亚马逊AWS官方博客
AWS Glue 全托管 ETL 服务使用指南
作者:蒋华, AWS合作伙伴解决方案架构师

目 录
第1章 Glue概述
1.1 Glue介绍
1.2 Glue主要特征
1.3 Glue定价与计费
第2章 Glue入门
2.1 数据准备
2.2 在线演示
2.2.1 增加IAM Role
2.2.2 配置Data Catalog
第1章 Glue概述
1.1 Glue介绍
AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务,让客户能够轻松准备和加载数据进行分析。您只需在 AWS 管理控制台中单击几次,即可创建并运行 ETL 作业。您只需将 AWS Glue 指向存储在 AWS 上的数据,AWS Glue 便会发现您的数据,并将关联的元数据 (例如表定义和架构) 存储在 AWS Glue 数据目录中。存入目录后,您的数据可立即供 ETL 搜索、查询和使用。AWS Glue 可生成代码执行数据转换和数据加载流程。
AWS Glue 可生成可自定义、可重复使用且可移植的 Python 代码。ETL 作业准备就绪后,您便可以安排它在 AWS Glue 完全托管的横向扩展 Apache Spark 环境中运行。AWS Glue 可提供一个具有依赖关系解析、作业监控和警报功能的灵活计划程序。
AWS Glue 没有服务器,因此无需购买、设置或管理基础设施。它会自动预配置完成作业所需的环境,客户只需为运行 ETL 作业期间使用的计算资源付费。使用 AWS Glue,数据在几分钟内即可用于分析。
1.2 Glue主要特征
- 集成式数据目录
