亚马逊AWS官方博客
关于Amazon EKS中Service和Ingress深入分析和研究
一、背景介绍
在使用Amazon EKS的过程中,暴露容器化的服务(各种类型的协议),经常会碰到Kubernetes Service和Ingress。它们具体适用的场景和特点是什么了?比如IoT场景下的服务暴露,使用那种方式比较适合了?这里和业务场合相关,也和Service和Ingress技术实现有很大关联。那细节上它们具体是如何实现的了?本文将主要讨论Amazon EKS中Service和Ingress的具体实现细节。知道这些细节后,我们能做出更好的取舍。
这里有一个典型的场景,对于一些应用的某些部分,比如常说的前端,可能希望将其暴露给 Amazon EKS集群外部的IP地址,Kubernetes Service和Ingress是常见的两种方式。对于Kubernetes Service允许指定你所需要的Service Tyeps(类型)。Service Types的可能的选项以及具体的特性如下:
(1) ClusterIP: 通过集群的内部IP(虚拟IP/VIP)暴露服务,选择此选项时服务只能够在集群内部访问。 这也是默认的Service类型。
(2) NodePort: 通过每个节点(worker node)上的IP和静态端口(NodePort)暴露服务。 NodePort服务会路由到自动创建的ClusterIP服务。 通过请求<节点 IP>:<节点端口>,你可以从集群的外部访问一个NodePort服务。
(3)LoadBalancer: 使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的NodePort服务和 ClusterIP 服务上。
(4) ExternalName:通过返回CNAME和对应值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。 无需创建任何类型代理。
说明:你需要使用kube-dns 1.7及以上版本或者 oreDNS 0.0.8 及以上版本才能使用 ExternalName 类型。
另外,你也可以使用 Ingress 来暴露服务。 Ingress 不是一种Service Tyeps(类型),但它充当集群提供的服务的入口。 它可以将路由规则整合到一个资源中,因为它可以在同一IP地址下公开多个服务。
上面对Service Tyeps(类型)和Ingress做了大致的介绍,但是你理解它具体是如何实现的吗?又如何根据他的特点来选择和配置呢?接下来我们来讨论Service (ClusterIP, NodePort, LoadBalancer)和Ingress。
二、准备知识
在分析和研究Service 和Ingress之前,让我们先温顾一下ISO OSI 7层模型和TCP/IP 4层模型。另外还有就是Linux的network stack以及netfilter 和iptables。因为这些都是我们来分析和研究Service和Ingress的前提知识。
1) ISO OSI 7层模型和TCP/IP 4层模型

开放系统互连模型(ISO OSI 7层模型)是一个概念模型,它对电信或计算系统的通信功能进行了描述和标准化,不考虑其潜在的内部结构和技术。它的目标是使不同的通信系统与标准通信协议具有互操作性。
传输控制协议/互联网协议模型(TCP/IP 4层模型)是指一套管理像以太网这样的IP网络中设备之间通信的规则。它是以一系列的层来实现的。为什么要分层?层允许我们处理复杂的系统,将问题分离成各个组成部分,然后以模块化的方式处理它。这种模块化使系统能够被维护和更新,而不会给系统的其他部分带来麻烦。
ISO OSI 7层模型和TCP/IP 4层模型有如上图的的对应关系。如上各层的信息,可以参考以下的link:
https://en.wikipedia.org/wiki/OSI_model
2) Linux Network Stack

上图主要反映Linux Network Stack的层次结构。Linux内核由几个重要部分组成,其中包括进程管理、内存管理、硬件设备驱动、文件系统驱动、网络管理和其他各种部分。其中最大的特性之一是它的网络堆栈(Network Stack),它最初起源于BSD的网络堆栈,有一个非常简洁的界面,而且组织良好。它的接口范围从与协议无关的层(如一般套接字层接口或设备层)到各种网络协议的特定层。请注意其中的Netfilter层。
下图是详细的发送者和接受者之间的数据传输路径(图片来之 https://www.cs.cornell.edu/~qizhec/paper/tcp_2021.pdf )

