Amazon Redshift 是为OLAP场景云原生设计的企业级数据仓库,许多行业领先的第三方工具(BI商业智能、报表及可视化数据分析工具)已经与Amazon Redshift 深度集成,可以对Amazon Redshift的数据进行加载、转换和可视化。Amazon Redshift 通过大规模并行处理(MPP)、列式数据存储和高效且具有针对性的数据压缩等特性的组合,实现了高效存储和优异的查询性能,因此一经推出就受到广大用户的好评。
Amazon Redshift的表设计与OLTP的表设计有很大区别,Amazon Redshift需要面对海量数据集和极其复杂的分析查询,如果设计不当,大规模并行处理就会受到数据分配不均和数据移动的影响,从而大大影响性能,本文希望能为读者理清Amazon Redshift表设计的一些基本原则,分享一些最佳实践,让读者能最大限度地发挥Amazon Redshift的潜力。阅读本文需要一定的基础数据库知识。
一、表设计要素与目标
1.1、表设计要素
首先,我们需要了解一些Amazon Redshift的基本概念和表设计的要素。
1.1.1 节点和切片
Amazon Redshift 集群由节点组成。每个集群包括一个领导节点以及一个或多个计算节点。
- 领导节点接收来自客户端应用程序的查询、解析查询并制定查询执行计划。然后,领导节点和计算节点协调这些计划并行执行,之后,领导节点聚合来自计算节点的中间结果。最后,领导节点会将这些结果最终返回至客户端应用程序。
- 计算节点执行查询执行计划,并在节点自身之间传输数据完成查询。中间结果被送回至客户端应用程序之前,会先发送至领导节点进行聚合。
- 一个计算节点分为多个切片。将为每个切片分配节点的内存和磁盘空间的一部分,从而处理分配给节点的工作负载的一部分。每个节点的切片数取决于集群的节点大小。例如,每个xlarge 计算节点有两个切片,每个ds2.8xlarge 计算节点有 16 个切片。所有节点均参与并行查询执行,查询处理应尽可能跨切片均匀分配的数据。
1.1.2 分配方式
将数据加载到表中时,Amazon Redshift 根据表的分配方式将表中的行分配到各个计算节点。在运行查询时,查询优化程序根据执行任何联接和聚合的需要将行重新分配到计算节点。Amazon Redshift中表有以下4种分配方式。
EVEN 分配
不管任意特定列中的值是什么,领导节点都以轮询方式向所有切片分配行。当表不参与联接或无法明确地在 KEY 分配和 ALL 分配之间做出选择时,即可使用 EVEN 分配。
KEY 分配
根据一列中的值分配行。领导节点会将匹配的值放置到同一个节点切片上。如果基于两个表的联接键来分配这对表,领导节点会根据联接列中的值在切片上并置行,使共同列相匹配的值实际存储在一起。
ALL 分配
每个节点都会分配一份整个表的副本。而相对的,EVEN 分配或 KEY 分配只将表中的部分行放置在每个节点上。
AUTO分配
如果您未指定带 CREATE TABLE 语句的分配方式,Amazon Redshift 将应用AUTO分配。利用AUTO分配,Amazon Redshift 可基于表数据大小分配最佳分配方式。例如,Amazon Redshift 最初向小型表分配的是 ALL 分配,然后在表变大时更改为 EVEN 分配。当表从 ALL 分配更改为 EVEN 分配时,存储利用率可能略有变化。几秒钟后,分配更改将在后台进行。Amazon Redshift 绝不会将分配方式从 EVEN 更改为 ALL。
1.1.3 排序键
在创建表时,您可以将其中一个或多个列定义为排序键。初次向空表中加载数据时,行以排序顺序存储在磁盘上。有关排序键的信息会被传递给查询计划程序,后者借助该信息构建出能够充分利用数据排序方式的计划。
复合排序键(Compound Sort Key)
复合键由排序键定义中列出的所有列组成(顺序即为其排列顺序)。当查询的筛选条件应用了使用排序键前缀的条件(如筛选条件和联接)时,复合排序键最为有用。当查询只依赖于辅助排序列而不引用主列时,复合排序的性能优势会下降。COMPOUND 是默认的排序类型。
交错排序键(Interleaved Sort Key)
交错排序为排序键中的每个列或列的子集赋予相同的权重。如果多个查询使用不同的列作为筛选条件,则通常可以使用交错排序方式来提高这些查询的性能。譬如当查询对辅助排序列使用限制性谓词时,与复合排序相比,交错排序可显著提高查询的性能。
1.2、设计目标
了解了以上一些基础概念后,我们来了解Amazon Redshift表设计的主要目标。
1.2.1 数据分配目标
数据重新分配
将数据加载到表中时,Amazon Redshift 根据表的分配方式将表中的行分配到各个节点切片。作为查询计划的一部分,优化程序会确定需要将数据块放置在何处,以便最好地执行查询。然后,在执行期间,数据可能被实际移动或重新分配。重新分配可能涉及将特定的行发送到特定的节点以进行联接,或将整个表广播到所有节点。数据重新分配可能占到查询计划成本的一大部分,其产生的网络流量可能会影响其他数据库操作并降低整个系统的性能。所以我们调整表的数据分配有两个主要目标:
- 将工作负载均匀地分配到集群中的节点上。不均匀的分配或数据分配偏斜会导致某些节点执行的工作比其他节点多,从而影响查询性能。
- 尽量减少查询执行期间的数据移动。如果参与联接或聚合的行已在节点上与其在其他表中将要联接的行并置,则优化程序在查询执行期间不必重新分配过多的数据。
您为表选择的分配策略会对查询性能、存储需求、数据加载和维护产生重大影响。通过为每张表设计最佳的分配方式,您可以均衡数据分配并显著提高整个系统的性能。
1.2.2 排序键目标
排序可实现范围限制谓词的高效处理。Amazon Redshift 将列式数据存储在 1 MB 大小的磁盘数据块中。每个数据块的最小值和最大值作为元数据的一部分存储。如果查询使用范围限制谓词,则查询处理器可在表扫描期间借助数据块的最小值和最大值来快速跳过大量的数据块。如图1所示,如果某张表存储着按日期排序的1年数据,且查询指定了一天的日期范围,则该查询可能跳过多达 99.7% 的磁盘数据块扫描操作。如果数据未排序,则该查询就不得不扫描更多(也可能是全部)的磁盘数据块。

图1
二、表设计最佳实践
2.1 分配方式最佳实践
前文中我们已经说明了数据分配的两个目标即均匀分配工作负载和减少数据移动,在Amazon Redshift中创建表后,无法更改其分配方式。要使用其他分配方式,您需要重新创建新表并借助深层复制填充该新表,所以我们需要在初期设计中充分考虑我们当前的需求和未来的增长的趋势。下面是一些分配方式的最佳实践:
- 如果表大部分为非规范化数据且不参与联接,或如果您无法明确确定采用其他分配方式,请使用 EVEN 分配。
- 当事实表和一个维度表频繁join时,选择联接键作为事实表和维度表的KEY分配键,从而实现两者并置,但是要注意,事实表只能有一个分配键。任何通过其他键联接的维度表都不能与此事实表并置。所以,我们要根据联接频率和联接行的大小妥善选择一个要并置的维度。另外,请注意KEY分配时,可能导致数据分配不均匀。
- 我们要根据常用查询筛选后的数据集的大小决定谁是最大的维度。而不是单纯看整个表的大小。
- 将一些维度表使用 ALL 分配。如果一个维度表不能与事实表或其他重要的联接表并置,您可以通过将整个表分配到所有节点的方法来大大提高查询性能。不过需要注意的是使用 ALL 分配可能会使存储空间需求成倍增长,并且会增加加载时间和维护操作,所以在选择 ALL 分配前应权衡所有因素。
- 选择高基数的列筛选结果集,所谓高基数列是指不同列值多的列。假设您将一个销售表的日期列作为分配键,除非您的大多数销售都是季节性的,否则数据分配会非常均匀。但是,如果您的查询通常使用范围受限谓词进行筛选并缩小日期期间的范围,则大多数筛选出来的行很可能都将出现在有限的一组切片上并且查询工作负载将偏斜。这也可能对性能造成不利影响。