AWS Glue 数据目录是您所有数据资产的永久元数据存储,且无论它们位于何处都将如此。数据目录包含表定义、任务定义和其他控制信息,以帮助您管理 AWS Glue 环境。它会自动计算统计信息并注册分区,以便经济高效地针对您的数据进行查询。它还会维护一个全面的架构版本历史记录,以便您可以了解您的数据如何随着时间发生变化。
- 自动架构发现
AWS Glue 网络爬虫连接到您的源或目标数据存储,通过分类器的优先级列表来确定数据的架构,然后在 AWS Glue 数据目录中创建元数据。元数据存储在数据目录的表中,并在 ETL 任务的创建过程中使用。您可以按计划、按需运行网络爬虫,也可以基于事件触发它们,以确保您的元数据是最新的。
- 代码生成
AWS Glue 自动生成代码以提取、转换和加载您的数据。只需将 Glue 指向您的数据源和目标,Glue 就会创建 ETL 脚本来转换、合并和丰富您的数据。AWS Glue 使用 Python 生成代码,并针对 Apache Spark 2.1 环境进行编写。
- 开发人员终端节点
如果您选择通过交互方式开发 ETL 代码,Glue 将提供开发终端节点,以供您编辑、调试和测试其为您生成的代码。您可以使用自己喜爱的 IDE 或笔记本电脑。您可以编写自定义读取器、写入器或转换程序,并将它们作为自定义库导入到 ETL 任务中。您还可以与其他开发人员一起使用和共享我们的 GitHub 存储库中的代码。
- 灵活的任务调度程序
AWS Glue 任务可以按计划、按需或基于事件进行调用。您可以并行启动多个任务,也可以跨任务指定依赖关系以构建复杂的 ETL 管道。Glue 将处理所有的任务间依赖关系、过滤不良数据并且在任务失败时进行重试。所有日志和通知都将推送到 Amazon CloudWatch,以便您可以从中心服务监控和获取警报。
1.3 Glue定价与计费
