亚马逊AWS官方博客
使用 AWS DeepLens 构建垃圾分类器
在本篇博文中,我们会为您展示如何使用 AWS DeepLens 构建一种垃圾分类器。AWS DeepLens 是支持 AWS 深度学习的视频摄像头,能够让开发人员通过有趣的实践方法学习机器学习技术。这个垃圾分类器项目会教您如何在自定义的数据集上训练图像分类模型。
图像分类是一种强大的机器学习技术。在该技术中,机器学习模型会通过观察许多示例图像来学习如何区分其中的物体。您可以运用在本篇博文中学到的技巧,解决图像的分类问题(例如,按大小或等级对水果进行分类)或判断图像中是否存在某个物体的问题(例如,在自助结账时识别物体的类型)。
本教程的灵感来自为 AWS Public Sector Builders Fair 创建的智能回收机械手项目。如需了解详情,请观看 YouTube 上的演示:自动回收。
解决方案概览
本方案包含以下步骤:
- 收集、准备数据集,并将其传送给 ML 算法
- 使用 Amazon SageMaker 训练模型。这是一种提供了快速构建、训练和部署 ML 模型的完全托管式服务
- 在 AWS DeepLens 本地运行模型,在无需将任何数据发送到云的前提下预测垃圾类型
- (可选)在 AWS DeepLens 做出预测之后,您可以对 AWS DeepLens 进行设置。可以通过 AWS IoT Greengrass 向 Raspberry Pi 发送一则消息,为您显示应将物品丢入哪个分类垃圾箱。
下图展示了解决方案的架构。

先决条件
若要完成本方案,您必须满足以下先决条件:
- 一个 AWS 账户
- 一台 AWS DeepLens 设备。可通过以下渠道购买:Amazon.com(美国)、Amazon.ca(加拿大)、Amazon.co.jp(日本)、Amazon.de(德国)、Amazon.fr(法国)、Amazon.es(西班牙)、Amazon.it(意大利)。
- 带 Sense HAT 的 Raspberry Pi(可选)
收集并准备数据集
本教程使用称为图像分类模型的 ML 算法。这些模型通过多轮迭代观察大量示例,从而学习如何区分不同的物体。本教程使用一种称为迁移学习的技术,以显著减少训练图像分类模型所需的时间和数据量。如需详细了解如何使用 Amazon SageMaker 内置算法进行迁移学习,请参阅图像分类的工作原理。使用迁移学习,您只需要为每种垃圾类型使用几百张图像即可。当您需要模型能够准确地区分未见过的垃圾时,您需要添加了更多的训练样本,并提供了在不同视角、不同光线条件下的图像。这样一来,模型所需要的训练时间就会更长,但在推理的时候准确性就越高。
有许多公开的图像来源可供您使用,在自行外出收集图像之前,不妨考虑使用其中一种来源。如果希望图像带有清晰的标签(通常是人为添加的标签),以标明图像内都有哪些物体,您可以考虑下面这些资源:
- AWS Open Data – 包含各种可靠的隔开数数据集,这些组织开放共享了他们的数据集,以供大众使用。
- AWS Data Exchange – 包含免费、收费和需要支付订阅费后才能使用的数据集。这些数据集均经过精心整理并且带有标签,因此大多数时候都需要付费才能使用。
- GitHub – 其中有一些包含图像数据集的公共代码库。请务必遵守适用的条款和条件,并注明原作者。
- Kaggle – 包含用于 ML 比赛的各种公共数据集。这些数据集通常提供了适合新手的代码。
- 非营利组织和政府机构 – 包含可供公众使用的数据集。确保查看各对应组织或机构的具体使用条款。
- Amazon SageMaker Ground Truth – 基于您的图像创建带标签的数据集。根据更具体的标签添加使用案例,您可以在自动添加标签(推荐用于常见对象)、人工添加标签或 AWS Marketplace 产品之间进行选择。如需了解更多信息,请参阅使用 Amazon SageMaker Ground Truth 构建高度精确的训练数据集。
在收集图像时,一种较好的做法是使用从不同角度、不同光线条件下拍摄的图像,从而让模型更加健壮。下图中的示例展示了模型分类为填埋、回收或堆肥的图像类型。

在您获得针对每类垃圾的图像之后,请将图像分成文件夹。
|-images
|-Compost
|-Landfill
|-Recycle
获得要用于训练 ML 模型的图像后,你需要将它们上传到 Amazon S3。首先,创建 S3 存储桶。对于 AWS DeepLens 项目,S3 存储桶名称必须以 deeplens- 前缀开头。
本教程提供添加有回收、填埋和堆肥这几类标签的图像数据集。在接下来使用 Amazon SageMaker 训练模型的步骤中,您需要下载这个数据集。
使用 Amazon SageMaker 训练模型