- Amazon Redshift 不强制实施主键和外键约束,但查询优化程序在生成查询计划时会使用它们。如果您在表上设置了主键和外键,则您的应用程序必须维护这些键的有效性。
2.2 排序键选择最佳实践
复合排序键与交错排序键区别
- 复合排序键可以加快联接、GROUP BY 和 ORDER BY 操作,以及使用 PARTITION BY 和 ORDER BY 的窗口函数。例如,当数据在联接列上分配和预先排序时,可以使用合并联接(通常快于哈希联接)。此外,复合排序键还有助于提高压缩率。
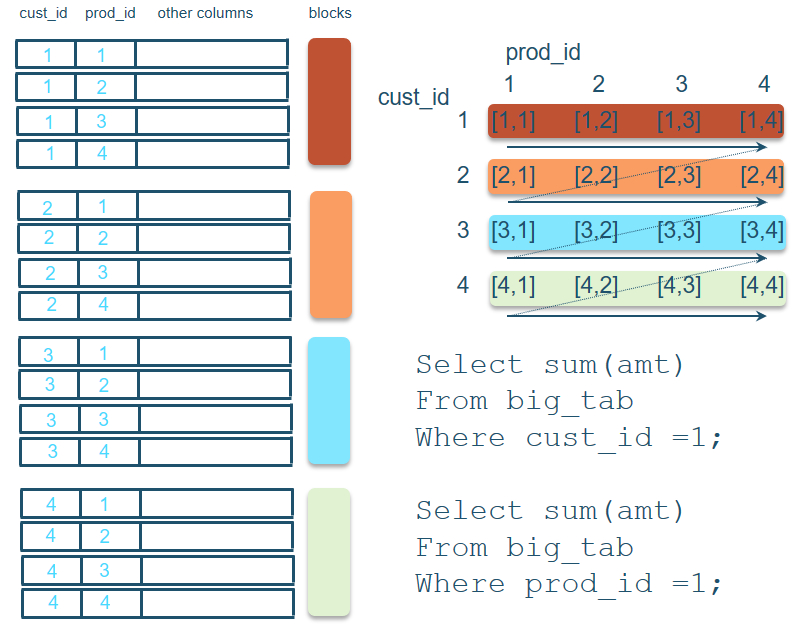
- 为了便于理解,我们假设有一个表以cust_id和prod_id做排序键,其中cust_id作为主列而prod_id作为辅助排序列,每四条记录填充一个数据块,如图2所示。那么当我们查询cust_id=1的记录时,我们只需要扫描一个数据块,而当查询prod_id=1的记录时,我们需要扫描四个数据块。

图2
- 交错排序为排序键中的每个列或列的子集赋予相同的权重。我们用同一个例子来说明,依然是cust_id和prod_id作为排序键,但这次是交错排序,如图3所示。那么当我们查询cust_id=1或者prod_id=1的记录时,我们都要访问两个数据块。
- 交错排序对于高选择性查询(即在 WHERE 子句中对一个或多个排序键列进行筛选的查询,如select c_name from customer where c_region = ‘ASIA’)最为有效。交错排序的优势随着受限制排序列的数量增加而增大。
- 交错排序对于大型表将更为有效。排序是针对每个切片应用的,因此,当某张表大到足以使每个切片占用多个 1 MB 数据块,从而使查询处理器能够借助限制性谓词跳过大量的数据块时,交错排序最为有效。要查看表使用的数据块数,请查询STV_BLOCKLIST 系统视图。
- 对单一列排序时,如果该列的值拥有较长的共同前缀,则交错排序的性能要优于复合排序。如都以“http://www”打头的 URL。复合排序键使用前缀中有限数量的字符,因此会产生大量的重复键。交错排序为区域映射值使用了内部压缩方案,使它们能够更好地区分具有较长共同前缀的列值。
- 请勿在具有单调递增属性的列 (例如,身份列、日期或时间戳) 上使用交错排序键。
- 当您考虑交错排序键时,需要在可能获得的性能提升与增加的负载以及vacuum 次数之间进行权衡。

图3
REINDEX
- 在您向已包含数据且已排序的表中不断添加行的过程中,性能会逐渐下降。复合排序和交错排序都会出现这种性能下降,但交错排序的表受到的影响更大。
- VACUUM 可恢复排序顺序,但对于交错排序的表,该操作可能需要花费更长的时间,因为合并新的交错数据可能涉及到修改每一个数据块。
- 如果偏斜过大,则性能会受到影响。要重新分析排序键并恢复性能,请运行包含 REINDEX 关键字的 VACUUM 命令。对于交错排序的表,由于它需要对数据进行额外的分析,因此,VACUUM REINDEX 需要花费比标准 VACUUM 操作还要长的时间。
- 要查看有关键分配偏斜和上次重建索引时间的信息,请查询SVV_INTERLEAVED_COLUMNS 系统视图。
三、实验
接下来,我们将做几个实验来验证此前的理论,实验所用的集群硬件为2台dc1.large实例。请注意实验的数据集不同,硬件条件不同,查询语句不同,实验结果自然也会有所不同,但是我们可以从实验中尝试总结出一些规律,以便在今后的工作中可以避免一些明显的错误。
3.1 复合排序键与交错排序键区别
准备
我们创建两个表lineorder_ec和lineorder_ei,两个表有相同的数据,计600037902行,表大小均为33G左右 ,分配方式为even,排序键选择lo_orderkey, lo_orderdate, lo_custkey, lo_suppkey四个列,两个表中lineorder_ec选择复合排序,lineorder_ei选择交错排序,其建表语句如下:
CREATE TABLE lineorder_ec
(
lo_orderkey INTEGER NOT NULL,
lo_linenumber INTEGER NOT NULL,
lo_custkey INTEGER NOT NULL,
lo_partkey INTEGER NOT NULL,
lo_suppkey INTEGER NOT NULL,
lo_orderdate INTEGER NOT NULL,
lo_orderpriority VARCHAR(15) NOT NULL,
lo_shippriority VARCHAR(1) NOT NULL,
lo_quantity INTEGER NOT NULL,
lo_extendedprice INTEGER NOT NULL,
lo_ordertotalprice INTEGER NOT NULL,
lo_discount INTEGER NOT NULL,
lo_revenue INTEGER NOT NULL,
lo_supplycost INTEGER NOT NULL,
lo_tax INTEGER NOT NULL,
lo_commitdate INTEGER NOT NULL,
lo_shipmode VARCHAR(10) NOT NULL
)
DISTSTYLE even
compound SORTKEY
(
lo_orderkey,
lo_orderdate,
lo_custkey,
lo_suppkey
);
CREATE TABLE lineorder_ei
(
lo_orderkey INTEGER NOT NULL,
lo_linenumber INTEGER NOT NULL,
lo_custkey INTEGER NOT NULL,
lo_partkey INTEGER NOT NULL,
lo_suppkey INTEGER NOT NULL,
lo_orderdate INTEGER NOT NULL,
lo_orderpriority VARCHAR(15) NOT NULL,
lo_shippriority VARCHAR(1) NOT NULL,
lo_quantity INTEGER NOT NULL,
lo_extendedprice INTEGER NOT NULL,
lo_ordertotalprice INTEGER NOT NULL,
lo_discount INTEGER NOT NULL,
lo_revenue INTEGER NOT NULL,
lo_supplycost INTEGER NOT NULL,
lo_tax INTEGER NOT NULL,
lo_commitdate INTEGER NOT NULL,
lo_shipmode VARCHAR(10) NOT NULL
)
DISTSTYLE even
interleaved SORTKEY
(
lo_orderkey,
lo_orderdate,
lo_custkey,
lo_suppkey
);
测试
在2个表上分别执行7个查询,从不同维度筛选数据,譬如订单号、订单日期、顾客编号以及以上条件的组合。筛选数据后求取符合条件所有订单税值的最小值和最大值
第一个查询涉及排序键的第一列,第二个查询涉及排序键的第二列,第三个查询涉及排序键的第三列,第四个查询涉及排序键的第四列,第五个查询涉及排序键的第一列和第二列,第六个查询涉及排序键的第一和第三列,第七个查询涉及排序键的第二和第三列,针对两张表的测试语句如下:
