亚马逊AWS官方博客
基于 Babelfish 的 T-SQL 代码开发最佳实践 Part 2 – 语法与调试以及 SQL 优化
本文是“基于 Babelfish 的 T-SQL 代码开发最佳实践”系列的第二篇,在上一篇中,我们介绍了基于 Babelfish 的 T-SQL 代码开发时,对于不同的对象属性及互操作性的相关指引和最佳实践。在这篇文章中,我们会对其他的一些开发要点和最佳实践进行介绍。
1. 语法与调试
在本系列的首篇中介绍了 Babelfish 的软件架构是使用 hooks 来处理 TDS 连接,关键之处在于它是在 PostgreSQL 上增加了一个 T-SQL 语法解析器来兼容 SQL Server 的行为。虽然到目前为止 Babelfish 的数据类型和语法兼容性越来越高,但还是存在一些不兼容的地方。本节将介绍 T-SQL 代码在 Babelfish 上开发时遇到的最常见的两类语法差异以及 T-SQL 代码的调试方法。
1)运算符
运算符是 T-SQL 代码中经常会使用到的,对于一些包含两个符号的比较运算符,比如 >=, <=,!= 等,SQL Server 允许在 SQL 语句中运算符的两个符号中间包含空格,而 Babelfish 则会遵照 PostgreSQL 的语法规则,不允许中间有空格。如下图所示,语句中的运算符之间即使有空格(包括换行),在 SQL Server 中也能正常执行。
 |
而在 Babelfish 中,运算符中间的空格会导致语句执行错误。
 |
另外,Babelfish 也不支持 SQL Server 中的 !< 和 !> 这两个比较运算符,可以使用等效的>=和<=。通过以上案例中的展示,我们建议审阅您的 T-SQL 代码是否有类似的使用方式,在迁移到 Babelfish 时,都需要做适当改写,以符合 Babelfish 的语法检查规则。
2)数据转换
T-SQL 代码中会调用一些数据库内置函数来进行操作,其中的一些函数可能涉及到多个值的比较或转换,如常用的 ISNULL 函数,其表达式为 ISNULL(check_expression,replacement_value),其中 check_expression 可以是任何类型,replacement_value 必须是可隐式转换为 check_expression 类型的类型。
来看下面的这样一条 SQL 语句:
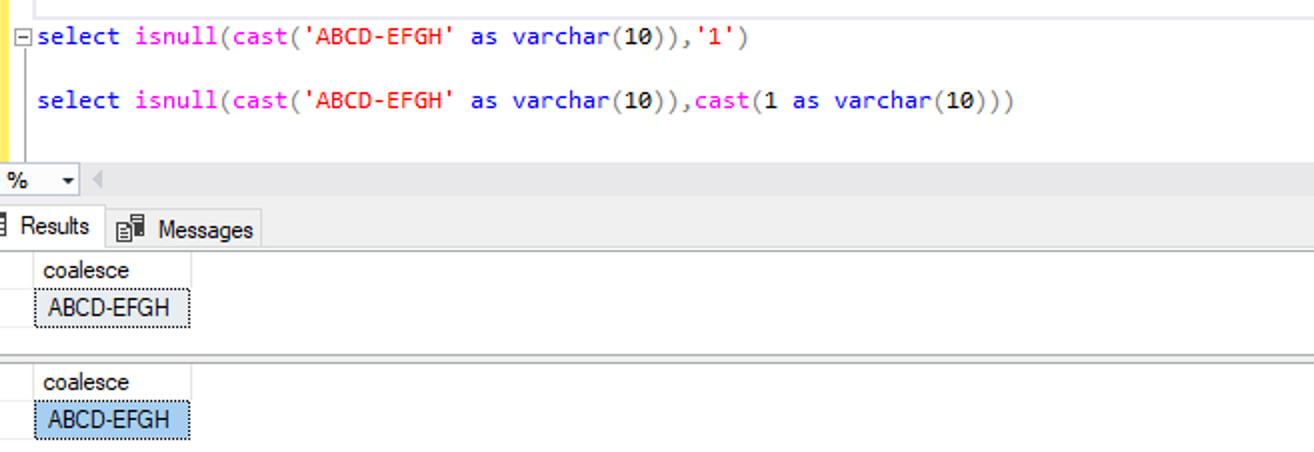
此语句在 SQL Server 中的处理流程为:将替换值的数字 1 隐式转换为字符 ‘1’ 以匹配检查条件的字符数据类型,从而能执行成功。但这条 SQL 语句在 Babelfish 中却执行失败。

如上图所示,语句执行时返回错误提示:整型数据类型输入语法错误。这是由于语句在 Babelfish 执行时没有将 isnull 函数的替换值隐式转换为同一数据类型。为此,我们可以通过以下任一方式来修改语句,使用显式的数据类型转换来确保在 Babelfish 中成功执行:
再看一个例子,是关于 cast 转换函数在两种环境中的执行差异。如下图所示:SQL Server 对于日期转换能支持仅输入 4 位数的年份值,默认会转换成该年份的首日零时,而 Babelfish 则不支持,需要补全年月日。

