亚马逊AWS官方博客
利用 Slurm + ParallelCluster 多集群解决方案,助力云端高性能计算
背景
在云上进行高性能计算的客户越来越多,利用云计算资源充足、按需使用、弹性伸缩的特点,客户不仅能快速的得到结果,而且成本很低。为了让客户能快速的部署高性能计算集群,AWS 推出了开源的ParallelCluster 集群管理软件,该软件可以让客户在数分钟之内部署一个高性能计算集群。ParallelCluster支持Torque、Slurm、SGE等调度引擎,集群的大小可以根据任务数量动态伸缩,而且支持SPOT实例,能最大程度的帮助客户降低成本。
在某些高性能计算场景中,客户会同时使用到CPU实例和GPU实例,这样就需要创建两个ParallelCluster集群,比如,一个是c5.xlarge集群和一个p3.2xlarge实例集群。并且客户的程序通常运行在一个主节点上,这就要求可以在一个主节点上提交任务到任意集群。而ParallelCluster 则要求到两个集群的主节点上分别提交任务,这种情况下,如果客户要使用ParallelCluster ,必须需要修改程序,不仅耗时耗力,而且需要改变用户原来的使用习惯,很难快速使用起来。
Slurm +ParallelCluster 多集群解决方案,在两个ParallelCluster集群前面增加一个管理节点,通过该管理节点可以提交任务到任意集群,这样,客户的程序可以运行在管理节点上,不需要做任何改变。
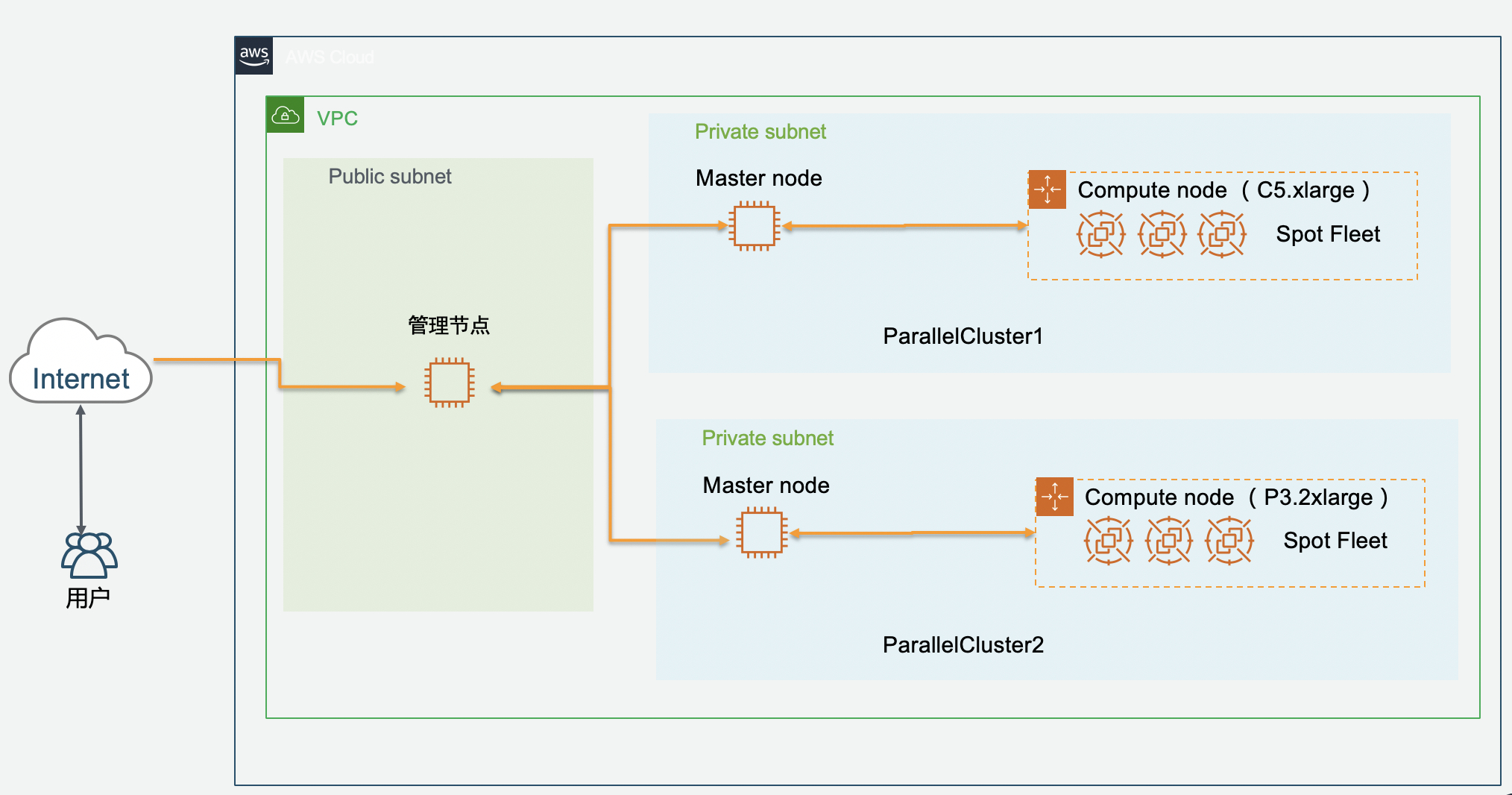
这种方案不仅满足了客户多种实例类型的要求,而且保留了ParallelCluster弹性伸缩优点,可以支持SPOT实例,多个集群可以通过EFS共享数据。目前已经有客户通过该方案在AWS上进行高性能计算。
Slurm +ParallelCluster 多集群解决方案
Slurm +ParallelCluster多集群架构如下:
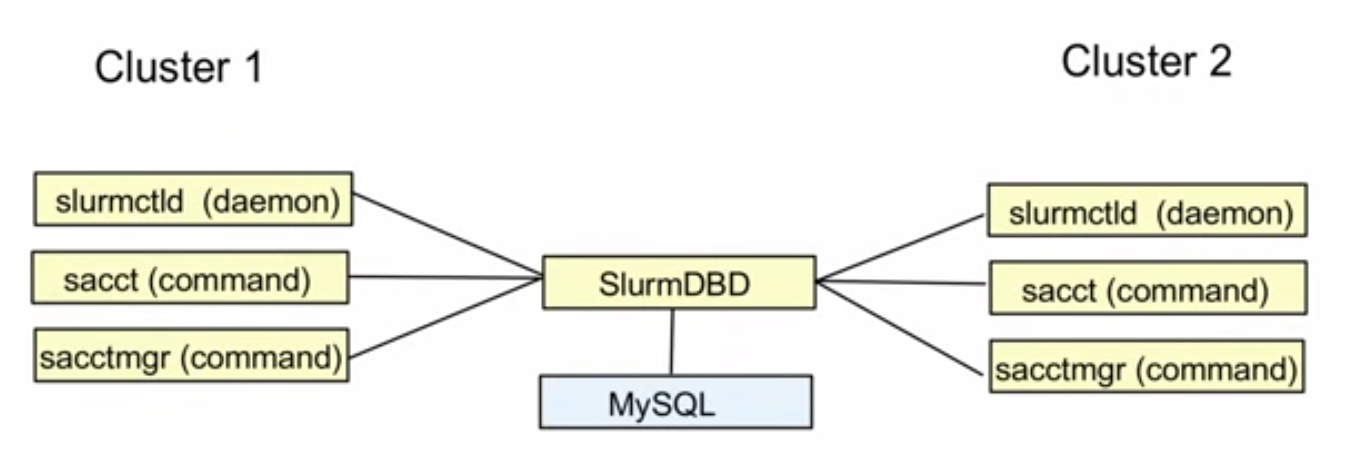
该方案把两个ParallelCluster集群的Slurm accounting信息存储在一个独立的管理节点(SlurmDBD所在节点)上,并保存在MySQL数据库中,这样在管理节点可以提交任务到任意的集群上。
以下是Slurm +ParallelCluster多集群方案详细配置步骤,主要包含以下几个步骤:
- 使用ParallelCluster创建两个slurm集群,两个集群通过EFS共享数据
- 创建并配置Slurm管理节点
- 注册第一个ParallelCluster集群到管理节点
