亚马逊AWS官方博客
通过AWS DMS与Amazon MSK来实时收集Amazon DocumentDB中的流数据
随着MongoDB的普及,基于MongoDB的实时分析的需求和场景也变得越来越多,例如:
- 游戏公司需要实时分析MongoDB中的玩家信息,产生实时排行榜,实时在线人数等
- 区块链公司需要实时获取链上数据,并且拿到最新区块内的交易额信息,最大金额,最小金额,DAU等等
本文将尝试从Amazon DocumentDB(兼容MongoDB) 中抽取实时数据流,并打入消息队列Kafka,方便后端进行Consume和分析。基于篇幅原因,我们会在之后的文章里使用Kinesis Analytics (托管Flink运行平台)来实时消费Kafka的数据,方便做特征工程以及实时分析,拿到实时数据中的Insight。

让我们先看一下本文中使用到的技术组件:
Amazon DocumentDB是一种数据库服务,专为大规模 JSON 数据管理而打造,由 AWS 全面托管,并兼容 AWS,具有适合大型企业持久性。这种可扩展的服务为您提供运行任务关键型 MongoDB 工作负载所需的持久性。
AWS Database Migration Service (AWS DMS) 可帮助您快速并安全地将数据库迁移至 AWS。源数据库在迁移过程中可继续正常运行,从而最大程度地减少依赖该数据库的应用程序的停机时间。
Amazon Managed Streaming for Apache Kafka (Amazon MSK) 是一种 AWS 流数据服务,可管理 Apache Kafka 基础设施和运营,让开发人员和 DevOps 经理可以轻松地在 AWS 上运行 Apache Kafka 应用程序和 Kafka Connect 连接器,而无需成为运行 Apache Kafka 方面的专家。Amazon MSK 运营、维护和扩展 Apache Kafka 集群,提供开箱即用的企业级安全功能,并具有内置的 AWS 集成,可加速流数据应用程序的开发。
前置条件:
在开始构建之前,请先完成以下步骤:
第一步:开启Change Streams并获取证书
- 首先,开源的MongoDB采用oplog来作为复制数据的源,而DocumentDB是采用Change Streams来作为复制数据的源,所以我们需要在DocumentDB集群中的主实例启用Change Streams:
- 下载DocumentDB的证书,以供DMS实例能安全的连接到DocumentDB:
wget https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem
第二步:设置DMS
- 切换到DMS 控制台,将DocumentDB证书导入,以供DMS在下一步中使用

- 创建DocumentDB数据源的终端节点,并测试连通性。关于更多细节信息,请参考AWS DMS终端节点使用指南。 以下截图所示,为本文示例中Amazon DocumentDB集群的终端节点。

其中
-
- 将Server name设置为DocumentDB的主实例域名
- 选择对应的DocumentDB的证书以开启SSL加密
- 创建Kafka为目标终端节点,并测试连通性
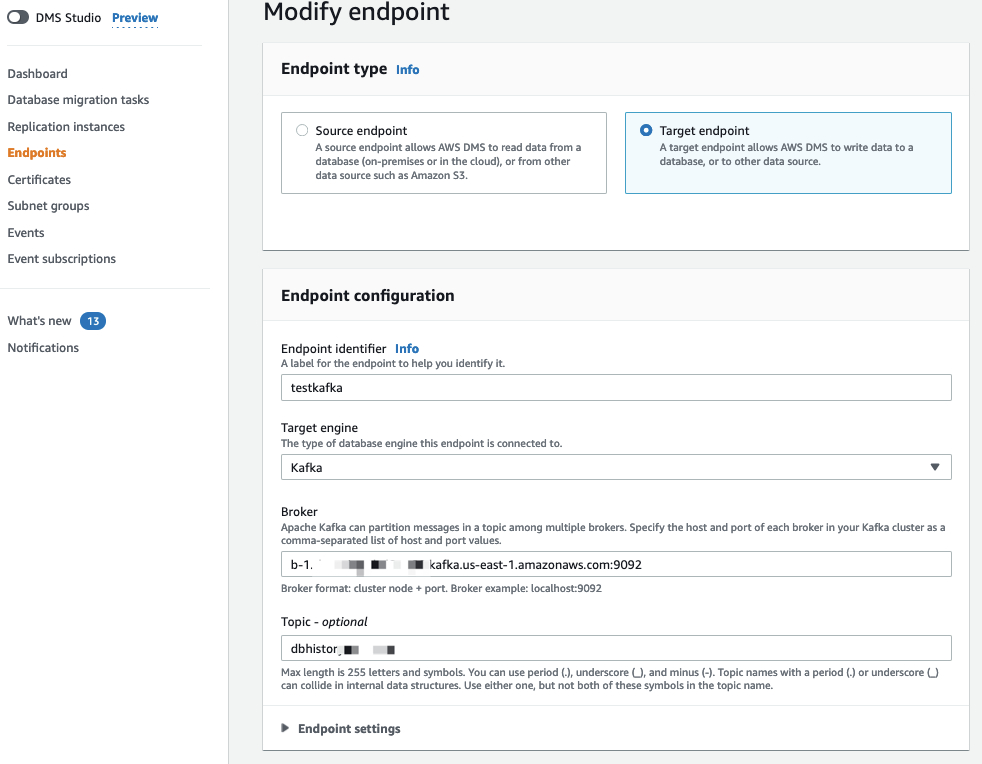
其中:
-
- Broker的信息为Kafka的集群地址和端口,如果有多个Broker,可以将多个域名写入
- Topic为Kafka中创建过的Topic名称
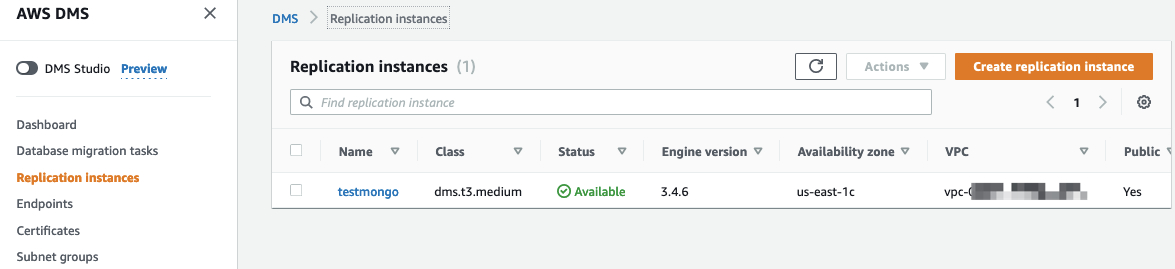
- 创建一个AWS DMS复制实例。具体操作,请参阅AWS DMS复制实例使用指南。 在数据迁移当中,本文使用medium实例类型,如果您是在生产环境中操作,则不建议使用T系列机型,而是根据您迁移数据量级来评估需要的任务实例机型,推荐使用C5/R5机型。AWS DMS利用该复制实例运行数据迁移任务,将来自Amazon DocumentDB的数据实时打入至目标Kafka集群。 此外,AWS DMS可在最长六个月周期内为特定迁移目标提供特定类型的免费复制实例。关于更多细节信息,请参阅AWS数据库迁移服务:免费DMS