本节中的最后一个案例,也是一个转换函数 convert 的执行差异,下图中的执行结果显示在 Babelfish 中,convert 函数无法将 date/datetime 字段转换为 int/float 等数值字段。

了解数据转换在 Babelfish 和 SQL Server 中的差异后,您可以通过执行语句返回的错误判断问题的原因并做针对性的处理,我们建议您审阅 T-SQL 代码中使用到的此类函数,确保比较的数据类型一致。对于无法按照预期行为转换的 T-SQL 语句,请尝试使用逻辑改写方式处理。
3)T-SQL 代码调试
调试是任何软件开发过程中最重要但又很痛苦的部分之一,当遇到代码执行返回错误时,您必须逐步运行代码以查看引起错误的代码部分,这称为运行时调试。SQL Server Management Studio(SSMS)版本 17.9.1 和更早版本提供了 Transact-SQL 调试器,通过为 SQL 存储过程显示 SQL 调用堆栈、局部变量和参数,以交互方式调试存储过程。您也可以使用 SQL Server Data Tools(SSDT)for Visual Studio 来进行代码调试。
当前的 Babelfish 版本,对于一些常用工具的支持还不能做到百分之百的兼容。那么当需要对逻辑复杂或包含大量代码的存储过程或函数进行调试时,该使用什么方法呢?我们建议您可以在代码中增加 print()函数来添加断点信息,通过输出执行流程、参数和变量值来进行调试。
print()函数的使用方式为:PRINT msg_str | @local_variable | string_expr
下图展示的是一个利用游标来查询系统视图并转换索引名称的存储过程,为了理解程序中语句的执行顺序和变量获取情况,我们在代码中添加了 print()函数来显示执行步骤和输出参数变量值。
 |
在 SSMS 工具中执行此存储过程,选择“信息”页面,您可以清楚地看到程序的运行步骤和一些关键的输出变量。
 |
4)交互数据诊断
T-SQL 的开发和应用代码的开发是相辅相成的,许多应用层的操作会在应用代码中去调用 T-SQL 和后台数据库进行交互:比如变量和参数的输入,存储过程和函数的调用等。由于此类操作行为是通过 TDS 协议来传输交互数据,PostgreSQL 通常不会记录相关信息。当遇到应用与数据库之间的操作报错时,需要进行交互数据的诊断,了解前端应用向后台数据库发送的详细 T-SQL 语句,传入的具体变量值等。我们推荐通过调整 Babelfish 的参数,启用 DEBUG 模式记录 TDS 协议上的相关操作到 PostgreSQL 日志来查看。
具体启用方法可以使用 AWS CLI 命令行工具或通过 AWS 控制台来调整 Babelfish 参数。
- AWS CLI 命令
- AWS 控制台
在数据库集群的控制台中查找当前 Aurora PostgreSQL 集群使用的集群组参数,并调整以下的参数:
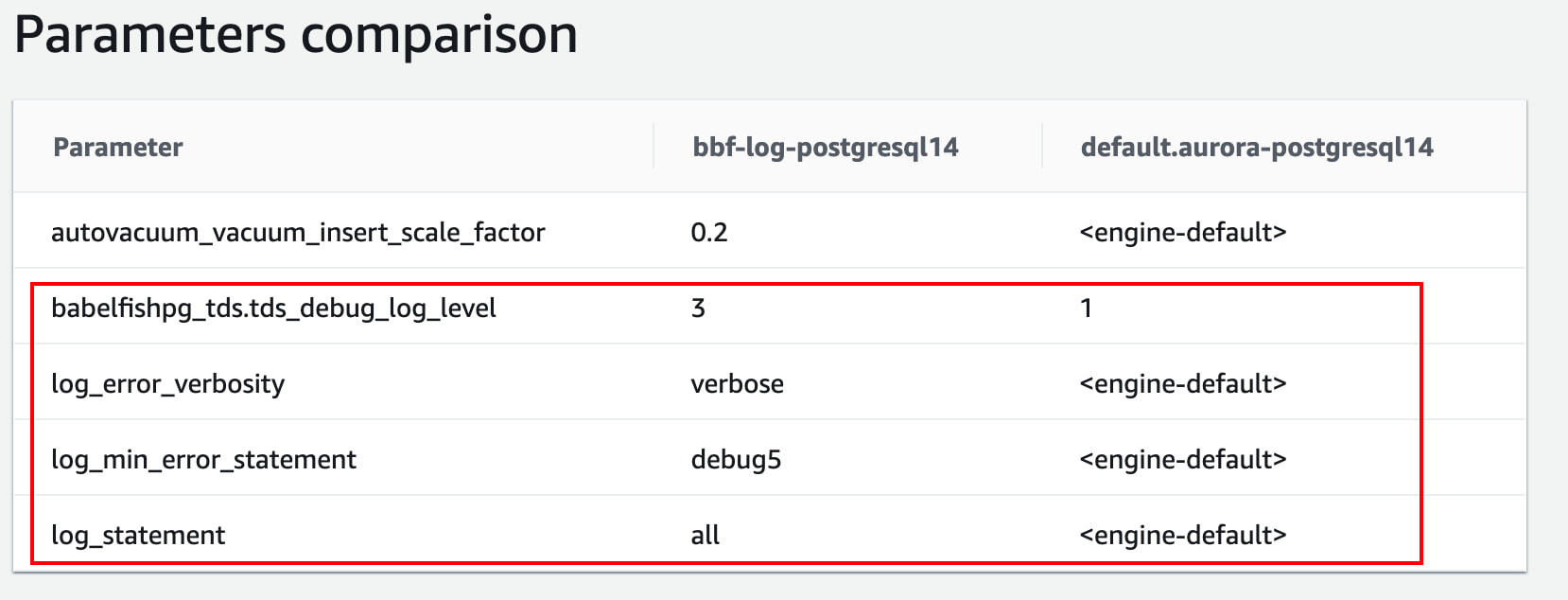 |
完成以上设置并重启生效后,您可以在控制台上找到 Aurora PostgreSQL 集群写实例上的“Logs & events”页面,选择并查看最新的 postgres.log 日志,从中寻找到前后端的数据交互信息。关于日志信息中可记录的 SQL 语句类型,您可以参考 PostgreSQL 使用手册。