除了 AWS Glue 数据目录免费套餐,您需要针对 AWS Glue 数据目录中的元数据存储和访问支付简单月度费用。此外,您还需要针对 ETL 任务和网络爬虫的运行按小时费率付费 (按秒计),每次最少 10 分钟。如果您选择使用开发终端节点以交互式方法开发您的 ETL 代码,那么您需要针对预置开发终端节点的时间按小时费率付费 (按秒计),最少 10 分钟。有关更多详细信息,请参阅我们的定价页面。
第2章 Glue入门
我们将通过一个简单的Demo,来描述Glue实现从S3桶扫描csv文件,并转换成Parquet格式的ETL过程,并通过Athena来查询,突出其易用性。
2.1 数据准备
我们先生成三个csv文件,内容如下:
创建S3桶,名有www.jianghua.com ,在其下面建立如下三个文件夹
csv ### 存放csv文件,并将上面的三个csv文件上传至该目录
tmp ### 存放临时文件
csv2parquet ### 存放转换后的parquet格式文件
2.2 在线演示
以下过程包括IAM Role、数据目录、Crawlers及Job
2.2.1 增加IAM Role
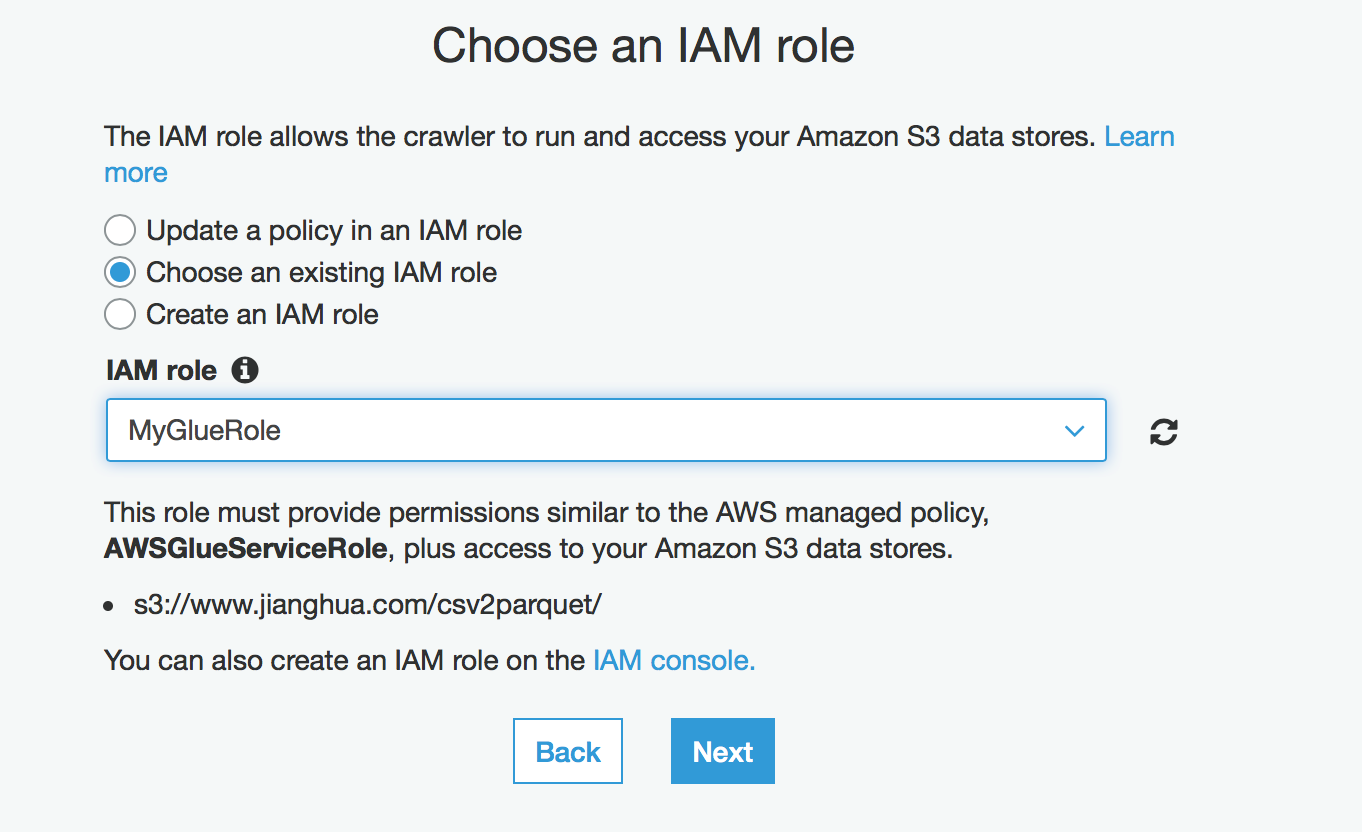
由于Glue是全托管的,该ETL过程会访问S3,请新建一个名为MyGlurRole,包括如下权限,记得S3 Full与Glue所有的权限:
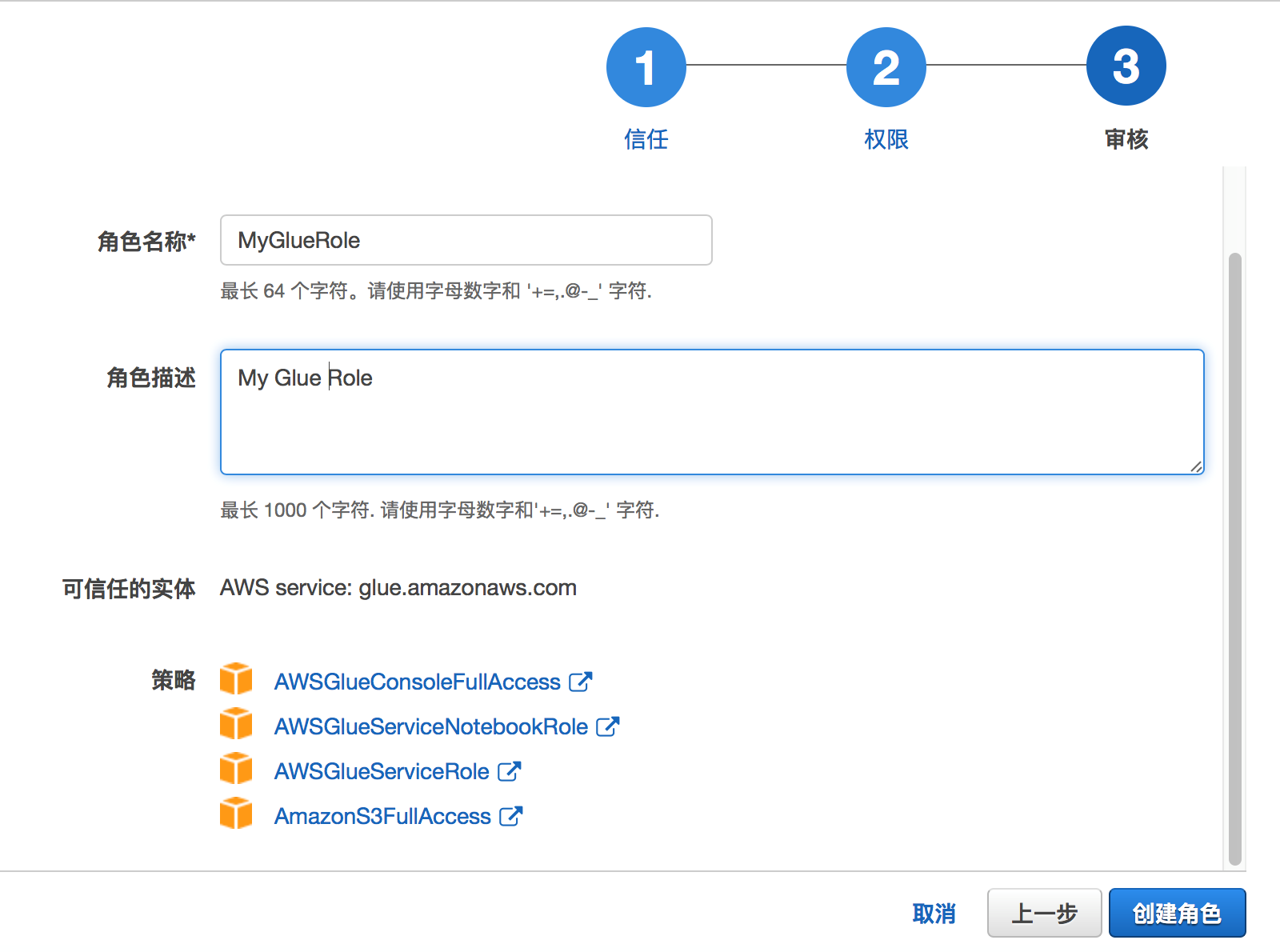
2.2.2 配置Data Catalog
如果有默认的数据库可以先删除,再新新建自己的数据,这里没有具体数据,只有元数据,即数据结构,描述数据的数据。
2.2.2.1 创建数据库
新建一个名为mygluedb的数据库