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_orderkey=6 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderkey=6 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_orderdate=19960102 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderdate=19960102 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_custkey=1112441 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderkey=1112441 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_suppkey=287503 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_suppkey=287503 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_orderkey=7 and lo_orderdate=19960110 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderkey=7 and lo_orderdate=19960110 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_orderkey=7 and lo_custkey=782686 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderkey=7 and lo_custkey=782686 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ec where lo_orderdate=19960110 and lo_custkey=782686 ;
select max(lo_tax),min(lo_tax) from liuyiyi.lineorder_ei where lo_orderdate=19960110 and lo_custkey=782686 ;
结果
| 查询涉及列 |
组合排序 |
交错排序 |
| 第一列 |
2.58 |
7.39 |
| 第二列 |
8.69 |
7.47 |
| 第三列 |
8.72 |
7.48 |
| 第四列 |
7.72 |
7.32 |
| 第一列和第三列 |
2.58 |
10.24 |
| 第一列和第三列 |
2.59 |
11.21 |
| 第二列和第三列 |
10.42 |
10.54 |
通过实验,我们可以看到:
- 针对组合排序键的查询where子句是否涉及主列对查询性能的影响极其明显,只涉及辅助排序列的查询性能较差。
- 交错排序键在涉及排序键列不同列组合的各种查询中表现比较平均。
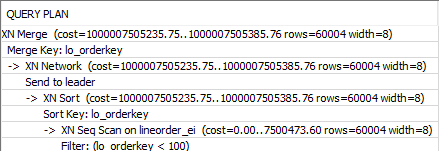
- 对于组合排序键来说,针对主列,主列和第一个辅助排序列以及涉及组合排序键所有列的查询,从执行计划中可以看到没有xn sort步骤,直接send to leader,而交错排序还是有xn sort步骤,sort key是lo_orderkey


3.2 分配方式区别
准备
实验的数据集按星型模型设计,其中sales表是事实表, times,customers 以及products是维度表。其中sales事实表大小3G,times维度表大小0.3G,products维度表大小0.2G,customers维度表大小0.2G。实验中我们对事实表尝试KEY和EVEN两种分配方式,维度表尝试KEY、EVEN和ALL分配,执行相同查询,针对事实表和维度表不同数据分配的排列组合,测试查询效果,进而使读者能直观认识到不同数据分配对查询性能的影响。
请注意表名后缀,后缀_e的表采取EVEN分配,后缀_k的表采取KEY分配,而后缀_a的表采取ALL分配。因为建表语句较长,为了不分散读者注意力,我将建表语句置于后面附录部分,读者可自行参阅。
测试
接下来的查询均是将事实表sales和维度表times,customers 以及products进行联接,而后按季度,产品名称,产品价格,客户信用卡额度,客户婚姻状况进行分组,显示汇总销售数据,查询内容相同,但是涉及表的数据分配不同,以此测试事实表和维度表不同的数据分配对相同查询语句性能的影响。同样地,因为测试语句较长,为了不分散读者注意力,我将测试语句置于后面附录部分,读者可自行参阅。具体每个查询涉及表的数据分配特征如下所示:
- 事实表数据key分配+交错排序键,维度表数据全部key分配
- 事实表数据key分配+复合排序键,维度表数据全部key分配
- 事实表数据even分配,维度表数据全部key分配
- 事实表数据key分配+交错排序键,维度表times数据 key分配且与事实表键值相同,其他维度表数据全部all分配
- 事实表数据key分配+复合排序键,维度表times 数据key分配且与事实表键值相同,其他维度表数据全部all分配
- 事实表数据even分配,维度表数据全部all分配
- 事实表数据even分配,维度表数据全部even分配
- 事实表数据even分配,维度表数据全部key分配
结果
| 查询涉及表的数据组织 |
cost |
Join类型 |
重分配类型 |
| 事实表数据key分配+交错排序键,维度表数据全部key分配 |
31121437712.42 |
Hash join |
DS_BCAST_INNER+ DS_DIST_INNER +DS_DIST_NONE |
| 事实表数据key分配+复合排序键,维度表数据全部key分配 |
31121082423.82 |
Hash join+Merge Join |
DS_BCAST_INNER+ DS_DIST_INNER+ DS_DIST_NONE |
| 事实表数据even分配,维度表数据全部key分配 |
371776381.48 |
Hash join |
DS_BCAST_INNER+ DS_DIST_INNER |
| 事实表数据key分配+交错排序键,维度表times数据 key分配且与事实表键值相同,其他维度表数据全部all分配 |
4086534.53 |
Hash join |
DS_DIST_ALL_NONE
+DS_DIST_NONE
|
| 事实表数据key分配+复合排序键,维度表times 数据key分配且与事实表键值相同,其他维度表数据全部all分配 |
2552664.38 |
Hash join+Merge Join |
DS_DIST_ALL_NONE
+DS_DIST_NONE
|
| 事实表数据even分配,维度表数据全部all分配 |
4084534.58 |
Hash join |
DS_DIST_ALL_NONE |
| 事实表数据even分配,维度表数据全部even分配 |
31413686534.53 |
Hash join |
DS_BCAST_INNER |
| 事实表数据even分配,维度表数据全部key分配 |
31413686534.53 |
Hash join |
DS_BCAST_INNER+ DS_DIST_INNER |
我们针对以上结果做出分析,可以总结出以下规律:
- 我们可以看到,通过实验验证了此前介绍的表设计最佳实践,事实表的数据做EVEN或KEY分配,维度表的数据做ALL分配效果不错。
- 如果维度表的数据全部做KEY或者EVEN分配,可以清楚地看到性能极差。
