亚马逊AWS官方博客
新功能 — 推出 SageMaker 训练编译器
 今天,我们很高兴地宣布推出 Amazon SageMaker 训练编译器,这是一项新的 Amazon SageMaker 功能,可以将深度学习 (DL) 模型的训练速度加快多达 50%。
今天,我们很高兴地宣布推出 Amazon SageMaker 训练编译器,这是一项新的 Amazon SageMaker 功能,可以将深度学习 (DL) 模型的训练速度加快多达 50%。
随着 DL 模型的复杂性增加,优化和训练它们所需的时间也越来越长。例如,训练流行的自然语言处理 (NLP) 模型“RoBERTa”可能需要 25000 个 GPU 小时。尽管客户可以应用一些技术和优化功能来缩短训练模型所需的时间,但实施这些技术和优化功能也需要一些时间,并且需要较为罕见的技能组合。这可能会阻碍在更广泛采用人工智能 (AI) 方面的创新和进步。
到目前为止是如何进行培训的?
通常,有三种方法可以加快培训:
- 使用功能更强大的单台计算机来处理计算
- 在 GPU 实例集群中分配计算以并行训练模型
- 通过使用更少的内存和计算,优化模型代码以更高效地在 GPU 上运行。
实际上,优化机器学习 (ML) 代码既困难又耗时,而且是一项难得的技能。数据科学家通常在基于 Python 的 ML 框架(例如 TensorFlow 或 PyTorch)中编写训练代码,并依靠 ML 框架将其 Python 代码转换为可在 GPU 上运行的数学函数(通常称为内核)。然而,这种通过用户 Python 代码进行的转换通常效率低下,因为 ML 框架使用预先构建的通用 GPU 内核,而不是创建特定于用户代码和模型的内核。
即使是技术最娴熟的 GPU 程序员,也可能需要几个月的时间才能为每个新模型创建自定义内核并对其进行优化。我们构建了 SageMaker 培训编译器来解决这个问题。
今天发布的功能让SageMaker 训练编译器可以自动编译 Python 训练代码并专门为您的模型生成 GPU 内核。因此,训练代码将使用更少的内存和计算,从而加快训练速度。例如,在对 Hugging Face 的 GPT-2 模型进行微调后,SageMaker 培训编译器将训练时间从近 3 小时缩短到 90 分钟。
自动优化深度学习模型
那么,我们是如何实现这种加速的呢? SageMaker 训练编译器将 DL 模型从其高级语言表示转换为硬件优化指令(比使用现成框架的作业训练速度更快),从而加速训练任务。在后台,SageMaker 训练编译器在原生 PyTorch 和 TensorFlow 框架所提供的范围之外进行了增量优化,以最大限度地提高 SageMaker GPU 实例的计算和内存利用率。
更具体地说,SageMaker 训练编译器使用图形级优化(运算符融合、内存规划和代数简化)、数据流级别优化(布局转换、常见子表达式消除)和后端优化(内存延迟隐藏、面向循环的优化),以生成高效使用硬件资源的优化模型。因此,训练速度最多可提高 50%,并且返回的模型与未使用 SageMaker 训练编译器 时相同。
但是,如何将SageMaker 训练编译器与模型配合使用? 就和添加两行代码一样简单!