2. SQL 优化
数据库性能优化的应用场景相当广泛,从软件层面上来说,包括架构优化、对象优化以及语句优化等。SQL 语句与业务联系紧密,确保 SQL 语句使用最佳的执行计划,并稳定运行,这是 T-SQL 代码开发的一个优先任务。
SQL Server 数据库提供了图形化和命令行的工具去查看 SQL 语句运行时的执行计划。当数据库的 SQL 执行出现性能问题时,最重要的操作之一是准确了解正在执行的工作负载以及如何驱动使用资源。为此,查看 SQL 实际执行计划是关键的诊断方法。另外,查询提示(Query Hints)可以对当前语句的执行计划进行调整,以期达到更好的性能。和 SQL Server 类似,Babelfish 也提供了两种相似的工具,帮助我们完成 SQL 的调优。
1)使用解释计划提高 Babelfish 查询性能
Babelfish 提供了两个函数,它们透明地使用 PostgreSQL 优化程序为 TDS 端口上的 T-SQL 查询生成估计和实际的查询计划。这些函数类似于在 SQL Server 数据库中使用 SET STATISTICS PROFILE 或 SET SHOWPLAN_ALL 来识别和改进运行缓慢的查询。您可以按如下方式使用这两个 Babelfish 的函数:
- SET BABELFISH_STATISTICS PROFILE{ON|OFF}:以显示用于执行语句的查询计划。该命令实现 PostgreSQL EXPLAIN ANALYZE 语句的行为。
- SET BABELFIS_SHOWPLAN_ALL{ON|OFF}:以显示语句的估计执行计划,而不执行该命令。该命令实现了 PostgreSQL EXPLAIN 语句的行为。
您还可以通过设置 escape_hatch_showplan_all 参数为 ignore(忽略),使用和 SQL Server 相同的 set 语法而忽略函数中的 BABELFISH_ 前缀execute sp_babelfish_configure 'escape_hatch_showplan_all','ignore'。
接下来,我们使用 SET STATISTICS PROFILE ON 来显示 SQL 语句执行的执行计划,案例中使用一条简单表关联 SQL 语句:
语句执行后除了返回其常规结果集外,还在“QUERY PLAN”中显示了此 SQL 语句的执行计划。结果显示此执行计划使用了 Nested Loop 的表连接方式,两张表的数据获取分别使用了索引(Index Scan)和全表扫描(Seq Scan)的方式。

对于查询计划显示的信息类型,您可以参考 Babelfish Explain Options 来调整相关的参数。我们建议您在 T-SQL 的代码开发过程中,使用执行计划显示来处理性能相关的问题,考虑到数据量和真实生产环境中的区别,您可以在执行计划中更关注索引的使用,表连接方式等信息。另外请注意:目前还不支持从函数、控制流程和游标获取查询计划。由于 Babelfish 中显示的执行计划是基于 PostgreSQL 的关键字和显示方式, 关于 PostgreSQL EXPLAIN 语句更详细的输出解读,请参考 PostgreSQL 的使用手册。
2)使用 T-SQL 查询提示提高 Babelfish 查询性能
