亚马逊AWS官方博客
深度探索通过数据共享(data sharing)优化Amazon Redshift工作负载分解
Amazon Redshift 是一款完全托管的 PB 级大规模并行数据仓库,它操作简单并且性能高效。它使用标准 SQL 和现有的商业智能 (BI) 工具来快速、简单且经济高效地分析所有数据。如今,Amazon Redshift 已成为使用最广泛的云数据仓库之一。客户使用 Amazon Redshift 来处理多种类型的大数据工作负载,例如加速现有数据库环境或用于大数据分析的日志摄取。
近年来,随着互联网产生数据量的显著增长,一些客户开始询问他们应该如何更高效地使用 Amazon Redshift 。为帮助客户更高效、低成本地使用Amazon Redshift,自其推出以来,亚马逊云科技一直对其不断完善,并发布了大量新特性和功能。例如 Amazon Redshift Spectrum、基于 SSD 的 RA3 节点类型、暂停和恢复集群、Amazon Redshift 数据共享和 AQUA(高级查询加速器)等。每项改进和/或新功能都可以提高 Amazon Redshift 的性能和/或降低成本。深入地了解以上功能可以帮助您更高效地使用Amazon Redshift。
在本篇博客中,我们将通过一个案例探讨如何使用 Amazon Redshift RA3 节点、数据共享(data sharing)以及暂停和恢复(pause/resume)集群在本案例的业务场景下来大幅提升Amazon Redshift 集群的性价比。
首先,让我们快速回顾一下一些关键功能。
Amazon Redshift 的 RA3 节点简介
适用于 Amazon Redshift 的 Amazon Redshift RA3 节点由新的托管存储模型提供支持,该模型可以分别优化计算能力和存储功能。它们利用一些架构改进,包括高带宽网络、使用由 S3 支持的基于 S3 的本地 SSD 存储的托管存储,以及多种高级数据管理技术来优化进出 S3 的数据移动。它们带来了一些非常重要的功能,其中之一就是数据共享。RA3 节点还具有暂停和恢复的功能,这使客户可以在不使用集群时轻松暂停集群以暂停计费。
数据共享(data sharing)简介
Amazon Redshift 数据共享功能于 2021 年正式推出,它使您可以安全、轻松地在 Amazon Redshift 集群之间共享实时数据以进行读取。数据共享支持在亚马逊云科技 账户内跨 Amazon Redshift 集群进行即时、精细和高性能的数据访问,而不会产生与数据副本和数据移动相关的复杂性和延迟。数据可以在多个级别共享,包括架构、表、视图和用户定义的函数,从而提供精细的访问控制,可以针对需要访问数据的不同用户和企业量身定制。
Example Crop. 的Amazon Redshift优化项目
客户Example crop. 大量使用 Amazon Redshift 作为其大数据分析业务的数据仓库,他们一直很享受 Amazon Redshift 为其业务带来的可能性。客户主要使用Amazon Redshift来存储和处理用于商业智能目的的用户行为数据,最近几个月数据每天增加约几百GB,各部门的人员在办公时间会不停地通过其商业智能 (BI) 平台在Amazon Redshift集群上查询各种数据。
因为有些数据会被所有工作负载使用,所以Example Crop. 将最主要的4种分析负载在单个 Amazon Redshift 集群上运行。这4种分析工作负载分别是:
- 来自其商业智能平台(BI platform)的查询:主要在办公时间被执行的各种查询。
- 每小时数据ETL :在每小时的前几分钟运行。执行通常需要大约40分钟。
- 每日数据 ETL :它每天运行两次。本负载执行是在办公时间进行的,原因是运营团队需要在每天下班之前获得每日报告。每次执行通常需要5到3个小时。它是资源消耗量第二大的工作负载。
- 每周数据ETL:它在每周日的凌晨运行。这是最耗资源的工作负载。执行时间通常需要3到4个小时。