- 使执行语句cost最小的数据分配方式是事实表和其中一个维度表的数据都以KEY分配,且根据共同列分配事实表和这个维度表的数据(事实表做组合排序),其他维度表的数据则选择ALL分配,如果以上条件不变,仅仅事实表选择交错排序则性能比选择会组合排序时下降。
- 事实表和其中一个维度表的数据都以KEY分配,根据共同列分配事实表和这个维度表的数据(事实表做组合排序)时,执行计划中的联接类型会出现merge join,其他情况下则都是hash join。
- 只要是维度表的数据做ALL分配或者可以根据共同列分配事实表和这个维度表的数据,那么就可以不做重分配,执行计划中可以看到DS_DIST_ALL_NONE +DS_DIST_NONE,否则一定会重分配,执行计划中会看到DS_BCAST_INNER或DS_DIST_INNER。
限于章节,关于执行计划中联接方式和数据重分配的意义以及执行计划各要素的说明我们将在下一篇博客《对症下药-Amazon Redshift调优漫谈》中详细介绍。
附录
事实表
/*even分配的事实表*/
CREATE TABLE IF NOT EXISTS sh.sales_e(
prod_id NUMERIC(38,18) NOT NULL,
cust_id NUMERIC(38,18) NOT NULL,
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
channel_id NUMERIC(38,18) NOT NULL,
promo_id NUMERIC(38,18) NOT NULL,
quantity_sold NUMERIC(10,2) ENCODE ZSTD NOT NULL,
amount_sold NUMERIC(10,2) ENCODE ZSTD NOT NULL
)
DISTSTYLE EVEN
SORTKEY
(
time_id,
channel_id,
cust_id,
prod_id,
promo_id
);
/*key分配的事实表,复合排序键*/
CREATE TABLE IF NOT EXISTS sh.sales_c(
prod_id NUMERIC(38,18) NOT NULL,
cust_id NUMERIC(38,18) NOT NULL,
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
channel_id NUMERIC(38,18) NOT NULL,
promo_id NUMERIC(38,18) NOT NULL,
quantity_sold NUMERIC(10,2) NOT NULL,
amount_sold NUMERIC(10,2) NOT NULL
)
DISTSTYLE KEY
DISTKEY
(
time_id
)
compound SORTKEY
(
time_id,
channel_id,
prod_id,
promo_id,
cust_id
);
/*key分配的事实表,交错排序键*/
CREATE TABLE IF NOT EXISTS sh.sales_k(
prod_id NUMERIC(38,18) NOT NULL,
cust_id NUMERIC(38,18) NOT NULL,
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
channel_id NUMERIC(38,18) NOT NULL,
promo_id NUMERIC(38,18) NOT NULL,
quantity_sold NUMERIC(10,2) ENCODE ZSTD NOT NULL,
amount_sold NUMERIC(10,2) ENCODE ZSTD NOT NULL
)
DISTSTYLE KEY
DISTKEY
(
time_id
)
interleaved SORTKEY
(
time_id,
channel_id,
cust_id,
prod_id,
promo_id
);
维度表
/*all分配的维度表*/
CREATE TABLE IF NOT EXISTS sh.customers_a(
cust_id NUMERIC(38,18) NOT NULL,
cust_first_name CHARACTER VARYING(20) ENCODE ZSTD NOT NULL,
cust_last_name CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_gender CHARACTER VARYING(1) NOT NULL,
cust_year_of_birth SMALLINT NOT NULL,
cust_marital_status CHARACTER VARYING(20),
cust_street_address CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_postal_code CHARACTER VARYING(10) ENCODE ZSTD NOT NULL,
cust_city CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
cust_city_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_state_province CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_state_province_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
country_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_main_phone_number CHARACTER VARYING(25) ENCODE ZSTD NOT NULL,
cust_income_level CHARACTER VARYING(30) ENCODE ZSTD,
cust_credit_limit NUMERIC(38,18) ENCODE ZSTD,
cust_email CHARACTER VARYING(30) ENCODE ZSTD,
cust_total CHARACTER VARYING(14) ENCODE ZSTD NOT NULL,
cust_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_src_id NUMERIC(38,18) ENCODE ZSTD,
cust_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE all
SORTKEY
(
cust_id,
cust_gender,
cust_marital_status,
cust_year_of_birth
);
CREATE TABLE IF NOT EXISTS sh.products_a(
prod_id INTEGER NOT NULL,
prod_name CHARACTER VARYING(50) ENCODE ZSTD NOT NULL,
prod_desc CHARACTER VARYING(4000) ENCODE ZSTD NOT NULL,
prod_subcategory CHARACTER VARYING(50) NOT NULL,
prod_subcategory_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_subcategory_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_category CHARACTER VARYING(50) NOT NULL,
