亚马逊AWS官方博客
推荐系统系列之排序模型的调优实践
上一篇文章介绍了排序任务的样本工程,本文我们介绍排序模型的调优实践。大家可能在做排序任务的项目中会有感触,排序模型的调优是一个反复迭代的过程(因为模型在线上的表现会时好时差),让一个新的排序模型在线上效果能持续的好,可能需要3~6个月的时间(期间会花费大量的时间在数据集的准备,训练速度优化,框架代码debug/踩坑,模型效果调优,线上推理速度优化等事情上)。搜推广领域的排序任务是比较类似的,下面我会用一个真实的客户项目为例子来详细介绍,虽然下面的例子是讲的计算广告领域的排序模型,但是对于三个领域的排序模型的调优实践来说是相通的。更多细节以及更详细的内容可以参考我的github repo。
客户项目的上下文以及背景介绍
这个项目的大致情况如下:
| 介绍 | |
| 背景 | 计算广告DSP平台做IVR预估(即从曝光到转化的预估)的排序模型 |
| 模型选型 | Wide & deep模型 |
| ML平台,框架和API | Amazon SageMaker + TF2.x + tf.keras API + tf.dataset API |
| 训练迭代方式 | T+1训练方式(这里用的是30天训练集+1天验证集) |
| 数据量级 | 训练集400GB+,验证集10GB+ |
| 需求 | 模型对验证集的AUC离线指标能达到0.75+才能上线做AB test |
| 痛点 | 当前验证集的AUC只有0.6左右;而且项目时间比较紧迫。 |
| 项目最后状态 | 在给定时间内,验证集的AUC提升到了0.85+;模型上线后的线上效果长期稳定的超过A/B test的另一个模型LightGBM模型。 |
客户的情况是,他没有办法拿到点击日志,只能拿到曝光日志和转化日志。因此这个客户做的是IVR预估即从曝光到转化的预估,区别于常见的CTR预估(从曝光到点击的预估)和CVR预估(从点击到转化的预估)。
关于排序模型有很多选择:LR,GBDT,LR+GBDT,FM/FFM, 深度模型(wide & deep,DeepFM,DCN等等 )。该客户当前已经用LightGBM模型在线上跑了一段时间了,现在准备尝试上深度模型,而wide & deep深度模型比较灵活而且在国内客户中用的比较多,所以客户就选择了wide & deep来尝试。
排序模型常见的训练方式有三种(该客户使用的是方法1即T+1全量数据训练方式,搜推广领域中的排序任务很大一部分客户用的方法1),如下:
| 介绍 | |
| 方法1:T+1训练(固定时间滑窗内的全量数据来训练) |  |
| 方法2:每天增量训练 | 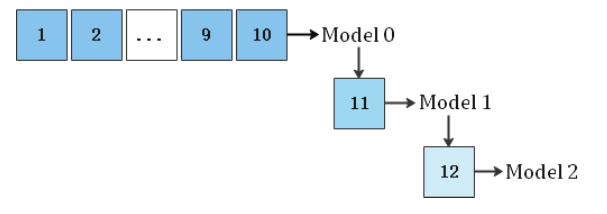 |
| 方法3:综合方法1和方法2 | 即当天内做增量训练(比如小时级别的增量训练),当天结束的时候做T+1全量训练。 |
对于业界常见的计算广告的排序公式ecpm,如果是CPC(按照点击计费)出价方式,ecpm = pctr * CPC_bid,如果是CPA(按照转化计费)出价方式,ecpm = pivr * CPA_bid。对于更复杂的排序公式,还会考虑价格挤压因子或者智能出价因子等。客户这里使用的是pivr * CPA_bid排序公式。
过程回放
样本类别不均衡处理尝试
对于搜推广领域的排序任务数据集,正负样本严重的类别不均衡,也就是说负样本数量经常是正样本数量的几百倍或者几千倍(当前这个客户的正负样本比例是1:4000)。对于这么严重的样本类别不均衡,如果不采取任何方案来缓解这个问题,对于模型学习知识是很困难的。对于排序任务来说,常见的缓解类别不均衡的方法如下:
- 对负样本降采样:目的是通过某种方法从海量的负样本中采样一些负样本出来,从而让负样本的比例减少。对负样本进行采样后,在计算广告领域的排序任务中,需要在最后计算排序公式的时候进行校准(校准发生在线上推理的时候,离线训练的时候不用考虑校准)。对于客户的这个场景,需要对pivr进行校准,校准的公式如下(参考Facebook 应用 GBDT+LR的paper),q = p/(p + (1 – p)/w),w为负样本采样比例(比如采样比例是10%),p是排序模型对单个样本的打分概率,q是矫正后的打分概率。对于个性化搜索和推荐系统来说,他们只关注打分概率的相对顺序,而采样前后的打分概率的相对顺序不会改变,所以不需要校准。
对负样本进行采样,会浪费掉很多负样本。在客户项目中,我们并没有尝试这个方案。
- 对正样本过采样:目的是通过某种方法把正样本的数量变多。如果把正样本过采样到和负样本差不多的量级,会导致总体训练样本量太大,训练时间相对于正样本过采样前的时间变长很多。对正样本如果进行了采样,在计算广告的排序任务中也需要对打分概率做校准,而个性化搜索和推荐系统中的排序任务不需要对打分概率做校准。