本教程使用 Amazon SageMaker Jupyter 笔记本作为训练模型的开发环境。Jupyter 笔记本是一种开源 Web 应用程序,可用于创建和共享包含代码、公式、可视化内容和叙述性文本。我们已经准备好了一个完整的 Jupyter 笔记本,可供您用于按照本教程的介绍操作。
首先,下载示例笔记本:aws-deeplens-custom-trash-detector.ipynb
接下来,为了创建自定义图像分类模型,您需要使用启用了图形处理单元 (GPU) 的训练作业实例。GPU 非常适合并行处理神经网络训练所需的计算。本教程使用一个 ml.p2.xlarge 实例。为了访问启用了 GPU 的训练作业实例,您必须向 AWS Support 中心提交提高服务限制的请求。若要提高限制,您可以按照此处的说明操作。
在限制提高之后,请按照以下说明创建 Amazon SageMaker 笔记本实例:
- 打开 Amazon SageMaker 控制台,网址为:https://console.aws.amazon.com/sagemaker/。
- 选择笔记本实例,然后选择创建笔记本实例。
- 在创建笔记本实例页面中提供以下信息(此处未提及的字段请保留默认值):
- 对于笔记本实例名称,请输入您的笔记本实例的名称。
- 对于实例类型,请选择“ml.t2.medium”。这是笔记本实例支持的价格最低的实例类型,而且足以满足本教程的需要。
- 对于 IAM 角色,请选择创建新角色。确保此 IAM 角色有权访问您先前创建的 S3 存储桶(带有
deeplens-前缀)。请参阅下文。
- 选择创建笔记本实例。

您的笔记本实例最多可能需要 1 分钟的时间完成配置。
在笔记本实例页面上的状态更改为“InService”时,请选择打开 Jupyter 以启动新创建的 Jupyter 笔记本实例。
上传您先前下载的 aws-deeplens-custom-trash-detector.ipynb 文件。
打开笔记本,一直执行到结束。如果系统要求您设置内核,请运行 select conda_mxnet_p36 命令。
Jupyter 笔记本包含文本和代码单元格的组合。要运行一段代码,请选择相应单元格并按 Shift+Enter 组合键。相应单元格运行时,它旁边会出现一个星号。在一个单元格运行完成后,原始单元格下方会显示一个输出编号和新的输出单元格。
执行完该笔记本之后,您就会获得一个经过训练的模型,可用以区分不同类型的垃圾。
在 AWS DeepLens 上本地运行该模型
一个 AWS DeepLens 项目包含两个部分:一个模型和一个推理函数。推理就是指将模型应用到先前未见过的图像,并获得预测的过程。该模型包括算法和通过训练过程学习的参数。您可以使用由 Amazon SageMaker 训练的模型,也可以使用在您自己的机器上训练的外部模型。在本教程中,您要使用的是刚刚训练的 Amazon SageMaker 模型。
将您的模型导入 AWS DeepLens
在您的 AWS DeepLens 控制台中,转到模型,然后单击导入模型。
选择 Amazon SageMaker 训练的模型。然后选择您最近的作业 ID 和模型名称,并选择 MXNet 作为您的模型框架。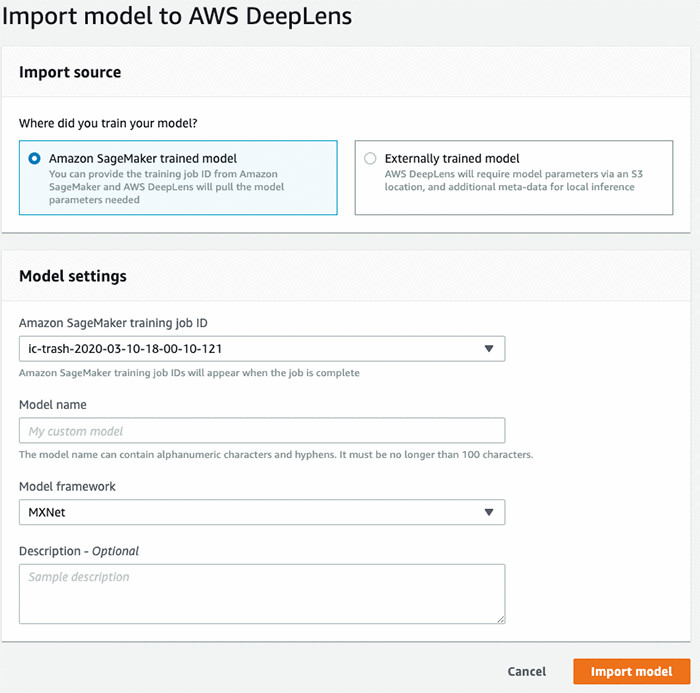
接下来单击导入模型。
创建推理函数
推理函数可以优化要在 AWS DeepLens 上运行的模型,并将摄像头拍摄到的每一帧画面传入模型,以获取预测。对于推理函数,您可以使用 AWS Lambda 创建要部署到 AWS DeepLens 的函数。Lambda 函数(位于 AWS DeepLens 设备本地)会对摄像头发来的每一帧画面进行推理。
本教程提供了一个 Lambda 函数推理示例。
首先,我们需要创建一个 AWS Lambda 函数,这个函数将会部署到 AWS DeepLens。
- 将 deeplens-trash-lambda.zip 下载到您的计算机上。
- 在 AWS 管理控制台中转到 AWS Lambda,然后单击创建函数。
- 然后选择从头开始创作,并确保选择以下选项:
- 运行时:Python 2.7
- 选择或创建执行角色:使用现有角色
- 现有角色:service-role/AWSDeepLensLambdaRole
- 创建函数后,在函数的详细信息页面上向下滚动,并在代码输入类型中选择上传压缩文件。
- 上传您先前下载的 deeplens-trash-lambda.zip 文件。
- 选择保存以保存您输入的代码。
- 从操作下拉菜单列表中,选择发布新版本。发布该函数后,即可在 AWS DeepLens 控制台中使用该函数,这样您就可以将其添加到自定义项目中。
- 输入版本号,然后单击“发布”!
