亚马逊AWS官方博客
Micro-MLOps——轻量级MLOps解决方案
背景
众所周知,机器学习领域的飞速发展带来了巨大的商机,而机器学习在工程化道路的发展,也逐步从手工作坊和验证试运行的工作模式,逐步过渡到大规模部署的生产的模式。这是预测的AI/ML必然的趋势。
谈到MLOps的发展就不能不提到它的起源,这要回溯到2018年,在谷歌举办的一场演讲中,业内专业人士首次公开谈及了在生产环境中对机器学习生命周期进行管理的必要性。
作为一个趋势,到2024年底,75%的企业在AI/ML的交付模式会从“Pilot/PoC模式”逐步转换为“可运维的AI/ML”模式 —— Gartner
这是Gartner对MLOps的一个预测。这里面提到的“Pilot/PoC模式”实际上指的是一种我们现在在机器学习领域进行开发和最终发布时,通常看到的一种工作方式,亦即一切都基本上以模糊的、实验性的、手工操作为主的方式。而与之相反的就是“可运维的AI/ML”模式,这种方式是今天我要探讨的主题——这是一种能帮助企业在机器学习领域达到生产级别的工作模式。生产级别的机器学习,就是那种具备大规模扩展、可持续、可审计、可靠、可重复等五大要素的工程模式。
另外,无论对于任何一个IT企业,只有产品上线到生产环境里,才能真正的产生价值,机器学习领域也不例外,而MLOps正是可以实现这个目标的有效保障,接下来我们谈一下什么是MLOps?
什么是MLOps?
MLOps是DevOps的近亲,它是一种哲学和实践的结合,它借鉴并基于DevOps的大量基础方法论和技术栈,旨在使数据科学和IT团队能够快速开发、部署、维护和扩展机器学习模型。
同时,它也是跨数据工程、数据科学和开发人员与系统运维团队的统筹与协调方面的方法论和实践,以管理机器学习模型从数据准备,训练到部署的整个生命周期。
 |
正如IT产业内许多新事物的发展规律一样,MLOps从2018年第一次被提出之后至今的短短几年之中,业内雨后春笋般诞生了各种与MLOps相关的技术和产品,他们当中有开源的也有闭源的,有的是MLOps复杂工具链中的一环,有的则是全栈产品。有的是云平台从自身平台属性出发设计的产品,而还有的是从数据工程师的角度去设计的。P s总之,大家都说自己是MLOps!
然而,遗憾的是,当最终用户想把上述产品拿来直接开始使用时,他们会发现很多功能强大的产品,却无法控制不同角色操作者(数据工程师、开发和运维)的权限,或者需要高昂的学习成本,或者需要在不同的控制台之间切来切去…….这种不甚完美的事情一直在发生着,仿佛是所有工程效能领域领域的一个永远解不开的谜。
本文将描述一个十分轻量级、学习成本非常低的端对端的MLOps解决方案的具体实现,它充分利用了GitOps思想,把git作为用户唯一需要理解的用户接口,并融入了基于主干的开发的思想,还利用了Gitlab Hook来帮助企业建立代码的合规性、把大部分MLOps涉及到的开发流程结合在了一起。这样,企业可以以极低的学习和部署成本,快速建立起不同角色间的协作关系,便于快速将AI/ML投入到快速迭代的良性循环之中。
Micro-MLOps系统架构
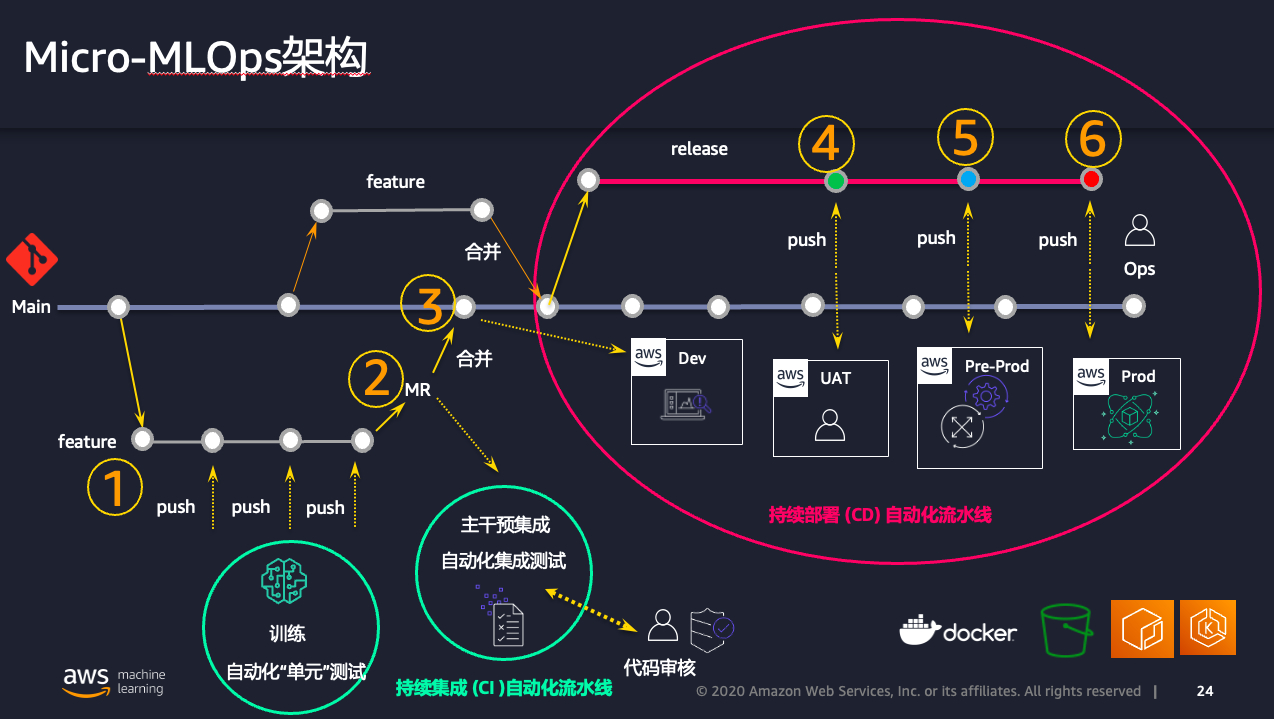 |
系统流程
开始训练