由于业务和数据量的不断增长,Example Crop. 的数据分析团队已经将原有的Amazon Redshift集群迁移到基于RA3 系列节点的新Amazon Redshift集群上。因为全部分析工作负载都在一个集群上运行并且数据量增长很快,为了保证其商业智能平台的查询平均执行时间,Example Crop. 逐步将 Amazon Redshift 集群的节点数量增加到 12 个。
但是,他们注意到,除了 ETL 任务执行期间会产生一些峰值外,平均 CPU 利用率通常低于 50%,因此数据分析团队希望和亚马逊云科技的技术团队合作探索在不损失查询性能的前提下,优化其 Amazon Redshift 集群性能和成本的解决方案。
由于 CPU 使用率峰值通常出现在执行各类ETL任务期间,因此我们首先想到的方案是将工作负载和相关数据拆分到规模不同的多个 Amazon Redshift 集群中。通过减少节点总数,我们希望能够降低客户的成本。
经过一系列探讨我们发现,将不同分析负载拆分到多个Amazon Redshift 集群的一大障碍是,由于业务需要,多个分析负载经常需要读取和/或更新数据仓库中的同一组数据表。在保证高性能的前提下,保证拆分后各个Amazon Redshift集群的数据一致性是一个挑战。比如,有些表中的数据需要由ETL 工作负载读取,并由 BI 工作负载更新,而有些表则相反。因此,如果我们将数据复制到2个Amazon Redshift集群中,并且仅创建从BI集群到报告集群的数据共享,则客户需要额外设计数据同步流程,在所有Amazon Redshift集群之间保持数据一致性——由于需要考虑的因素比较多,这可能会变的很复杂。
在进一步深入了解客户工作负载之后,我们发现可以将数据表分为 4 种类型,顺着这个思路我们提出了两集群双向数据共享(two-way data sharing)方案。该解决方案的目的是将资源消耗大的ETL工作负载迁移到一个单独的 Amazon Redshift 集群——以便我们利用 Amazon Redshift 的暂停和恢复(pause/resume)集群功能,只在这些ETL负载执行时使用该集群,从而降低 Amazon Redshift 的运行成本,并且通过双向数据共享保证2个Amazon Redshift集群之间的数据一致性,而无需额外构建数据同步流程。

将旧架构单集群(左),改进为新的两集群方案(右)
分解工作负载和数据
由于四种主要工作负载的特点,我们将工作负载分为两类,即持续运行(long-running)的工作负载和定期运行(periodic-running)的工作负载。
持续运行的工作负载适用于 BI 平台和每小时 ETL。因为每小时的 ETL 工作负载平均需要大约 40 分钟才能完成,这意味着即使我们将其迁移到独立的 Amazon Redshift 集群并每小时暂停/恢复一次,收益也比较小,因此我们目前将它与BI平台负载划分在一起。
定期运行的工作负载为每日 ETL 和每周 ETL。
规划数据共享
下一步是确定每个类别的所有数据(表)的访问模式。
对此,我们确定了4种类型的数据表:
- 类型1数据表:只能由持续运行的工作负载读取和更新。
- 类型2数据表:由持续运行的工作负载读取和更新,且由定期运行的工作负载读取,但不更新。
- 类型3数据表:由定期运行的工作负载读取和更新,且由持续运行的工作负载读取,但不更新。
- 类型4数据表:只能由定期运行的工作负载读取和更新。
将所有数据表根据上述4种类型分类后发现,所有数据表都符合4种类型中的一种。因此,我们可以继续将单个 Amazon Redshift 集群分为 2 个群集。一个集群具有 12 个 RA3 节点,命名为long-running-cluster,用于持续运行的工作负载;另一个集群具有 20 个 RA3 节点,命名为periodic-running-cluster,用于周期运行的工作负载。
