1.前言
AWS Well-Architected Framework 描述了用于在云中设计和运行工作负载的关键概念、设计原则和架构最佳实践。其中可持续性支柱作为目前 Well-Architected Framework 中的最新一员侧重于减少运行的云工作负载对环境的影响。在正确的时间以正确的数量提供正确的资源,以满足明确定义的业务需求。以Reuse,Recycle,Reduce,Rearchitect 四个方面为准则构建最佳架构。本系列博客将以在EKS上的部署Flink作业为例,通过 Karpenter, Spot, Graviton 等技术,遵循Reuse,Recycle,Reduce,Rearchitect 四大原则,从零开始构建最佳架构。

这一篇我们将介绍如何搭建EKS集群和 Karpenter 弹性伸缩工具,并添加Spot工作节点,运行 Flink作业。
- 遵循 Recycle 原则,通过Spot 实例实现云应用的交付和优化:
- Amazon EC2 Spot 实例让您可以利用 亚马逊云中的备用 EC2 容量,与按需实例相比,可享受高达 90% 的折扣。当这些实例即将被 Amazon EC2 回收时,Spot 实例会收到两分钟的警告。 有许多优雅的方式来处理中断,例如EC2 实例重新平衡建议,以便在 Spot 实例处于较高中断风险时发送主动通知。Spot 实例是扩展和增加大数据工作负载吞吐量的好方法,已被许多客户采用。
- 遵循 Reuse原则,结合 Karpenter 弹性伸缩工具最大限度地提高利用率和资源效率:
- EKS集群中根据不同应用的可用性要求,可能存在多组不同类型算力,例如相对固定的按需托管节点组,用于部署系统组件如集群弹性伸缩器本身等。如果没有特殊的隔离和稳定性要求,我们尽量先把现有节点填满,不够再由Karpenter动态快速拉起。
- Kapenter从15版本开始支持工作负载整合(consolidation),启用后将根据集群中的工作负载变化,自动寻找机会重新安排到未充分利用的节点上,最大限度复用现有算力,帮助提高利用率并降低集群计算成本。
总体架构如下所示:

架构概要说明:
1. 创建 EKS 集群时,添加一个托管按需节点组(默认一个节点),用于部署系统组件例如 EBS CSI 驱动程序等。
2. 借助 Karpenter 动态拉起 Flink 作业需要的计算资源,通过配置多个Provisioner,每个 Provisioner 设置不同 weight,实现精细化协同控制。
3. ARM 节点主动打上 Taints,配合使用 Tolerations,以确保 Flink 作业调度到合适的节点上。
4. 利用 docker buildx 工具一键打包 Multi-Arch 镜像并推送到镜像仓库。
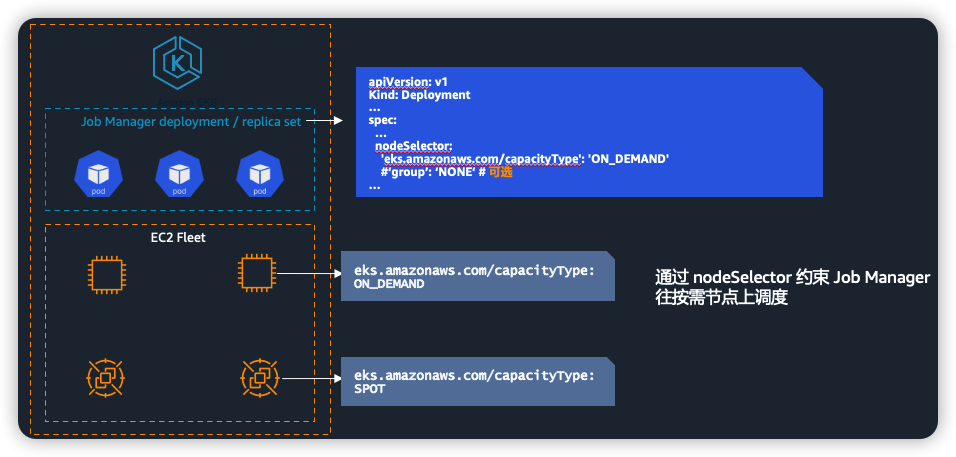
5. Flink Job Manager (Flink JM) 利用 nodeSelector 主动调度到由按需节点(包括部署系统组件的按需节点组和 Karpenter拉起的节点)。
6. Flink Task Manager (Flink TM) 默认不加任何限定条件(nodeSelector/ nodeAffinity),并且配置HPA(基于CPU)。当资源不够时,由 Provisioner 按优先级协调拉起合适节点。
7. 利用 Kinesis Data Generator 生成大量模拟数据,打到 Kinesis Data Stream 数据。随着数据的增加,配置了 HPA 的 Task Manager 自动弹出更多Pod。
8. Flink 作业启用检查点,并将作业检查点数据写入 S3,从而允许 Flink 保存状态并具备容错性。
9. 使用 Fault Injection Simulator 模拟 Spot 回收事件。
10. Node Termination Handler 配合 Spot,让应用运行更平稳。
2.搭建集群
2.1 准备基础资源
测试区域:美东(us-east-1)。
部署创建VPC,通过使用CloudFormation在实验环境中部署以下内容:
- 创建一个包含公有、私有子网的VPC
- 公有子网: 分别位于两个不同的可用区,该子网内的资源会暴露在互联网上,可被用户或客户端直接访问。用于部署NAT Gateway, 堡垒机,ELB负载均衡器等。
- 私有子网: 分别位于两个不同的可用区,该子网内的资源无法直接被互联网上的用户直接访问。用于部署Web应用服务器,中间件服务,数据库服务等无需直接暴露在互联网上的服务。
- 多个安全组: 用于控制EKS集群/EC2网络传入和传出流量。
- Cloud9实例: 用于管理和维护EKS集群。
- EKS管理角色:用做EKS集群的最高管理员。
首先下载模板:
https://raw.githubusercontent.com/BWCXME/cost-optimized-flink-on-kubernetes/main/cfn-infra.yaml
然后打开CloudFormation控制台https://us-east-1.console.aws.amazon.com/cloudformation/home?region=us-east-1#/。
上传刚刚下载的模板,输入堆栈名称,例如“eks-infra”:
# 定义CloudFormation模板名称,例如 eks-infra
CFN_NAME="eks-infra"
其他参数保持默认,点击创建,约等待 3~4 分钟即可创建完成。
2.2 配置Cloud9
堆栈创建完成后,切到“Outputs”,点击输出里的Cloud9链接进入。
或者通过 Cloud9 控制台:
https://us-east-1.console.aws.amazon.com/cloud9/home?region=us-east-1。

进入环境后,注意需要绑定EKS管理员角色。首先跳转到EC2控制台:

然后修改角色配置:

搜索“eks”,绑定到实例:

然后修改安全组配置,添加三个安全组后保存:
- ControlPlaneSecurityGroup
- SharedNodeSecurityGroup
- ExternalSecurityGroup

在Cloud9里新开一个终端,升级awscli命令行,接着取消临时凭证:
sudo mv /bin/aws /bin/aws1
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
/usr/local/bin/aws cloud9 update-environment --environment-id $C9_PID --managed-credentials-action DISABLE
