一来,Amazon SageMaker将把所有推理请求100%发送至Variant2,参见以下代码:
下图所示为针对各变体的总调用量CloudWatch指标,可以看到 Variant2处理了所有推理请求,而 Variant1没有处理任何推理请求。
现在,我们可以安全地更新端点,并将 Variant1从端点中删除。大家还可以向端点中添加新的变体,并参照本次演练中的各项步骤继续测试生产环境下的新模型。
总结
Amazon SageMaker可帮助用户在端点之上运行多个生产变体,从而轻松对生产环境中的ML模型进行A/B测试。大家可以使用SageMaker提供的功能配合不同训练数据集、超参数、算法以及ML框架测试由此训练出的模型,了解它们在不同实例类型上的执行性能,并将各项因素整合起来形成不同搭配。我们还可以在端点上的各变体之间进行流量分配,Amazon SageMaker会根据指定的分发方式将推理流量拆分并分发至各个变体。另外,如果您需要面向特定客户群体测试模型性能,则可通过SageMaker提供的 TargetVariant标头指定负责处理特定推理请求的变体,相应请求将被自由路由至您所指定的变体处。关于A/B测试的更多详细信息,请参阅AWS开发者指南:在生产环境中测试模型。