在客户项目中我们尝试了这个方案,通过简单复制正样本把正样本数量变成与负样本差不多的样本量,模型的离线效果还不错,就是训练时间相对长,比如一个epoch单机跑都要4,5个小时。正因为这个原因,我们最终没有使用这个方案。
- 每个epoch对负样本采样出和正样本1:1的数量:这样就不浪费负样本,epoch的数量可以根据负样本数量和训练时间来权衡。
我们的做法是这样的,使用tf.keras + tf.data.experimental.sample_from_datasets API 从大量的负样本采样,并与正样本拼接为最终的训练集,结果发现每个epoch后的验证集的AUC不变化。如果说模型已经充分收敛也就是loss基本不变了从而模型参数基本不变化,这个时候验证集的AUC不变化是有可能的,但是模型在刚开始的那些epoch都应该能看到不同的负样本,应该会继续学习而不会收敛,因此在开始的几个epoch验证集AUC应该是变化的。到这里,我推断可能是Tensorflow/TF的坑,可能每个epoch都拟合了一样的负样本并且基本上在第一个epoch以后模型就基本收敛了。
接下来就是找证据,首先从网上看到有 类似的issue,然后去查看TF的源码:tf.keras的fit()函数会通过调用data_adapter.get_data_handler而最终调用DatasetAdapter的初始化函数__init__,而DatasetAdapter的__init__函数中有如下的注释,“Note that the dataset instance is immutable, its fine to reuse the user provided dataset”。 也就是说在tf.keras fit API的每个epoch中会一直重用传入的dataset,也就是每个epoch的dataset是一致的,这也就印证了我们的推断是正确的。所以我们只好放弃这个方案。
- 使用class weight或者sample weight:目的是通过设置权重来让模型更关注正样本。这个方法在很多客户项目中都会使用,实际效果也是很不错。
这个客户的正负样本比例是1:4000,因此每个step的batch size不能太小,太小的话每个step模型看到的正样本太少,对学习正样本的知识不利。最后这个客户上线的模型训练的时候采用如下的方式:直接使用tf.keras的fit API的参数class weight,正样本的class weight设置为(训练集中的负样本数量/正样本数量) * 0.8,负样本的class weight设置为1;为了每个step都尽可能有足量的正样本送入模型,shuffle操作和更大的batch size是需要的(batch size尝试过16K,64K)。
- 使用Focal loss:Focal loss可以做困难样本学习和缓解类别样本不均衡。由于时间关系,这个项目没有尝试这个方案。
调试过程中很快出现了欠拟合
对于欠拟合,简单来说就是模型学习的不够充分。常见的处理方法如下:
- 用更多和更好的特征:
连续特征的特征缩放处理(深度模型对于连续特征的幅度变化很敏感,所以用深度模型建模的话一定要对连续特征做特征缩放处理)。特征缩放的方法有很多,常见的比如Z-score标准化,MinMax归一化,取log,平滑方法(比如贝叶斯平滑)等等。对于历史ctr这样的比率特征,在排序任务中经常会考虑对该特征做平滑,目的是为了让那些历史ctr相等但是曝光次数多且点击次数也多的item经过平滑后得到的值与那些长尾的item区别开来(比如7天内点击1次,曝光2次的item与7天内点击50次,曝光100次的item,虽然他们的点击率相同,但是他们的受欢迎度差别很大,因此这个时候直接用7天内的ctr作为特征对他们来说没有辨识度,这个时候做ctr平滑就很有意义)。
在这个客户的项目中,我们尝试了几种特征缩放方法,包括Z-score标准化,取log。对他的数据集和模型来说,取log的表现比Z-score标准化要好,欠拟合得到缓解。由于时间原因,这个项目中并没有对历史ctr特征进行贝叶斯平滑,这个是以后一个优化的点。
还可以根据业务语义逐渐加入更多的设备侧和广告侧的交叉特征。在项目中我们也尝试了这个方法,欠拟合得到进一步的缓解。
- 增加模型复杂度/容量:
在当前使用的wide & deep排序模型的情况下,增加模型容量可以通过下面两种方式,方法1是把全连接层层数变多或者每层的神经元数量变多,方法2是把embedding向量的长度变大。业界一般做排序模型用到的全连接层常见都是3层,这个项目也是用的3层,我们尝试了把每层的神经元变多。另外,看到很多文章对于排序模型中用到的itemid/usrid embedding table的embedding向量的维度一般都是设置为8或者10(算是一个经验值,在其他项目中也见到一些客户是这样的设置的)。
除了上面提到的这些缓解欠拟合的方法,调整学习率和batch size大小,以及样本类别不均衡的处理方法都可能缓解欠拟合。因此可以看到,缓解欠拟合的组合因素有很多。建议的方式是每次调试只是改变一个因素来进行训练后效果对比(在客户的项目中,经常要同时在SageMaker中跑多个实验来进行对比)。特征缩放肯定是要先做的,除了学习率,batch size以及样本类别不均衡处理这三个因素外,我们可以循序渐进的尝试下面的方法来缓解欠拟合:挖掘一些好的特征(不包含交叉特征,比如一些历史统计特征),接着增加模型复杂度(主要是增加层数或者神经元个数),最后逐渐增加有意义的交叉特征。
欠拟合没有了之后,又发生了过拟合
过拟合指的是模型在训练集上的效果/表现不错,但是在验证集上的表现与训练集上的差距很大。在实际生产项目中,我们更关心模型在训练集上效果不错,在验证集上的效果也不错,在这样的情况下即使过拟合我们也不关心,比如训练集上的AUC是0.95,验证集上的AUC是0.8,那这种情况是属于过拟合了,但是验证集的AUC也足够高了,所以这个情况我们能接受;如果是训练集上的AUC是0.95,验证集上的AUC是0.6,这种过拟合就是我们需要关心的了。欠拟合到过拟合,有时候就是一瞬间的事情(比如特征一下子加多了就容易从欠拟合变成过拟合)。对于使用深度模型做排序任务的场景,过拟合常见的处理方式如下:
- 收集更多的数据 :目的是让模型能更多的见到不同的数据分布,从而学习到不同的知识。比如T+1训练中的T常见的是7天的数据作为训练集(当然这个T取多少和训练集中的正样本量有多少有很大关系),在我们这个项目中,T取的是30天的数据,因此能获得更多的样本尤其是正样本。
- 减少模型复杂度/容量:也就是使用小一点的神经网络,包括小一点的embedding table,目的是让神经网络和embedding table的容量变小。在实际的项目中,我见到过有的客户把itemid/userid embedding table的embedding向量的长度设置为几百几千的,不建议这样,太容易过拟合了,就像前面提到的,设置为8左右就是一个不错的起点。注意这里的embedding指的是input embedding,而关于output embedding以及文本embedding向量长度的选择可以参考我的github中的文章推荐系统概览。
- 使用BatchNormalization(简称BN,本质是对神经元的激活值进行整形,它在Deep Learning中非常有用,建议尽量用):使用BN的话,batch size不能太小,而batch size的调整一般伴随着同方向的learning rate的调整(也就是把batch size调大的话,learning rate可以适当调大一点点)。虽然BN主要是在CNN卷积层用的比较多,但是MLP层也可以用,RNN的话要用LayerNormalization(简称LN)。在当前项目中,使用BN后的离线效果提升很明显。
- 使用Early stopping早停:监控模型在验证集的metric,并early stopping早停。Early stopping并不是必须的,如果设定模型固定跑的epoch数量,之后选择一个表现最好的epoch的checkpoint也是可以的,这个情况下就不需要early stopping。
- 正则化方法:在深度学习中,常用的正则化方法是Dropout,L1/L2正则,Label标签平滑等。当前项目使用了dropout和L1/L2正则。Dropout的比率以及L1/L2正则的超参数在调试的时候,都要小步调整,大幅调整很容易一下子就从过拟合到了欠拟合了。
- 使用更少的特征:在这个项目中,一下子增加了几种交叉特征后,模型从欠拟合到了过拟合。然后在去掉了几个交叉特征之后,过拟合得到缓解。因此加入新的特征要一点点加,小步走。
在使用深度模型发生过拟合的时候,首先要检查验证集的数据分布(比如每个连续特征的统计分布,每个离散特征的覆盖度,和训练集中的数据分布做一下对比)。如果训练集和验证集的数据分布相差很多,考虑如何重新构造训练集和验证集;否则,建议尝试按照如下的顺序来缓解(每做完一步就训练看效果,如果验证集的效果能接受了,就先打住;否则继续下一步):使用BN(基本上是标配)——使用更少的特征(如果特征本身就不多,可以跳过;主要关注交叉特征是否很多)——收集更多的数据(如果正样本量已经足够多,可以跳过这步)——使用正则化方法——减少模型复杂度/容量(尤其要注意embedding table中embedding向量的长度)
