亚马逊AWS官方博客
另辟蹊径: 在云端使用SQL语言实现数据转化,测试和文档维护
前言
这是系列文章的第一篇,在这篇文章中主要介绍ELT的模式,开源工具DBT,以及DBT的简要用法;在第二篇文章中,将以此为基础,使用Amazon Web Services CDK构建一个Data OPS方案。
引子
全球化经济放缓带来的需求乏力、竞争过度、产能过剩等问题日益突出,传统企业面临着比以往更加激烈的市场竞争,迫切需要探寻新的增长机会和发展模式。企业如何利用数字化技术,实施以创新为核心的数字化转型,就变得尤为重要。
作为一名解决方案架构师,按我的理解,从技术角度去看,数字化转型的本质就是利用大数据的技术来提升企业的运营效率。
在当前这个数据量,数据来源,数据类型爆炸的时代,企业做数据分析也面临着新的挑战, 如何能够更高效的去做数据准备,从而缩短整个数据分析的周期,让数据更有实效性,增加数据的价值,就变得尤为重要。数据量巨大,数据来源众多,数据类型多样也对数据分析人员提出了挑战,有客户讲,在“数据准备”这个环节所占用的时间,很多情况下会超过整个项目时间的80%,这其中又包含了 开发,测试 和 文档维护等多个环节。
有没有什么办法可以提高数据准备的效率呢?
本篇文章将为读者介绍一新的开源工具: DBT(Data Build Tool), 并详细演示,如何使用DBT,基于Amazon Redshift 使用SQL语言来做数据转换,测试用例编写 和文档维护。
在开始介绍DBT之前,我们先来回顾下数据准备的两个常见模式: ELT 和 ETL.
数据准备模式: ETL 还是 ELT, 如何选择?
在 ETL and ELT design patterns for lake house architecture using Amazon Redshift 中,详细分析对比了ETL 和 ELT两种模式。在本篇文章中,不再详细去分析对比,只是选取其中关键部分加上笔者理解,目的是帮助读者能够更全面的理解本文中基于DBT做数据准备的方案。
ETL(Extract –> Transform –> Load) 和 ELT(Extract –> Load –> Transform) 的概要对比图如下:

图片出自Amazon Web Services Blog: ETL and ELT design patterns for lake house architecture using Amazon Redshift
ETL 和 ELT两种模式的区别在于,先做数据转换(Transform) 还是 先做数据加载(Load)。
在ETL的模式中,先做数据转换,这个过程是在数据仓库之外完成的,做数据转换的工具可以选择 Amazon EMR 或者 Glue。
在ELT的模式中,先把数据加载到数据仓库中,然后再做数据转换。
在亚马逊云科技上,就可以选择Amazon Redshift,充分利用Redshift MPP的架构优势来做数据转换。同时也得益于Redshift Spectrum的功能,可以简单的使用CTAS(Create Table as )命令来做数据转换, 整个流程图如下:

图片出自Amazon Web Services Blog: ETL and ELT design patterns for lake house architecture using Amazon Redshift
可以看出,使用ELT模式,技术栈也相对简单,开发人员只需要使用SQL就可以完成数据转换。而在ETL的模式中,做数据转换,开发人员则需要掌握Spark等技能,使用的技术语言则是Scala或者Python。所以,如果读者已经非常熟悉SQL,而面对学习Scala/Python又有些不知所措时,ELT模式会是一个好的选择。
那么在选择ELT的模式之后,如何高效开发,如何进行测试,如何维护项目文档?这些问题可以尝试下DBT,接下来将带读者认识DBT,学会如何使用DBT。
DBT 简介
DBT(data build tool) 是一个开源的工具,利用DBT,数据分析人员可以使用SQL来做数据转换,DBT会负责将命令转化为表或者视图。并且DBT支持多种数仓产品(Redshift, Snowflake, BigQuery, Presto 等),DBT会根据用户的配置,自动将用户编写的代码转换为特定数据仓库支持的命令。因此,DBT广受欢迎,目前以后850+ 企业在他们的生产环境使用DBT做数据转换,其中包括Casper, Seatgeek, Wistia等知名公司。