rm -vf ${HOME}/.aws/credentials
定义堆栈名称,注意一定要和前面创建的CloudFormation堆栈名称保持一致:
# 定义CloudFormation模板名称
CFN_NAME="eks-infra"
更新环境变量和安装辅助工具:
# 更新环境变量
wget https://raw.githubusercontent.com/BWCXME/cost-optimized-flink-on-kubernetes/main/prepareCFNENVs.sh
chmod u+x prepareCFNENVs.sh
./prepareCFNENVs.sh ${CFN_NAME}
source ~/.bashrc
# 安装辅助工具
wget https://raw.githubusercontent.com/BWCXME/cost-optimized-flink-on-kubernetes/main/prepareCloud9IDE.sh
chmod u+x prepareCloud9IDE.sh
./prepareCloud9IDE.sh
source ~/.bashrc
2.3 生成SSH Key
生成SSH Key,方便后续有问题时,可以直接进入Worker节点进行调试:
#连续按3次回车
ssh-keygen -t rsa -b 4096
生成后导入:
aws ec2 import-key-pair --key-name "k8s" --public-key-material fileb://~/.ssh/id_rsa.pub
2.4 准备Flink节点权限
生成策略文件:
cat <<EoF > flink-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:*",
"firehose:*",
"kinesisanalytics:*",
"ec2:*",
"ec2messages:*",
"s3:*",
"s3-object-lambda:*",
"elasticfilesystem:*",
"logs:*",
"cloudwatch:*",
"autoscaling:*",
"sns:*",
"ssm:*",
"ssmmessages:*",
"lambda:*"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:ListPolicyVersions",
"iam:ListRoles",
"iam:PassRole"
],
"Resource": "*"
}
]
}
EoF
执行创建:
aws iam create-policy \
--policy-name flink-policy \
--policy-document file://flink-policy.json
2.5 创建EKS集群
指定EKS版本和集群名称到环境变量:
export EKS_VERSION=1.23
export EKS_CLUSTER_NAME=ekslab
export EKS_IP_FAMILY=IPv4
echo "export EKS_VERSION=\"$EKS_VERSION\"" >> ~/.bashrc
echo "export EKS_CLUSTER_NAME=\"$EKS_CLUSTER_NAME\"" >> ~/.bashrc
source ~/.bashrc
创建一个集群配置文件 flink-cluster.yaml:
cat > flink-cluster.yaml <<EOF
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: ${EKS_CLUSTER_NAME}
region: ${AWS_REGION}
version: "${EKS_VERSION}"
kubernetesNetworkConfig:
ipFamily: ${EKS_IP_FAMILY}
vpc:
id: "${EKS_VPC_ID}"
securityGroup: ${EKS_CONTROLPLANE_SG}
sharedNodeSecurityGroup: ${EKS_SHAREDNODE_SG}
clusterEndpoints:
publicAccess: true
privateAccess: true
subnets:
public:
public-${AWS_REGION}a:
id: "${EKS_PUB_SUBNET_01}"
public-${AWS_REGION}b:
id: "${EKS_PUB_SUBNET_02}"
public-${AWS_REGION}c:
id: "${EKS_PUB_SUBNET_03}"
private:
private-${AWS_REGION}a:
id: "${EKS_PRI_SUBNET_01}"
private-${AWS_REGION}b:
id: "${EKS_PRI_SUBNET_02}"
private-${AWS_REGION}c:
id: "${EKS_PRI_SUBNET_03}"
iam:
withOIDC: true
cloudWatch:
clusterLogging:
enableTypes: ["*"]
logRetentionInDays: 60
secretsEncryption:
keyARN: ${EKS_KEY_ARN}
managedNodeGroups:
- name: ondemand-x86-al2-cpu
amiFamily: AmazonLinux2
instanceTypes: [ "m5.xlarge" ]
minSize: 1
maxSize: 3
desiredCapacity: 1
volumeSize: 1000
volumeType: gp3
volumeEncrypted: true
ssh:
allow: true
publicKeyName: k8s
subnets:
- ${EKS_PRI_SUBNET_01}
- ${EKS_PRI_SUBNET_02}
- ${EKS_PRI_SUBNET_03}
updateConfig:
maxUnavailablePercentage: 33
labels:
os-distribution: amazon-linux-2
cpu-architecture: x86
network: private
group: managed