prod_category_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_category_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_weight_class SMALLINT ENCODE ZSTD NOT NULL,
prod_unit_of_measure CHARACTER VARYING(20) ENCODE ZSTD,
prod_pack_size CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
supplier_id INTEGER ENCODE ZSTD NOT NULL,
prod_status CHARACTER VARYING(20) NOT NULL,
prod_list_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_min_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_total CHARACTER VARYING(13) ENCODE ZSTD NOT NULL,
prod_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_src_id NUMERIC(38,18) ENCODE ZSTD,
prod_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE all
SORTKEY
(
prod_id,
prod_category,
prod_status,
prod_subcategory
);
CREATE TABLE IF NOT EXISTS sh.times_a(
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
day_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
day_number_in_week SMALLINT ENCODE ZSTD NOT NULL,
day_number_in_month SMALLINT ENCODE ZSTD NOT NULL,
calendar_week_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_week_number SMALLINT ENCODE ZSTD NOT NULL,
week_ending_day TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
week_ending_day_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
calendar_month_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_month_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
calendar_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
fiscal_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
fiscal_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
calendar_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
calendar_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
fiscal_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_year SMALLINT ENCODE ZSTD NOT NULL,
calendar_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_year SMALLINT ENCODE ZSTD NOT NULL,
fiscal_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL
)
DISTSTYLE all
SORTKEY
(
time_id
);
/*key分配的维度表*/
CREATE TABLE IF NOT EXISTS sh.customers_k(
cust_id NUMERIC(38,18) NOT NULL,
cust_first_name CHARACTER VARYING(20) ENCODE ZSTD NOT NULL,
cust_last_name CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_gender CHARACTER VARYING(1) NOT NULL,
cust_year_of_birth SMALLINT NOT NULL,
cust_marital_status CHARACTER VARYING(20),
cust_street_address CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_postal_code CHARACTER VARYING(10) ENCODE ZSTD NOT NULL,
cust_city CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
cust_city_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_state_province CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_state_province_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
country_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_main_phone_number CHARACTER VARYING(25) ENCODE ZSTD NOT NULL,
cust_income_level CHARACTER VARYING(30) ENCODE ZSTD,
cust_credit_limit NUMERIC(38,18) ENCODE ZSTD,
cust_email CHARACTER VARYING(30) ENCODE ZSTD,
cust_total CHARACTER VARYING(14) ENCODE ZSTD NOT NULL,
cust_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_src_id NUMERIC(38,18) ENCODE ZSTD,
cust_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE KEY
DISTKEY
(
cust_id
)
SORTKEY
(
cust_id,
cust_gender,
cust_marital_status,
cust_year_of_birth
);