2.2.2.2 创建表
通过Add tables using a crawler建表

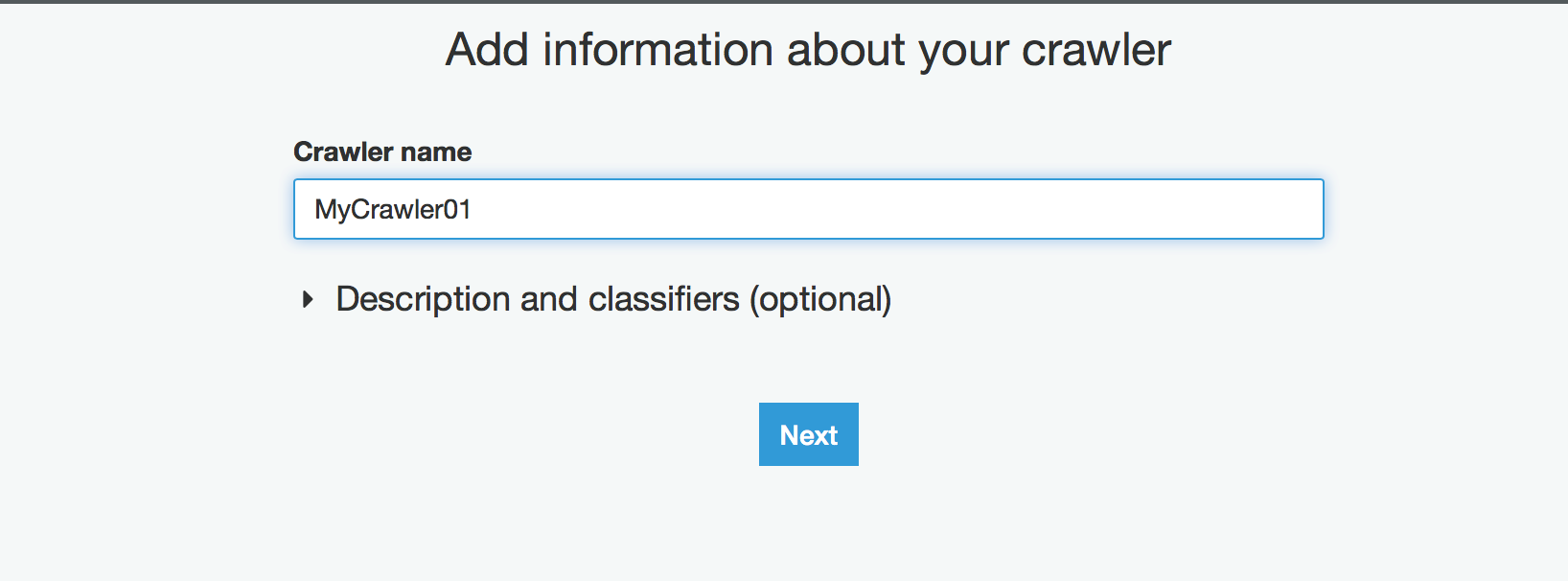
把源直接指向S3桶下面的csv目录


选择上面建的Role

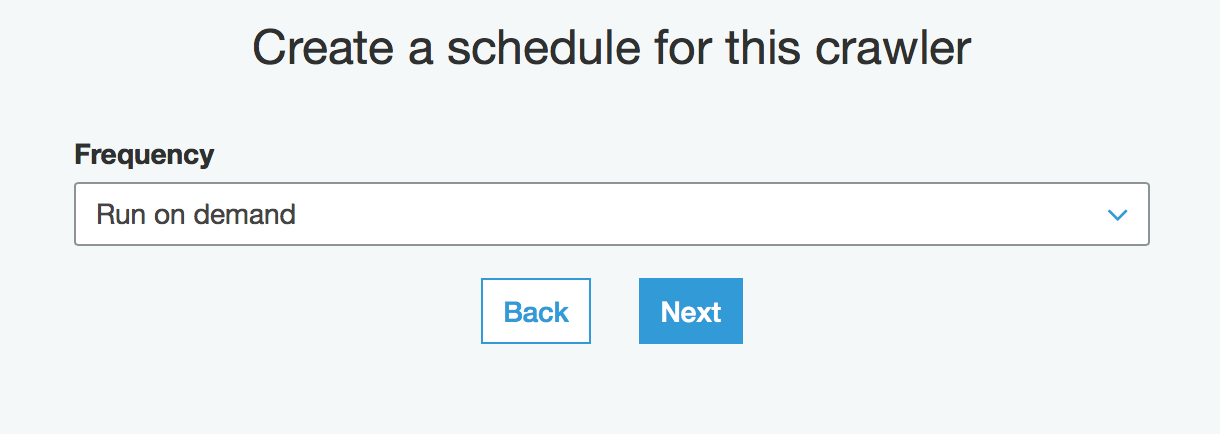
选择mygluedb后Next -> Finish

会看建立了一个Crawler,选中,再运行Run crawler,等待一小会,如下所示:


点击Table会看表已经生成,其实只是表结构,并不会把数据拉过来。MyCrawler01会根据csv目录下的文件内容情况自动生成表,有可能与文件个数相等或不同。

2.2.2.3 创建Job
再点击Job,新建Job,输入名字,选择Role,选择tmp临时目录,Next
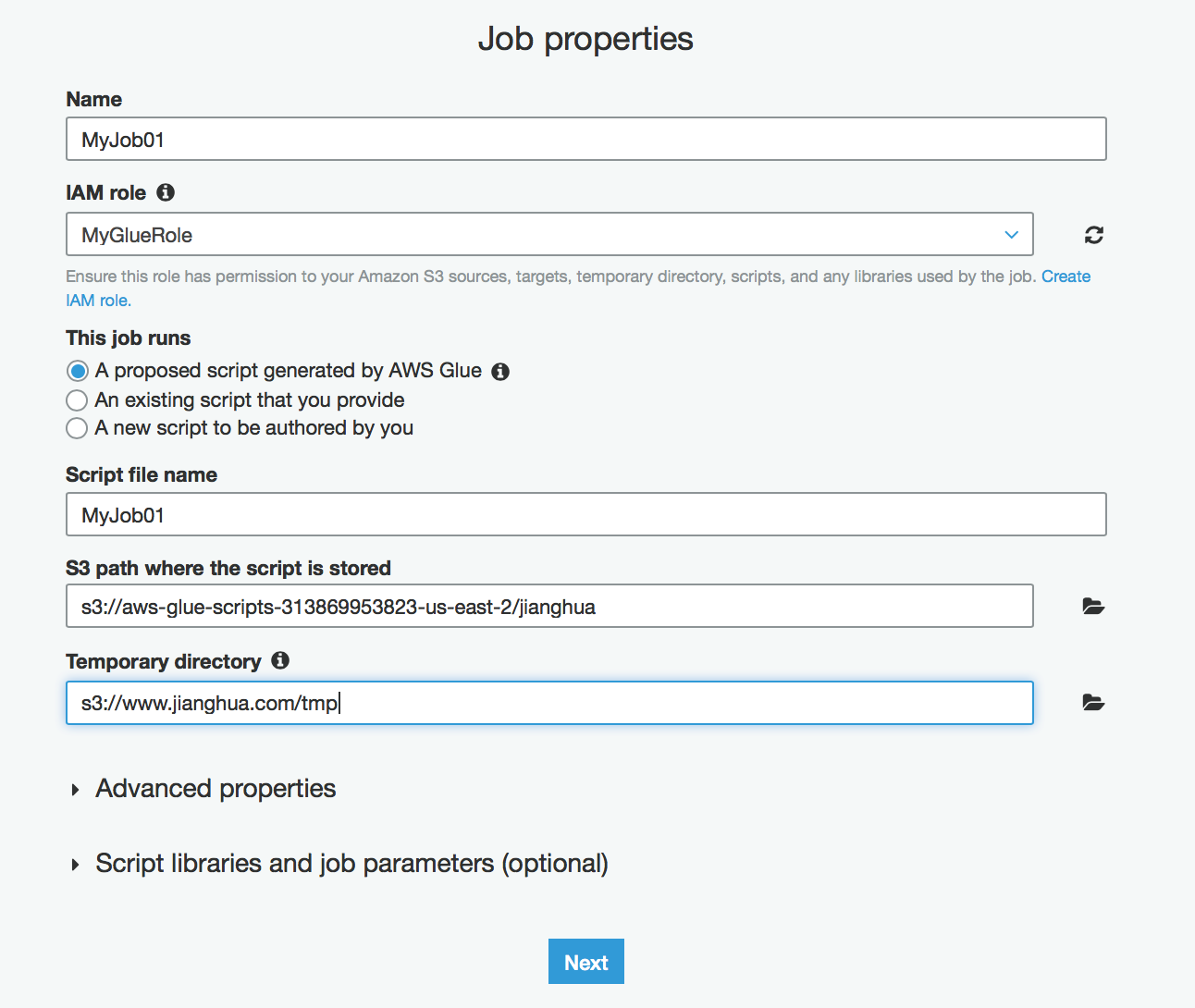
选择数据源,Next