- 当算法工程师开始自己的工作时,其可以通过从主干(main)代码上建立一个名为“feature-xxx”的自有分支来作为每次工作的开始点。注意这个分支的命名规范通常是提前和最终用户约定好的,本实现中默认为“feature-”作为前缀。如果工程师不按照这个约定来创建的分支,将不会触发后续自动流水线。由于本文对应的源代码可以在aws samples得到,所以您可以根据实际落地客户的喜好,通过源代码的修改来默认命名规范,比如将前缀命名为“experiment-”等,本文的后面部分将会介绍代码结构。如图。
 |
- 该分支的拉取和命名,建议遵循敏捷开发的最佳实践,功能尽量小而紧凑,能够快速验证并能够尽快回到主干。
- 本方案的设计之中,采用了基于主干的开发作为分支策略。如图。
 |
- 每次当算法工程师进行push操作时,将会触发GitLab的训练/测试流水线,并且每次训练的结果,将会以comments的形式追加到当前feature分支的commit里。如下图所示。
 |
- 由于不同的训练代码,总会产生出不同的测试结果和图形,为了让流水线能够进行灵活的衔接,在本方案里,用一个名为“.feature.settings”配置文件给feature分支的操作者(通常是ML算法工程师)。该文件是一个json格式的配置文件,内容如下。
配置说明如下:
| 配置项 | 值 | 注释 |
| FEATURE_REPORT | “xxx.txt,xxx.png” |
* 用来配置训练完成后的结果和图形,由后台流水线形成最终结果报告,并创建git commit中的comments。 * 目前支持文本和png格式的图形,使用逗号进行分割。 |
| FEATURE_DEPENDENCIES | “requirement.txt”,或其他对等文件名。 | 描述python依赖包的文件,通常约定是requirement.txt |
| FEATURE_TRAIN_ENABLED | “yes”或者“no” |
yes:表示feature代码被push后,立刻触发训练的流水线。 no:当代码处于未准备好的最初阶段,不想触发训练流水线,目的是减少无效的训练代码的触发,导致相关资源的浪费。 |
| FEATURE_TRAIN | “xxx.py” | 指定数据工程师训练代码的入口文件,通常是“xxx.py”的形式,也可以代入参数。 |
| FEATURE_TEST_ENABLED | “yes”或“no” |
yes:训练代码执行之后便开始调用测试代码文件,以验证测试结果。 no:执行训练代码后,不执行测试。 |
| FEATURE_TEST | “xxx.py” | 指定测试代码入口文件,如“test.py”或“test/test.py 1 2 3 4”,路径是相对路径,可以代入参数。 |
这个配置文件,控制了训练代码,和训练测试代码的行为,给操作提供了灵活性。如果想添加更多的控制,可以修改源代码去提供这样的支持。
需要注意的是,该文件必须由feature分支的拥有者方可编辑并push,否则合规性检测将会给予错误提示,最终将不能成功提交。反之,如果在feature分支上修改了.deploy目录下的文件,也会被合规检测拦截。如图所示。
 |
- 同样,如果一次feature分支上的commit里包含了一部分“合法的”的可以变更的文件,和一部分不合法的文件变更(比如.deploy下面的文件),都会被系统拦截。
- 数据工程师,经过反复的push代码来迭代自己的训练,直到觉得训练结果满意为止。
- 按照DevOps的最佳实践原则,我们鼓励测试人员编写所有与当前feature有关的测试用例,在py中,并在每次训练执行之后,执行测试并输出测试结果(如testResult.txt,同样可以放到FEATURE_REPORT中去,以comment的最终形式展现给开发者/QA,以得到最佳效果。
