亚马逊AWS官方博客
三剑客 EKS + Kubeflow + Karpenter 助力构建弹性机器学习平台
随着机器学习的不断发展和在各个行业的使用,很多企业已经从最初关注构建模型,算法选择到了现在如何构建自己的机器学习平台,在该平台上实现从数据处理、模型训练、模型部署和CI/CD。现在机器学习平台有很多,比较受欢迎的机器学习平台有亚马逊云科技的托管服务SageMaker和开源的Kubeflow、MLflow等。本文结合用户的场景,使用Kubeflow构建一个弹性可灵活扩展的机器学习平台。
Kubeflow 是 Kubernetes 的机器学习工具包, 目标是利用 Kubernetes的优点,尽可能简单地扩展机器学习 (ML) 模型并将它们部署到生产环境。在Kubernetes部署选择上,我们根据用户的使用情况选择了Amazon Elastic Kubernetes Service (Amazon EKS) ,它是一项托管容器服务,可以在云中和本地运行和扩展 Kubernetes 应用程序。最后我们会选择三剑客中的第三项,Karpenter, Karpenter 是使用 AWS 构建的开源、灵活、高性能的 Kubernetes 集群自动扩缩程序。它通过快速启动适当规模的计算资源来响应不断变化的应用程序负载,从而帮助提高应用程序可用性和集群效率。Karpenter特别适合该用户在机器学习中对于成本优化的需求,在无需配置任何GPU节点组情况下,快速的获得GPU资源进行模型训练和在训练结束后快速释放GPU资源。本方案中,我们会专注于使用这三个服务,构建弹性的机器学习平台。
本方案部署在北京区域进行,本文通过四个部分总结如何在中国区搭建Kubeflow 1.5.1并利用Karpenter进行动态的进行GPU资源的扩展满足Kubeflow ML 训练的需求。
- 准备环境
- 部署Kubeflow
- 验证Kubeflow的安装,包含实验
- 利用 Karpenter 进行动态的资源扩展满足Kubeflow ML 训练的需求
需要的服务和架构如下图:

准备环境
准备环境主要分为四部分:
- 安装必要的工具
- 创建EKS集群
- 下载源码
- 配置 image 拉取工具
安装必要的工具
在正式安装Kubeflow前,需要准备一些必要的工具,具体也可参考Kubeflow on EKS 官网。安装时请一定注意工具版本,Python 3.8 和Kustomize 3.2.0。
创建EKS集群
创建一个新的集群为Kubeflow使用,关于EKS的版本选择,可以参考Amazon EKS 和Kubeflow 兼容性网站。
首先设置环境变量,EKS 集群名称和指定北京Region。
创建集群
下载源码
此次实验基于1.5.1 进行,下载1.5.1相关的源码
配置 image 拉取工具
在安装Kubeflow的时候,比较困难的一个问题是image的拉取,例如k8s.gcr.io, gcr.io, quay.io等源的image拉取。关于这部分,我们在Amazon API Gateway Mutating Webhook For K8S 基础上做了一些修改,具体可以参考自动化拉取Image,概括来说,原理是在需要gcr.io 等镜像的时候,该工具自动通过AWS Global区域的CodeBuild拉取镜像并添加到中国区的ECR中。
部署KubeFlow
在部署KubeFlow on EKS 的时候有多种选择,除了原始安装方法外,AWS 发行了Kubeflow on EKS 开源版本,允许客户使用现成的 AWS 服务集成构建机器学习系统并提供安装文档, 包括 RDS 和 S3 安装方法,Cognito、RDS 和S3 安装方法等。本篇是使用的RDS 和S3 安装方法。此部署方法用到的服务包含:
- RDS:代替KFP和Katib 使用的MySQL pod,用于持久化 KFP 数据(例如实验,pipelines,job信息等)和Katib 日志信息。
- S3: 代替MinIO 存储对象, 例如一些日志文件。
- Secret Manager:存储RDS相关信息,像用户名密码和Endpoint等。
准备工作
因为代码中没有考虑对中国区的支持,需要手动修改一些代码。
在 auto-rds-s3-setup.py 文件中需要修改两处:
- iam_policies 部分,需要把aws替换成aws-cn
- s3_params 部分,需要把amazonaws.com 换成s3.amazonaws.com.cn
在config 文件中s3 endpoint 需要修改,
准备 RDS,S3 和Secret Manager 环境
- 首先确保从代码的根目录开始,
export REPO_ROOT=$(pwd)
- 进入 tests/e2e 目录并安装依赖
- 准备需要使用的环境变量
- 配置 RDS, S3 和Secret Manager 环境,安装auto-rds-s3-setup.py。此步骤包含:
- RDS 数据库 创建
- S3 桶 创建
- Secret Manager 设置
- Serviceaccounts 创建
- Secret Store CSI driver设置等

