亚马逊AWS官方博客
在 Amazon SageMaker 上微调与部署语音分离模型
“语音分离”(Speech Separation)来自于“鸡尾酒会问题”,采集的音频信号中除了主说话人之外,还有其他人说话声的干扰和噪音干扰。 语音分离的目标就是从这些干扰中分离出主说话人的语音。 由于麦克风采集到的声音中可能包括噪声、其他人说话的声音、混响等干扰,不做语音分离、直接进行识别的话,会影响到识别的准确率。语音分离被广泛应用在各个语音方向的机器学习场景中。然而,在语音分离任务中,数据科学家常常会遇到以下问题:
-
- 底层软硬件限制,模型训练慢,效率低。
- 系统环境配置复杂,不得不投入更多精力在非业务相关的维护上。
- 需要同时保证数据与代码的安全与CICD pipeline,流程复杂。
- 需要监控与追溯模型版本与数据。
- 需要持续对于上线模型进行性能监控与追踪,费神费力,通知不及时。
Amazon SageMaker 是一项完全托管的服务,可通过完全托管的基础设施、工具和工作流程为任何用例构建、训练和部署机器学习 (ML) 模型。Amazon SageMaker 的优势包括:
- 近乎无限的计算资源与预配置环境与算法,显著提升模型开发效率。
- 快速、轻松地构建和训练机器学习模型,然后直接将模型部署到生产就绪托管环境中。
- 数据安全与MLOps最佳实践,简化ML CICD 与工程化流程。
- 集成的 Jupyter studio IDE,供您轻松访问数据源以便进行探索和分析,训练与部署过程中全面的监控与日志记录。
- SageMaker monitor进行线上模型性能监控与追踪。
在这篇blog中,我们将以DPRNNTasNet为例探索开源代码迁移到SageMaker的过程与SageMaker优势,如算法一键训练,模型一键部署,自定义运行环境,过程监控等。DPRNNTasNet是 2020 ICASSP 语音分离SOTA(state of the art)模型。下图为DPRNN系统流程图:

A 分段。将一个连续的输入分割成块,重叠并连接,以形成三维张量。重叠率设置为50%。
B 每个DPRNN块由两个RNN在不同维度上重复连接。双向RNN首先应用于单个数据块处理本地信息。然后跨数据块RNN获取全局特征。多个块可以堆叠以增加网络的总深度。最后3-D输出被转换回原始维度序列输出。
DPRNN在asteroid实现源码可参考:https://asteroid.readthedocs.io/en/v0.3.3/_modules/asteroid/models/dprnn_tasnet.html。在这篇blog中,数据为基于DNS4创建的合成数据 https://github.com/microsoft/DNS-Challenge。合成脚本请参考 https://github.com/aws-samples/asteroid-on-sagemaker/blob/main/snr_mix.py。
接下来我们在sagemaker上进行asteroid部署。首先打开Amazon sagemaker 控制界面,点击【创建笔记本实例】