- 注册第二个ParallelCluster集群到管理节点
- 检查配置并提交测试任务
创建两个ParallelCluster集群
ParallelCluster的安装步骤在这里不再赘述,在参考资料中有ParallelCluster的配置链接。
使用ParallelCluster创建两个集群,集群名称分别为 parallelcluster和pcluster2,每个节点初始配置为一个master node和两个compute node。
1.创建第一个集群
配置文件中需要增加EFS的配置,完整的配置文件参考附录。
[efs customfs]
shared_dir = efs
encrypted = false
performance_mode = generalPurpose
创建第一个集群:
88e9fe506815:~ liangmao$ pcluster create parallelcluster
2.创建第二个集群
创建第二个集群时,需要在集群配置文件中指定第一个集群的efs_fs_id,efs_fs_id需要根据实际情况进行修改。
[efs customfs]
shared_dir = efs
encrypted = false
performance_mode = generalPurpose
efs_fs_id = fs-165884bd
创建第二个集群:
88e9fe506815:~ liangmao$ pcluster create pcluster2
创建Slurm 管理节点
Slurm管理节点需要部署在单独的服务器上,运行SlurmDBD进程,并且通过Munge进行身份认证,Slurm管理节点可以使用pcluster集群的master node创建AMI,再从AMI中创建,这样做有以下几个好处:
- 不用安装Munge和Slurm,master node中已经包含。
- 管理节点的Slurm和Munge用户的uid和gid和pcluster集群保持一致
- 不用再额外配置Munge key,使用pcluster创建的key即可。
1.使用集群的master node创建AMI
可以在管理控制台上创建AMI:

2.使用AMI创建管理节点
在管理控制台上创建管理节点,使用上一步创建的AMI。
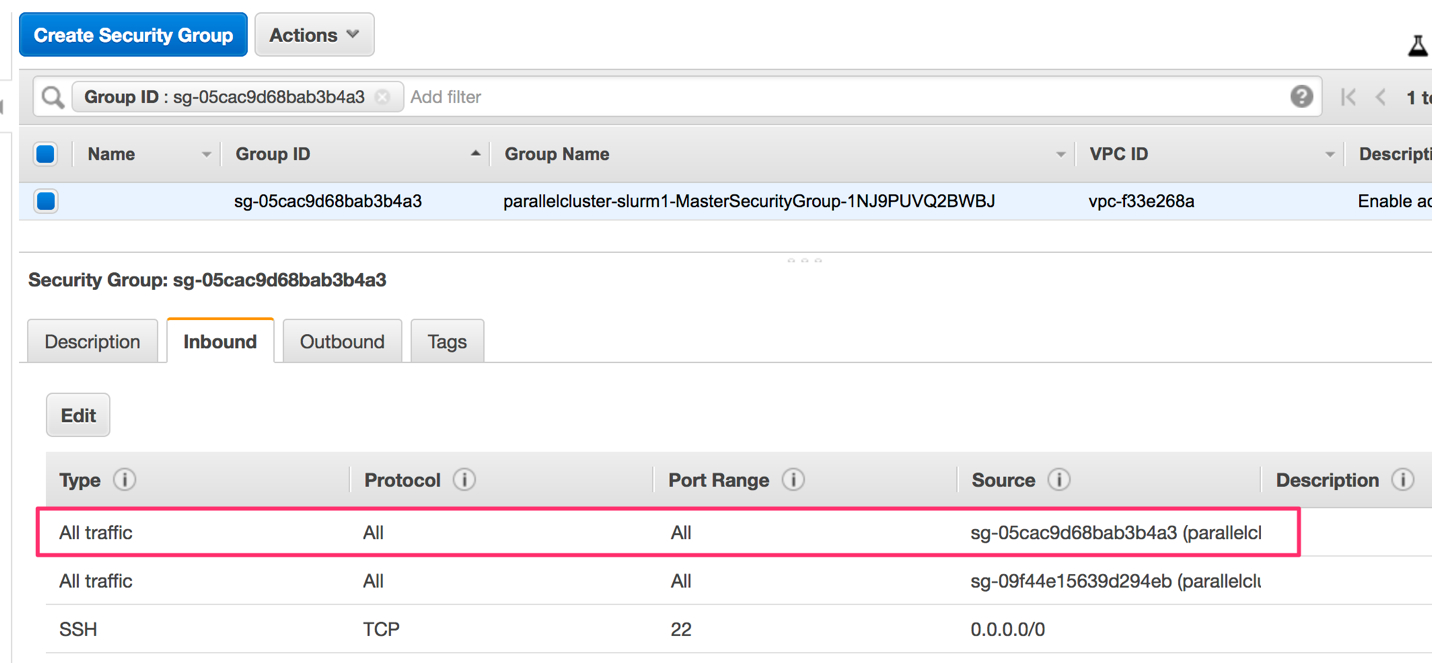
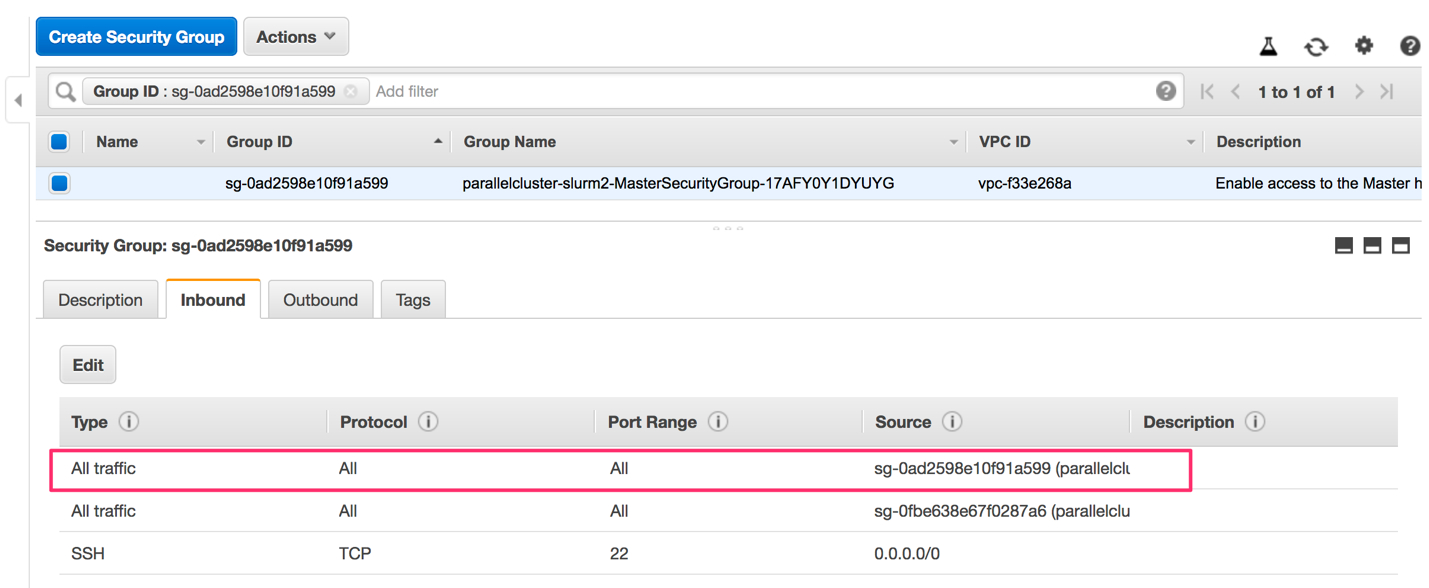
注意:要把管理节点加入两个slurm master的安全组。

另外,两个slurm master的安全组需要增加一条规则,允许安全组内的实例互相访问。