CREATE TABLE IF NOT EXISTS sh.products_k(
prod_id INTEGER NOT NULL,
prod_name CHARACTER VARYING(50) ENCODE ZSTD NOT NULL,
prod_desc CHARACTER VARYING(4000) ENCODE ZSTD NOT NULL,
prod_subcategory CHARACTER VARYING(50) NOT NULL,
prod_subcategory_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_subcategory_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_category CHARACTER VARYING(50) NOT NULL,
prod_category_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_category_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_weight_class SMALLINT ENCODE ZSTD NOT NULL,
prod_unit_of_measure CHARACTER VARYING(20) ENCODE ZSTD,
prod_pack_size CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
supplier_id INTEGER ENCODE ZSTD NOT NULL,
prod_status CHARACTER VARYING(20) NOT NULL,
prod_list_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_min_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_total CHARACTER VARYING(13) ENCODE ZSTD NOT NULL,
prod_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_src_id NUMERIC(38,18) ENCODE ZSTD,
prod_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE KEY
DISTKEY
(
prod_id
)
SORTKEY
(
prod_id,
prod_category,
prod_status,
prod_subcategory
);
CREATE TABLE IF NOT EXISTS sh.times_k(
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
day_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
day_number_in_week SMALLINT ENCODE ZSTD NOT NULL,
day_number_in_month SMALLINT ENCODE ZSTD NOT NULL,
calendar_week_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_week_number SMALLINT ENCODE ZSTD NOT NULL,
week_ending_day TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
week_ending_day_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
calendar_month_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_month_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
calendar_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
fiscal_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
fiscal_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
calendar_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
calendar_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
fiscal_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_year SMALLINT ENCODE ZSTD NOT NULL,
calendar_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_year SMALLINT ENCODE ZSTD NOT NULL,
fiscal_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL
)
DISTSTYLE KEY
DISTKEY
(
time_id
)
SORTKEY
(
time_id
);
/*even分配的维度表*/
CREATE TABLE IF NOT EXISTS sh.customers_e(
cust_id NUMERIC(38,18) NOT NULL,
cust_first_name CHARACTER VARYING(20) ENCODE ZSTD NOT NULL,
cust_last_name CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_gender CHARACTER VARYING(1) NOT NULL,
cust_year_of_birth SMALLINT NOT NULL,
cust_marital_status CHARACTER VARYING(20),
cust_street_address CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_postal_code CHARACTER VARYING(10) ENCODE ZSTD NOT NULL,
cust_city CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
cust_city_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_state_province CHARACTER VARYING(40) ENCODE ZSTD NOT NULL,
cust_state_province_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
country_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_main_phone_number CHARACTER VARYING(25) ENCODE ZSTD NOT NULL,
cust_income_level CHARACTER VARYING(30) ENCODE ZSTD,
