亚马逊AWS官方博客
一桥飞架南北-中国区与 Global 区域 DynamoDB 表双向同步 (下)
在《一桥飞架南北-中国区与Global区域DynamoDB 表双向同步(上)》中我们介绍了通过lambda、DynamoDB stream、kinesis stream等托管服务实现中国区与Global区域DynamoDB表之间数据双活同步的架构与准备工作,本文将介绍后续的部署,测试乃至监视步骤,希望能给您一些有益的启示。
1.7 创建send to kinesis 的lambda函数
新加坡区域
创建lambda
创建python lambda function命名为ddb-send-to-kinesis,上传ddb_send_to_kinesis的Lambda代码,代码请见send_to_kinesis.py
设置环境变量
为lambda添加五个环境变量,第一个用来从parameter store中获取中国区的Access Key和Secret Key的路径
| Key | Value |
| PARAMETER_STORE_PATH_PREFIX | /DDBReplication/TableCN/ |
| TARGET_REGION | cn-north-1 |
| TARGET_STREAM | ddb_replication_stream_cn |
| USE_PROXY | FALSE |
| PROXY_SERVER | <China region proxy IP>:<port> |
创建触发器
通过lambda页面选中ddb_send_to_kinesis,而后选择add trigger,下拉框中选择DynamoDB,而后填写以下信息:
- 从DynamoDB console获取我们开启的DDB stream的ARN,填写到DDB table处
- 将SQS:ddbstreamsg的arn填写到On-failure destination处
- Concurrent batches per shard设为10
- Batch size设为500
- Retry attempts: 300
- Maximum age of record: 1 Day
- Timeout设置为1分钟
通过命令查询
将lambda置于VPC内
在lambda页面选中ddb_send_to_kinesis,在VPC界面进行设置,选中两个AZ中的私有子网,并选择预先设置好security group,向北京区代理服务器的EIP网段开放http/https接口

北京区域
创建lambda
创建python lambda function命名为ddb-send-to-kinesis,上传ddb_send_to_kinesis的Lambda代码,编辑send_to_kinesis.py,代码请见send_to_kinesis.py
设置环境变量
为lambda添加五个环境变量,第一个用来从parameter store中获取中国区的Access Key和Secret Key的路径
| Key | Value |
| PARAMETER_STORE_PATH_PREFIX | /DDBReplication/TableSG/ |
| TARGET_REGION | ap-southeast-1 |
| TARGET_STREAM | ddb_replication_stream_sg |
| USE_PROXY | FALSE |
| PROXY_SERVER | <Singapore region proxy IP>:<port> |
创建触发器
通过lambda页面选中ddb_send_to_kinesis,而后选择add trigger,下拉框中选择DynamoDB,而后填写以下信息:
- 从DynamoDB console获取我们开启的DDB stream的arn,填写到DDB table处
- 将SQS:ddbstreamcn的arn填写到On-failure destination处
- Concurrent batches per shard设为10
- Batch size设为500
- Retry attempts: 300
- Maximum age of record: 1 Day。
- Timeout设置为1分钟
将lambda置于VPC内
在lambda页面选中ddb_send_to_kinesis,在VPC界面进行设置,选中两个AZ中的私有子网,并选择预先设置好security group,向新加坡区代理服务器的EIP网段开放http/https接口

