亚马逊AWS官方博客
使用 Amazon Forecast 自动补全机制管理目标与相关数据集中的缺失值
Original URL:https://aws.amazon.com/cn/blogs/machine-learning/managing-missing-values-in-your-target-and-related-datasets-with-automated-imputation-support-in-amazon-forecast/
Amazon Forecast是一项全托管服务,使用机器学习技术生成高准确性预测,且使用者无需具备任何固有机器学习经验。Forecast适用于多种用例,包括估算产品需求、供应链优化、资源规划、能源需求预测以及计算云基础设施使用情况等。
借助Forecast,我们无需配置服务器或者手动构建机器学习模型,即可享有强大的预测能力。此外,您只需要为自己实际使用的资源付费,其中不存在任何最低成本或预先使用承诺。要使用Forecast,您只需要提供待预测变量的历史数据,以及可能影响预测结果的任何可选相关数据。其中后一部分数据可以包括随时间变化的数据(例如价格、事件与天气),以及分类数据(例如颜色、类型或地区等)。该服务会根据您的数据自动训练并部署机器学习模型,同时提供API以检索预测结果。
在现实预测场当中,我们往往会发现原始数据中存在严重的数值缺失。历史数据(或者时间序列)中缺少值,则代表其无法在各个时间段内提供真实的对应值。这种数值缺失状况可能出自多种原因,例如在特定时间段内并没有对应交易,也可能是存在采样错误或者采样无法正常进行。
Forecast支持对相关及目标时间序列数据集、乃至历史与预测时间段内的缺失值(包括现有的NaN值)进行自动估算。相关时间序列(RTS)数据中通常涵盖促销、价格或与目标值(产品需求量)等相关的缺失信息,在补全之后将显著提高预测准确率。大家可以使用多种缺失值逻辑,包括value, median, min, max, zero, mean与 nan (仅适用于目标时间序列)等,具体取决于实际用例。您可以在CreatePredictor API 中通过FeaturizationConfig使用Forecast提供的这项功能。
本文将使用Forecast GitHub repo中的notebook示例,向您展示为相关及目标时间序列(TTS)数据集进行缺失值补全的功能。
在Forecast中处理缺失值
时间序列中的缺失值,代表由于多种原因而无法使用真实对应值完成进一步处理的情况。对于代表产品销售情况的时间序列,这些缺失值可能意味着该产品在特定时段内无法上架销售——例如产品发布之前、产品淘汰之后,或者产品暂时不可用(暂时缺货)。当然,缺失值也可能意味着我们在这段时间之内没有记录下销售数据。
即使是在“无法销售”并导致目标值为零的情况下,我们面对的缺失值实际上也提示出其他一些信息。例如,我们正在销售、但当前库存为零所造成的缺失值表示为zero,而产品根本没有正式上市所引发的缺失值通常表示为nan。正因为如此,如果在目标时间序列中填充zero,则可能导致变量预测值发生过度偏移;而填充nan则可能与售出“零”个商品条目的实际情况不符,同样有可能导致预测变量过度偏移。
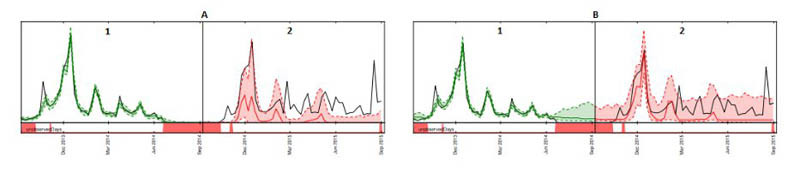
以下时间序列图,展示了选择错误的填充值如何严重影响模型的准确性。图A与图B分别代表缺货商品的需求,黑线代表实际销售数据。A1中的缺失值被填充为zero,这导致A2中的预测结果相对偏低(由虚线表示)。同样的,B1中的缺失值用nan填充,因此在B2中的预测结果更贴近实际值。
Forecast提供多种填充方法,用于处理TTS与RTS数据集中的缺失值。所谓填充,是将标准化值添加至数据集中缺失条目的过程。在回溯测试期间,预测会将填充的值(除NaN以外)假定为真实值,并将其用于评估指标。Forecast支持以下几种填充方法:
- 中间填充——填充条目开始日期与结束日期之间的所有缺失值。
- 回溯填充——填充条目最后记录的数据点与数据集全局结束日期(所有条目的最后结束日期)之间的所有缺失值。
- 未来填充(仅适用于RTS)——填充数据集全局结束日期与预测范围终点之间的所有缺失值。
下图所示,直观展现了这几种不同的填充方法。