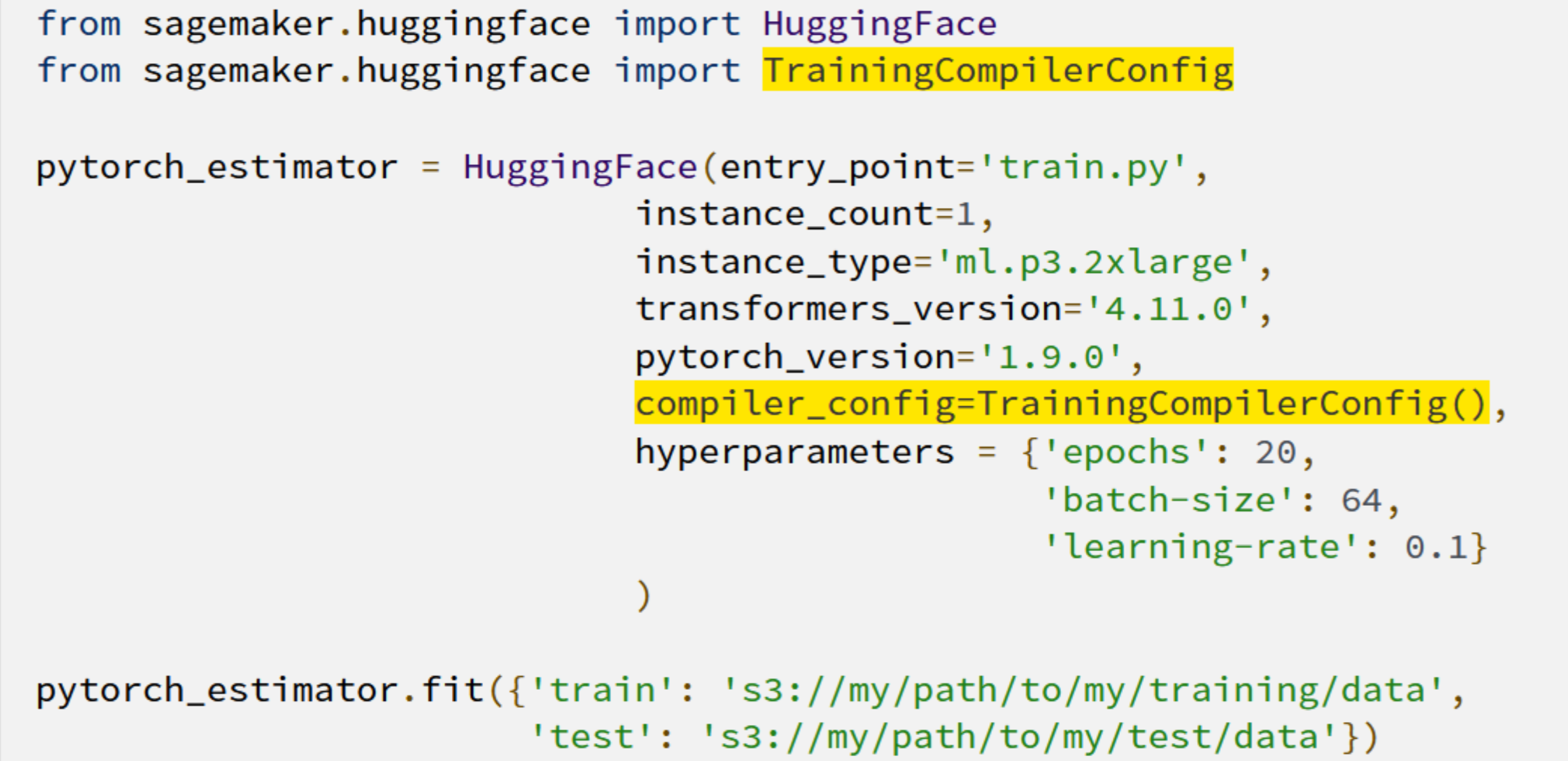
训练时间缩短意味着客户有更多的时间以更低的成本创新和部署他们新训练的模型,并且更有能力试验更大的模型和更多的数据。
充分利用 SageMaker 训练编译器
尽管许多 DL 模型都可以从SageMaker 训练编译器中受益,但训练时间更长的大型模型能节省最多的时间和成本。例如,在长期运行的基于 RoBERTa 的微调练习中,训练时间和成本降低了 30%。
Quantum Health(一个以“让医疗导航对每个人来说更智能、更简单、更具成本效益”为使命的组织)的高级数据科学家 Jorge Lopez Grisman 说:
“考虑到 NLP 模型的大小,使用它来进行迭代可能是一个挑战:长时间的训练会使工作流程停滞不前,高昂的成本会阻碍我们的团队尝试可能提供更好性能的更大模型。Amazon SageMaker 训练编译器令人兴奋,因为它有可能减轻这些摩擦。使用 SageMaker 训练编译器实现加速对我们的团队来说是一次真正的胜利,这将使我们在向前迈进的过程中更加敏捷和创新。”
更多资源
要详细了解 Amazon SageMaker 训练编译器的益处,可以在此处访问我们的页面。要开始使用,请在此处查看我们的技术文档。