iam:
withAddonPolicies:
imageBuilder: true # Write access to ECR
cloudWatch: true # Allow workers to send data to CloudWatch
ebs: true
fsx: true
efs: true
externalDNS: true
certManager: true
attachPolicyARNs:
# Required by EKS workers
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
# For our Application
- arn:aws:iam::${ACCOUNT_ID}:policy/flink-policy
addons:
- name: vpc-cni
version: latest
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- name: coredns
version: latest # auto discovers the latest available
- name: kube-proxy
version: latest
- name: aws-ebs-csi-driver
EOF
执行创建:
eksctl create cluster -f flink-cluster.yaml
集群创建完成并添加第一个x86的节点组需要约20分钟左右,期间可以去两个控制台查看进度:
创建完成后,检查集群状态:
3.安装集群弹性伸缩器
Karpenter 是一个为 Kubernetes 构建的开源自动扩缩容项目。它提高了 Kubernetes 应用程序的可用性,而无需手动或过度配置计算资源。Karpenter 旨在通过观察不可调度的 Pod 的聚合资源请求并做出启动和终止节点的决策,以最大限度地减少调度延迟和基础设施成本。
3.1 添加标签
首先需要先给指定“子网”和“安全组”添加标签。
Karpenter 发现标记为 “kubernetes.io/cluster/$EKS_CLUSTER_NAME” 的子网。将此标签添加到为您的集群配置的关联子网。检索子网 ID 并使用集群名称标记它们。
子网打标签(这里示例选择私有子网):
aws ec2 create-tags \
--resources ${EKS_PRI_SUBNET_01} ${EKS_PRI_SUBNET_02} ${EKS_PRI_SUBNET_03} \
--tags Key="karpenter.sh/discovery,Value=${EKS_CLUSTER_NAME}"
Karpenter 拉起新节点时,自动挂上打了对应标签的安全组。这里示例,自动捞取现有节点组,然后标记集群中第一个节点组的安全组:
NODEGROUP=$(aws eks list-nodegroups --cluster-name ${EKS_CLUSTER_NAME} \
--query 'nodegroups[0]' --output text)
LAUNCH_TEMPLATE=$(aws eks describe-nodegroup --cluster-name ${EKS_CLUSTER_NAME} \
--nodegroup-name ${NODEGROUP} --query 'nodegroup.launchTemplate.{id:id,version:version}' \
--output text | tr -s "\t" ",")
# If your EKS setup is configured to use only Cluster security group, then please execute -
SECURITY_GROUPS=$(aws eks describe-cluster \
--name ${EKS_CLUSTER_NAME} --query "cluster.resourcesVpcConfig.clusterSecurityGroupId")
# If your setup uses the security groups in the Launch template of a managed node group, then :
SECURITY_GROUPS=$(aws ec2 describe-launch-template-versions \
--launch-template-id ${LAUNCH_TEMPLATE%,*} --versions ${LAUNCH_TEMPLATE#*,} \
--query 'LaunchTemplateVersions[0].LaunchTemplateData.[NetworkInterfaces[0].Groups||SecurityGroupIds]' \
--output text)
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${EKS_CLUSTER_NAME}" \
--resources ${SECURITY_GROUPS}
如果您有多个节点组或多个安全组,您可以手动指定,例如这里我们再加上共享安全组:
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${EKS_CLUSTER_NAME}" \
--resources ${EKS_SHAREDNODE_SG}
3.2 指定版本
截至到2022年9月初,最新版本为0.16.1:
export KARPENTER_VERSION=v0.16.1
echo "export KARPENTER_VERSION=\"$KARPENTER_VERSION\"" >> ~/.bashrc
source ~/.bashrc
3.3 准备Karpenter权限
首先通过CloudFormation模板,快捷创建KarpenterNode角色,并添加基础权限:
TEMPOUT=$(mktemp)
curl -fsSL https://karpenter.sh/"${KARPENTER_VERSION}"/getting-started/getting-started-with-eksctl/cloudformation.yaml > $TEMPOUT \
&& aws cloudformation deploy \
--stack-name "Karpenter-${EKS_CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${EKS_CLUSTER_NAME}"