下表列出了每种方法所支持的不同填充选项。关于更多详细信息,请参阅处理缺失值。
| A | B | C | |
| 1 | 填充方法 (TTS) | 默认 | 选项 |
| 2 | 前方填充 | 不填充 | 无 |
| 3 | 中间填充 | zero | nan, zero, value, median, mean, min, max |
| 4 | 回溯填充 | zero | nan, zero, value, median, mean, min, max |
| 5 | 未来填充(不支持) | n/a | n/a |
| A | B | C | |
| 1 | 填充方法 (RTS) | 默认 | 选项 |
| 2 | 前方填充(不支持) | n/a | n/a |
| 3 | 中间填充 | 无默认 | zero, value, median, mean, min, max |
| 4 | 回溯填充 | 无默认 | zero, value, median, mean, min, max |
| 5 | 未来填充 | 无默认 | zero, value, median, mean, min, max |
获取数据
我们首先需要为TTS与RTS导入数据。在本用例中,使用的数据文件为tts.csv与rts.csv。其中tts.cv会按月对多个商品的需求进行跟踪,而rts.csv文件则跟踪各商品的每月平均价格。这就模拟出了一种相当常见的零售场景。接下来,我们使用Forecast中的填充方法与逻辑,对这些数据集中的缺失值进行填充。首先,使用以下Python示例代码对示例商品(item_001)的需求进行可视化:

创建数据集组与数据集
现在,我们需要创建一个数据集组,并通过以下操作步骤向其中添加TTS与RTS数据集:
- 在Forecast控制台上的Dataset groups下,选择Create dataset group。
- 在Dataset group name部分,输入
filling_analysis_v1。 - 在Forecasting domain部分,选择Retail。
- 选择Next。

- 在Dataset name部分,输入
filling_analysis_v1_tts。 - 在Data schema部分,输入以下代码:
- 选择Next。

- 在Dataset import name部分,输入
filling_analysis_v1_tts_dsi。 - 在Timestamp format部分,输入
yyyy-MM-dd。 - 在IAM role部分,选择AmazonForecast-ExecutionRole。
- 选择Create dataset import。




要导入RTS数据集,请重复以上步骤,并在schema中使用以下代码:
模型创建与推理
在导入数据之后,您可以训练模型并生成准确率指标。Forecast提供五种内置算法;您可以选择特定算法,也可以直接选择Auto-ML以使Forecast选择服务中最适合目标功能的算法。关于更多详细信息,请参阅选择Amazon Forecast算法。
在本用例中,我们将使用DeepAR+,因为这里要处理的是300种彼此独立、且各自拥有两年历史数据的商品。当数据集中包含成百上千个时间序列时,DeepAR+算法的性能会优于标准ARIMA与ETS方法。要训练您的预测模型,请完成以下操作步骤:
- 在Forecast控制台的Train a predictor之下,选择Start。
- 在Predictor name部分,输入
filling_analysis_v1。 - 在Forecast horizon部分,输入
3。 - 在Forecast frequency部分,选择month。
- 在Algorithm部分,选择Deep_AR_Plus。
- 在Number of backtest windows部分,输入
1。 - 在Backtest window offset部分,输入
3。 - 在Training parameters部分,输入以下代码:
现在,我们可以为TTS(需求)与RTS(价格)设置缺失值逻辑了。在这里,我们将为TTS与RTS的middlefill 与backfill使用mean逻辑。对于futurefill(用于在预测范围内指定缺失值的逻辑),请在RTS中使用min。另一种常见的预测情况,是评估预测期间外部变量(例如价格)的不同取值产生的实际影响。这将有助于提升商品计划效果,使您无论面对哪种情况都能确保维持恰当的库存水平。您可以通过更新数据并重新生成预测(关于具体说明,请参阅GitHub repo)、或者使用futurefill方法(同上)并为模型使用不同填充选项(例如max)的方式,在Forecast中模拟这些具体目标场景。
- 在Featurizations部分,输入以下代码:

- 选择Train predictor。
在模型训练完成后,您可以转至预测模型详细信息页面以评估相关指标。
创建预测
要创建一项预测,请完成以下操作步骤:
- 在Forecast控制台的Forecast generation之下,选择Start。
- 在Forecast name部分,输入filling_analysis_v1_min。
- 在Predictor部分,选择
filling_analysis_v1。 - 在Forecast types部分,输入您希望生成预测的分位数;例如
.10,.50,.90,.99。 - 选择Create a forecast。
预测查询与可视化
最后,我们可以通过控制台利用QueryForecast API对以上创建的商品预测结果进行可视化处理。
要查询一项预测,请完成以下操作步骤:
- 在Forecast 控制台上前往Dashboard,选择Lookup Forecast。
- 在Forecast部分,选择filling_value_v1_min。
- 在Start date部分,选择
2019/07/01。 - 在End date部分,选择
2019/12/01。 - 在item_id部分,选择
item_269(您可以在这里选择任意条目) 而后点击Get Forecast。
现在,您可以显示所选条目的预测需求与历史需求,如下图所示。
总结
本文介绍如何使用Forecast支持的方法选项填充TTS与RTS数据集中的缺失值。您可以在提供Forecast服务的所有区域中立即开始使用这项功能。如果您有任何反馈意见,请通过AWS论坛或者常规AWS支持渠道与我们联系。