图片来自于 DBT Blog: what exactly is dbt
DBT 可以大幅度的提高数据分析人员的效率:
- DBT 集成了 package manager的功能。
数据分析人员可以把常用的包做成Package,发布到私有或者公开的仓库,方便重用;
- DBT支持开发人员定义测试用例,可以方便的对编写的代码进行测试,保障代码质量;
- DBT支持根据开发人员编写代码中的元数据生成对应文档(类似于数据分析领域的Swagger), 降低文档维护工作量。
使用DBT在Redshift中做数据转换(Data Transformation)
本文接下来为读者详细演示,如何配置使用DBT在Redshift中做数据转换。
演示所使用的示例代码,读者可以通过https://github.com/readybuilderone/elt-with-dbt-demo 下载运行,示例代码仅供参考。
环境准备
创建演示用的Redshift集群,为了演示方便,在本文中打开了Redshift集群的公网访问权限。
笔者封装成了Amazon Web Services CDK的Project,可以使用如下方法创建 (不习惯Amazon Web Services CDK的读者,可以参考Redshift官方文档手工创建集群):
Amazon Web Services CDK 开发环境搭建
开发Amazon Web Services CDK需要先安装Amazon Web Services CDK CLI,利用 Amazon Web Services CDK CLI可以生成对应的CDK 的Project。
Amazon Web Services CDK CLI的安装依赖于Node.js, 所以在您的开发环境需要先安装node.js。node.js 的安装可参看官方教程: https://nodejs.org/en/download/package-manager/。
安装好 node.js 之后,可以直接使用 如下命令安装 Amazon Web Services CDK CLI:
npm install -g aws-cdk #安装cdk cli
cdk --version #查看版本
安装 CDK CLI后,需要通过aws configure 命令配置开发环境的用户权限,详情参考: https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html
搭建测试Redshift集群
配置好之后,在命令行使用如下命令,创建Redshift集群:
git clone https://github.com/readybuilderone/elt-with-dbt-demo.git
cd elt-with-dbt-demo
npx projen
npx cdk bootstrap
npx cdk deploy --profile <YOUR-PROFILE>
注意,请将上述代码中的 替换为您配置的Amazon Web Services Credential的Profile。
执行完成之后,会创建一具有公网访问权限的S3 Bucket 和 一个Redshift集群。
创建成功后,会在命令行打印出:
- 用于存放需要加载到Redshift数据的S3的BucketName;
- Redshift的Host地址;
- Redshift的Execute Role的ARN

Redshift的链接信息如下
- Redshift DB Name: redshift-db
- Redshift User: redshift-user
- Redshift Port: 5439
- Redshift Host: 参考CDK运行截图
上述CDK 代码会在Secrets Manager中创建 名为”redshift-credentials” 的secrets,您可以通过Retrieve secret value 查看。
可以使用如下命令,测试Redshift连接 (参考: https://docs.aws.amazon.com/redshift/latest/mgmt/connecting-from-psql.html):
psql -h <endpoint> -U <userid> -d <databasename> -p <port>
 安装DBT
安装DBT
DBT 的安装非常简单并且有多种选择, 参考: https://docs.getdbt.com/dbt-cli/installation
安装完成之后,运行如下命令检查DBT安装是否成功:
dbt --version
#正确安装应该会输出如下内容
installed version: 0.20.2
latest version: 0.20.2
Up to date!
Plugins:
- bigquery: 0.20.2
- snowflake: 0.20.2
- redshift: 0.20.2
- postgres: 0.20.2
新建DBT Project
DBT安装好之后,使用如下命令创建 Project:
dbt init dbt-demo
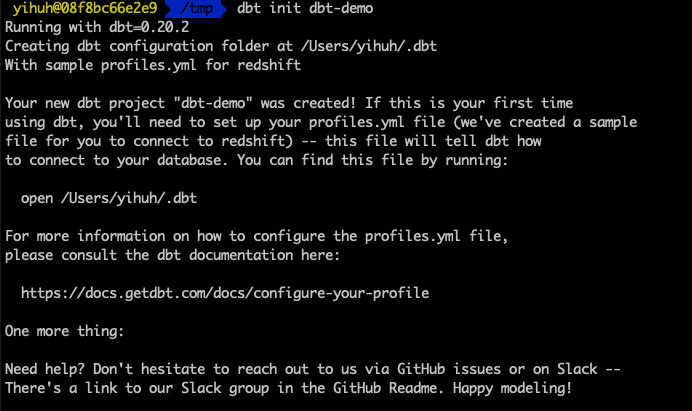
这个命令将会创建 profiles.yml 和 一个 dbt-demo 的文件夹, profiles.yml 存放RedShift的Credentials。dbt-demo 文件夹为DBT的项目文件夹。
根据创建的Redshift的值,修改profiles.yml 中 default –> outputs –> dev 的配置项:

之后,在dbt-demo 中执行如下命令,验证dbt可以连接到新建的Redshift集群:
dbt debug

数据准备
测试数据说明
本文中使用Jaffle Shop Sample 数据来做演示。
Jaffle Shop 中共有customer, order, payments 三张表,schema如下:

加载测试数据到Redshift
Jaffle Shop 的原始数据存在sample_db/jaffle_shop/ 文件夹下,使用如下命令将CSV文件同步到S3:
cd ./sample_db/jaffle_shop
aws s3 sync . s3://<YOUR-BUCKET>/jaffle_shop/ --profile <YOUR-PROFILE>
注意: 读者请替换 和 为自己环境中的值;
数据同步到S3之后,读者可以选择使用自己喜欢的IDE或者在Amazon Web Services控制台中,使用如下语句创建Table:

使用如下语句把数据从s3加载到redshift:
注意:需要替换上述代码中的 , , , 其中, 参考创建Redshift集群时CDK的Output。
到此,我们已经准备好了DBT的开发环境,也准备好了Redshift中的数据,接下来为读者们演示如何使用DBT来做Data Transform,Test 和Generate Doc。
使用DBT做Data Transform, Test 和 Generate Doc:
使用DBT做Data Transform
如上文所讲,在ELT的模式中,使用create table as 的方法来做Data Transform。
在DBT的Project中,先定义对应的model,再利用dbt run命令可以方便的来实现。
在数据准备阶段,创建了raw_customers, raw_orders, raw_payments三张表,现在模拟数仓分层,生成对应的stg 数据, 在DBT中操作如下:
创建对应的model, 内容如下:
创建完成之后,文档的目录应如下图所示:

/models/example文件夹为DBT生成的示例model,这里可忽略。
允许 dbt run命令,执行对应的数据转换:
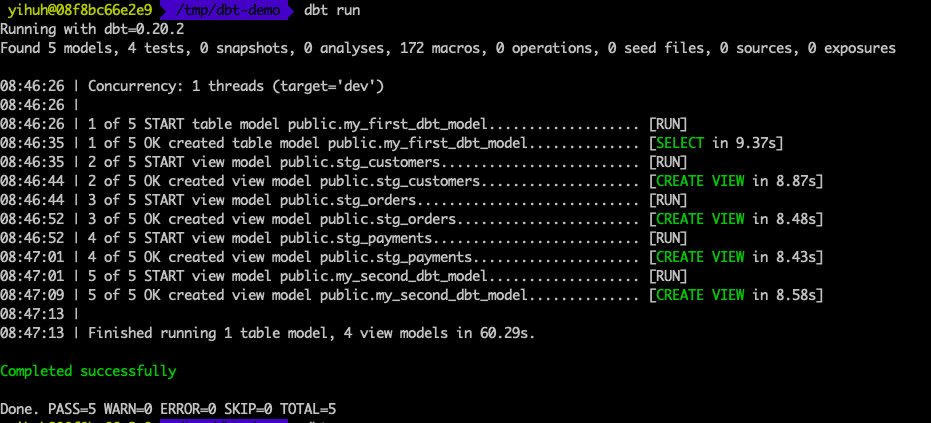
执行完成之后,在Redshift进行验证:

可以看到,对应的stg tables 都已创建完成,操作成功。
使用DBT做Test
在做数据准备的时候,测试是提高效率,保证数据质量,降低Bug的有效手段。
在上述做stg的时候,如果对于数据有如下要求:
- customer_id, order_id, payment_id 要求唯一切不能为null
- order的status只能为’placed’, ‘shipped’, ‘completed’, ‘return_pending’, ‘returned’ 之一;
- payment method 只可以为 ‘credit_card’, ‘coupon’, ‘bank_transfer’, ‘gift_card’ 之一;
这样的条件该如何满足呢?
在DBT中,可以利用yml文件定义规则,然后使用dbt run来进行检查。
具体操作如下:
创建schema.yml 文件,放在 models/stg 文件夹下:

