亚马逊AWS官方博客
使用 Amazon SageMaker 通过自定义数据集训练模型
近年来,人工智能尤其是机器学习深度学习技术,成为了时下热门的讨论话题和研究方向。在前不久结束的re:Invent 2018大会上,AWS新发布了很多机器学习相关的新服务新功能,满足不同层次、不同场景的客户需求。
学习如何进行机器学习并不是一个简单的任务。目前大多数的机器学习相关的DEMO或者示例,都是通过已经制作完成并经过清洗检验的公开数据集进行演示测试。这些数据集往往是经过压缩和特定格式转换后的结果,例如 MXNet 的 RecordIO 数据格式,而不是常见的一张张jpeg或png图片。而对于刚上手机器学习的从业人员而言,业务需求所需要呈现的结果,往往不仅是用这些公开数据集就能够训练出合适的模型。我们往往只有少量的业务相关数据,甚至这些数据也需要从零开始收集整合,而这之后还需要进行数据清洗、数据打标签、特定数据格式转化等复杂的制作特定数据集的步骤,这些工作会阻塞住我们前进的脚步。
除了容易在数据集上举步不前外,对于所需要数据量的误解也是另外一大阻碍因素。我们总认为进行机器学习需要“大量”的数据,究竟需要多少数据?在仅有少量数据时就不能训练出准确率较高的模型?本文试图从零开始,从制作自己的数据集开始,来探讨上面提出的问题。
环境准备