3) netfilter 和iptables

netfilter官网对netfilter 和iptables有很好介绍和说明,具体如下:
什么是netfilter项目?
netfilter项目是一个社区驱动的协作性的FOSS(开源免费软件)项目,为Linux 2.4.x及以后的内核系列提供包过滤软件。netfilter项目通常与iptables和它的后继者nftables有关。
netfilter项目实现了数据包过滤、网络地址[和端口]转换(NA[P]T)、数据包记录、用户空间数据包排队和其他数据包处理。
iptables是一个通用的防火墙软件,允许你定义规则集。iptables内的每个规则由一些分类器(iptables匹配)和一个连接动作(action)或iptables目标(target)组成。留意这里的action和target.
netfilter主要特点
(1)无状态数据包过滤(IPv4和IPv6)
(2)有状态数据包过滤(IPv4和IPv6
(3)各种网络地址和端口转换,如NAT/NAPT(IPv4和IPv6)。
(4)灵活和可扩展的基础设施
(5)用于第三方扩展的多层次的API
根据如上的内容,netfilter提供的是一个数据包过滤的框架,而iptables只是通过定义的规则集来调用这个框架的工具。所以我们经常使用的工具为iptables。
在netfilter框架中过滤的流程图,来至于https://en.wikipedia.org/wiki/Netfilter
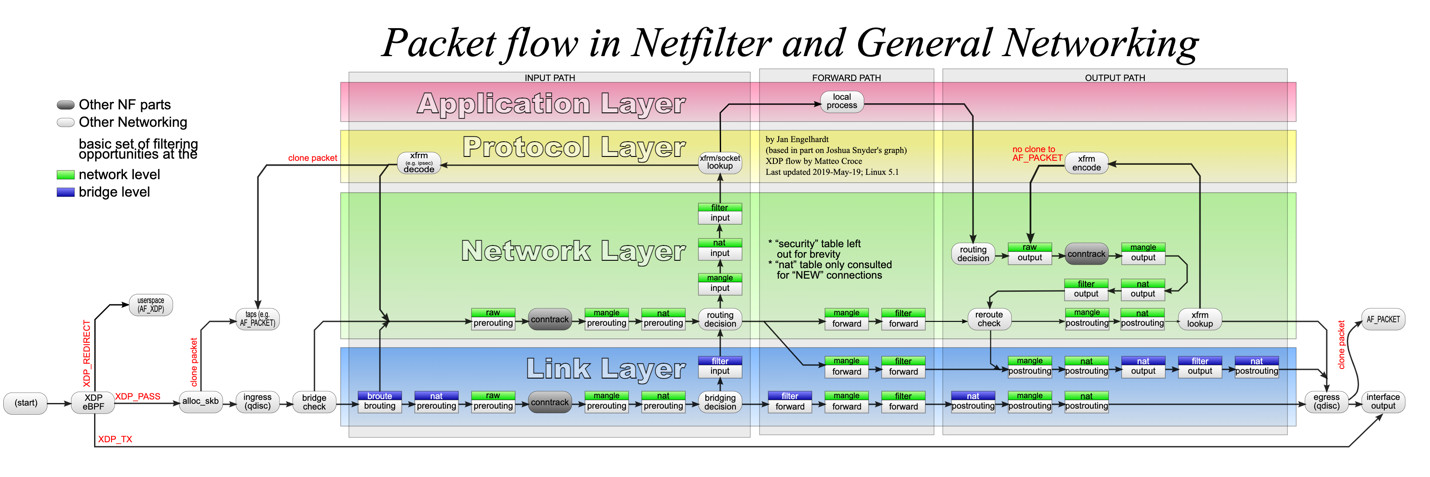
上面是详细版本数据包流程图,下面给一个笔者制作的简易易于理解的流程图:
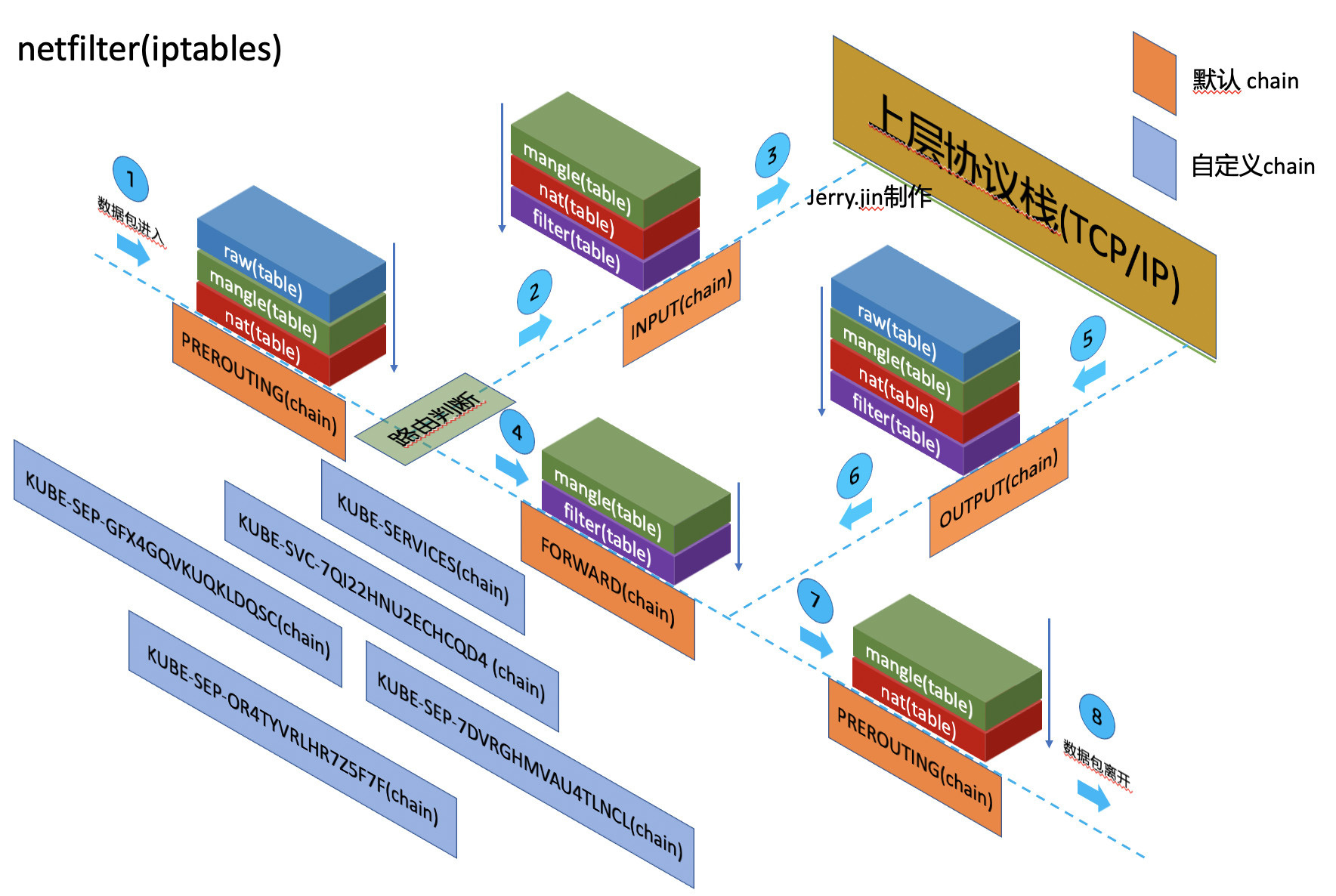
当我们说iptables,什么是链和表了?经常会说道四表五链。那具体是什么了?如上图
从数据包的角度,进入到Linux Network Stack中的netfilter环节,扮演成网络防火墙的netfilter会根据设定规则来过滤这些数据包,比如拒绝掉ping请求(ICMP包)。这些规则就组织成了形如链的结构–“规则链”。这些链用预定义的标题来命名,五链包括PREROUTING, INPUT, OUTPUT, FORWARD和POSTROUTING。这些链的标题有助于描述netfilter堆栈中的位置和起源。例如,数据包的接收属于PREROUTING,而INPUT代表本地交付的数据,转发的流量则属于FORWARD链。本地产生的输出通过OUTPUT链,而要发送出去的数据包则在POSTROUTING链。另外,链中规则还可以执行自己定义的规则(放置于自定义链中),这就使额外的处理和迭代成为可能。Kubernetes Service中大量使用了自定义链。
但一条链上有了太多的规则后,如何对这些规则进行管理是个问题。我们可以将具有相同功能的规则集合放在一起,这里就形成了表。iptables已经默认定义了四张表。它们分别是filter, nat, raw, mangle。每个表的引入都是为了服务于一个特定的目的, 就netfilter而言,它以特定的顺序相对于其他表运行一个特定的表,比如上图中的PREROUTING链中表的执行顺序就是raw,mangle和nat。这四表的功能如下:
(1)filter表:负责过滤功能,防火墙;内核模块:iptables_filter
(2)nat表:network address translation,网络地址转换功能;内核模块:iptable_nat
(3)mangle表:拆解报文,做出修改,并重新封装 的功能;内核模块:iptable_mangle
(4)raw表:关闭nat表上启用的连接追踪机制;内核模块:iptable_raw
因为iptables中表和链的关系刚接触理解起来是比较繁琐的,所以建议看如下的博客,写的比较通俗易懂 https://www.zsythink.net/archives/tag/iptables/page/2
三、Service和Ingress分析和研究
1) 准备实验环境
此处使用亚马逊云科技的宁夏区域,使用如下的yaml文件,通过eksctl创建EKS集群,具体创建步骤方法可以参考github链接 — https://github.com/jerryjin2018/AWS-China-EKS-Workshop-2021/blob/main/Lab1:%20Create%20an%20EKS%20cluster%20through%20eksctl.md
本次分析和研究用的yaml文件在如下的连接中https://github.com/jerryjin2018/service_ingress/tree/main/code
eksgo05-cluster.yaml
查看新建集群的状态:
kubectl get nodes