3.在管理节点上安装和配置MySQL
sudo yum install mysql
sudo yum install mysql-server
sudo yum install mysql-devel
service mysqld start
/usr/bin/mysqladmin -u root password <password>
chkconfig –add /etc/init.d/mysqld
chkconfig mysqld on
mysql -u root -p
create database slurm_acct_db;
create user ‘slurm’@’localhost’ identified by ‘<password>’;
create user ‘slurm’@’%’ identified by ‘<password>’;
GRANT ALL PRIVILEGES ON slurm_acct_db.* TO ‘slurm’@’localhost’;
GRANT ALL PRIVILEGES ON slurm_acct_db.* TO ‘slurm’@’%’ ;
4.修改SlurmDBD配置文件/opt/slurm/etc/slurmdbd.conf
[ec2-user@ip-172-31-30-63 ~]$ more /opt/slurm/etc/slurmdbd.conf
#
# slurmDBD info
#DbdAddr=192.168.80.13
DbdHost=localhost
#DbdBackupHost=node14
DbdPort=6819
SlurmUser=slurm
#MessageTimeout=60
#DebugLevel=6
#DefaultQOS=normal
LogFile=/var/log/SlurmdbdLogFile
PidFile=/var/run/slurmdbd.pid
PluginDir=/opt/slurm/lib/slurm
#PrivateData=accounts,users,usage,jobs
#TrackWCKey=yes
#
# Database info
StorageType=accounting_storage/mysql
StorageHost=localhost
StoragePort=3306
StoragePass=<password>
StorageUser=slurm
StorageLoc=slurm_acct_db
5.启动slurmdbd进程
#/opt/slurm/sbin/slurmdbd