我们将利用 Amazon SageMaker 提供的托管 Jupyter 笔记本来进行动手实验。Amazon SageMaker 提供了实验中所需要用到的训练和预测容器,该容器也能直接用做最后模型生成好后的部署操作。当然你也可以选择在了解工作流程后自己实现训练和预测的定制化容器,并上传到 Amazon ECR 服务中。
登录 AWS 管理控制台并转至 Amazon SageMaker 控制台。在控制面板界面点击笔记本实例,再点击创建笔记本实例按钮,进入创建笔记本实例页面。
出于本博客实践的目的,我们将执行以下操作:
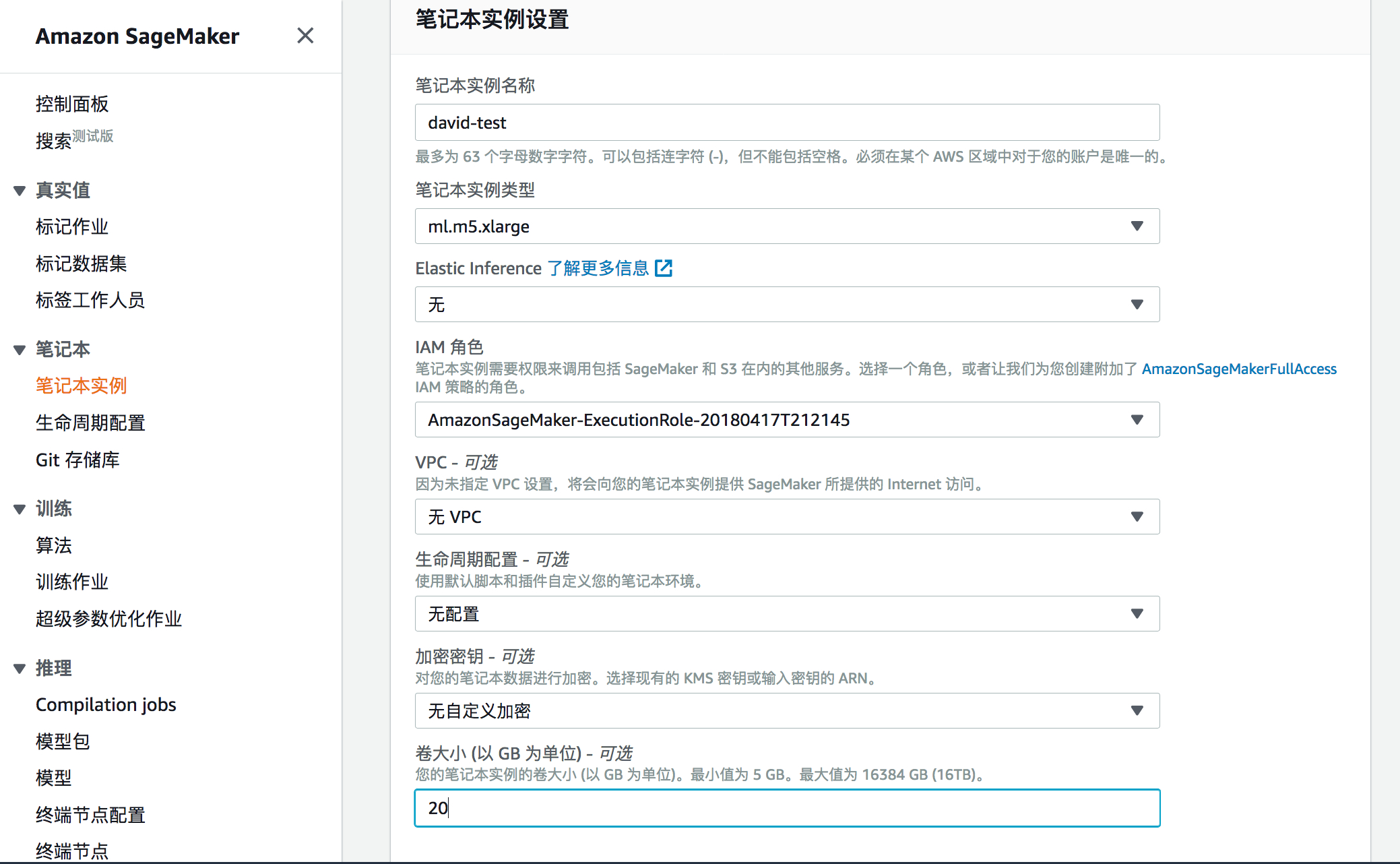
- 给笔记本实例起一个名字。
- 您可以从下拉列表中选择任何实例选项,但是我们建议至少使用m5.xlarge及以上的类型。
- 创建新的IAM角色或附加现有角色。确保此IAM角色允许Amazon S3 Bucket的正常访问。此访问权限是您为 Amazon SageMaker 创建新IAM角色时获得的默认访问权限之外的访问权限。对于这篇博客,这些权限应该足以启动,但是,如果要进一步缩小权限范围并将其限制为指定资源,请参考文档中对Amazon SageMaker 角色的介绍。
- 设置实例的卷大小为20GB,您可以选择设置的更大以便进行更多的模型训练与测试。
- 保留其余设置选项为默认设置。
点击创建笔记本实例按钮,你应该能看到该笔记本实例正在创建中(Pending)。等待笔记本实例的状态从Pending变化到InService。