合并到主干
- 当算法工程师认为训练已经达到了某种最佳状态,可以通过提交合并请求(Merge Request,MR)进入到代码审核(Code Review)环节。在该环节,需要按照一般的软件开发共识来进行代码审核,比如指定有经验的代码审查人(Reviewer)来做这件事。
- 当算法工程师,将合并请求提交成功之后,也就是MR创建之后,系统将自动触发MR流水线,在该环节,系统将自动将当前主干的代码与当下feature分支的代码进行合并(称之为“预合并”),如果发现有合并冲突导致失败,将失败整个流水线,此情况下,流程将不能往下继续进行,数据开发者将必须在feature分支上解决掉潜在的合并冲突后,再次申请代码合并。
 |
- 如果上述过程都没有问题,流水线将执行预合并后的代码,并进行相应的测试,如果全程没有问题,则测试结果将在comments里予以体现。
 |
- 当代码审核者打开此MR时,他需要做的是,查看自动流水线完成后给予的测试结果,如果是流水线失败了,则意味着数据工程师需要重新提交Code Review。
 |
- 如果自动流水线给出了正确的结果,代码审核人如果在查看了代码的变更之后仍然觉得有问题,则可以让这次合并请求失败,不予放行。
- 因此,作为最重要的一个环节,我们需要流水线和代码审核人都赞同,才能过进行一次成功的代码合并。这样设计的目的是尽可能保障主干的安全。
- 当代码被最终推入主干之后,系统会自动触发一个新的流水线,这个流水线的任务是将本次合并的代码版本,进行镜像的构建,并将其传输到AWS ECR中备用,同时,还会自动将其部署到开发环境(Dev Environment)。在本实现中,训练模型和推理代码将被部署到EKS上,并以Repo所在的分组名称,以及项目名称作为关键字,拼接在一起,形成独特的Namespace/Deployment/Service/Ingress命名。本文展示的Kubernetes命名空间为“mlops-aws-poc–dev”,如图。
 |
- 此时,数据开发者或者QA便可以在测试环境中,对最终发布的微服务进行手工或自动的集成测试,以验证其功能的正确性。在此再次重申自动化测试的重要性,虽然它的确不容易达成。
- 以上步骤将由企业内的所有算法开发者并行操作,周而复始,不断迭代。
- 以上整个过程,我们称之为MLOps流程当中的持续集成(CI)部分。
Release/Hotfix流程
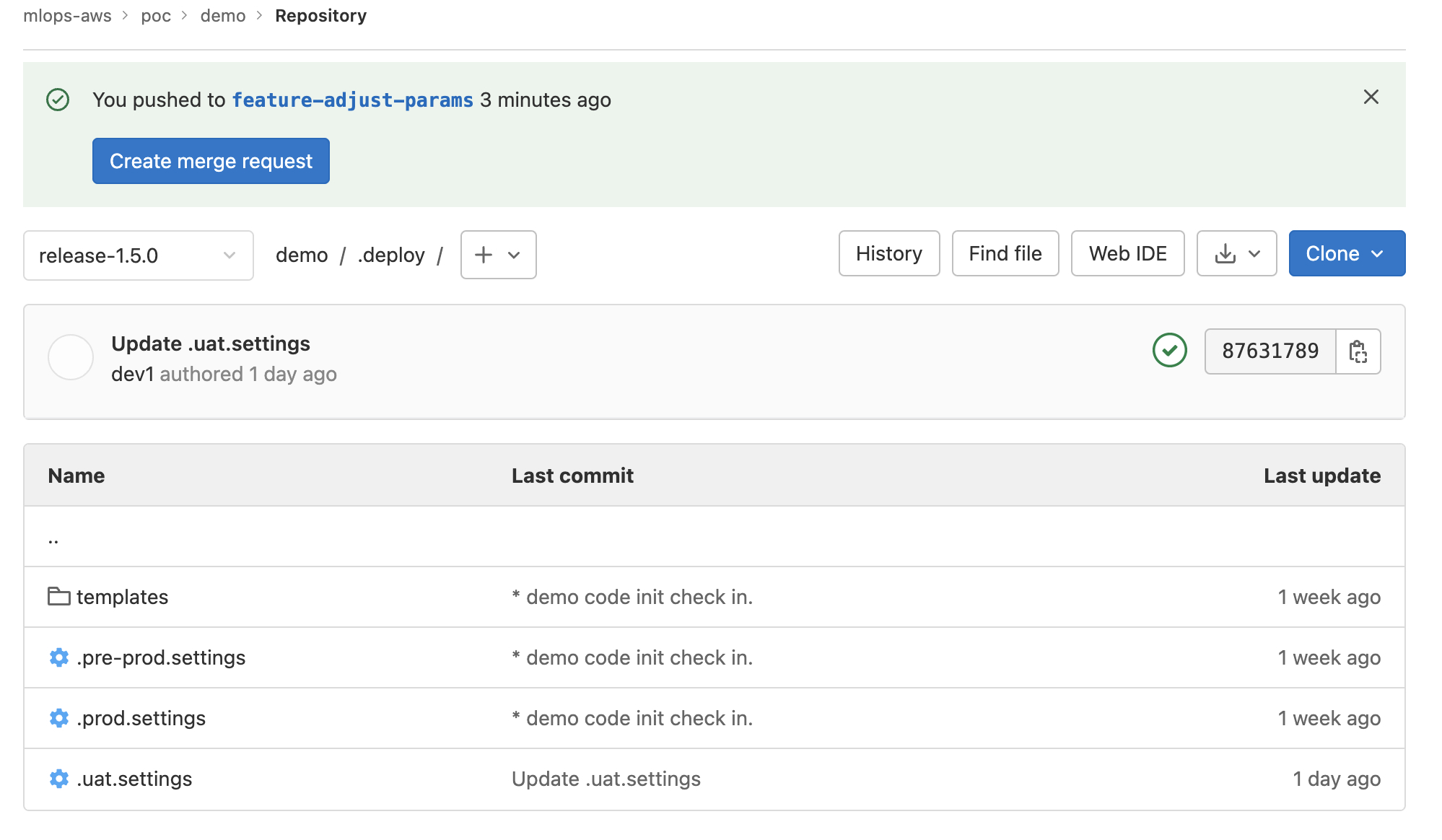
- 当开发者在主干不断迭代的同时,在某个时刻,企业的产品拥有者(PO)会从商业角度来决定何时进行Release,一旦决定下来,他将会从主干的某一次提交,建立出一个release分支,来正式进入一个产品版本的发布工作。
- Release分支的命名依旧是遵从事前的约定,否则拉出的分支将无法触发后续的自动流水线,也无法最终被部署到测试环境和生产环境。在这里,Release分支的命名规范为“release-1.5.0”,不但格式是强约束的,而且最后一位一定是“0”。如图所示。
 |
- 同理,hotfix分支的命名规范形如“hotfix-1.5.1”,注意最后一位一定不是“0”,后台流水线会首先检查分支命名的合理性。
- 在Release分支拉出,到最终部署到生产,通常会遵从uat(用户接受测试),和pre-prod(预生产),本实现提供了极简的操作方案:以部署到uat环境为例,仅需要有权限的人,在release分支内变更“.deploy/.uat.settings”文件,并push即可触发相应的自动化流水线进行相应的部署。