SQL 语句采用什么样的执行计划是由优化器根据成本代价估算自动选择的,查询优化程序经过精心设计,可以找到 SQL 语句的最佳执行计划。选择计划时,查询优化程序会同时考虑引擎的成本模型以及列和表统计数据。但是,建议的计划可能无法满足数据集的需求。因此,查询提示可以改进执行计划以解决部分性能问题。
SQL Server 中使用 Query Hint 在 SQL 标准中添加提示来调整执行计划,指示数据库引擎如何执行查询。PostgreSQL 本身也可以通过 enable_bitmapscan 之类的参数进行调节,但这些参数是针对会话的,对优化器的控制没有提示来的直接,也没有提示那么精细。Babelfish 中提供了 enable_pg_hint 的设置,您可以在会话或全局层面打开,打开后会启用 pg_hint_plan 插件的功能,它支持以下几类执行计划提示:
- INDEX 提示 – 扫描方式
- JOIN 提示 – 表连接方式,主要有 Nest Loop,Hash Join,Merge Join
- FORCE ORDER 提示 – 表连接顺序
- MAXDOP 提示 – 最大并行度
下面我们看一个使用查询提示的简单案例,首先在 Babelfish 连接中创建两张测试表
然后执行一个表关联查询的语句
通过 SET 语句打开执行计划显示,您可以看到两张表的关联使用了“Hash Join”连接
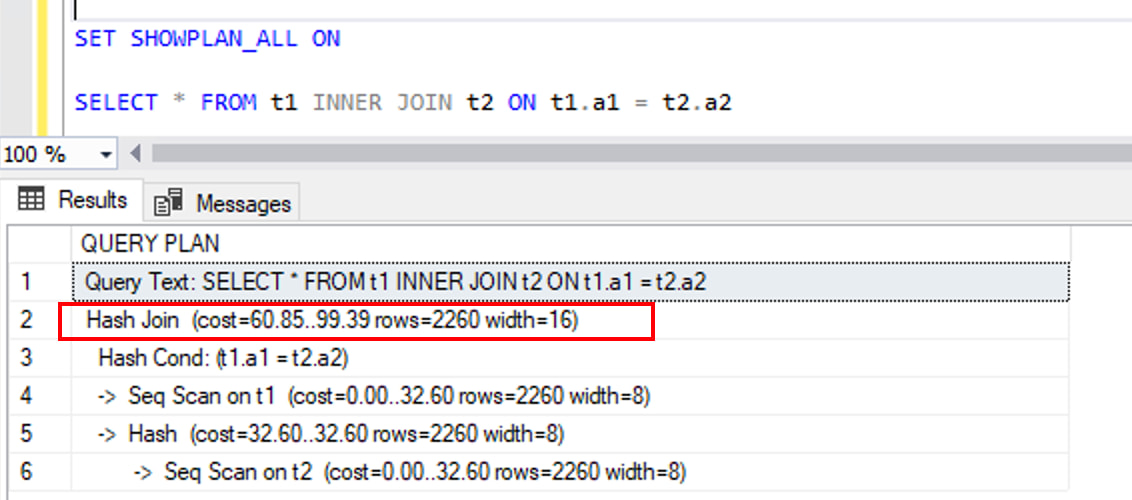
接下来我们在会话中启用查询提示,并修改 SQL 语句,添加指定表连接方式和引导顺序的提示。
再次执行后,您可以看到新的执行计划使用了提示的“Merge Join”表连接方式,而评估成本中的第一个数字(返回第一行)和第二个数字(返回所有数据)也有相应的变化。

不管是 SQL Server 还是 PostgreSQL,查询优化器通常会为查询选择最佳的执行计划,因此我们建议经验丰富的开发人员和数据库管理员仅使用查询提示作为最后的优化手段。另外 Query Hint 的时效性会随着时间推移,数据量的变更而发生变化,您需要适时重新评估 Hint 的优化效率。
3. 其他建议
当您的开发平台从 SQL Server 迁移到 Babelfish 之后,除了以上介绍的一些开发要点和建议外,基于代码开发的使用习惯在两种平台上的差异,在此还有一些其他的建议。
1)TempDB 的使用
SQL Server 中的 TempDB 是一个系统数据库,它主要用于存放全局或局部临时表及索引、临时存储过程、表变量、表值函数返回的表或游标,这些对象都是基于临时特征。Babelfish 支持本地临时表(名称以#开头的表),不支持全局临时表(名称以##开头的表)。
TempDB 中的操作是最小日志记录操作,以便回滚事务。每次启动 SQL Server 时都会重新创建 TempDB,在断开联接时会自动删除临时表和存储过程,并且在系统关闭后没有活动连接。在 TempDB 的使用上,Babelfish 和 SQL Server 的显著不同就是它在重新启动数据库时,不会删除在 TempDB 中创建的永久对象(如表和过程)。
一般而言,您在 T-SQL 代码开发时,不会将永久对象存放在 TempDB 上,除非这些对象是临时使用,预期在重启数据库后自动清除。在迁移到 Babelfish 之后,您的预期行为将发生改变,即使是数据库重启,存放在 TempDB 的对象也将保持不变。我们建议您审阅当前代码中相似的场景,做出及时调整,避免出现 TempDB 空间占用的问题。