2) 检查每个worker node上iptables中四表的状态

因为iptables命令就是按照参数-t[表名]来展示规则的。默认是filter表。登陆到其中一台worker node上
2.1)检查filter表
iptables -t filter -vnL | grep ^Chain && iptables -t filter -vnL | grep ^Chain | wc -l

filter表处理有默认的链,还有自定义的链,如KUBE-SERVICES等。共12条链。
2.2)检查nat表
iptables -t nat -vnL | grep ^Chain && iptables -t nat -vnL | grep ^Chain | wc -l

nat表处理有默认的链,还有自定义的链,如KUBE-SERVICES等。共32条链。
2.3)检查raw表
iptables -t raw -vnL | grep ^Chain && iptables -t raw -vnL | grep ^Chain | wc -l

raw表处理有默认的链。
2.4)检查mangle表
iptables -t mangle -vnL | grep ^Chain && iptables -t mangle -vnL | grep ^Chain | wc -l

mangle表处理有默认的链,还有自定义的链,如KUBE-PROXY-CANARY等。共7条链。
2.5)给node group中增加一个node,看新的node上的iptables中四表的状态
查看目前node group中node的数量
aws eks describe-nodegroup --cluster-name eksgo05 --nodegroup-name ng-eksgo05-01 | jq .nodegroup.scalingConfig

增加一个node
aws eks update-nodegroup-config --cluster-name eksgo05 --nodegroup-name ng-eksgo05-01 --scaling-config minSize=1,maxSize=8,desiredSize=4

再次检查node group的
aws eks describe-nodegroup --cluster-name eksgo05 --nodegroup-name ng-eksgo05-01 | jq .nodegroup.scalingConfig

kubectl get nodes

登陆到这个新增加的worker node上,我们会发现iptables的四张表中的链,包括自定义链(在准备知识中已经解释了)的数量和名称都是一样的,也就是说,默认情况下,所有worker node上的iptables的规则定义是一样,这个和笔者以前了解的分布式的SDN的实现方式是一致的。
将node group仍然调整为3个nodes,具体命令为
aws eks update-nodegroup-config --cluster-name eksgo05 --nodegroup-name ng-eksgo05-01 --scaling-config minSize=1,maxSize=8,desiredSize=3
3) 分析Service类型是ClusterIP的场景
3.1)创建类型为ClusterIP的Service和测试的Deployment, testenv_clusterip.yaml
kubectl apply -f testenv_cluster.yaml && kubectl get service -n net-test
3.2)检查ClusterIP的Service和对应的nat表中的链
查看创建的类型为ClusterIP的Service对应deployment中的pod

nat表中的链有iptable默认定义的链(PREROUTING,INPUT,OUTPUT,POSTROUTING)
在测试机器上执行kubectl,我们可以看到我们刚刚创建的名为nginx-service-clusterip 的service,目前为ClusterIP的类型(TYPE),而且它的CLUSTER-IP地址为10.100.87.207,端口为8080/TCP,也就是通过 nginx-service(10.100.87.207)的8080端口可以访问到target(pod的80端口)
再查看service名为nginx-service-clusterip中的细节以及endpoints和endpointslices clusterip
kubectl describe service/nginx-service-clusterip -n net-test
kubectl get endpoints -n net-test
kubectl describe service/nginx-service-clusterip -n net-test
kubectl describe endpointslices.discovery.k8s.io/nginx-service-clusterip-kzkhp -n net-test

登陆到其中一台worker node上查看iptables 规则,其实在3个worker node上的iptables -t nat -vnL结果基本一样,只是Chain KUBE-SERVICES中具体的规则的顺序不一样



nat表中的链有iptable默认定义的链(PREROUTING,INPUT,OUTPUT,POSTROUTING),来检查CLUSTER IP — 10.100.87.207。我们会发现10.100.87.207 在自定义链 KUBE-SERVICES中定义一条规则,具体如下,并且应用的target/action是KUBE-SVC-7QI22HNU2ECHCQD4
iptables -t nat -vnL | grep -i "10.100.87.207" -B 8

那我们来检查自定义链 KUBE-SERVICES 和 KUBE-SVC-7QI22HNU2ECHCQD4
iptables -t nat -vnL | grep -i "Chain KUBE-SVC-7QI22HNU2ECHCQD4 " -A 5