项目中遇到的其他问题
- 数据集变了,模型的离线评估AUC变化很大:
数据集变大可能会导致容量小的模型效果变差,发生欠拟合。对于CTR/CVR任务,训练流程跑通以后,用固定滑窗的数据集来训练调试模型;而一般固定滑窗内的数据集的量级差不多。数据集的清洗和预处理每天都要保证一致性的行为,否则出问题调试很花时间。
要尽量保证特征的线上线下一致性(更多细节可以参考我的另一个文章“Data-centric AI之数据集的质量”)。
- 同样的数据集和同样的模型,两个实验对比,发现对验证集的评估指标AUC有差别:
ML带入的随机性很多,所以最好在上下文尽量一致的情况下对比,包括超参数的设置,训练任务的相关参数和随机种子fix(这个非常重要,包括python random seed和tensorflow.random rseed都需要fix)。
- 经常发现在分布式训练中模型的评估指标比单机训练的评估指标要差:
这个是很常见的。使用分布式训练甚至只是单机多卡的时候,学习率可能不适合还用单机单卡训练的学习率,适当需要调整。对于horovod分布式训练方式,一般来说,把学习率变大一点就好,不能完全按照horovod官网建议的那样即用worker数量乘以之前单机单卡的学习率作为调整后的学习率(这个可能会得到很大的学习率,从而导致模型学习效果不好)。对于parameter server分布式训练的异步梯度更新方式,可能需要把学习率调小,为了让最慢那个stale model replica的更新对整体的影响小一些。
- 特征的覆盖度问题:
如果某些离散特征的特征值的样本出现频率很低比如少于10次,那么可以考虑特征向上合并或者把那些小类别统一归并为”Other”。这个方法在客户的另一个项目LightGBM模型中使用了,效果不错。对于那些长尾的itemid或者长尾的usrid,也可以考虑把这些长尾的id的样本给剔除。更多详细的关于特征覆盖度的问题,可以参考我的另一个文章“Data-centric AI之数据集的质量”。
- Hash trick的使用:细分为hash后提升维度和降低维度两个方向。
如果单个离散特征在训练集中出现的唯一值个数不大(也就是说基数小),可以利用特征hash来分桶,桶的大小可以考虑几倍于训练样本中该离散特征出现的唯一值个数。这个方法的目的就是,在尽量降低hash冲突的情况下,不用提供额外的映射表就可以在hash分桶后直接embedding(因为embedding table的索引是从0开始的)。当前项目中使用了这个方法,对一些离散特征做了特征hash分桶(hash桶的size是离散特征的基数的3~5倍)。
反过来,如果单个离散特征(比如usrid或者itemid)在训练样本中唯一值数量非常大(也就是说基数很大),那可以使用特征hash来降维(这里有个隐含的假设,高基数id类特征的样本比较稀疏,多个不同id落入同一个hash桶之后会公用一个embedding向量,这个embedding向量可以装下多个不同id的知识)。Hash bucket size的选择可以用训练集中的这个id特征的基数开4次根号为一个尝试起点。当前项目中,对一些高基数的id类特征使用了这个方法来降维。客户的另一个项目中想使用Amazon SageMaker 内建算法object2vec学习item的embedding,但该算法对id有300w的限制,客户非低频的itemid超过300w,这个时候可以用特征hash来降维后再使用object2Vec。
总结
排序模型的调优实践到此就讲完了,本文以一个客户的具体项目为例,详细介绍了排序模型调优过程遇到的挑战和处理方法。到此为止,整个推荐系统系列的讲解也结束了。整个系列文章比较完整的涵盖了推荐系统的核心内容,包括推荐系统概览,推荐系统的召回阶段深入探讨,排序阶段的样本工程和排序模型的调优实践,相信大家现在已经对推荐系统有了更深刻的理解。推荐系统和CV以及NLP相比而言,是一个更大层面的东西,CV和NLP是技术领域的划分,而推荐系统更像是业务/工程领域,你可以把CV和NLP的技术用到整个推荐系统的工程当中。把一个完整的推荐系统上线,短时间很难做到,因为它涉及到的不只是机器学习领域,还有很多工程领域的技术,而使用Amazon Personalize这样的AI SaaS服务可以帮助你短时间做到从0到1的推荐系统的搭建。再次感谢大家的耐心阅读。