2)外部数据访问
T-SQL 可以通过 SQL Server 的链接服务器(Linked Server)访问远程数据源并读取数据,并针对 SQL Server 实例之外的 OLE DB 数据源等远程数据库服务器执行命令。许多类型的 OLE DB 数据源都可配置为链接服务器,包括第三方数据库提供程序。
对于企业客户来说,往往需要在多个数据源中获取数据来支撑业务的使用,链接服务器是一个非常好的选择。对于 Babelfish 的用户来说,好消息是,在当前最新版本的 Babelfish 3.1.0 版本中,已经可以有限度地支持链接服务器地使用,它通过 Aurora PostgreSQL 支持的外部数据包装器(FDW)扩展来实现类似链接服务器的功能,提供对外部数据的访问。Babelfish 当前仅支持创建 TDS 协议的链接服务器,在使用上也仅支持 OPENQUERY()的远端数据查询方式。
下面我们通过具体的操作命令来向您展示如何使用 Babelfish 的链接服务器功能,首先您需要通过 PostgreSQL 连接来安装 tds_fdw 扩展:
然后您可以在 Babelfish 中使用 SQL Server 相同的存储过程 sp_addlinkedserver 和 sp_addlinkedsrvlogin 完成远程数据源的配置。注意:此功能同样支持将远端的 Babelfish 也当成 TDS 的数据源。添加链接服务器和登陆用户信息的 T-SQL 请参考下面的语句。注意:当前版本的链接服务器创建和使用需要在master 数据库下执行相关语句
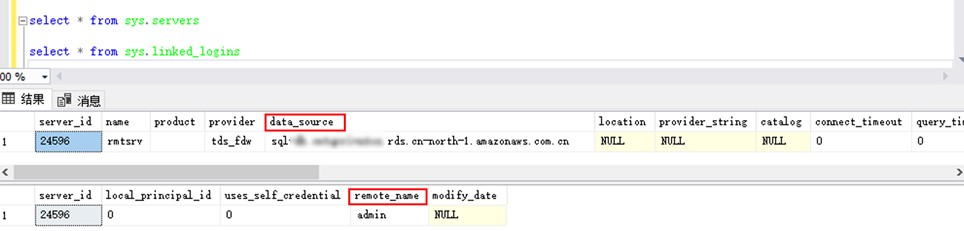
Babelfish 中同样提供了系统视图 sys.servers 和 sys.linked_logins 来查询链接服务器的相关信息,注意查询结果中 sys.servers 视图的 data_source 和 sys.linked_logins 视图的 remote_name 两个字段不能为空。
链接服务器创建成功后,可以使用下面的语句查询远端的数据
通过链接服务器,您可以直接使用远程查询来创建本地表
或将查询到的远程数据插入本地表
在数据迁移到 Babelfish 后,如果想比较两边数据的差异,我们建议您通过链接服务器来做快速比较:创建一张本地表来存储源表中唯一字段的数据,和本地目标表中唯一字段的数据进行比较,找到具体的差异数据。如下图案例所示:包含 1 千万条数据的源表 transdata,在目标库中有 3 条缺失,我们将源表的唯一字段 empno 存储到 babelfish 中的 master.dbo.t1 表中,然后通过一条简单的查询语句就能将具体的数据找到。

除了对 TDS 数据源的支持外,Aurora PostgreSQL 本身也支持使用 oracle_fdw 扩展来访问 Oracle 数据库源,与链接服务器不同的是,您需要通过 PostgreSQL 的连接去创建映射到 Oracle 的外部表并访问。注意:您无法直接通过 Babelfish 连接去调用此外部表。关于此扩展的更多信息,请参考 Aurora PostgreSQL 的使用手册。我们建议您在 T-SQL 开发过程中,根据实际的外部数据的访问需求,选择适当的方式来处理。
