亚马逊AWS官方博客
使用 Amazon Glue Data Quality 创建高质量的 ETL 管道
目前有几十万客户使用数据湖进行分析和机器学习。不过,数据工程师必须先清理和准备这些数据,之后才能使用它们。基础数据必须准确且最新,以便客户自信地做出业务决策。否则,数据使用者将失去对数据的信任,并做出不理想的或错误的决策。评估数据是否准确且最新是数据工程师的一项常见任务。虽然目前提供了多种数据质量工具,但常见的数据质量工具通常需要实施手动流程来监控数据质量。
Amazon Glue Data Quality 自动监测功能是 AWS Glue 的一项预览功能,可用于测量和监控 Amazon Simple Storage Service(Amazon S3)数据湖以及 AWS Glue 提取、转换、加载(ETL)作业中的数据质量。这是一项开放性的预览功能,已在您账户的可用区域中启用。您可以在 AWS Glue Studio 控制台中轻松定义和测量数据质量检查,而无需编写代码。它简化了管理数据质量的体验。
这篇文章是一个文章系列(共 4 篇文章)的第 2 部分,旨在说明 Amazon Glue Data Quality 自动监测功能的工作原理。查看该文章系列的上一篇文章:
Amazon Glue Data Quality 自动监测功能入门
|
在这篇文章中,我们不仅说明如何创建 AWS Glue 作业来衡量和监控数据管道的数据质量,还将说明如何根据数据质量结果来采取措施。
解决方案概览
让我们考虑一个示例使用案例,其中,数据工程师需要构建数据管道,以便将数据从原始区域提取到数据湖中的精选区域。作为数据工程师,除了负责提取、转换和加载数据之外,您还主要负责验证数据质量。预先识别数据质量问题可帮助您防止将不良数据放置在精选区域内,并避免出现严重的数据损坏事件。
在这篇文章中,您将了解如何在 AWS Glue 作业中轻松设置内置和自定义数据验证检查,以防止不良数据损坏下游的高质量数据。
本文中使用的数据集是综合生成的;以下屏幕截图显示了数据示例。

使用 AWS CloudFormation 设置资源
这篇文章包含一个用于快速设置的 AWS CloudFormation 模板。您可以查看并自定义此模板以满足自己的需求。
CloudFormation 模板会生成以下资源:
- 一个 Amazon Simple Storage Service(Amazon S3)存储桶(
gluedataqualitystudio-*)。 - S3 存储桶中的以下前缀和对象:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS Identity and Access Management(IAM)用户、角色和策略IAM 角色(
GluedataQualityStudio-*)有权在 S3 存储桶中进行读取和写入。 - AWS Lambda 函数以及这些函数创建和删除此堆栈所需的 IAM policy。
要创建您的资源,请完成以下步骤:
- 在
us-east-1区域中登录到 AWS CloudFormation 控制台。 - 选择 Launch Stack(启动堆栈):

- 选择 I acknowledge that AWS CloudFormation might create IAM resources(我确认 AWS CloudFormation 可以创建 IAM 资源)。
- 选择 Create stack(创建堆栈)并等待堆栈创建步骤完成。

实施解决方案
要开始配置您的解决方案,请完成以下步骤:
- 在 AWS Glue Studio 控制台上,在导航窗格中选择 Jobs(作业)。

- 选择 Visual with a blank canvas(带空画布的视觉效果),然后选择 Create(创建)。

- 选择 Job Details(作业详细信息)选项卡以配置作业。

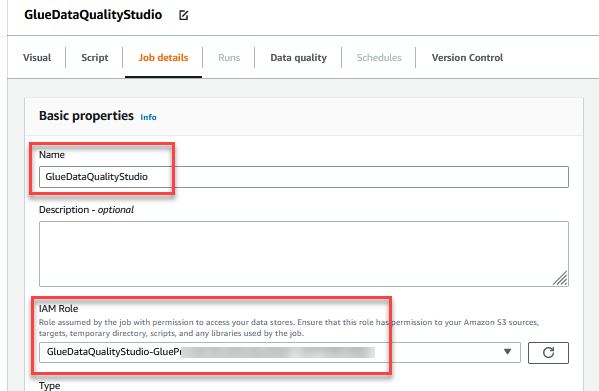
- 对于 Name(名称),请输入
GlueDataQualityStudio。 - 对于 IAM Role(IAM 角色),请选择以
GlueDataQualityStudio-*开头的角色。 - 对于 Glue version(Glue 版本),请选择 Glue 3.0。
- 对于 Job bookmark(作业书签),请选择 Disable(禁用)。这可让您使用相同的输入数据集来多次运行此作业。
- 对于 Number of retries(重试次数),请输入
0。