可以查看日志文件/var/log/SlurmdbdLogFile是否有报错。
[2019-05-27T06:45:59.410] error: Processing last message from connection 10(172.31.23.185) uid(496)
[2019-05-27T06:45:59.494] error: Processing last message from connection 10(172.31.23.185) uid(496)
[2019-05-27T13:24:08.546] error: Problem getting jobs for cluster test
[2019-05-27T14:45:34.646] error: Problem getting jobs for cluster test
[2019-05-28T02:45:39.496] error: Database settings not recommended values: innodb_buffer_pool_size innodb_log_file_size innodb_lock_wait_timeout
[2019-05-28T02:45:39.537] error: chdir(/var/log): Permission denied
[2019-05-28T02:45:39.537] chdir to /var/tmp
[2019-05-28T02:45:39.538] slurmdbd version 18.08.6-2 started
注:日志建议修改innodb的参数innodb_buffer_pool_size innodb_log_file_size innodb_lock_wait_timeout,可以按实际要求修改。
6.修改/opt/slurm/etc/slurm.conf
测试中发现要在管理节点上执行slurm 相关命令,会检查slurm.conf文件中的配置。因管理节点没有集群,可以把ClusterName和ControlMachine改成任意一个名称和地址,以免和另外两个集群冲突,并注释最后两行配置。
ClusterName=dummy
ControlMachine=dummyip
…
#include slurm_parallelcluster_nodes.conf
#PartitionName=compute Nodes=ALL Default=YES MaxTime=INFINITE State=UP
注册第一个集群到管理节点