笔记本实例状态切换到InService后,选择打开 JupyterLab。新打开的页面将会自动跳转到笔记本实例之中。
现在您拥有一台完全正常工作的Jupyter笔记本实例,其中包含预先配置和预先构建的各种不同的代码编写环境,包含TensorFlow和MXNet等。

选择Launcher界面中Other栏目下的Terminal,来打开一个新的Terminal环境。
我们接下来的实验将在这个笔记本实例上进行。
数据整合(收集、预处理、清洗)
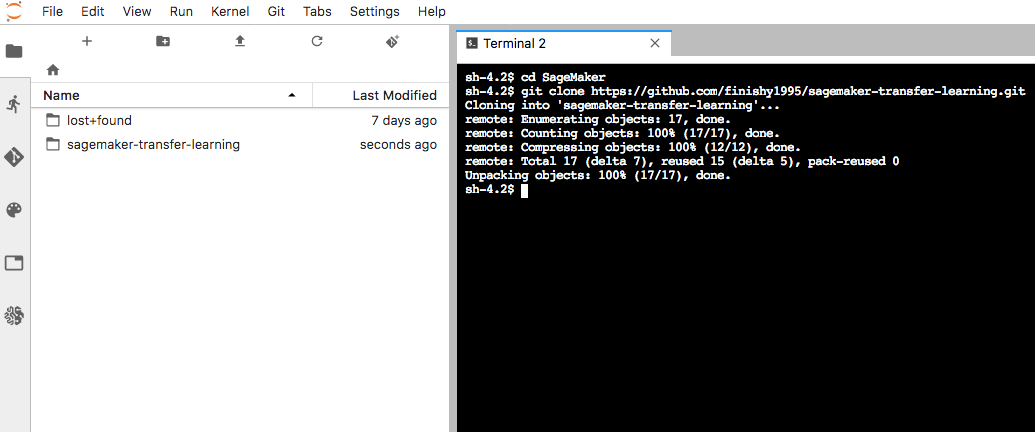
首先,我们将先从Git代码库中克隆整个项目,用做数据整合。在Terminal窗口中,执行以下命令:
cd SageMaker
git clone https://github.com/finishy1995/sagemaker-transfer-learning.git
点击左侧文件列表中刚下载好的文件目录‘sagemaker-transfer-learning’,再打开crawler.py文件。您可以查看这段通过python编写的爬虫程序,爬取网站上的图片并保存为jpeg格式的图片,存取在Amazon S3对象存储服务中,作为原始的数据集。如果您有自己业务相关的数据,可以仿照这些步骤把原始数据上传到Amazon S3之中。
在这段脚本中,我们同时做了简单的数据清洗工作。利用Amazon Rekognition图像视频识别服务,筛选爬虫爬取的图片,把具有多个特征和特征不明显的图片从数据集中去除。

对应于其他图片甚至其他类型的业务数据,可以使用最新发布的数据处理服务Amazon SageMaker Ground Truth(以下简称Ground Truth)进行数据打标签和数据清洗的任务。
Ground Truth 可帮助您快速构建用于机器学习的高准确度培训数据集。Ground Truth 可轻松访问公有和私有人工标识器,并为它们提供常见标记任务的内置工作流和界面。此外,Ground Truth 通过使用自动标记功能,最多可降低 70% 的标记成本。自动标记的工作原理如下:根据人工标记的数据培训 Ground Truth,从而使服务学会独立标记数据。
下面,关闭crawler.py文件并回到Terminal之中,运行以下命令:

cd sagemaker-transfer-learning
bash ground-truth-setup.sh
在命令成功执行完成之后,我们拿到了随机生成的Amazon S3存储桶中存储描述原始数据集的文件路径s3://sagemaker-data-labeling-2019011706-12221/data.json(注:由于bash脚本生成的是随机存储桶名,请复制输出在命令行中的文件路径),并复制这个文件路径以便后续的操作中使用。
在正式使用Ground Truth服务之前,让我们花些时间看一下启动脚本ground-truth-setup.sh中都执行了什么操作:
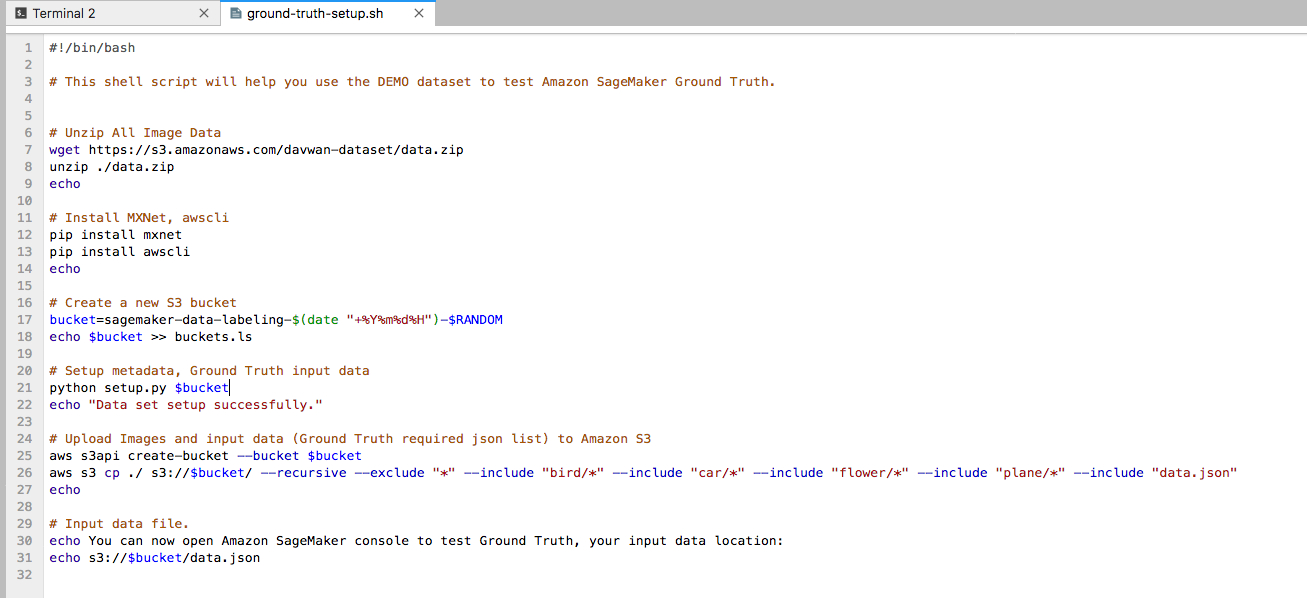
在这段脚本中,我们执行了以下操作:
- 下载前面步骤中由爬虫脚本爬取的原始数据,并解压。(这里可以替换为自己的业务数据)
- 在Amazon SageMaker托管的Jupyter笔记本实例中安装必要的软件包和依赖。
- 执行初始化程序,生成文件目录和描述文件。
- 创建Amazon S3存储桶,并将存储桶名记录到本地,将数据集和描述文件全部上传到新生成的存储桶中。
- 在命令行下输出文件路径。
生成的数据集描述文件格式如下:

把原始数据集描述文件生成并上传完成后,下面让我们使用Ground Truth进行打标签和清洗的工作。
回到AWS控制台上,并选择Amazon SageMaker中的“标记作业”(Labeling jobs),点击右上角的Creating labeling job按钮:

出于本博客实践的目的,我们将执行以下操作:
- 给标记作业起一个名字。
- 在Input dataset location中,复制上我们前文生成的配置文件路径,例如s3://sagemaker-data-labeling-2019011706-12221/data.json。
- 在Output dataset location中,输入结果存放在Amazon S3中的路径,例如s3://sagemaker-data-labeling-2019011706-12221/output。
- IAM 角色设置为前文创建好的角色。
- 保留其余设置选项为默认设置。

选择Worker types为Public,并勾选下方的两个选择框。如果您的业务数据中有敏感数据,建议选择Private并输入内部员工的邮箱地址;如果您有其他的数据处理厂商帮助您做数据处理,可以选择Vendor managed。

定义一下任务的内容,您可以像下方一样输入您的任务。或者,您可以在会话框中详细的描述任务的具体要求和结果,并编写一个或多个好示例和坏示例,使得任务正确按照预期结果进行。

在点击submit按钮后,任务将正式提交。请注意,本博客中的这项任务会花费约420美金的费用。
在任务的状态由In progress变为Complete后,您可以在设置好的Output dataset location 处查询数据标记的结果。

标记结果中不仅包含每条数据的标记输出值,还会对每项输出值给出置信度、标记人员等其他详细信息,您可以针对这些信息做进一步的数据清洗和处理。
回到Jupyter笔记本中,在Terminal之中运行以下命令:
bash ground-truth-clean.sh
命令成功运行后,Ground Truth测试所生成的资源将全部清空。
模型训练及部署
在Jupyter笔记本中,打开transfer-learning-setup.sh文件。这段脚本执行的操作与上文中的启动脚本的功能类似。最后在生成了必要的描述文件后,调用了lst_handler.py,用于把由jpeg格式的图片组成的数据集,分为训练和验证数据两个文件的RecordIO数据格式。