在命令行 来进行测试:
dbt test --models stg_customers, stg_orders, stg_payments

测试成功。
使用DBT Generate Doc
文档维护也是数据分析项目中极其重要又极其耗时的工作。使用DBT,可以利用yml 对数据格式进行描述,并自动生成文档:
更新 schema.yml, 添加 description 字段:
在命令行,使用命令生成文档,查看文档
dbt docs generate
dbt docs serve
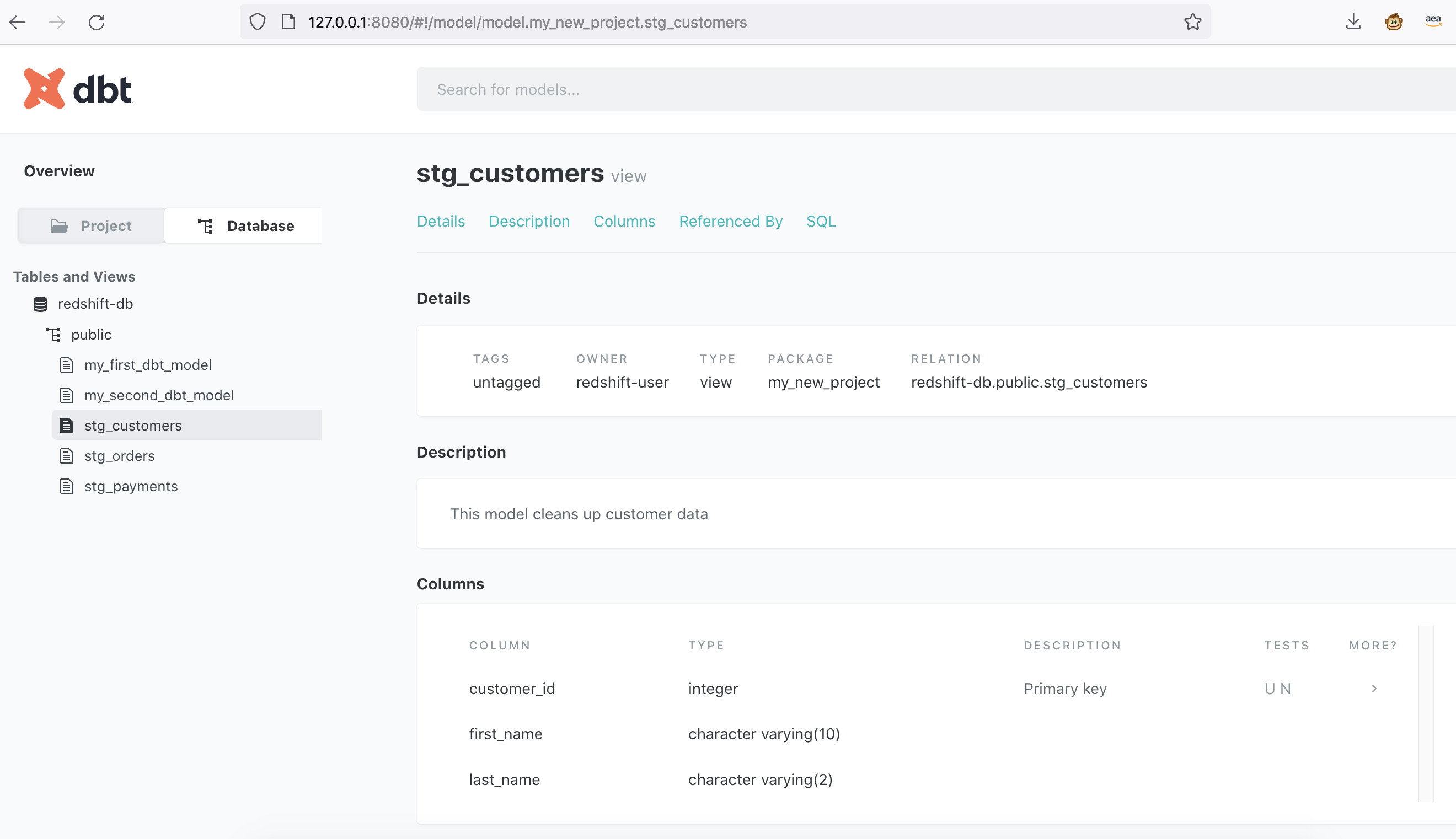
文档生成成功。
总结
在本文中,介绍了数据准备中的ELT的模式 和 DBT,基于这个方案,可以让数据分析人员使用SQL来做数据转换,测试和维护文档。这个是系列文档的第一篇,读者将在第二篇文章中为读者演示如何使用Amazon Web Services CDK利用DBT来构建一个DataOPS的方案,希望对您有所帮助。
参考文档
- Medium:Data Engineering — ETL or ELT
- Amazon Web Services Blog: ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
- Amazon Web Services Blog: https://aws.amazon.com/blogs/big-data/etl-and-elt-design-patterns-for-lake-house-architecture-using-amazon-redshift-part-2/
- Towards Data Science Blog:A Data Warehouse Implementation on Amazon Web Services
- DBT Offical Doc