增加Flink作业需要的额外权限:
aws iam attach-role-policy --policy-arn arn:aws:iam::${ACCOUNT_ID}:policy/flink-policy --role-name KarpenterNodeRole-${EKS_CLUSTER_NAME}
将 Karpenter 节点角色添加到您的 aws-auth configmap,允许具有此角色的节点连接到集群:
eksctl create iamidentitymapping \
--username system:node:{{EC2PrivateDNSName}} \
--cluster "${EKS_CLUSTER_NAME}" \
--arn "arn:aws:iam::${ACCOUNT_ID}:role/KarpenterNodeRole-${EKS_CLUSTER_NAME}" \
--group system:bootstrappers \
--group system:nodes
接着准备KarpenterController权限:
eksctl create iamserviceaccount \
--cluster "${EKS_CLUSTER_NAME}" --name karpenter --namespace karpenter \
--role-name "${EKS_CLUSTER_NAME}-karpenter" \
--attach-policy-arn "arn:aws:iam::${ACCOUNT_ID}:policy/KarpenterControllerPolicy-${EKS_CLUSTER_NAME}" \
--role-only \
--approve
export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${ACCOUNT_ID}:role/${EKS_CLUSTER_NAME}-karpenter"
3.4 准备Spot服务关联角色(可选)
仅当您第一次在账户中使用 EC2 Spot 时,才需要执行此步骤:
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
3.5 安装Karpenter
通过Helm快速安装:
helm repo add karpenter https://charts.karpenter.sh
helm repo update
helm upgrade --install --namespace karpenter --create-namespace \
karpenter karpenter/karpenter \
--version ${KARPENTER_VERSION} \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \
--set clusterName=${EKS_CLUSTER_NAME} \
--set clusterEndpoint=$(aws eks describe-cluster --name ${EKS_CLUSTER_NAME} --query "cluster.endpoint" --output json) \
--set aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${EKS_CLUSTER_NAME} \
--set defaultProvisioner.create=false \
--wait # for the defaulting webhook to install before creating a Provisioner
检查部署:
k get all -n karpenter
k logs -f deployment/karpenter -c controller -n karpenter
您也可以启用Debug日志,方便排查问题(此步骤可选):
k patch configmap config-logging -n karpenter --patch '{"data":{"loglevel.controller":"debug"}}'
3.6 部署Provisioner
Karpenter 0.16版本开始支持对多个Provisioner设置优先级,使用 “.spec.weight” 字段对Provisioner进行排序。我们可以更细粒度的进行协调控制:
- 配置多个Provisioner
- 设置不同优先级
- 动态调整优先级(例如集成Spot Placement Score,这里不做展开)
例如我们可以分别设置Spot和按需Provisioner,先优先尝试Spot Provisioner,Spot资源不足,拿不到再退回到按需Provisioner。
这里需要注意,Karpenter 不基于自动伸缩组管理,拉起的节点默认打上的标签与托管节点组有差异,例如区分按需和Spot的标签键值都不一样:

这里我们遵循 “Reuse” 原则,先填满托管节点组,然后到Karpenter现有节点并适时拉起新节点。为方便应用通过统一的标签识别 ,在Provisioner里手动指定2个标签:
- amazonaws.com/capacityType,值与托管节点组保持一致
- group,值设置为“NONE”,便于快速识别Karpenter节点
如果您希望保持简单,不要求最大化托管节点组利用率,或者计划后期通过手工调整托管节点组数量和机型,Flink 作业可以只使用 Kaprenter 节点。Karpenter 已经内置了优先选择 Spot 然后按需的机制,这样只需配置一个 Provisioner。同时注意不要设置eks.amazonaws.com/capacityType标签,因为拉起的节点可能是 Spot,也可能是按需。对于 Flink Job Manager 等必须使用按需实例的任务,只需利用 node selector 通过原生标签 karpenter.sh/capacity-type 指定即可。
可以利用别名(前面步骤安装辅助工具时设置),快速查看节点信息,有一列显示eks.amazonaws.com/capacityType,帮助快速识别节点资源类型:
创建x86 Provisioner配置文件 provisioner-x86.yaml:
cat > provisioner-x86.yaml <<EOF