前文中由爬虫爬取的图片主要是四类图片:花、汽车、鸟、飞机,分别分配1200、1000、1200、300组不同的数据在目标数据集中。将数据打散后,按照0.9的比率拆分训练和验证数据,即训练数据是验证数据的9倍。

看完这些文件中执行的操作后,让我们直接开始生成这次训练需要用到的数据集,在Terminal中执行如下命令:
bash transfer-learning-setup.sh

如果在这一步中无法正确生成train_train.lst、train_train.rec等文件,请执行以下操作:
- 在Terminal中输入exit退出当前环境。
- 打开新的Terminal,输入cd SageMaker/ sagemaker-transfer-learning进入工作目录
- 重新执行bash transfer-learning-setup.sh
成功生成需要的文件后,打开ipython文件Image-classification-transfer-learning-highlevel.ipynb。
按照顺序执行ipython中的步骤,首先配置S3中的环境,读取用于本次训练的容器地址。

把前文生成的RecordIO数据上传到训练环境中S3的指定路径下。

配置本博客下的实验参数,使用1台ml.p2.xlarge机型进行训练,设置迁移学习的对象为SageMaker里预训练好的18层神经网络,设置输入图片的形状为224*224的rgb图片,设置训练例子为3329个,最小的训练批大小为12,学习速率为0.001。以上训练参数可以视具体任务的不同进行修改,也可以通过Amazon SageMaker的自动调参功能(不需要编写交叉验证代码)快速选择较好的参数。更多参数设置请查阅官方SDK。

执行训练任务,并等待迁移学习完成。

数分钟之后,训练任务完成,我们最终得到了一个具有97.8%预测准确率的模型。


我们可以选择直接调用SageMaker中现成的部署函数把模型部署成API的形式,供应用直接调用。

清理环境删除资源
在测试完成后,调用删除函数把部署的终端节点删除。

回到AWS控制台,在Amazon SageMaker控制台页面下,分别点击模型、终端节点配置和笔记本实例,删除本博客生成的资源,删除模型如下。

结论
除了文中的测试之外,我们又对不同的数据集规模对迁移学习下的模型准确率影响进行了测试:
| 类别 | 花样本 | 汽车样本 | 鸟样本 | 飞机样本 | 训练数据比 | 准确率 |
| 1 | 1200 | 1000 | 1200 | 300 | 0.9 | 97.8% |
| 2 | 200 | 200 | 200 | 200 | 0.9 | 97.2% |
| 3 | 100 | 100 | 100 | 100 | 0.9 | 91.7% |
以上数据在同一组参数的设置下进行,仅数据集规模的不同导致最后训练准确率有差异,并非训练的极限值。使用迁移学习,仅需要少量的样本也能够达到比较高的准确率,而其他场景使用其他算法训练究竟需要多少数据,是不是一定需要非常大规模的数据量才能产生可以接受的结果,这些都可以通过快速的原型验证来发现。而AWS正是为机器学习这种快速实验、快速试错创造了广阔的舞台。
最后,我希望通过这篇博客能够给您一些动手机器学习的指导,特别是使用Amazon SageMaker快速的测试、验证并最终实现自己的想法。Amazon SageMaker覆盖了从数据打标签到最终模型部署一整套的步骤支持和现成的容器化方法,使得开发人员和数据科学家可以专注于他们所擅长的业务以及科学研究之中。SageMaker中包含了对常用机器学习框架如TensorFlow、MXNet、Pytorch等的支持,同时包含了大量的代码示例和步骤指导。您可以使用您喜欢的任何机器学习框架和算法,结合其他的AWS服务(如Amazon S3,Amazon CloudWatch,Amazon ECR和AWS IAM)来运行您的业务。