3)所有权链
SQL Server 中对象的访问,会保证只有被授予权限的安全主体(Principal)才能访问安全对象(Securable)。当多个数据库对象相互访问时,访问的对象序列称作链(chain),链中的每个节点都是一个数据库对象。当遍历链中的各个节点时,SQL Server 会采用特殊的方式来评估权限,这跟分别访问单个对象时的权限评估方式不同。
所有权链是一种特殊的权限评估方式:只检查链中对象的所有者,如果所有者相同,那么有权限访问该对象。也即是说在所有权链中,SQL Server 完全信任数据库对象的所有者(Owner),不会检查用户是否具有该对象的访问权限,只比较链中相邻的两个对象的所有者是否相同,如果相同,那么就有权限访问该对象;只在所有者不同时,才会执行权限检查。这在数据库管理上非常有用,但也会带来潜在的风险。
假设存在一个存储过程,用于从一个数据表中读取数据,用户被授予对存储过程的执行权限。如果存储过程和表具有相同的所有者,那么不需要被授予对该表的任何权限(甚至被授予拒绝权限),用户都可以访问该数据表。但是,如果存储过程和表具有不同的所有者,那么 SQL Server 必须在允许访问数据之前检查用户在表上的权限。
在 Babelfish 中,SQL Server 所有权链适用于视图,但不适用于存储过程。这意味着必须授予过程对与调用过程相同的所有者拥有的其他对象的显式访问权限。在 SQL Server 中,授予调用者对该过程的 EXECUTE 权限就足以调用同一所有者拥有的其他对象。在 Babelfish 中,还必须向调用者授予对该过程访问的对象的权限。
来看具体的案例,在 SQL Server 和 Babelfish 中,存储过程 P_Test1 和过程中需要访问的表 emp 都是属于管理用户,通过 SQL 语句将存储过程 P_Test1 的执行权限授予用户“user1”,表 emp 不做操作。
使用 user1 在 SQL Server 和 Babelfish 中分别执行存储过程,结果显示 Babelfish 不能通过所有权链的方式直接在执行过程中访问表 emp,需要向用户授权访问,而 SQL Sever 则不需要。
 |
鉴于 Babelfish 的所有权链处理方式和 SQL Server 的不同,可能会导致应用运行错误,我们建议您检查类似的 T-SQL 代码,如果需要则授予用户相应的访问权限。
4. 总结
在本篇文章中,我们向您介绍了更多的基于 Babelfish 的 T-SQL 开发最佳实践。您可以使用原有 SQL Server 开发经验,结合这些最佳实践,开发出适应业务需求的应用和 T-SQL 代码。
Babelfish 是一项不断发展的 Aurora PostgreSQL 功能,自它伴随着 Aurora PostgreSQL 13.4 首次推出以来,Babelfish 的每个新版本都添加了可更好地与 T-SQL 功能和行为保持一致的特性和功能,如 Babelfish 的各个版本支持的功能表中所示。为了在使用 Babelfish 时获得最佳效果,我们建议您通过官方手册了解 SQL Server 与最新版本的 Babelfish 支持的 T-SQL 之间目前存在的区别。