- 部署到pre-prod(预生产)环境与部署到uat(用户接受测试)环境的过程一致,仅需修改“.pro-pred.settings”文件并push。
 |
- 当所有上线前的测试都完成之后,可以进行生产环境的上线。如果是具备权限的人修改“.prod.settings”文件并push,则可以部署到生产环境。如果是没有权限的操作者,试图去提交对.deploy/.prod.settings文件变更的时候,会被提示不合规而最终不能提交代码到feature分支上。
 |
源代码
工程样例
- 代码结构
 |
- 说明
| 目录/文件名 | 注释 |
| * |
所有文件。 * 不同文件/文件夹需要不同权限来操作 * 管理员身份可以全部变更并push |
| .deploy |
所有部署相关的文件 * 在feature分支内,仅可查看,无法变更和push |
| .deploy/.uat.settings |
Release/Hotfix分支下,部署到uat环境时需要变更,并可以直接push的文件。 * 在其他分支下,如main/feature分支下无法变更。 * 管理员身份没有限制。 |
| .deploy/.pre-prod.settings |
Release/Hotfix分支下,部署到pre-prod环境时需要变更,并可以直接push的文件。 * 在其他分支下,如main/feature分支下无法变更。 * 管理员身份没有限制。 |
| .deploy/.prod.settings |
Release/Hotfix分支下,部署到prod环境时需要变更,并可以直接push的文件。 * 需获得上线权利,则需要操作者是“MLOps Admin”组的成员 * 在其他分支下,如main/feature分支下无法变更。 |
| ./* | 根目录下所有文件和除.deploy文件夹之外,均为应用本身可以自行控制/变更/创建。 |
流水线
- 代码结构
 |
- 说明
| 目录/文件名 | 注释 |
| custom_hooks/pre-received.d | Gitlab的服务端Hook代码 |
| Dockerfiles | Gitlab流水线用到的docker image文件 |
| Jobs | Gitlab流水线代码 |
| Templates | Gitlab流水线代码 |
安装和配置
Gitlab安装
- 选择一台EC2,x社区版本安装,参见这里。
- 确保系统上包含x。
- 运行pip install –upgrade python-gitlab。
- 确保系统上安装了git。
Gitlab配置Hook
- Ssh登录到Gitlab服务器,选择一个目录(basedir),git clone https://github.com/aws-samples/micro-mlops.git ,拷贝<basedir/cicd-templates/ custom_hooks/* 到/var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/
- 执行 chmod +x /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/*.sh
- 执行chown git:git /var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/*