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: x86-spot-provisioner
spec:
consolidation:
enabled: true
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
weight: 50 # 值越大,优先级越高
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.xlarge", "m5d.xlarge", "m5dn.xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["${AWS_REGION}a", "${AWS_REGION}b", "${AWS_REGION}c"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"] # arm64
kubeletConfiguration:
systemReserved:
cpu: 1
memory: 5Gi
ephemeral-storage: 10Gi
maxPods: 20
limits:
resources:
cpu: 1000
memory: 2000Gi
providerRef: # optional, recommended to use instead of provider
name: flink
labels:
eks.amazonaws.com/capacityType: 'SPOT'
cpu-architecture: x86
network: private
group: 'NONE'
---
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: x86-ondemand-provisioner
spec:
consolidation:
enabled: false
ttlSecondsAfterEmpty: 60
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
weight: 10 # 值越大,优先级越高
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.xlarge", "m5d.xlarge", "m5dn.xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["${AWS_REGION}a", "${AWS_REGION}b", "${AWS_REGION}c"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"] # arm64
kubeletConfiguration:
systemReserved:
cpu: 1
memory: 5Gi
ephemeral-storage: 10Gi
maxPods: 20
limits:
resources:
cpu: 1000
memory: 2000Gi
providerRef:
name: flink
labels:
eks.amazonaws.com/capacityType: 'ON_DEMAND'
cpu-architecture: x86
network: private
group: 'NONE'
---
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: flink
spec:
subnetSelector:
karpenter.sh/discovery: ${EKS_CLUSTER_NAME}
securityGroupSelector: # required, when not using launchTemplate
karpenter.sh/discovery: ${EKS_CLUSTER_NAME}
instanceProfile: KarpenterNodeInstanceProfile-${EKS_CLUSTER_NAME} # optional, if set in controller args
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 1000Gi
volumeType: gp3
iops: 10000
encrypted: true
deleteOnTermination: true
throughput: 125
EOF
执行部署:
k apply -f provisioner-x86.yaml
检查部署:
4.安装Node Termination Handler
Node Termination Handler是配合Spot使用的好搭档,有助于在Spot 实例中断、EC2 计划维护窗口或扩展事件期间让应用运行的更平稳。
Node Termination Handler有两种模式:
- 实例元数据服务(IMDS),在每个节点上运行一个 pod 来监控事件并采取相应措施。
- 队列处理器,使用 Amazon SQS 接收 Auto Scaling Group (ASG) 生命周期事件、EC2 状态更改事件、Spot 中断终止通知事件和 Spot 重新平衡建议事件。这些事件可以配置为发布到 Amazon EventBridge。
这里我们使用队列处理器模式,注意Karpenter 拉起的实例不属于任何Auto Scaling组,Auto Scaling Group 生命周期事件无需配置。
4.1 准备SQS队列
创建SQS队列:
export SQS_QUEUE_NAME="nth"
QUEUE_POLICY=$(cat <<EOF
{
"Version": "2012-10-17",
"Id": "NTHQueuePolicy",
"Statement": [{
"Effect": "Allow",
"Principal": {
"Service": ["events.amazonaws.com", "sqs.amazonaws.com"]
},
"Action": "sqs:SendMessage",
"Resource": [
"arn:aws:sqs:${AWS_REGION}:${ACCOUNT_ID}:${SQS_QUEUE_NAME}"
]
}]
}
EOF
)
## make sure the queue policy is valid JSON
echo "$QUEUE_POLICY" | jq .