理解 Lambda 函数
这一节为您介绍 Lambda 函数的一些重要部分。
首先,您应该注意两个文件:labels.txt 和 lambda_function.py。
labels.txt 包含人类可读标签的列表,便于我们将神经网络的输出(整数)映射到这些标签。
lambda_function.py 包含用于调用该函数的代码,以便针对摄像头拍摄到的每一帧画面进行预测,并返回结果。
下面是 lambda_function.py 的重要部分。
首先,您加载并优化模型。与采用 GPU 的云端虚拟机相比,AWS DeepLens 的计算能力要略逊一筹。AWS DeepLens 使用 Intel OpenVino 模型优化工具来优化在 Amazon SageMaker 中训练的模型,以便在其硬件上运行这些模型。以下代码对我们的模型进行优化,以便在本地运行此模型:
随后,您可以运行该模型,处理摄像头发来的每一帧图像。请参阅以下代码:
最后,您将文本形式的预测结果发回到云端。在云端查看文本结果是一种便捷的判断确保模型是否正确运行的方法。每个 AWS DeepLens 设备都有一个自动创建的专用 iot_topic,专用于接收推理结果。您也可以将结果以叠加方式显示在视频流上,或将这些结果发送到另一台设备,例如 Raspberry Pi。请参阅以下代码:
创建自定义 AWS DeepLens 项目
在您的 AWS DeepLens 控制台的项目页面中,单击创建项目。
选择空白项目选项。
为您的项目命名,以您的名字开头,后接 -trash-sorter。
然后单击添加模型并选择您刚刚创建的模型。
再单击添加函数,并按名称搜索您之前创建的 AWS Lambda 函数。
然后单击创建以创建项目。
将您的模型导入 AWS DeepLens
在 AWS DeepLens 控制台的项目页面中,选择要部署的项目,再选择部署到设备。
在“目标设备”屏幕上,从列表中选择您的设备,然后单击查看。
然后单击部署。根据您的 AWS DeepLens 所连网络的速度不同,部署最多可能需要 10 分钟完成。部署完成后,您应该会看到一个绿色的横幅,如下图所示。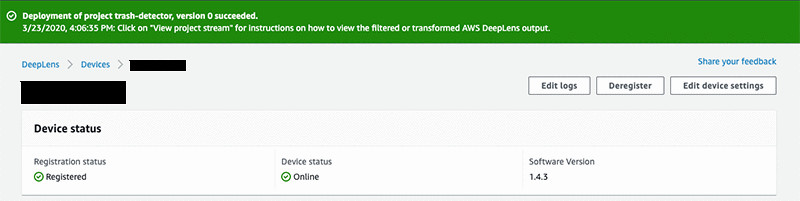
恭喜,您的模型现在已在 AWS DeepLens 上本地运行!