选择数据目录,Create新表以及S3桶的路径,Next

选择源与目标的字段mapping,Next –> Finish

点击Save,再点击Run Job,开始运行

此处需要待一段时间,预计5分钟后会有logs输出



2.2.2.4 数据验证
参考上面建表的方法,通过Crawler新建一个表,去导入刚才Job生成的Parquet格式的元数据

选择S3桶里,存放Parquet文件名为csv2parquet的文件夹,Next
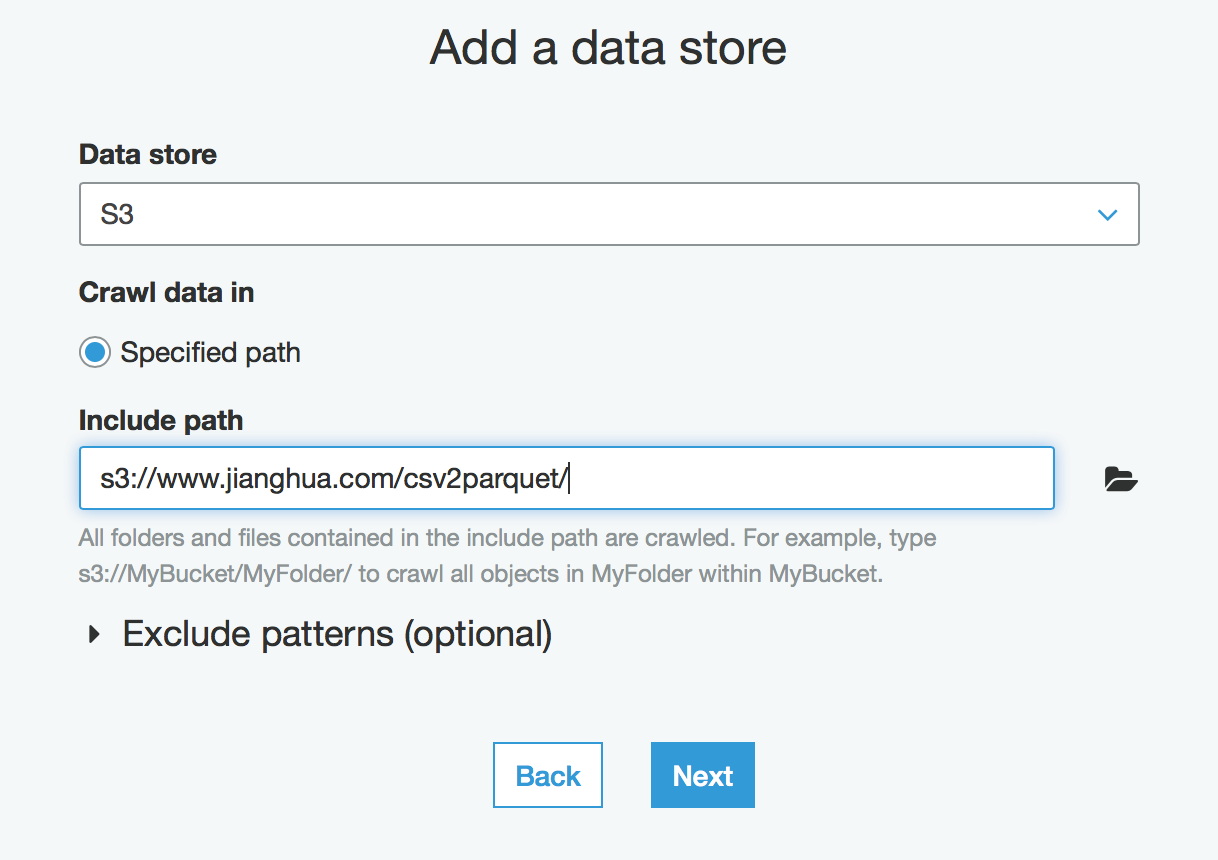
选择之前建立的数据库,其他可以默认, Next -> Finish