我们将在long-running集群和periodic-running集群之间创建双向数据共享。对于上面列出的类型2数据表,我们将在long-running集群(作为生产者/producer)上创建数据共享L-to-P,并将periodic-running集群设置为使用者(consumer)。对于上面的类型3数据表,我们将在periodic-running集群(作为生产者’/producer’)上创建数据共享P-to-L,并把long-running集群设置为使用者(consumer’)。
双向数据共享(Two-way data sharing)架构图
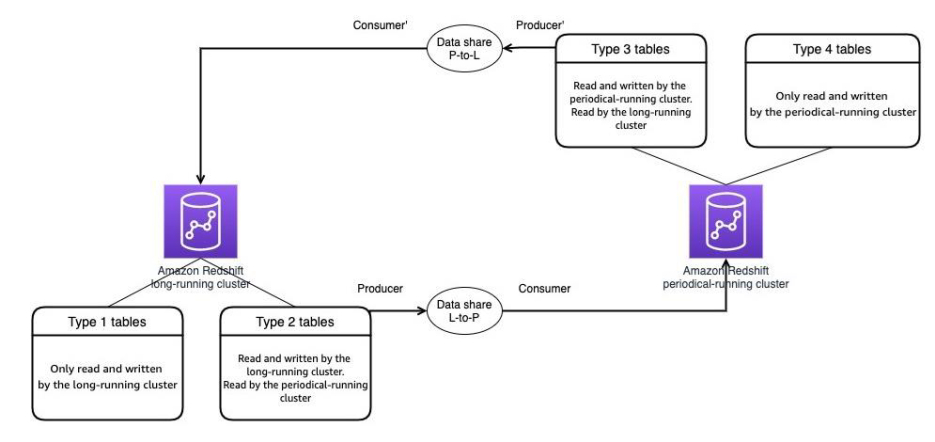
long-running集群(producer)与periodic-running集群(consumer)共享类型 2 数据表。periodic-running集群(producer’)与long-running集群(consumer’)共享类型3数据表
跨Amazon Redshift 集群构建双向数据共享
首先,让我们对最初的单个Amazon Redshift 集群进行快照(snapshot),稍后该集群将被改造成long-running-cluster集群。

现在,让我们创建一个具有 20 个 RA3 节点的新 Amazon Redshift 集群,名字为periodic-running-cluster,用于周期运行的工作负载,请确认选择RA3类型实例。创建完成后,我们将类型 3 和类型 4 表迁移到该集群。
从long-running-cluster集群共享数据到periodic-running-cluster集群
下一步是创建数据共享L-to-P。我们可以使用Amazon Redshift Query Editor V2进行操作。
在periodic-running-cluster集群上,我们执行以下命令得到其namespace,记为[periodic-running-cluster],并记录下namespace的值:
然后,在long-running-cluster集群上,我们执行下列queries:
注意,请将最后一条query中的[periodic-running-cluster] 替换为前一步记录的namespace值。
然后,我们可以用下列命令验证数据共享L-to-P:
验证数据共享L-to-P后,我们通过下列query得到long-running-cluster的namespace [long-running-cluster-namespace],并记录下namespace的值:
然后,让我们回到periodic-running-cluster集群。在periodic-running-cluster集群上,我们执行下列命令加载数据:
注意,请将query中的[long-running-cluster] 替换为前一步记录下的namespace值。
然后我们验证我们能否通过数据共享L-to-P读取工作表数据。
从periodic-running-cluster集群共享数据到long-running-cluster集群
创建数据共享 P-to-L
我们在前面的步骤中已经记录了long-running-cluster集群和periodic-running-cluster集群的namespaces,后面的步骤中我们将直接使用他们。
在periodic-running-cluster上,我们执行下列queries来创建数据共享P-to-L:
之后,我们用下面query来验证数据共享P-to-L是否创建成功:
在我们验证了数据共享P-to-L创建成功之后,回到long-running-cluster集群。
在long-running-cluster集群上,我们执行下列命令将数据共享中的数据加载到long-running-cluster集群上:
然后我们验证在long-running-cluster集群上是否能通过数据共享P-to-L读取工作表数据。
验证成功后,双向数据共享(two-way data sharing)的建立就完成了。
下一步是更新不同工作负载的代码,以正确地使用两个 Amazon Redshift 集群的endpoints,并进行业务测试。
至此,我们已经将工作负载划分到两个 Amazon Redshift 集群,并在两个集群之间成功建立了双向数据共享。