此处需要介绍一下 iptables statistic 模块https://ipset.netfilter.org/iptables-extensions.man.html

很显然,通过 statistic 模块达到负载均衡的效果,但是这里是3个worker node,如果是4个或是10个pod,情况会是如何的了?那我们先将pod扩展到4个。
kubectl get deployments.apps -n net-test -o wide
kubectl get pod -n net-test -o wide
kubectl scale deployments.apps/nginx-deployment --replicas=4 -n net-test
kubectl get deployments.apps/nginx-deployment -n net-test

再来看看iptables 自定义链 KUBE-SVC-7QI22HNU2ECHCQD4。正如你所见到的,自定义链 KUBE-SVC-7QI22HNU2ECHCQD4的条目发生了变化,它根据增加的pod,而调整了statistic模块 mode random probability后面的值。
扩展到4个pod的情况
iptables -t nat -vnL | grep -i "Chain KUBE-SVC-7QI22HNU2ECHCQD4 " -A 5

扩展到10个pod的情况
iptables -t nat -vnL | grep -i "Chain KUBE-SVC-7QI22HNU2ECHCQD4 " -A 12

总结下来,当你扩展pod副本的数量后,Amazon EKS /K8S 会在自定义链 KUBE-SVC-7QI22HNU2ECHCQD4 中定义n条额外的自定义链,n的数量等于pod replicas的数量,每一条自定义链后面的statistic模块 mode random probability后面的值的规律是:
1/n
1/(n-1)
1/(n-2)
…
1/3
1/2
先缩回3个pod,继续分析自定义链 — KUBE-SEP-GFX4GQVKUQKLDQSC, KUBE-SEP-7DVRGHMVAU4TLNCL, KUBE-SEP-OR4TYVRLHR7Z5F7F

扩展到10个pod的情况
iptables -t nat -vnL | grep -i "Chain KUBE-SEP-GFX4GQVKUQKLDQSC" -A 4
iptables -t nat -vnL | grep -i "Chain KUBE-SEP-7DVRGHMVAU4TLNCL" -A 4
iptables -t nat -vnL | grep -i "Chain KUBE-SEP-OR4TYVRLHR7Z5F7F" -A 4

那DNAT和MARK target/action意义是什么了?如下的官方文档的介绍。DNAT就是对数据包中的目的地址做NAT(地址转换),也就是访问到CLUSTER-IP地址10.100.87.207后,会被负载均衡到后端的pod上,而MARK则是给指定的数据包做标识


到这里,对于Service类型是ClusterIP的场景分析结束,ClusterIP就是通过Cluster-IP的虚拟IP(VIP),结合iptables中的自定义链加上statistic模块和DNAT来做轻量的负载均衡。结合之前的数据包流程图:

这里,你可能会问为什么没有走nat表,而不是走raw表或是mangle表。其实还是这里主要需要实现地址转换(NAT)。数据包在netfilter/iptables中nat表走的链如下:

4) 分析Service类型是NodePort的场景

4.1)创建类型为NodePort的Service和测试的Deployment, testenv_nodeport.yaml
4.2)检查NodePort的Service和对应的nat表中的链
nat表中的链有iptable默认定义的链(PREROUTING,INPUT,OUTPUT,POSTROUTING)
在测试机器上执行kubectl,我们可以看到我们刚刚创建的名为nginx-service-nodeport 的service,目前为NodePort的类型(TYPE),而且它的CLUSTER-IP地址为10.100.127.14,对的它也有CLUSTER-IP,它的端口是8080:32060/TCP。也就是通过 nginx-service-nodeport(worker node)的32060端口可以访问到target(pod的80端口)
再查看service名为nginx-service- nodeport中的细节以及endpoints和endpointslices
kubectl get service -n net-test
kubectl get endpoints -n net-test
kubectl get endpointslices.discovery.k8s.io -n net-test
kubectl describe service/nginx-service-nodeport -n net-test

大家很容易想到使用Node Port,为了确保能访问到pod,一定是发生了nat(网络地址翻译),所以我们来查看nat表。nat表中的链有iptable默认定义的链(PREROUTING,INPUT,OUTPUT,POSTROUTING),逻辑上数据包进入到linux network stack,是先到PREROUTING链,再结合 iptables -t nat -vnL 输出中在4条链(PREROUTING,INPUT,OUTPUT,POSTROUTING)内容的观察,也会直接查看PREROUTING链的规则。PREROUTING链的target/action还是自定义链 KUBE-SERVICES。接下来还是查看自定义链 KUBE-SERVICES中定义一条规则,具体如下:
iptables -t nat -vnL | grep PREROUTING -A 3
iptables -t nat -vnL | grep "Chain KUBE-SERVICES" -A 10

尽管其中有一个条规则,它的destination 是10.100.127.14,但是我们现在创建的service的类型是nodeport,也就意味一定是通过worker node的端口(port)进入到worker node,也就是一定通过了worker node的ip地址,不论是primary ip,还是secondary ip.
这里有一个iptables的addrtype模块,具体功能如下:
netstat -ntupl| head -n 2 && netstat -ntupl | grep -i 32060
 我们可以看到worker node的端口32060是被kube-proxy监听,而且是监听了worker node上所有的ip地址。所以进入到worker node的端口32060的数据包匹配的是 KUBE-SERVICES 中 KUBE-NODEPORTS 自定义链。
我们可以看到worker node的端口32060是被kube-proxy监听,而且是监听了worker node上所有的ip地址。所以进入到worker node的端口32060的数据包匹配的是 KUBE-SERVICES 中 KUBE-NODEPORTS 自定义链。
iptables -t nat -vnL | grep "Chain KUBE-NODEPORTS" -A 4
iptables -t nat -vnL | grep "Chain KUBE-SVC-NUUJACZKM4EFI6UZ" -A 5

那KUBE-NODEPORTS 自定义链包含的具体规则是什么了?如大家可以看到的,自定义链 KUBE-MARK-MASQ 对数据包mark。另外的自定义链 KUBE-SVC-NUUJACZKM4EFI6UZ ,让我们记住这个自定义链 KUBE-SVC-NUUJACZKM4EFI6UZ

