亚马逊AWS官方博客
使用 Amazon Elasticsearch Service 构建 k 近邻 (k-NN) 相似度搜索
Elasticsearch通常是ELK堆栈的统称,用于描述一个包含三个流行的开源项目的堆栈:Elasticsearch,Logstash和Kibana。ELK堆栈能够聚合来自所有系统和应用程序的日志,分析这些日志,并创建可视化的图像以进行应用程序和基础架构监视,更快的故障排除,安全分析等。ELK堆栈之所以受欢迎,是因为它满足了日志分析领域的需求。随着越来越多的IT基础架构移至云,越来越需要一个日志管理和分析解决方案来监视此基础架构以及处理任何服务器日志,应用程序日志和点击流。ELK堆栈为开发人员和DevOps工程师提供了一个简单而强大的日志分析解决方案,以低廉的价格获得了有关故障诊断,应用程序性能和基础架构监视的宝贵见解。Amazon Elasticsearch Service (Amazon ES) 是一项完全托管的服务,方便大规模经济高效地部署、保护和运行 Elasticsearch。该服务提供开源 Elasticsearch API、托管 Kibana、与 Logstash 和其他 AWS 服务的集成以及内置提醒和 SQL 查询支持。
最近,Amazon ES提供了k 近邻 (k-NN) 相似度搜索的功能,可通过相似度来增强搜索。例如,在音乐流服务中,当用户生成播放列表时,推荐系统使用k-NN添加与该播放列表的属性匹配的歌曲。在k-NN搜索算法中,数据集的元素由矢量表示。每首歌曲都是矢量,包含艺术家,专辑,流派,发行年份等多个维度(属性)。搜索假定您在数据元素(矢量)之间具有定义的距离函数,并将最相似的项返回给所提供的作为输入,最接近的距离转化为项目相似度。具有相似性搜索的其他用例包括欺诈检测,图像识别和语义文档检索等。
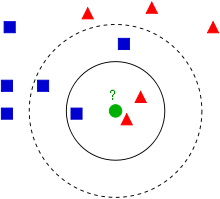
k-NN算法是经典的机器学习算法之一,是用于分类和回归的非参数方法。在两种情况下,输入都包含特征空间中k个最接近的训练示例。输出取决于将k-NN用于分类还是回归:在k-NN分类中,输出是类成员。对象通过其邻居的多次投票进行分类,该对象被分配给其k个最近邻居中最常见的类别(k是一个正整数,通常很小)。如果k = 1,则仅将对象分配给该单个最近邻居的类;在k-NN回归中,输出是对象的属性值。该值是k个最近邻居的值的平均值。下图为k-NN分类的示例。测试样品(绿点)应分类为蓝色正方形或红色三角形。如果k = 3(实线圆),则将其分配给红色三角形,因为内部圆内部只有2个三角形,而只有1个正方形。如果k = 5(虚线圆),则将其分配给蓝色正方形(外部圆内的3个正方形对2个三角形)。关于k-NN算法,我们在此不详细展开,如有兴趣可以参阅相关书籍。
Amazon ES 中的k-NN算法使用高效的轻型 Non-Metric Space Library (NMSLIB) 构建,支持对跨数千个维度的数十亿个文档进行大规模、低延迟的最近邻搜索,与运行任何常规 Elasticsearch 查询一样简单易行。 给定数据点的空间,k-NN 插件会查找距离查询数据点最近的数据点数 (k)。通过 k-NN 的新字段类型,您能够将 k-NN 搜索与 Elasticsearch 的各种功能(如聚合和筛选)无缝集成,以进一步提高搜索结果的精确度。Elasticsearch 的分布式架构使 k-NN 插件能够摄取和处理大型数据集,支持增量更新,从而为您提供具有快速推理功能的高性能相似度搜索引擎。
Amazon ES中的k-NN 相似度搜索由 Open Distro for Elasticsearch提供支持,已在运行 Elasticsearch 7.1 及更高版本的域上推出。Open Distro for Elasticsearch是 Elasticsearch 的一个增值发行版,100% 开源(采用 Apache 2.0 许可证)并且由 AWS 提供支持。Open Distro for Elasticsearch提供了诸多企业级的安全性和高级功能,例如警报,SQL和群集诊断,性能分析仪,索引管理以及机器学习能力。
下面我们来看如何在Amazon ES的域中构建 k-NN 相似度搜索。
首先,我们使用index.knn设置创建一个索引,并添加一个或多个knn_vector数据类型的字段。
在创建索引后,我们向其中添加一些样本数据。knn_vector数据类型支持最多10,000个浮点数的单个列表,其浮点数由所需的Dimension参数定义。
这样我们就可以使用k-NN查询类型来进行搜索数据了。
在这种情况下,k是我们要查询返回的邻居数,但是还必须包括size选项。 否则,我们将只能为每个分片(和每个段)获得k个结果,而不是整个查询获得k个结果。 K-NN支持的最大k值为10,000。
如果将k-NN查询与其他子句混合使用,则收到的结果可能少于k个。 在下面的示例中,我们使用post_filter子句将结果数从2减少到1。
Open Distro for Elasticsearch可让您使用_cluster / settings API修改所有KNN设置。 在Amazon ES上,您可以更改除knn.memory.circuit_breaker.enabled和knn.circuit_breaker.triggered之外的所有设置。 KNN统计信息可以包含在Amazon CloudWatch指标中。
使用Amazon ES构建k-NN搜索的一个最佳实践是,请对照knn.memory.circuit_breaker.limit统计信息和实例类型的可用RAM,检查每个数据节点上的KNNGraphMemoryUsage指标。 Amazon ES将实例RAM的一半用于Java堆(最大堆大小为32 GiB)。 默认情况下,KNN最多使用剩余一半的60%,因此具有32 GiB RAM的实例类型可以容纳9.6 GiB图形(32 * 0.5 * 0.6)。 如果图形内存使用率超过此值,则性能可能会受到影响。
参考资料
- https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- https://opendistro.github.io/for-elasticsearch-docs/docs/knn/
- https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/knn.html
- https://github.com/nmslib/nmslib