- 在 Advanced properties(高级属性)部分中,提供由 CloudFormation 模板创建的 S3 存储桶(以
gluedataqualitystudio-*开头)。
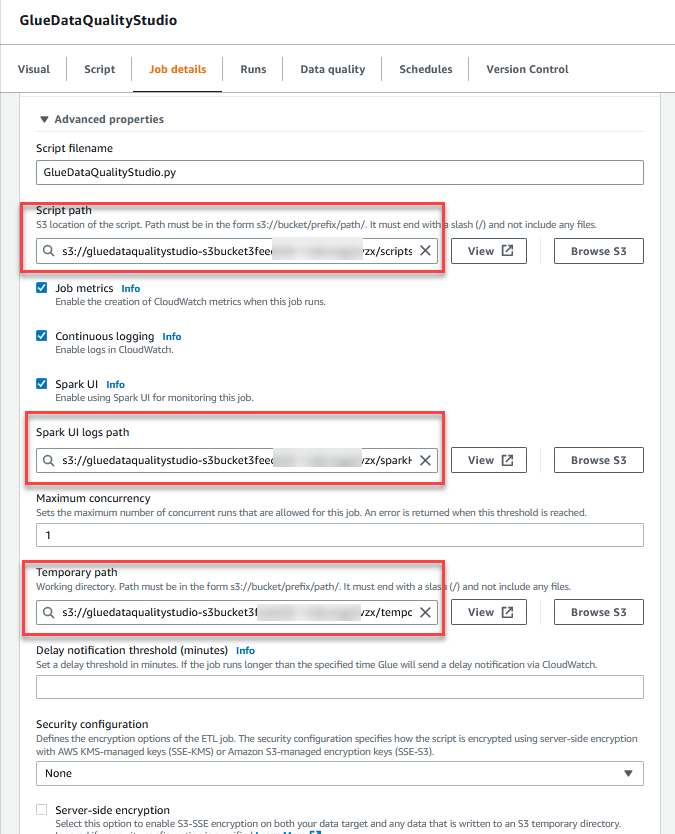
- 选择 Save(保存)。

- 保存作业后,选择 Visual(可视对象)选项卡,然后在 Source(源)菜单上选择 Amazon S3。
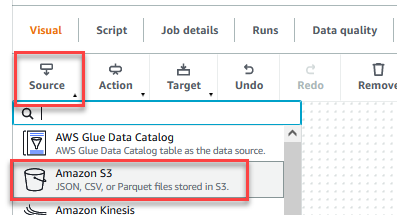
- 在 Data source properties – S3(数据来源属性 – S3)选项卡上,对于 S3 source type(S3 源类型),选择 S3 location(S3 位置)。
- 选择 Browse S3(浏览 S3)并导航到以
gluedataqualitystudio-*开头的 S3 存储桶中的前缀/datalake/raw/customer/。 - 选择 Infer schema(推断架构)。

- 在 Action(操作)菜单上,选择 Evaluate Data Quality(评估数据质量)。
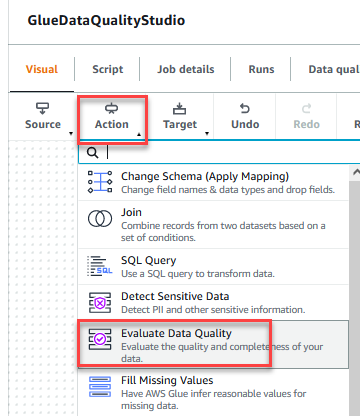
- 选择 Evaluate Data Quality(评估数据质量)节点。

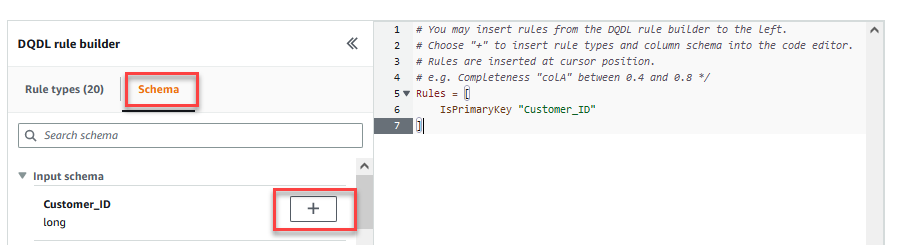
在 Transform(转换)选项卡上,您现在可以开始构建数据质量规则。您创建的第一条规则是使用isPrimaryKey规则检查Customer_ID是否唯一且不为空。 - 在 DQDL rule builder(DQDL 规则生成器)的 Rule types(规则类型)选项卡上,搜索
isprimarykey并选择加号。