到这里,大家又看到类似ClusterIP又做了负载均衡。
我们来看看自定义链 KUBE-SERVICES 中destination 是10.100.127.14的规则, 它的target/action也是自定义链 KUBE-SVC-NUUJACZKM4EFI6UZ。所以在iptables 的规则的角度,NodePort变相的使用了ClusterIP(的规则),而不是直接使用ClusterIP的ip地址。

至此,对于Service类型是NodePort的场景分析结束,NodePort就是通过worker node上的kube-proxy将流量引入iptables,结合addrtype模块将数据包再次转到ClusterIP的处理规则上来。进而在结合statistic模块和DNAT来做轻量的负载均衡。具体的在iptables中nat表走的链如下:

5) 分析Service类型是LoadBalancer的场景
Service类型是LoadBalancer的场景,根据yaml文件中Service参数的不同,会创建不同类型的Amazon ELB
5.1)创建类型为LoadBalancer(CLB模式)
创建类型为LoadBalancer的Service和测试的Deployment, testenv_lb_1.yaml, 注意创建Service的部分没有annotation字段
5.2)检查LoadBalancer的Service(CLB模式)
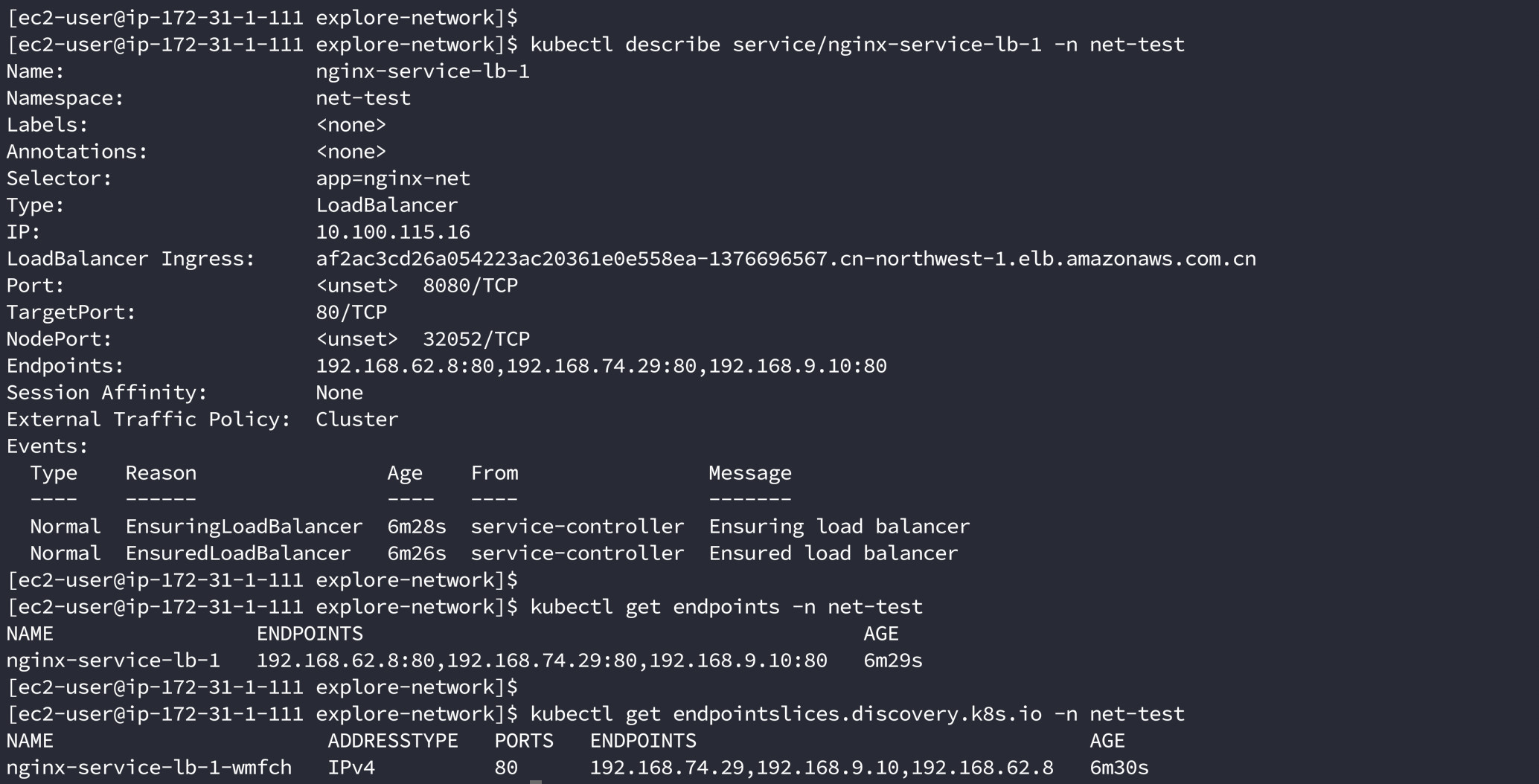
在测试机器上执行kubectl,我们可以看到我们刚刚创建的名为nginx-service-lb-1 的service,目前为LoadBalancer的类型(TYPE),而且它的CLUSTER-IP地址为10.100.115.16,对的它也有CLUSTER-IP,它的端口是8080:32052/TCP。也就是通过 nginx-service-lb-1(也就是Amazon ELB)将数据包分发到 worker node的32052端口可以访问到target(pod的80端口)。注意到这里的EXTERNAL-IP就是Amazon ELB的地址。

再查看service名为nginx-service-lb-1中的细节以及endpoints和endpointslices
kubectl describe service/nginx-service-lb-1 -n net-test
kubectl get endpoints -n net-test
kubectl get endpointslices.discovery.k8s.io -n net-test
我们再到亚马逊云科技的console查看ELB,可以看到在这里创建的是CLB(Classic Load Balancer)