输入【笔记本实例名称】,选择适当的笔记本实例类型
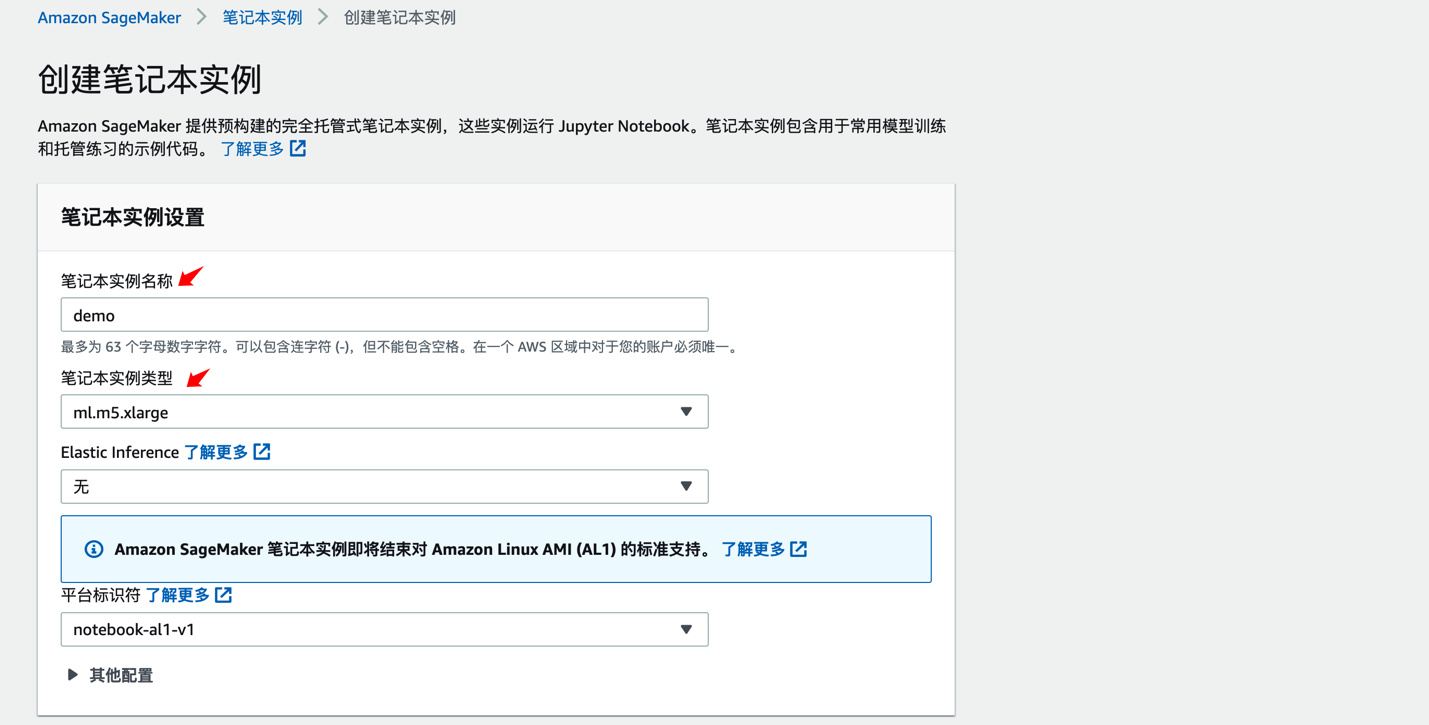
在 IAM 角色选项上选择【创建新角色】

点击【创建笔记本实例】创建 notebook

当笔记本实例状态变成 InService 后,点击【打开 JupyterLab】

由于asteroid依赖libsndfile是c++库,因此无论是jupyter instance,training container还是inference container,都需要预先取得sudo权限通过bash脚本安装。
在弹出的 jupyter 页面,依次选择 File – New – Terminal