## Save queue attributes to a temp file
cat << EOF > /tmp/queue-attributes.json
{
"MessageRetentionPeriod": "300",
"Policy": "$(echo $QUEUE_POLICY | sed 's/\"/\\"/g' | tr -d -s '\n' " ")"
}
EOF
aws sqs create-queue --queue-name "${SQS_QUEUE_NAME}" --attributes file:///tmp/queue-attributes.json
获取队列URL和ARN,并输出到变量:
export SQS_QUEUE_URL=$(aws sqs get-queue-url --queue-name ${SQS_QUEUE_NAME} | jq -r '.QueueUrl')
export SQS_QUEUE_ARN=$(aws sqs get-queue-attributes --queue-url ${SQS_QUEUE_URL} --attribute-names QueueArn | jq -r '.Attributes.QueueArn')
4.2 定义事件
通过以下命令快速创建(您也可以通过EventBridge在控制台创建):
aws events put-rule \
--name NTHASGTermRule \
--event-pattern "{\"source\":[\"aws.autoscaling\"],\"detail-type\":[\"EC2 Instance-terminate Lifecycle Action\"]}"
aws events put-targets --rule NTHASGTermRule \
--targets "Id"="1","Arn"=${SQS_QUEUE_ARN}
aws events put-rule \
--name NTHSpotTermRule \
--event-pattern "{\"source\": [\"aws.ec2\"],\"detail-type\": [\"EC2 Spot Instance Interruption Warning\"]}"
aws events put-targets --rule NTHSpotTermRule \
--targets "Id"="1","Arn"=${SQS_QUEUE_ARN}
aws events put-rule \
--name NTHRebalanceRule \
--event-pattern "{\"source\": [\"aws.ec2\"],\"detail-type\": [\"EC2 Instance Rebalance Recommendation\"]}"
aws events put-targets --rule NTHRebalanceRule \
--targets "Id"="1","Arn"=${SQS_QUEUE_ARN}
aws events put-rule \
--name NTHInstanceStateChangeRule \
--event-pattern "{\"source\": [\"aws.ec2\"],\"detail-type\": [\"EC2 Instance State-change Notification\"]}"
aws events put-targets --rule NTHInstanceStateChangeRule \
--targets "Id"="1","Arn"=${SQS_QUEUE_ARN}
aws events put-rule \
--name NTHScheduledChangeRule \
--event-pattern "{\"source\": [\"aws.health\"],\"detail-type\": [\"AWS Health Event\"],\"detail\": {\"service\": [\"EC2\"],\"eventTypeCategory\": [\"scheduledChange\"]}}"
aws events put-targets --rule NTHScheduledChangeRule \
--targets "Id"="1","Arn"=${SQS_QUEUE_ARN}
4.3 准备NTH权限
创建策略并进行关联:
# 配置IAM策略
cat <<EoF > /tmp/nth-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:CompleteLifecycleAction",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeTags",
"ec2:DescribeInstances",
"sqs:DeleteMessage",
"sqs:ReceiveMessage"
],
"Resource": "*"
}
]
}
EoF
aws iam create-policy \
--policy-name nth-policy \
--policy-document file:///tmp/nth-policy.json
# 把IAM Role和SA关联起来
eksctl create iamserviceaccount \
--name nth \
--namespace kube-system \
--cluster ${EKS_CLUSTER_NAME} \
--attach-policy-arn "arn:aws:iam::${ACCOUNT_ID}:policy/nth-policy" \
--approve \
--override-existing-serviceaccounts
# 查看并确认
k -n kube-system describe sa nth
4.4 部署NTH
生成配置文件:
cat > nth-values.yaml<<EOF
enableSqsTerminationDraining: true
queueURL: "${SQS_QUEUE_URL}"
awsRegion: "${AWS_REGION}"
serviceAccount:
create: false
name: nth
checkASGTagBeforeDraining: false # <-- set to false as instances do not belong to any ASG
enableSpotInterruptionDraining: true
enableRebalanceMonitoring: true
enableRebalanceDraining: true
enableScheduledEventDraining: true
EOF
执行部署:
helm repo add eks https://aws.github.io/eks-charts
helm upgrade --install aws-node-termination-handler \
--namespace kube-system \
-f nth-values.yaml \
eks/aws-node-termination-handler
检查部署:
k get po -n kube-system -l k8s-app=aws-node-termination-handler
5.部署Flink
Flink 本身具备一定的容错能力,可以利用检查点来恢复流中的状态和位置,前提是:
- 持久数据源(Apache Kafka、Amazon Kinesis)能够重放数据
- 持久分布式存储(Amazon S3、EFS、HDFS)以存储状态

Job Manager 和 Task Manager 是 Flink 的关键组件:
- Task Manager计算密集型,可以跑在Spot实例上;
- Job Manager是中央协调器,建议运行在按需实例上。
数据流如下所示:

实验代码仓库:
https://github.com/BWCXME/cost-optimized-flink-on-kubernetes
5.1 准备镜像
拉取代码:
cd ~/environment
git clone https://github.com/BWCXME/cost-optimized-flink-on-kubernetes flink-demo
cd flink-demo
创建仓库:
aws ecr create-repository --repository-name flink-demo --image-scanning-configuration scanOnPush=true
登录仓库:
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com
打包x86镜像并推送到镜像仓库:
docker build --tag ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest .
docker push ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
5.2 准备Flink Service Account
增加Flink作业需要的额外权限:
export FLINK_SA=flink-service-account
kubectl create serviceaccount $FLINK_SA
kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=default:$FLINK_SA
echo "export FLINK_SA=\"$FLINK_SA\"" >> ~/.bashrc
source ~/.bashrc
5.3 准备输入/输出
创建Kinesis输入流并保存名称到环境变量:
export FLINK_INPUT_STREAM=FlinkDemoInputStream
aws kinesis create-stream \
--stream-name ${FLINK_INPUT_STREAM} \
--shard-count 3
echo "export FLINK_INPUT_STREAM=\"${FLINK_INPUT_STREAM}\"" >> ~/.bashrc
source ~/.bashrc
创建输出S3桶并保留名称到环境变量:
export FLINK_S3_BUCKET=flink-${ACCOUNT_ID}
aws s3 mb s3://${FLINK_S3_BUCKET}
echo "export FLINK_S3_BUCKET=\"${FLINK_S3_BUCKET}\"" >> ~/.bashrc
source ~/.bashrc
5.4 提交任务 (YAML)
您即可以通过明确定义YAML文件来部署,也可以利用命令行快捷部署。这里演示我们用YAML文件。
准备目录:
生成配置文件:
cat > flink-configuration-configmap.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
kubernetes.cluster-id: flink-demo
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: s3a://${FLINK_S3_BUCKET}/recovery
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 100000
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 1
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
queryable-state.proxy.ports: 6125
jobmanager.memory.process.size: 2048m
taskmanager.memory.process.size: 2048m
scheduler-mode: reactive
parallelism.default: 4
rest.flamegraph.enabled: true
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = DEBUG
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = \${sys:log.file}
appender.rolling.filePattern = \${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
EOF
参考Flink Kubernetes高可用部署文档,这里我们通过nodeSelector,强制往按需节点上调度,同时遵循“Reuse”原则,托管节点组或者Karpenter拉起的按需节点都可以。

如果您希望限定到没有自动伸缩组的节点(由Karpenter拉起),请手动添加到后面生成的jobmanager-application-ha.yaml:
nodeSelector:
'group': 'NONE'
生成jobmanager部署文件:
cat > jobmanager-application-ha.yaml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: flink-jobmanager
spec:
parallelism: 1 # Set the value to greater than 1 to start standby JobManagers
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
serviceAccountName: ${FLINK_SA}
nodeSelector:
'eks.amazonaws.com/capacityType': 'ON_DEMAND'
restartPolicy: OnFailure
containers:
- name: jobmanager
image: ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
imagePullPolicy: Always
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
args: ["standalone-job", "--host", "\$(POD_IP)","--job-classname", "com.amazonaws.services.kinesisanalytics.S3StreamingSinkJob","--inputStreamName", "${FLINK_INPUT_STREAM}", "--region", "${AWS_REGION}", "--s3SinkPath", "s3a://${FLINK_S3_BUCKET}/data", "--checkpoint-dir", "s3a://${FLINK_S3_BUCKET}/recovery"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
serviceAccountName: flink-service-account # Service account which has the permissions to create, edit, delete ConfigMaps
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
EOF
对于Task Manager,这里演示我们遵循“Reuse”原则,不加 nodeSelector或nodeAffinity,保证充分利用现有计算资源。
如果您需要限定托管按需节点组优先部署集群管理相关组件,或者稳定性要求高的应用,可以参考以下配置,让 Task Manager优先运行在 Karpenter 拉起的节点上:

我们通过设置nodeAffinity 让 task manager 优先放置在的 Karpenter拉起的实例上(如果需要,请手动添加到后面生成的taskmanager-job-deployment.yaml):
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
preference:
matchExpressions:
- key: group
operator: In
values:
- NONE
生成taskmanager部署文件:
cat > taskmanager-job-deployment.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
serviceAccountName: ${FLINK_SA}
containers:
- name: taskmanager
image: ${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest
imagePullPolicy: Always
resources:
requests:
cpu: 250m
memory: "4096Mi"
limits:
cpu: 500m
memory: "8192Mi"
env:
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
- containerPort: 6125
name: query-state