1.修改master node slurm.conf配置文件
修改/opt/slurm/etc/slurm.conf配置,主要是以下几个配置,其中ip-172-31-30-63为管理节点的主机名。
ClusterName=parallelcluster
ControlMachine=ip-172-31-20-39
# JobComp
JobCompType=jobcomp/mysql
JobCompHost=ip-172-31-30-63
JobCompPort=3306
JobCompPass=<password>
JobCompUser=slurm
JobCompLoc=slurm_acct_db
#
# ACCOUNTING
JobAcctGatherType=jobacct_gather/linux
#JobAcctGatherFrequency=30
#
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageHost=ip-172-31-30-63
2.重启slurmctld进程
[root@ip-172-31-20-39 ~]# /etc/init.d/slurm stop
stopping slurmctld: [ OK ]
slurmctld is stopped
slurmctld is stopped
[root@ip-172-31-20-39 ~]# /etc/init.d/slurm start
starting slurmctld: [ OK ]
3.查看/var/log/slurmctld.log日志是否有报错
4.注册集群到管理节点
#sacctmgr add cluster parallelcluster
5.查看是否注册成功
用sacctmgr list cluster 查看ControlHost,ControlPort的信息是否为空,如果为空,表示注册失败,可以尝试重启slurmctld。

注册成功的日志如下:
检查 /var/log/slurmctld.log:
[2019-05-27T14:35:17.062] cons_res: select_p_node_init
[2019-05-27T14:35:17.062] cons_res: preparing for 1 partitions
[2019-05-27T14:35:17.062] Running as primary controller
[2019-05-27T14:35:17.062] Registering slurmctld at port 6817 with slurmdbd.