1.8 创建消费Kinesis Stream的Lambda函数
新加坡区域
创建lambda
创建python lambda function命名为replicator_kinesis,上传replicator_kinesis的Lambda代码,代码请见 replicator_kinesis.py
设置环境变量
创建触发器
通过lambda页面选中replicator_kinesis,而后选择add trigger,下拉框中选择Kinesis,而后填写以下信息:
- 下拉菜单中选取ddb_replication_stream_sg
- 将SQS:ddbreplicatorsg的arn填写到On-failure destination处
- Concurrent batches per shard:10
- Batch size:500
- Retry attempts:100
北京区域
创建lambda
创建python lambda function命名为replicator_kinesis,上传replicator_kinesis的Lambda代码,代码请见 replicator_kinesis.py
设置环境变量
创建触发器
通过lambda页面选中replicator_kinesis,而后选择add trigger,下拉框中选择Kinesis,而后填写以下信息:
- 下拉菜单中选取ddb_replication_stream_cn
- 将SQS:ddbreplicatorcn的arn填写到On-failure destination处
- Concurrent batches per shard:10
- Batch size:500
- Retry attempts:100
2、测试
2.1、准备加载数据脚本
在北京和新加坡的代理服务器上,生成load_items.py,代码请见 load_items.py
2.2、测试
单进程加载执行python3 load_items.py -n 20000 -r sg,其中:
- -n后的参数是加载记录数量,本例中是加载20000条记录
- -r后是指定区域,本例是指定Singapore
多进程并发加载可以执行seq 5 | parallel -N0 –jobs 0 “python3 load_items.py -n 20000 -r sg”,其中:
- seq后是并发数,本例中选择5个并发进程,每个加载20000行数据
为了模拟两个region同时有大量本地写DynamoDB的场景,我们在北京和新加坡的压测机上同时运行并发加载测试。
在运行过程中,我们可以通过监控DynamoDB表的Write Capacity图表,可以看到WCU达到了500以上。值得注意的是,在双向复制的测试中,既有压测进程在写入DynamoDB表,同时有lambda在复制来自对端的数据,因此观察到的WCU是两者的叠加。如果是同样测试条件下做单向复制的测试,那会观察到WCU大约是前者的一半。

2.3、监控lambda
通过lambda console的monitor对lambda运行情况进行监控,以下几个指标要关注。
以下截图的产生背景是:在中国区代理EC2上运行seq 5 | parallel -N0 –jobs 0 “python3 load_items.py -n 20000 -r cn”也就是用5个进程模拟向user-cn表插入记录,每个进程插入20000条,总计100000条记录,最终执行时间大概是5分:29秒,实际生产环境中的监控图可能有很大变化。
Invocations
– 函数代码的执行次数,包括成功的执行和导致出现函数错误的执行。如果调用请求受到限制或导致出现调用错误,则不会记录调用。这等于计费请求的数目。这里可以看到中国区ddb_send_to_kinesis的调用次数明显比新加坡区replicator_kinesis调用次数高,可以通过cloudwatch logs查看2个lambda运行日志找到原因,我们可以看到ddb_send_to_kinesis因为是跨region写入记录,所以网络延迟导致每批次处理记录要比同region的replicator_kinesis的每批次处理记录要少得多,故而相应地调用次数也要多得多。
中国区ddb_send_to_kinesis

新加坡区replicator_kinesis

Duration
函数代码处理事件所花费的时间量。对于由函数实例处理的第一个事件,该时间量包括初始化时间。调用的计费持续时间是已舍入到最近的 100 毫秒的 Duration 值。因为ddb_send_to_kinesis是跨region写入记录,所以网络延迟导致其花费时间要比replicator_kinesis时间长一些。
中国区ddb_send_to_kinesis

新加坡区replicator_kinesis

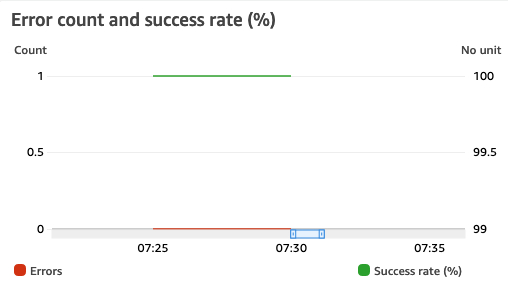
Error count and success rate (%)
Errors – 导致出现函数错误的调用的次数。函数错误包括您的代码所引发的异常和 Lambda 运行时所引发的异常。运行时返回因超时和配置错误等问题导致的错误。错误率即通过 Errors 的值除以 Invocations 的值计算而得。我们可以看到ddb_send_to_kinesis因为是跨region写入记录,所以网络可能导致部分失败。
中国区ddb_send_to_kinesis

新加坡区replicator_kinesis
IteratorAge
对于从流读取的事件源映射,为事件中最后一条记录的期限。期限是指流接收记录的时间到事件源映射将事件发送到函数的时间之间的时间量。我们可以看到ddb_send_to_kinesis因为是跨region写入记录有网络延迟,所以IteratorAge会比replicator_kinesis长一些。
中国区ddb_send_to_kinesis
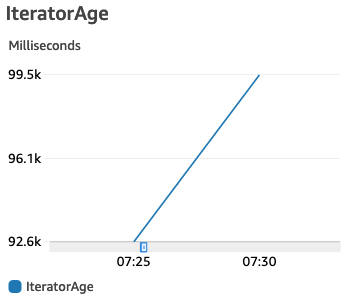
新加坡区replicator_kinesis