运行MyParquet01后,再去查看表。会自动生成一个名为csv2parquet的表

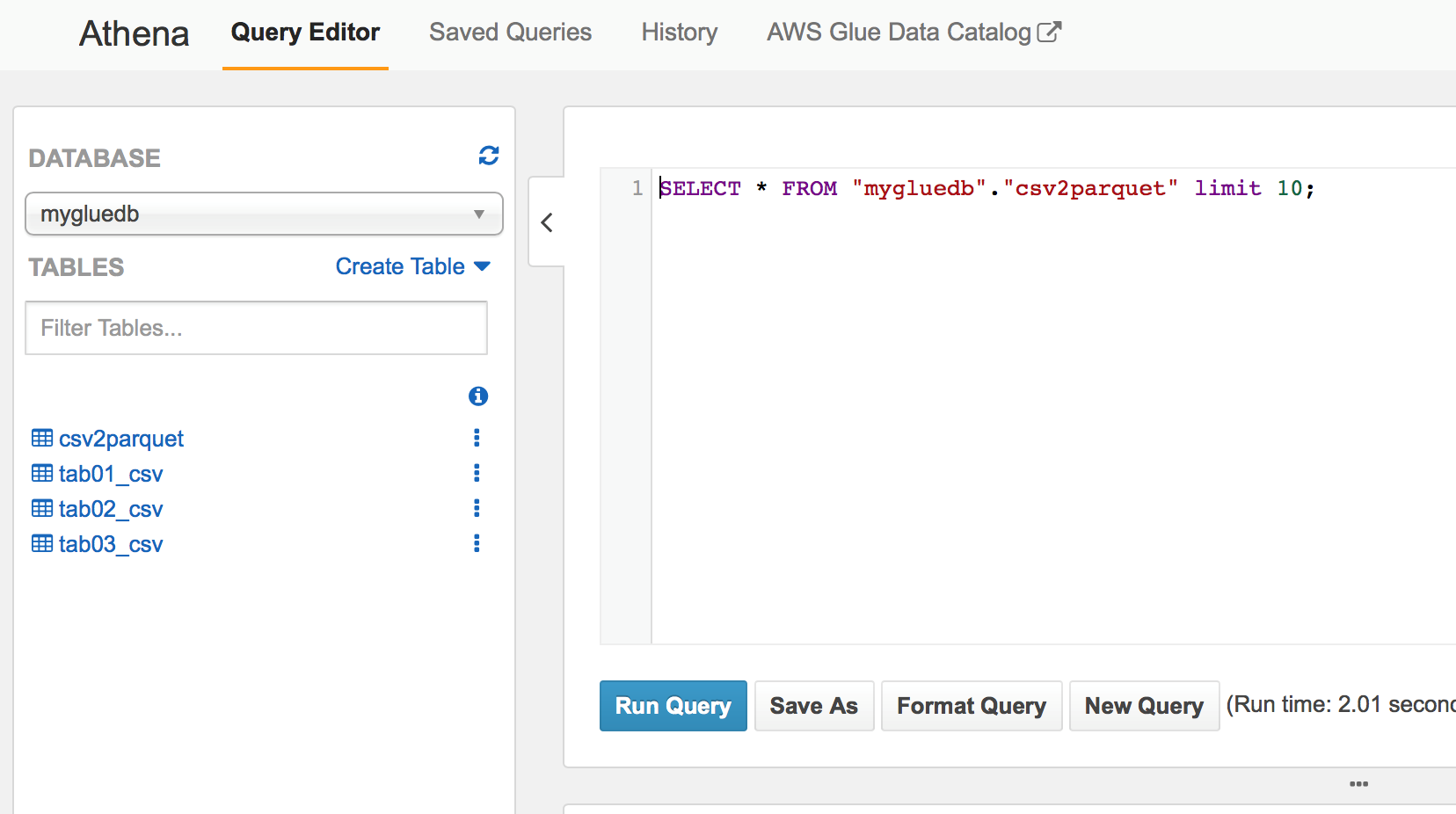
选中csv2parquet的表,再选择View data,再在Athena里面打开此表进行查询

Run Query,即可
作者介绍:

蒋华, AWS合作伙伴解决方案架构师,获得AWS解决方案架构师专业级认证,主要负责AWS(中国)技术类、SaaS合作伙伴的技术支持,基于AWS云服务方案的架构设计、咨询及应用迁移等工作,同时致力于AWS云服务在国内的应用及推广,并在关系型数据库服务、存储服务、分析服务、HA/DR及云端应用迁移方面有着丰富的设计和实战经验。加入AWS之前,曾在IBM(中国)工作12年,历任数据库售前工程师、UNIX服务器资深售前工程师及解决方案架构师,熟悉传统企业IT架构、私有云及混合云部署,在数据库、数据仓库、高可用容灾及企业应用架构等方面有多年实践经验。