- 编辑 /etc/gitlab/gitlab.rb, 找到“gitaly[‘custom_hooks_dir’]”的配置项,并去掉去掉注释状态。
gitaly['custom_hooks_dir'] = "/var/opt/gitlab/gitaly/custom_hooks"- 在Gitlab中配置一个Private Access Token(PAC),具体步骤见这里。
- 修改/var/opt/gitlab/gitaly/custom_hooks/pre-receive.d/.gitlab.conf如下。
- 执行gitlab-ctl reconfigure使Gitlab Hook生效。
Gitlab Runner安装和配置
- 选择另一台EC2,安装Gitlab Runner,具体步骤参见这里。
ssh登录到Runner所在的EC2,修改配置文件/etc/gitlab–runner/config.toml,在[[runners]]下添加下列配置。
- 执行gitlab-runner restart使配置生效。
Gitlab 配置环境变量
- 在合适的范围内,如repo或者某个组上,配置Gitlab几个环境变量,如图所示。
 |
- 环境变量
| Variable Name | Value |
| AK | AWS密钥名称 |
| SK | AWS密钥密码 |
| AWS_DEFAULT_REGION | Region名,如us-east-1 |
| CLUSTER_NAME | EKS Cluster Name, 如my-test-k8s |
| DOCKER_REGISTRY | 用于存储ML推理镜像的私有ECR地址 |
| DOCKER_REGISTRY_PUBLIC | 用于存储流水线用到的工具镜像的公开ECR地址 |
| repo_token | 调用Gitlab API时所需的PAC Token |
Gitlab 配置流水线
- 编辑cicd-templates/templates/default-pipeline.yaml,修改EKS和ECR有关配置信息。修改完成后提交到Gitlab中,如下。
- Build并推送流水线需要的docker image到用户AWS账号的ECR中, 最终效果如图所示。
 |
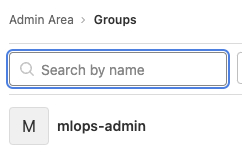
配置Micro-MLOps的权限
- 权限控制是将特权用户放到一个名为mlops-admin的组内。
- 在这个组的用户将可以执行生产环境的上线操作。
 |
- 可以利用GitLab内置的不同角色(owner/maintainer/developer等)来设定更复杂的权限,本文仅展示了在/不在这个组内的最简化的权限控制。
推荐的组和项目之间的布局
 |
- 权限控制组为mlops-admin
- mlops-aws组下有2个子组,gitlab-ci内包含cicd-templates工程。该组只能给使用pipeline的所有用户和组以只读权限(reporter),防止对pipeline的非法篡改。如图所示。
 |
- poc组下存放开发者日常使用的ML工程,并可按照Gitlab通常的方式来分配权限。如图所示。
 |
最后
本文提供了一个轻量级的MLOps实现,旨在提供一种快速适应客户侧需求变化的MLOps流程和框架。后续将根据客户的实际需求继续迭代功能,请随时关注aws samples。