- 在 DQDL rule builder(DQDL 规则生成器)的 Schema(架构)选项卡上,选择
Customer_ID旁边的加号。 - 在规则编辑器中,删除
id。
我们添加的下一个规则将检查所有行是否都存在First_Name列值。 - 您也可以直接在规则编辑器中输入数据质量规则。在第一个规则后面添加逗号(,),然后输入
IsComplete "First_Name",。

接下来,添加一个自定义规则来验证是否不存在不包含Telephone或Email的行。 - 在规则编辑器中输入以下自定义规则:

评估数据质量功能提供了根据作业质量结果来管理作业成果的操作。 - 在这篇文章中,选择 Fail job when data quality fails(在数据质量未达到要求时使作业失败)和 Fail job without loading target data(在不加载目标数据的情况下使作业失败)操作。在 Data quality output setting(数据质量输出设置)部分中,选择 Browse S3(浏览 S3),并导航到以
gluedataqualitystudio-*开头的 S3 存储桶中的前缀dqresults。

- 在 Target(目标)菜单上,选择 Amazon S3。

- 选择 Data target – S3 bucket(数据目标 – S3 存储桶)节点。
- 在 Data target properties – S3(数据目标属性 – S3)选项卡上,对于 Format(格式),选择 Parquet,对于 Compression Type(压缩类型),选择 Snappy。
- 对于 S3 Target Location(S3 目标位置),选择 Browse S3(浏览 S3),并导航到以
gluedataqualitystudio-*开头的 S3 存储桶中的前缀/datalake/curated/customer/。

- 选择 Save(保存),然后选择 Run(运行)。
 您可以在 Runs(运行)选项卡上查看作业运行详细信息。在我们的示例中,作业失败并显示错误消息 AssertionError: The job failed due to failing DQ rules for node: <node>(AssertionError:由于未满足节点 <node> 的 DQ 规则,作业失败)。
您可以在 Runs(运行)选项卡上查看作业运行详细信息。在我们的示例中,作业失败并显示错误消息 AssertionError: The job failed due to failing DQ rules for node: <node>(AssertionError:由于未满足节点 <node> 的 DQ 规则,作业失败)。
 您可以在 Data quality(数据质量)选项卡上查看数据质量结果。在我们的示例中,自定义数据质量验证失败,因为数据集中的某个行不具有
您可以在 Data quality(数据质量)选项卡上查看数据质量结果。在我们的示例中,自定义数据质量验证失败,因为数据集中的某个行不具有 Telephone或Email值。 评估数据质量结果也将基于节点的数据质量结果位置参数以 JSON 格式写入 S3 存储桶。
评估数据质量结果也将基于节点的数据质量结果位置参数以 JSON 格式写入 S3 存储桶。 - 导航到以
gluedataqualitystudio-*开头的 S3 存储桶下的前缀dqresults。您将看到数据质量结果按日期进行了分区。

以下是 JSON 文件的输出。您可以使用此文件输出来构建自定义数据质量可视化控制面板。

您也可以通过 Amazon CloudWatch 指标监控 Evaluate Data Quality(评估数据质量)节点,并设置警报以发送有关数据质量结果的通知。要了解有关如何设置 CloudWatch 警报的更多信息,请参阅使用 Amazon CloudWatch 警报。

清理
为了避免将来产生费用并清理未使用的角色和策略,请删除您创建的资源:
- 删除您在这篇文章中创建的
GlueDataQualityStudio作业。 - 在 AWS CloudFormation 控制台上,删除
GlueDataQualityStudio堆栈。
小结
利用 Amazon Glue Data Quality 自动监测功能,可以轻松测量和监控 ETL 管道数据质量。在这篇文章中,您已了解如何根据数据质量结果来采取必要措施,这有助于您保持较高的数据标准并自信地做出业务决策。
要了解有关 Amazon Glue Data Quality 自动监测功能的更多信息,请查看文档:
- 使用 AWS Glue Studio 评估数据质量
- Amazon Glue Data Quality 自动监测功能(预览版)
- 要深入了解 Amazon Glue Data Quality 自动监测功能 API,请查看文档:数据质量自动监测功能 API
关于作者
 Deenbandhu Prasad 是 AWS 的一位高级分析专家,专门从事大数据服务。他热衷于帮助客户在 AWS Cloud 上构建现代数据架构。他已帮助各种规模的客户实施数据管理、数据仓库和数据湖解决方案。
Deenbandhu Prasad 是 AWS 的一位高级分析专家,专门从事大数据服务。他热衷于帮助客户在 AWS Cloud 上构建现代数据架构。他已帮助各种规模的客户实施数据管理、数据仓库和数据湖解决方案。
 Yannis Mentekidis 是 AWS Glue 团队的高级软件开发工程师。
Yannis Mentekidis 是 AWS Glue 团队的高级软件开发工程师。