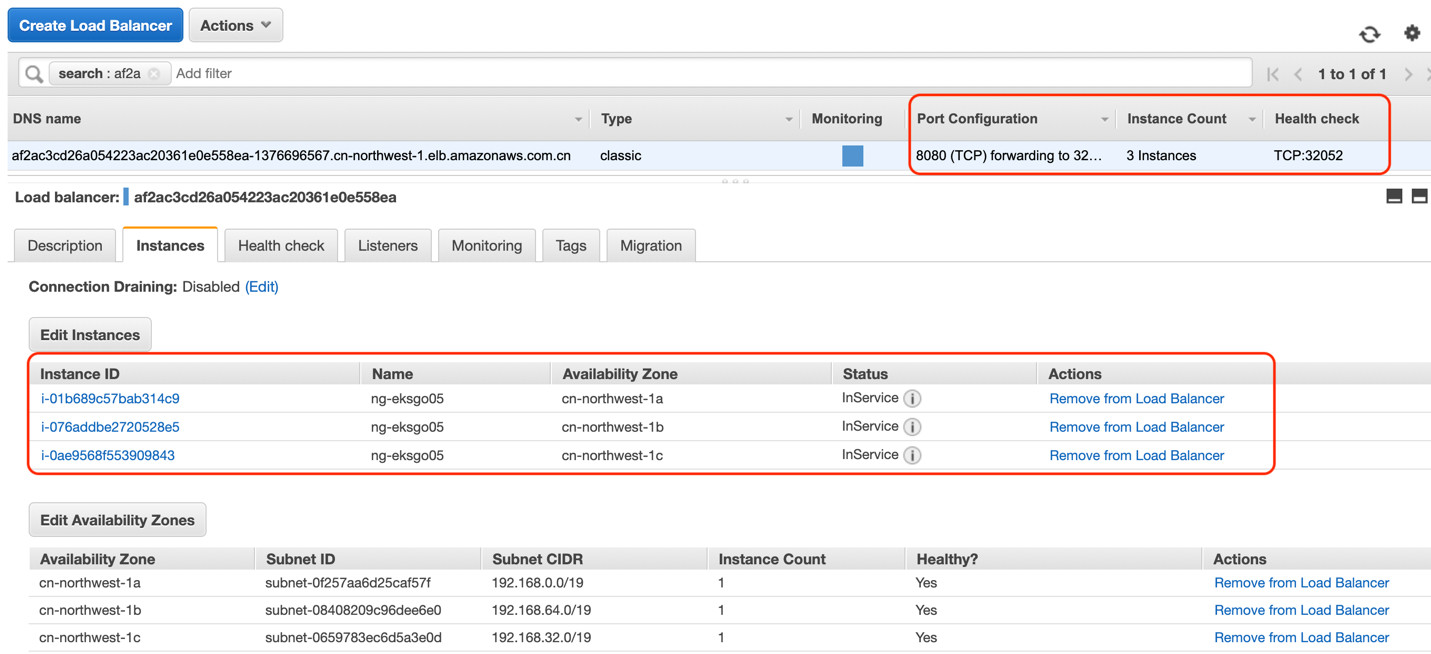
其实当数据包由亚马逊云科技的CLB转发到3个worker node的端口,数据包处理的逻辑和过程和NodePort没有什么本质的差别。此处不再赘述。
5.3) 创建类型为LoadBalancer(NLB instance模式)
创建类型为LoadBalancer的Service和测试的Deployment, testenv_lb_2.yaml, 注意创建Service的部分的annotation字段

其实这次创建的名为nginx-service-lb-2的service和之前创建的nginx-service-lb-1 的service很相似。显示内容基本相同,只是在亚马逊云科技的console查看ELB是显示为NLB。