[2019-05-27T14:35:17.326] No parameter for mcs plugin, default values set
[2019-05-27T14:35:17.326] mcs: MCSParameters = (null). ondemand set.
注册第二个集群到管理节点
1.修改master node slurm.conf配置文件
修改/opt/slurm/etc/slurm.conf配置,主要是以下几个配置,其中ip-172-31-30-63为管理节点的主机名。
ClusterName=pcluster2
ControlMachine=ip-172-31-23-185
# JobComp
JobCompType=jobcomp/mysql
JobCompHost=ip-172-31-30-63
JobCompPort=3306
JobCompPass=slurm
JobCompUser=slurm
JobCompLoc=slurm_acct_db
#
# ACCOUNTING
JobAcctGatherType=jobacct_gather/linux
#JobAcctGatherFrequency=30
#
AccountingStorageType=accounting_storage/slurmdbd
AccountingStorageHost=ip-172-31-30-63
2.重启slurmctld进程
[root@ip-172-31-20-39 ~]# /etc/init.d/slurm stop
stopping slurmctld: [ OK ]
slurmctld is stopped
slurmctld is stopped
[root@ip-172-31-20-39 ~]# /etc/init.d/slurm start
starting slurmctld: [ OK ]
3.查看/var/log/slurmctld.log日志是否有报错
4.注册集群到管理节点
#sacctmgr add cluster pcluster2
5.查看是否注册成功
用sacctmgr list cluster 查看ControlHost,ControlPort的信息是否为空,如果为空,表示注册失败,可以尝试重启slurm。

注册成功的日志如下:
检查 /var/log/slurmctld.log:
[2019-05-27T14:42:31.654] cons_res: select_p_reconfigure
[2019-05-27T14:42:31.654] cons_res: select_p_node_init
[2019-05-27T14:42:31.654] cons_res: preparing for 1 partitions
[2019-05-27T14:42:31.654] Running as primary controller
[2019-05-27T14:42:31.654] Registering slurmctld at port 6817 with slurmdbd.
[2019-05-27T14:42:31.912] No parameter for mcs plugin, default values set
[2019-05-27T14:42:31.912] mcs: MCSParameters = (null). ondemand set.
运行测试任务
登陆管理节点,执行以下脚本:
可以在管理节点上看到两个集群,并且可以把测试命令hostname发送到不同的集群。
附录
1.ParallelCluster 集群config文件
88e9fe506815:.parallelcluster liangmao$ cat config
[aws]
aws_region_name = us-west-2
[global]
cluster_template = gputest
update_check = true
sanity_check = true
[cluster default]
key_name = <keypair name>
vpc_settings = public
[cluster gputest]
key_name = oregon
vpc_settings = public
compute_instance_type = c5.large
master_instance_type = c5.large
initial_queue_size = 2
max_queue_size = 10
maintain_initial_size = yes
scheduler = slurm
cluster_type = ondemand
placement_group = DYNAMIC
placement = cluster
shared_dir = public
master_root_volume_size = 20
compute_root_volume_size = 20
base_os = alinux
scaling_settings = custom
efs_settings = customfs
[efs customfs]
shared_dir = efs
encrypted = false
performance_mode = generalPurpose
[scaling custom]
scaledown_idletime = 60
[vpc public]
vpc_id = vpc-f33e268a
master_subnet_id = subnet-82e999fb
[aliases]
ssh = ssh {CFN_USER}@{MASTER_IP} {ARGS}
参考资料
ParallelCluster官方文档:
https://aws-parallelcluster.readthedocs.io/en/latest/
Slurm官方文档:
https://slurm.schedmd.com/overview.html
Multi-cluster配置:
https://slurm.schedmd.com/multi_cluster.html
Accounting and Resource Limits
https://slurm.schedmd.com/accounting.html
Slurm下载链接:
https://www.schedmd.com/downloads.php
Slurm安装步骤:
https://slurm.schedmd.com/quickstart_admin.html
Munge下载链接:
Munge安装步骤
https://github.com/dun/munge/wiki/Installation-Guide