输入:
运行完成后,在左侧可以看到如下文件层级:
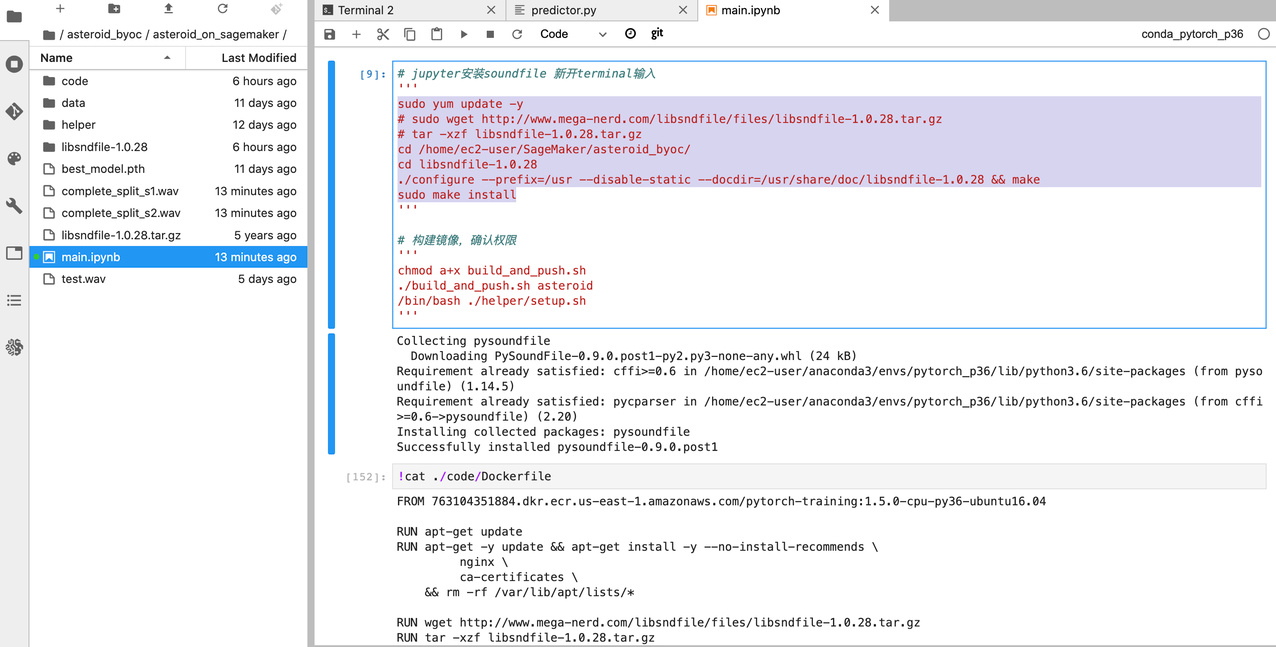
其中code是主要算法脚本文件,helper为辅助脚本文件,data是本地数据文件。该数据文件为dns4开源数据集加工而成,需要进行对应数据集以及json metadata的替换。libsndfile-1.0.28为用于读写音频文件的C语言库,main.ipynb为SageMaker 运行主脚本。
双击打开main.ipynb,根据提示在Terminal中输入:
来安装libsndfile
安装完成后,运行以下bash命令:
然后trigger training job。首先我们看一下train文件