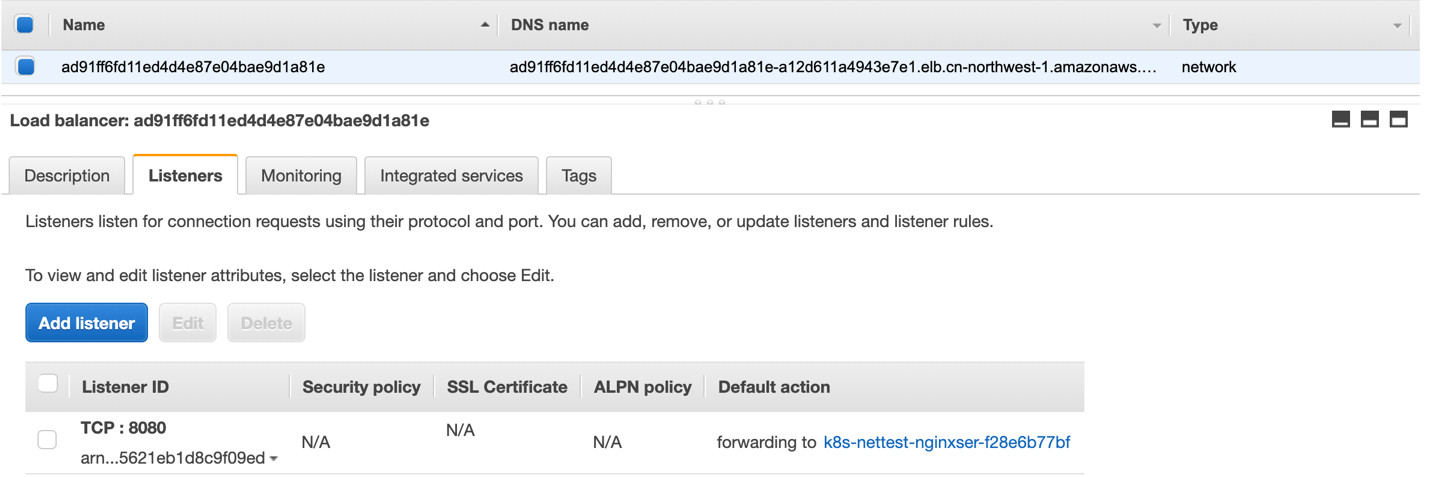
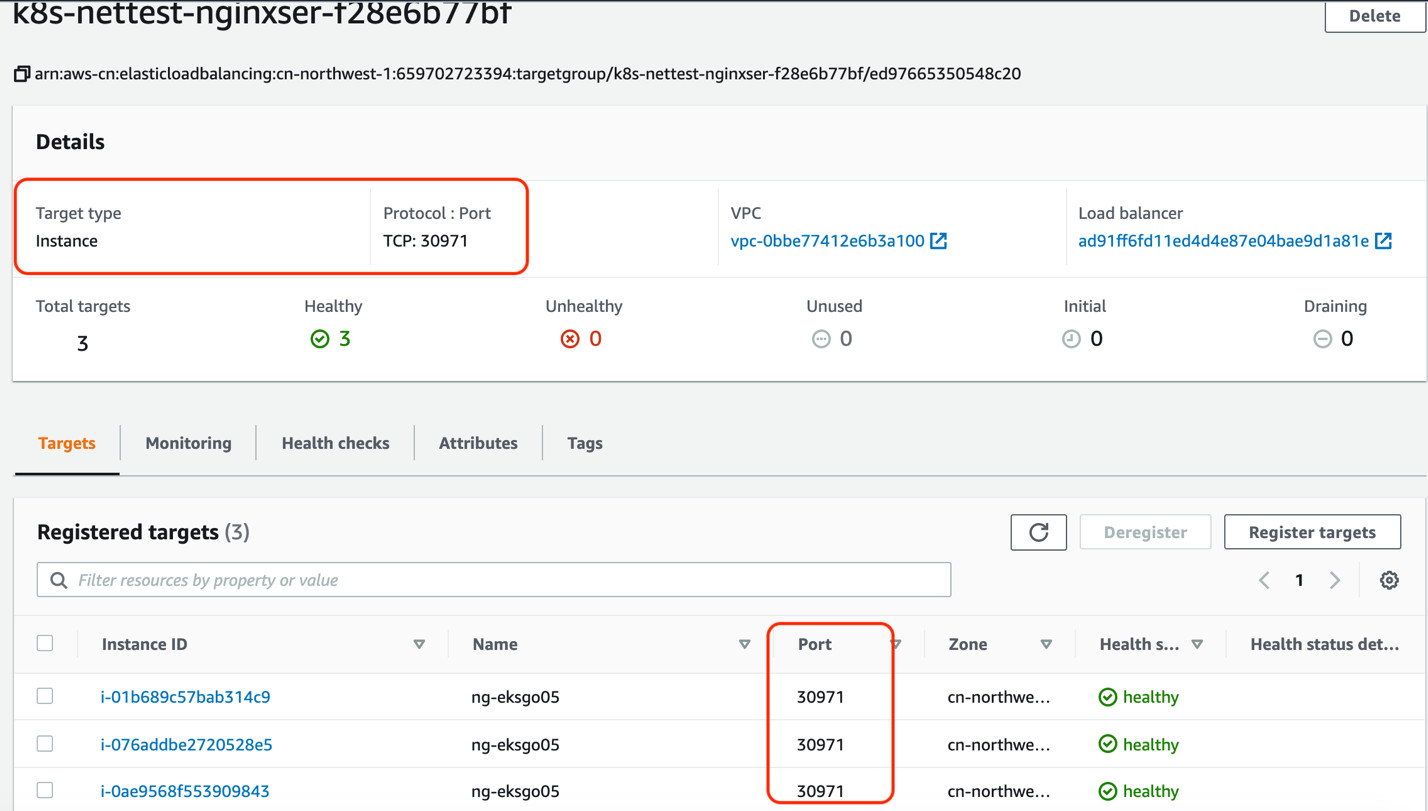
其实这次创建的名为nginx-service-lb-2的service和之前创建的nginx-service-lb-1 的service很相似。显示内容基本相同,只是在亚马逊云科技的console查看ELB是显示为NLB。这里就是NLB的instance模式。当数据包由亚马逊云科技的NLB转发到3个worker node的端口,数据包处理的逻辑和过程和NodePort没有什么本质的差别。此处也不再描述
5.4) 创建类型为LoadBalancer(NLB ip模式)
创建类型为LoadBalancer的Service和测试的Deployment, testenv_lb_3.yaml, 注意创建Service的部分的annotation字段
而这次创建的名为nginx-service-lb-3的service和之前创建的nginx-service-lb-2 的service也很相似。也只是在亚马逊云科技的console查看ELB也显示为NLB。但是这里为ip 模式。