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.properties
EOF
准备服务部署文件:
cat > jobmanager-svc.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanager
---
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-web
annotations:
service.beta.kubernetes.io/aws-load-balancer-security-groups: "${EKS_EXTERNAL_SG}"
spec:
type: LoadBalancer
ports:
- name: web
port: 80
targetPort: 8081
selector:
app: flink
component: jobmanager
EOF
注意这里为了方便测试,使用LoadBalancer将服务暴露出来,并且绑定了安全组ExternalSecurityGroup,请确保:
- 这个安全组允许您的本机IP访问80端口。
- 如果您修改了暴露端口80,例如用的8081,请相应在安全组中放开8081端口。
执行部署(请先确认在x86目录下):
检查部署:
一开始Job Manager和Task Manager都是处于Pending状态,等待Karpenter拉起机器。
拉起速度很快,一分钟左右就开始创建容器了。

获取服务地址:
k get svc flink-jobmanager-web
拿到地址后在浏览器中打开,类似如下:

5.6 提交任务 (命令行)
目前 flink 1.13+ 以上 支持 pod 模板,我们可以自定义JM跟TM的启动方式。这允许直接支持 Flink Kubernetes 配置选项不支持的高级功能。
定义任务名称:
export kubernetes_cluster_id=your-flink-job-name
使用参数 kubernetes.pod-template-file 指定包含 pod 定义的本地文件。它将用于初始化 JobManager 和 TaskManager。平台化这里可以作为高级功能开放给用户。
指定 job manager 运行在按需节点上 :
cat > jobmanager-pod-template.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: jobmanager-pod-template
spec:
nodeSelector:
'eks.amazonaws.com/capacityType': 'ON_DEMAND'
EOF
使用命令行提交任务, 注意指定参数 kubernetes.pod-template-file.jobmanager:
flink run-application -p 2 -t kubernetes-application \
-Dkubernetes.cluster-id=${kubernetes_cluster_id} \
-Dkubernetes.container.image=${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/flink-demo:latest \
-Dkubernetes.container.image.pull-policy=Always \
-Dkubernetes.jobmanager.service-account=flink-service-account \
-Dkubernetes.pod-template-file.jobmanager=./jobmanager-pod-template.yaml \
-Dkubernetes.rest-service.exposed.type=LoadBalancer \
-Dkubernetes.rest-service.annotations=service.beta.kubernetes.io/aws-load-balancer-security-groups:${EKS_EXTERNAL_SG} \
-Dhigh-availability=org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory\
-Dhigh-availability.cluster-id=${kubernetes_cluster_id} \
-Dhigh-availability.storageDir=s3://${FLINK_S3_BUCKET}/recovery \
-Dstate.savepoints.dir=s3://${FLINK_S3_BUCKET}/savepoints/${kubernetes_cluster_id} \
-Dkubernetes.taskmanager.service-account=flink-service-account \
-Dkubernetes.taskmanager.cpu=1 \
-Dtaskmanager.memory.process.size=4096m \
-Dtaskmanager.numberOfTaskSlots=2 \
local:///opt/flink/usrlib/aws-kinesis-analytics-java-apps-1.0.jar \
--inputStreamName ${FLINK_INPUT_STREAM} --region ${AWS_REGION} --s3SinkPath s3://${FLINK_S3_BUCKET}/data --checkpoint-dir s3://${FLINK_S3_BUCKET}/recovery
注意:设置命令行参数时请注意对照代码配置:
https://github.com/BWCXME/cost-optimized-flink-on-kubernetes/blob/main/src/main/java/com/amazonaws/services/kinesisanalytics/S3StreamingSinkJob.java
例如,代码中已经指定检查点间隔为10秒,无需在命令行重复设置 “-Dexecution.checkpointing.interval”。
我们同样可以通过设置 nodeAffinity 让 task manager 优先放置在的 Karpenter 拉起的实例上。
准备 task manager 的 pod 模板(主容器应使用名称 flink-main-container 定义,不可改变):
cat > taskmanager-pod-template.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: taskmanager-pod-template
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
preference:
matchExpressions:
- key: group
operator: In
values:
- NONE
containers:
# Do not change the main container name
- name: flink-main-container
env:
- name: HADOOP_USER_NAME
value: "hdfs"
EOF
然后在提交任务时,通过参数 -Dkubernetes.pod-template-file.taskmanager=/path/taskmanager-pod-template.yaml 指定即可:
-Dkubernetes.pod-template-file.taskmanager=./taskmanager-pod-template.yaml
总结
在本文中,我们遵循 AWS Well-Architected Framework 的可持续性支柱,从 Reuse 角度,在 EKS 上部署 Flink 容器化应用,并结合 Karpenter 弹性伸缩工具最大限度地提高利用率和资源效率。从 Recycle 的角度,再利用 Spot 实例实现云应用的交付和优化。
参考文档
Optimizing Apache Flink on Amazon EKS using Amazon EC2 Spot Instances:
https://aws.amazon.com/blogs/compute/optimizing-apache-flink-on-amazon-eks-using-amazon-ec2-spot-instances/
本篇作者