cust_credit_limit NUMERIC(38,18) ENCODE ZSTD,
cust_email CHARACTER VARYING(30) ENCODE ZSTD,
cust_total CHARACTER VARYING(14) ENCODE ZSTD NOT NULL,
cust_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
cust_src_id NUMERIC(38,18) ENCODE ZSTD,
cust_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
cust_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE even
SORTKEY
(
cust_id,
cust_gender,
cust_marital_status,
cust_year_of_birth
);
CREATE TABLE IF NOT EXISTS sh.products_e(
prod_id INTEGER NOT NULL,
prod_name CHARACTER VARYING(50) ENCODE ZSTD NOT NULL,
prod_desc CHARACTER VARYING(4000) ENCODE ZSTD NOT NULL,
prod_subcategory CHARACTER VARYING(50) NOT NULL,
prod_subcategory_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_subcategory_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_category CHARACTER VARYING(50) NOT NULL,
prod_category_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_category_desc CHARACTER VARYING(2000) ENCODE ZSTD NOT NULL,
prod_weight_class SMALLINT ENCODE ZSTD NOT NULL,
prod_unit_of_measure CHARACTER VARYING(20) ENCODE ZSTD,
prod_pack_size CHARACTER VARYING(30) ENCODE ZSTD NOT NULL,
supplier_id INTEGER ENCODE ZSTD NOT NULL,
prod_status CHARACTER VARYING(20) NOT NULL,
prod_list_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_min_price NUMERIC(8,2) ENCODE ZSTD NOT NULL,
prod_total CHARACTER VARYING(13) ENCODE ZSTD NOT NULL,
prod_total_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
prod_src_id NUMERIC(38,18) ENCODE ZSTD,
prod_eff_from TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_eff_to TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD,
prod_valid CHARACTER VARYING(1) ENCODE ZSTD
)
DISTSTYLE even
SORTKEY
(
prod_id,
prod_category,
prod_status,
prod_subcategory
);
CREATE TABLE IF NOT EXISTS sh.times_e(
time_id TIMESTAMP WITHOUT TIME ZONE NOT NULL,
day_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
day_number_in_week SMALLINT ENCODE ZSTD NOT NULL,
day_number_in_month SMALLINT ENCODE ZSTD NOT NULL,
calendar_week_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_week_number SMALLINT ENCODE ZSTD NOT NULL,
week_ending_day TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
week_ending_day_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
calendar_month_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_month_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
calendar_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_month_desc CHARACTER VARYING(8) ENCODE ZSTD NOT NULL,
fiscal_month_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_month NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_month TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
fiscal_month_name CHARACTER VARYING(9) ENCODE ZSTD NOT NULL,
calendar_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
calendar_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_quarter_desc CHARACTER VARYING(7) ENCODE ZSTD NOT NULL,
fiscal_quarter_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_quarter NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_quarter TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
calendar_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
fiscal_quarter_number SMALLINT ENCODE ZSTD NOT NULL,
calendar_year SMALLINT ENCODE ZSTD NOT NULL,
calendar_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