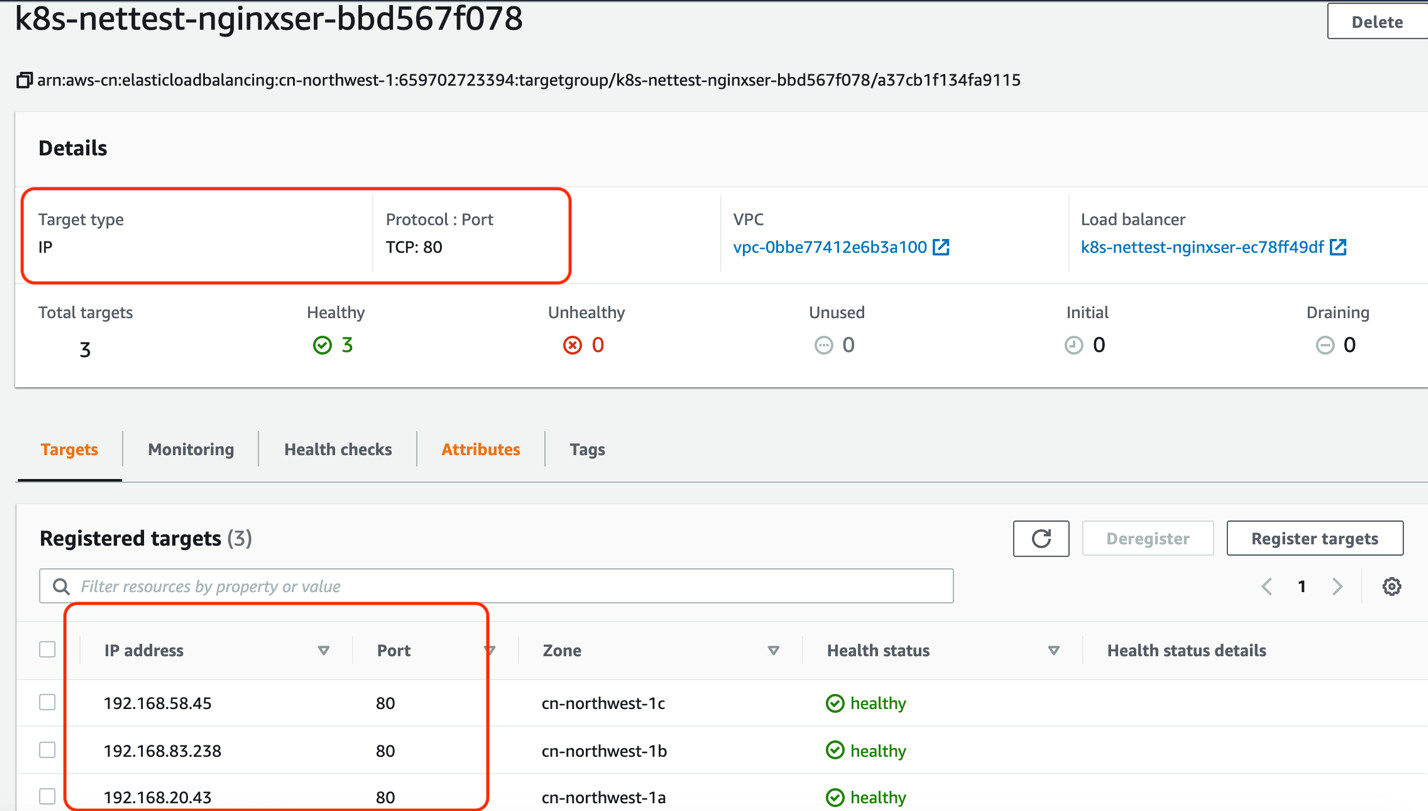
这里是直接将数据包发到pod的ip地址,因为此处EKS的service的类型为LoadBalancer(IP 模式)。而且pod也具有vpc cidr range内分配的IP 地址,直接arp获得pod对应的内网ip地址的mac,流量就直接转到承载此pod的worker node上。
6) 分析Ingress
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
Ingress 规则,每个 HTTP 规则都包含以下信息:
可选的 host: 该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。 如果提供了 host(例如 foo.bar.com),则 rules 适用于该 host。
路径列表 paths: (例如,/testpath),每个路径都有一个由 serviceName 和 servicePort 定义的关联后端。 在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。
backend(后端): 是 Service 文档中所述的服务和端口名称的组合。 与规则的 host 和 path 匹配的对 Ingress 的 HTTP(和 HTTPS )请求将发送到列出的 backend。
通常在 Ingress 控制器中会配置 defaultBackend(默认后端),以服务于任何不符合规约中 path 的请求。
6.1)创建ingress和相应的Deployment

正如你在kubernetes官方页面( https://kubernetes.io/docs/concepts/services-networking/ingress
)中看到的那样, Ingress就扮演一个连接器的角色,它将http/https流量引入到Service.但我们可以看到为这个Ingress创建的ALB仍然使用的IP模式。也就是意味着Ingress也会如Service的LoadBalancer类型中的NLB IP模式,流量直接引入到pod的ip地址,因为pod也具有vpc cidr range内分配的IP地址。直接arp获得pod对应的内网ip地址的mac,流量就直接转到承载此pod的worker node上。
另外,尽管此处Service为ClusterIP,其实不论是NodePort还是LoadBalancer,效果也一样,这一点完全体现了Ingress就扮演一个连接器的角色,它将流量直接引入到pod,借助了ALB中的IP模式的优势。
这里可以通过查看 ALB ( k8s-nettest-nginxing-2893a9a207-569319061.cn-northwest-1.elb.amazonaws.com.cn )的target group。



四、总结
在使用Amazon EKS的过程中,Service和Ingress是主要两种服务暴露方式。通过以上的深入分析和研究,我们可以看到Service的ClusterIP,NodePort和LoadBalancer的技术实现,在使用iptables的情况下,都是重度依赖kube-proxy对iptables的规则的操作。这其中ClusterIP是最关键最基础,NodePort又利用了ClusterIP的实现方式,LoadBalancer(CLB和NLB的instance模式)又使用了NodePort提供的功能。对于Service的NLB的ip模式和ingress又是主要利用的就是ALB的ip模式。
根据如上的特性,我们可以在不同的业务场景下选择不同的方式来暴露服务。
参考材料:
https://blogs.cisco.com/cloud/an-osi-model-for-cloud
https://www.cisco.com/c/dam/global/fi_fi/assets/docs/SMB_University_120307_Networking_Fundamentals.pdf
https://en.wikipedia.org/wiki/OSI_model
https://www.cisco.com/E-Learning/bulk/public/tac/cim/cib/using_cisco_ios_software/linked/tcpip.htm
https://www.cisco.com/c/en/us/support/docs/ip/routing-information-protocol-rip/13769-5.html
https://www.netfilter.org/
https://www.netfilter.org/projects/iptables/index.html
https://www.zsythink.net/archives/tag/iptables/
https://ipset.netfilter.org/iptables-extensions.man.html
https://aws.amazon.com/premiumsupport/knowledge-center/eks-kubernetes-services-cluster/
https://kubernetes.io/docs/concepts/services-networking/service/
https://docs.aws.amazon.com/eks/latest/userguide/network-load-balancing.html
https://en.wikipedia.org/wiki/OSI_model
https://en.wikipedia.org/wiki/List_of_network_protocols_(OSI_model)
https://codilime.com/blog/how-to-drop-a-packet-in-linux-in-more-ways-than-one
http://www.jsevy.com/network/Linux_network_stack_walkthrough.html
https://openwrt.org/docs/guide-developer/networking/praxis
https://www.cs.cornell.edu/~qizhec/paper/tcp_2021.pdf
https://www.netfilter.org/
https://en.wikipedia.org/wiki/Netfilter
https://kubernetes.io/zh/docs/concepts/services-networking/service/