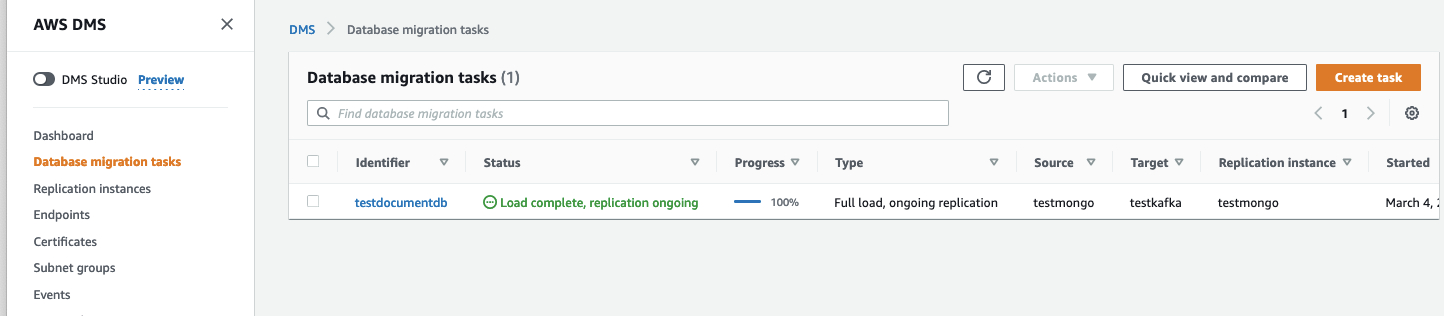
- 创建一项复制任务,用于将数据从源端点实时传输至目标终端节点。
将任务类型选定为“Full data load followed by ongoing data replication”(在数据复制完成后加载全部数据)。
将“Selection Rules”选择对应的需要的Table,如果都需要读取,则可以使用通配符%

在创建时启用“Start task”(启动任务)选项。 则在任务创建后,复制过程会立即开始。以下截图展示了数据库迁移任务的当前状态,可以看到任务已经完成全部加载,且当前正在执行持续复制。
第三步:测试写入实时数据
本次实验采用AWS Cloud9作为代码执行环境,并安装Python以及Kafka客户端。如下代码向DocumentDB持续写入数据,稍后我们可以查看是否能在MSK的Topic中实时看到这些数据。具体代码如下所示:
第四步:查看实时流数据
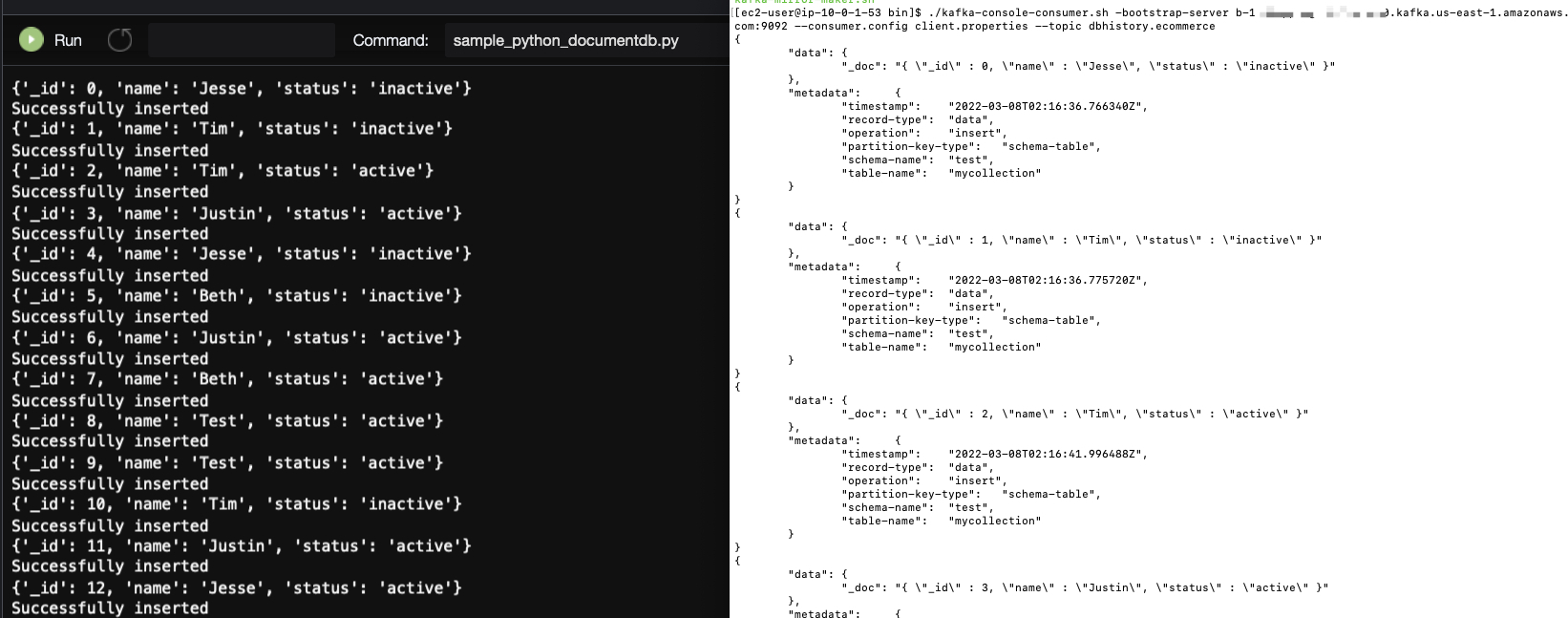
- 代码开始运行后,我们可以开启一个Kakfa的Consumer,来查看是否接收到了来自DocumentDB的实时数据流
./kafka-console-consumer.sh -bootstrap-server YourBrokerHostname:9092 --consumer.config client.properties --topic YourKafkaTopic
可以看到,左侧黑背景的代码为Python代码实时输出的随机数据结果,而右侧白背景的代码是我们从Kafka中拿到的实时结果,两者的Document数据是一致的,并且DMS还添加了额外的一些元数据,方便后期进行分析和过滤
总结
本文介绍了如何使用在线方法将实时数据流从Amazon DocumentDB传输至Kafka。基于篇幅的原因,那在之后的文章中,我们还会来用Flink程序实时处理这些来自DocumentDB的流数据,帮助企业获得想要的Insight。
如果您有任何疑问或者建议,请在下方评论中表达您的观点