Concurrent executions
正在处理事件的函数实例的数目。如果此数目达到区域的并发执行限制或您在函数上配置的预留并发限制,则其他调用请求将受到限制。我们可以看到ddb_send_to_kinesis因为源头DDB stream是多个shard(因为源DDB是on demand且记录数较多),所以他并发有40个,而replicator_kinesis的源头kinesis stream我们只有一个shard所以并发只有10个。
中国区ddb_send_to_kinesis
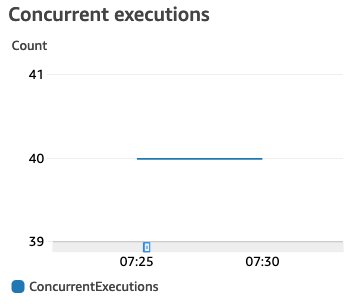
新加坡区replicator_kinesis

2.4、通过replicator_stats记录复制数量
在本实验中,为了方便查询复制记录的总数,每当load_items.py向名为user-*的DynamoDB表中加载记录都会向本region的loader_stats表中记录加载记录数,此后每当对端region的lambda replicator_kinesis向同region名为user-*的DynamoDB表中成功写入记录时就会累加在replicator_stats表的replicated_count值,故而可以通过比较replicator_stats表的replicated_count值与load_items中插入的记录总数来掌握整个复制进度。
譬如我在中国区压测机上运行seq 5 | parallel -N0 –jobs 0 “python3 load_items.py -n 20000 -r cn”也就是用5个进程模拟向user-cn表插入记录,每个进程插入20000条,总计100000条记录,可以在中国区的loader_stats表中看到插入条目统计值为100000。并且,我们从北京区的loader_stats以及新加坡区的replicator_stats中可以看到加载和复制完成记录数。
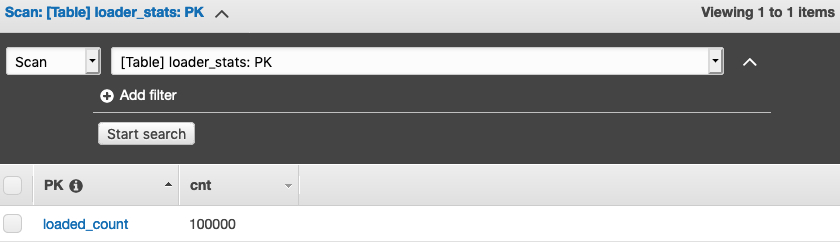

2.5、通过cloudwatch监控metrics
在通过load_items.py向DynamoDB表中加载数据时会向cloudwatch中输出metrics Total_loaded,该metrics会记录每个load_items.py加载数据的总数,通过cloudwatch的console我们可以图形化展示该metrics,可以在CloudWatch Metrics->DDB-Loader->loader找到这个图表。下图选取的
在通过replicator_kinesis lambda向DynamoDB表中加载数据时同样会向cloudwatch中输出2个metrics ,其中:
- Total_replicated 记录了向目标DynamoDB表中复制数据的总量
- Updated_count记录了每次调用lambda复制数据的数量
过cloudwatch的console我们可以图形化展示2个metrics,下图Total_replicated选择30秒周期内的最大值,我们可以从中掌握复制数据的情况,而Updated_count选择总数可以从曲线中判断复制速率是否稳定,如果波动较大,要考虑是否网络或者程序出现问题。


另外,我们可以比较Total_loaded和Total_replicated的时间点来分析复制的时延。在这个实验中,压测机在07:31:42UTC时间完成测试,Total_loaded达到100K条,而复制端在07:32:16UTC时间复制完成,达到100K条,总体时延34秒。
通过两篇blog,我们介绍了如何通过lambda、DynamoDB stream、Kinesis Stream等托管服务实现中国区与Global区域DynamoDB表之间数据双活复制同步,其中包含了架构、部署步骤以及监控方法,希望当您有类似需求的时候,能从中获得启发,助力业务发展。
附录