暂停/恢复periodic-running Amazon Redshift 集群
现在,我们来更新一下运行每日ETL和每周ETL工作负载的定时脚本(可能是crontab)。将有两处更新。
- 脚本启动时,通过集群ID,调用 Amazon Redshift 检查并恢复集群 API,以便在恢复(resume)处于暂停状态的 Amazon Redshift 集群periodic-running-cluster。
aws resume-cluster --cluster-identifier [periodic-running-cluster-id]
- 在ETL工作负载完成后,使用集群 ID 调用 Amazon Redshift 暂停集群 API 以暂停periodic-running-cluster集群。
aws pause-cluster --cluster-identifier [periodic-running-cluster-id]
结果
在将工作负载迁移到新架构之后,Example Crop. 数据分析团队进行了为期一个月左右的测试。
根据测试,所有工作负载的性能都有提高。详情如下:
- 在 ETL 工作负载运行期间,BI 工作负载的平均性能提高了约 100%。
- 每小时 ETL 工作负载的执行时长缩短了约 50%。
- 每日ETL工作负载持续时间从最长3小时缩短至平均40分钟。
- 每周ETL工作负载持续时间从最长4小时缩短至平均5小时。
优化期间业务新增数据约10%,但总成本只上升了约13%,并且所有业务都运行正常。
结论和局限性
根据该项目的情况,在将工作负载分成不同的Amazon Redshift集群之后,我们有以下发现。
- 首先,BI工作负载的平均性能提高了100%,因为其不再与每日ETL和每周ETL工作负载竞争资源。
- 其次,定期运行的 Amazon Redshift 群集上的 ETL 工作负载的持续时间显著缩短,因为没有来自 BI 和每小时 ETL 工作负载的资源竞争,并且该集群拥有了更多节点(20个)。
- 第三,通过利用 Amazon Redshift RA3 系列的集群暂停/恢复(pause/resume)功能,在业务数据量新增约10%的情况下,Amazon Redshift 集群的总体成本仅增加了约 13%。
由此得到的结论是,在该项目中 Amazon Redshift 集群的性价比至少提高了 70%。
但是,该解决方案存在一些局限性。
- 首先,要使用 Amazon Redshift 暂停/恢复功能,必须将调用 Amazon Redshift 暂停/恢复 API 的代码添加到所有在periodic-running-cluster集群上运行 ETL 工作负载的相关脚本中或在集群中配置定时暂停和恢复。
- 其次,Amazon Redshift 集群需要几分钟才能完成暂停/恢复,尽管暂停和恢复过程中不会向客户计费。
- 第三,Amazon Redshift 集群的大小无法根据工作负载自动缩减/扩展,还需要人工定期调整。
下一步计划
为了保证系统的稳定运行,本项目中未缩减long-running-cluster集群的节点数量。考虑到该集群平均CPU Utilization并不高,在经过测试后,我们可以尝试在保证BI 工作负载和每小时ETL工作负载性能的前提下,对该集群进行Elastic Resize操作,将节点数减少,以达到进一步降低成本的目的。
尽管本文中的解决方案在客户的分析工作负载上实现了显著的性价比提升,但我认为我们可以进一步简化Amazon Redshift操作,并提高工作负载持续时间的粒度。
Amazon Redshift Serverless已在re:Invent 2021中宣布开始preview。Amazon Redshift Serverless 可自动预置和智能地扩展数据仓库容量,为您的所有分析提供一流的性能。您只需按秒为工作负载持续时间内使用的计算资源付费。您可以直接从中受益,而无需对现有的分析和商业智能应用程序进行任何更改。
因此,Amazon Redshift Serverless是我们下一步可以尝试的一项服务。