可以看到文件描述,以及training_script位置指向code/train.py

在train.py中,我们加载./code/conf.yaml中的参数,然后设置DaraLoader, 通过pytorch lightening进行训练。

在训练任务触发后,可以在SageMaker控制台上看到训练配置信息与training instance的监控信息

训练完成后,在任务详情中点击output—S3 model artifact可以看到模型文件。

接下来进行部署操作
首先我们看一下serve文件

该脚本主要用于启动nginx,gunicorn,flask。主要推理脚本位于predictor.py
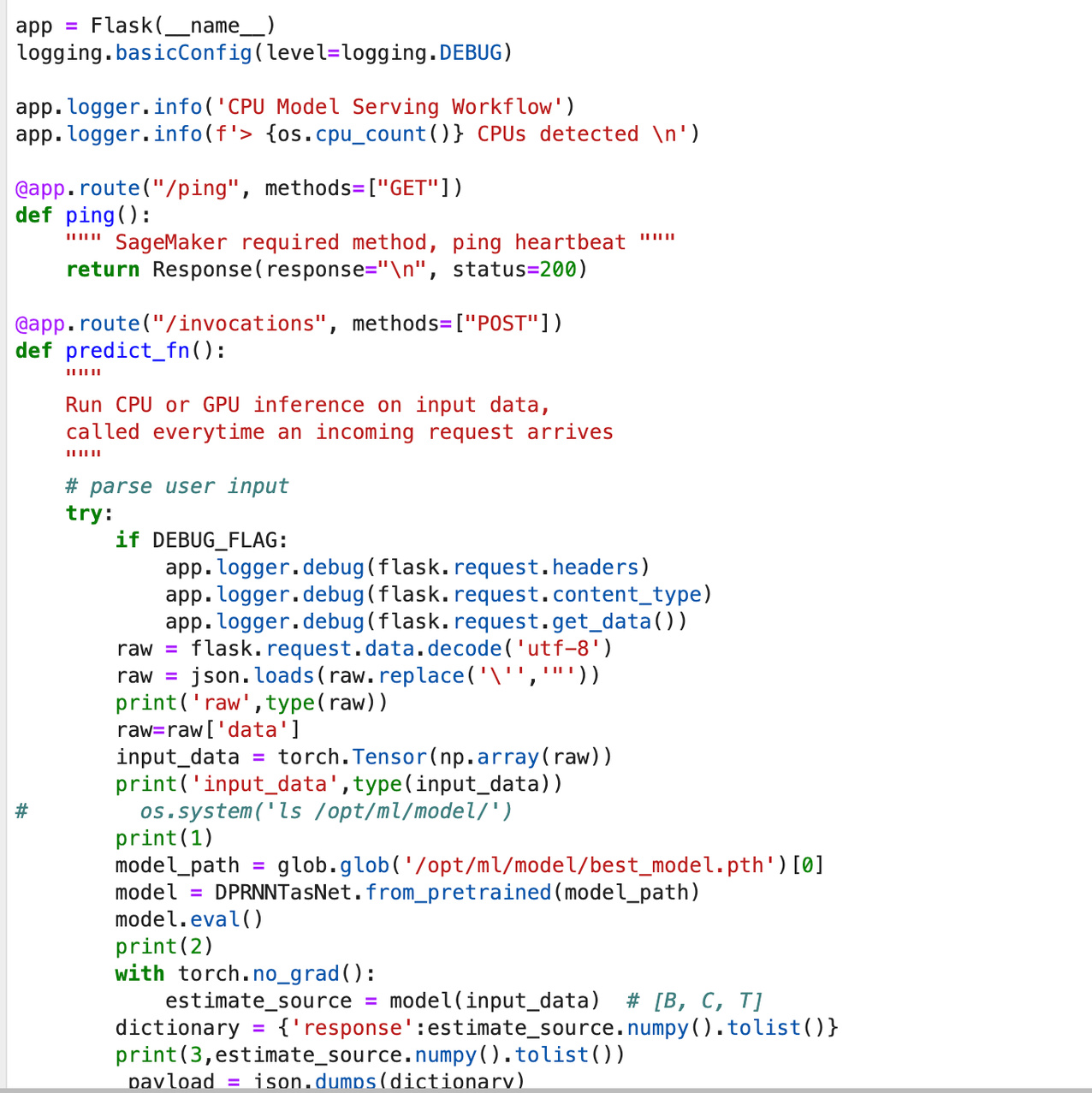
其中,ping function主要用于健康检查,predict_fn 接受 flask传入 request data, 进行推理并以json形式返回推理结果。
运行 main.ipynb deploy cell

部署完成后,在sagemaker控制台的Inference–Endpoint下可以看到推理的终端节点信息。

接下来调用endpoint进行推理。首先定义.wav 的读取与padding function。

通过boto3调用endpoint的代码如下:

在有限推理算力的情况下,我们可以采用批量clip语音文本与batch process 并行操作,batch predict function如下所示

推理完成后,在main.ipynb 路径下会生成 complete_split_s1.wav 与complete_split_s2.wav,我们成功了!
总结:在这篇blog中,我们以asteroid部署为例探索SageMaker自定义容器镜像的训练与推理一站式平台体验,算法采用DPRNN, 可以满足专业的语音分离任务要求。如果您想使用到Amazon SageMaker 的更多高级用法,需要对已有项目进行改造,比如支持实时推理、批量推理、断点重新训练,MLOps, serverless inference等,欢迎联系我们。