fiscal_year SMALLINT ENCODE ZSTD NOT NULL,
fiscal_year_id NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_cal_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
days_in_fis_year NUMERIC(38,18) ENCODE ZSTD NOT NULL,
end_of_cal_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL,
end_of_fis_year TIMESTAMP WITHOUT TIME ZONE ENCODE ZSTD NOT NULL
)
DISTSTYLE even
SORTKEY
(
time_id
);
测试查询语句
/* 1 事实表key分配+交错排序键,维度表全key分配 */
explain select b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_k a,sh.times_k b,sh.customers_k c,sh.products_k e
where
a.time_id=b.time_id
and a.prod_id=e.prod_id
and a.cust_id=c.cust_id
group by b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 2 事实表key分配+复合排序键,维度表全key分配 */
explain select b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_c a,sh.times_k b,sh.customers_k c,sh.products_k e
where
a.time_id=b.time_id
and a.prod_id=e.prod_id
and a.cust_id=c.cust_id
group by b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 3 事实表even分配,维度表全key分配 */
explain select b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_e a,sh.times_k b,sh.customers_k c,sh.products_k e
where
a.time_id>=to_timestamp('20010101','yyyymmdd') and a.time_id<=to_timestamp('20011231','yyyymmdd')
and a.time_id=b.time_id
and a.prod_id=e.prod_id
and a.cust_id=c.cust_id
group by b.calendar_quarter_desc,e.prod_name,e.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 4 事实表key分配+交错排序键,维度表times key分配且与事实表键值相同,其他维度表all分配 */
explain select to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_k a,sh.products_a b,sh.customers_a c,sh.times_k e
where
a.time_id=e.time_id
and a.prod_id=b.prod_id
and a.cust_id=c.cust_id
group by to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 5 事实表key分配+复合排序键,维度表times key分配且与事实表键值相同,其他维度表all分配 注意merge join cost最小*/
explain select to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_c a,sh.products_a b,sh.customers_a c,sh.countries_a d,sh.times_k e
where
a.time_id>=to_timestamp('20010101','yyyymmdd') and a.time_id<=to_timestamp('20011231','yyyymmdd')
and a.time_id=e.time_id
and a.prod_id=b.prod_id
and a.cust_id=c.cust_id
group by to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 6 事实表even分配,维度表全all分配 */
explain select to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_e a,sh.products_a b,sh.customers_a c,sh.times_a e
where
a.time_id=e.time_id
and a.prod_id=b.prod_id
and a.cust_id=c.cust_id
group by to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 7 事实表even分配,维度表全even分配 */
explain select to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_e a,sh.products_e b,sh.customers_e c,sh.times_e e
where
a.time_id=e.time_id
and a.prod_id=b.prod_id
and a.cust_id=c.cust_id
group by to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
/* 8 事实表even分配,维度表全key分配 */
explain select to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status,sum(a.amount_sold) sale_cnt
from sh.sales_e a,sh.products_k b,sh.customers_k c,sh.times_k e
where
a.time_id=e.time_id
and a.prod_id=b.prod_id
and a.cust_id=c.cust_id
group by to_char(a.time_id,'yyyymm'),b.prod_name,b.prod_list_price,c.cust_credit_limit,c.cust_marital_status limit 80;
结束语
Amazon Redshift的表设计是获取良好性能的基础,要想做出正确的设计一方面需要读者了解Amazon Redshift的运作原理和表设计最佳实践,另一方面更需要读者对自身业务的深入理解,有时候表设计不仅仅是技术,甚至是一种艺术。总之,正如俗语所说“善始方能善终”,希望读者在阅读本文后,在使用Amazon Redshift之前能多一份思考,多一分准备,能够最大限度地发挥Amazon Redshift的潜力,助力我们的业务成长。
参考文档
《Amazon Redshift数据库开发人员指南》
本篇作者