要查看文本输出,请在设备详细信息页面上向下滚动,找到项目输出部分。按照该部分中的说明复制主题,然后转到 AWS IoT 控制台订阅相应主题。
您应该看到如下图所示的结果。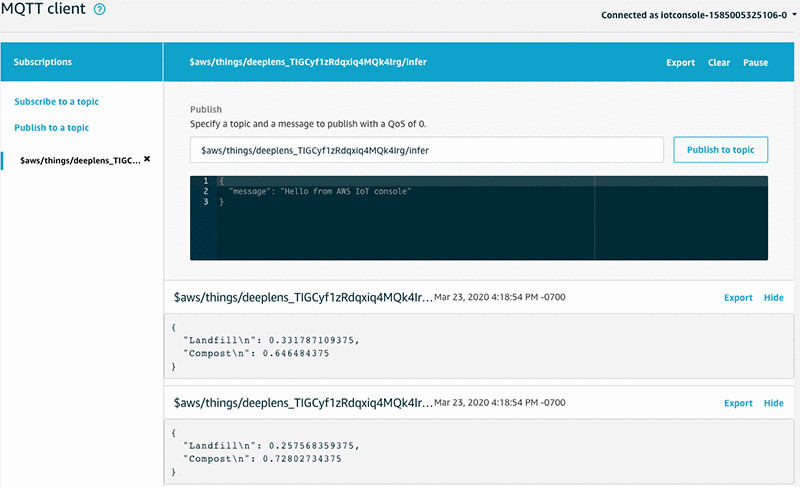
有关如何查看视频流或文本输出的分步说明,请参见此处。
通过 AWS IoT 采取行动
您可以选择将结果从 AWS DeepLens 发送到 IoT 设备(例如 Raspberry Pi),本节介绍了相关的步骤。随后,Raspberry Pi 可以利用这些结果来采取行动,例如移动机械臂或显示一则消息,告诉您要将具体的垃圾扔进哪个分类垃圾桶。这篇博文以概要探讨了这些步骤,如需查看详尽的分步指导,请参阅此处的说明。
更新 AWS DeepLens Lambda 函数
为了使 Raspberry Pi 了解需要采取怎样的行动,AWS DeepLens 需要发送一则消息,其中包含模型推理的输出结果。您需要向现有的 AWS DeepLens Lambda 函数添加新的代码行,以便将消息发送到新的 MQTT 主题。在部署更新的项目之前,请务必保存并发布 Lambda 函数的新版本,以便 AWS DeepLens 可以使用更新后的功能。详尽的分步说明请参见此处。
将设备添加到 Greengrass 组
借助 AWS IoT Greengrass,即使与云之间的连接时断时续,互联设备也能如常运行。无论在线还是离线,设备都能收集和处理数据。为了使设备之间直接进行安全通信,必须将 Raspberry Pi 添加到一个现有的 Greengrass 组中。如需查看相关说明,请参阅在 AWS IoT Greengrass 组中创建 AWS IoT 设备。确保选择以 deeplens 开头的现有组。详尽的分步说明请参见此处。
将 Raspberry Pi 添加到 Greengrass 组后,您需要创建一个订阅,保证 Lambda 函数发来的 MQTT 主题能够发送到正确的目的地。对于此使用案例,您希望 Lambda 函数使用 deeplens/trash/infer 的 MQTT 主题,将消息发送到 Raspberry Pi。 添加订阅后,请确保将该 Greengrass 组部署到 AWS DeepLens。详尽的分步说明请参见此处。
默认情况下,AWS DeepLens 会阻止端口 8883 上的流量,这是本地 AWS IoT Greengrass 通信的必要条件。要允许此通信,请首先打开您计算机上的终端,然后通过 SSH 登录到 AWS DeepLens 设备,再输入 ssh aws_cam@<YOUR_DEEPLENS_IP>。您可能需要按照此处的说明启用 SSH。随后输入 sudo ufw allow 8883 打开防火墙端口。 详尽的分步说明请参见此处。
每次更新 Lambda 函数时,您都需要使用自己创建的设备和订阅来更新 Greengrass 组。您不必在 AWS IoT 中重新创建新设备,设备定义将得到保留。您只需将现有设备添加到 Greengrass 组,重新创建订阅,然后部署该组即可。
配置 Raspberry Pi
在将 AWS DeepLens 配置为将模型的推理发送到 MQTT 主题之后,您需要准备 Raspberry Pi,使其侦听关于该 MQTT 主题的消息。由于 Raspberry Pi 使用 Python 与 AWS IoT 进行交互,因此您需要确保其具有适用于 Python 的 AWS IoT 设备开发工具包。如需了解详情,请参阅安装适用于 Python 的 AWS IoT 设备开发工具包。
Python 脚本接收到消息并执行相应操作。您可以从此处下载示例脚本。此外,您还可以使用 AWS IoT 设备开发工具包提供的 basicDiscovery.py 作为模板,编写自己的脚本。该脚本使用在创建新的 AWS IoT Greengrass 设备过程中下载的证书。有关更多信息,请参见测试通信。
结论
在本教程中,您学习了如何训练图像分类模型并将其部署到 AWS DeepLens,用以执行垃圾分类。接下来,用您自己的数据尝试一下本教程介绍的方法吧。
有关本教程的更详尽的演练以及其他 AWS DeepLens 教程、示例和项目构思,请访问 www.awsdeeplens.recipes。