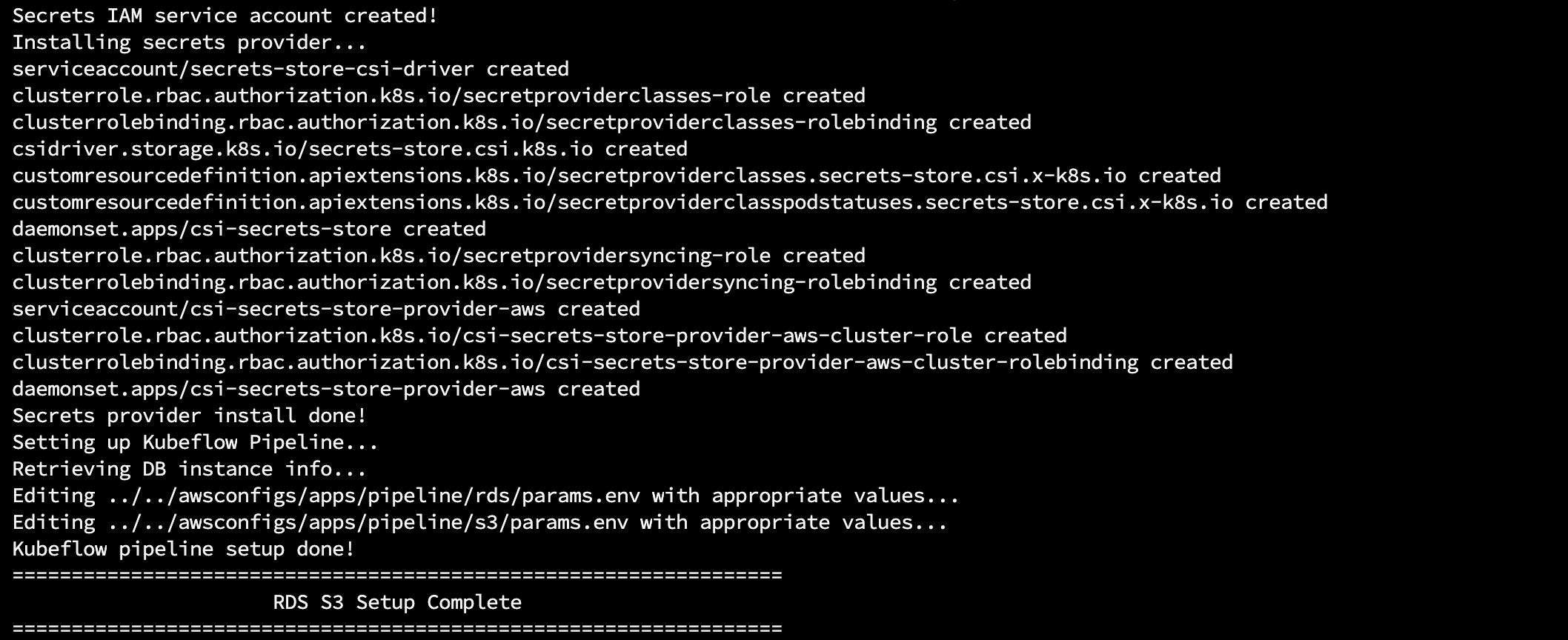
Python 脚本执行后, 会看到上面的log输出,为了确保安装过程成功,可以分别查看 pod运行的状态、serviceaccounts和CSI driver等。
kubectl get pods —all-namespaces

kubectl describe serviceaccounts kubeflow-secrets-manager-sa -n kubeflow

kubectl get csidriver

Kubeflow 安装
执行如下命令安装,安装后也可以建议查看pod状态。
如果各个Pod运行没有问题的话,执行如下命令后,就可通过 http://localhost:8080 访问 Kubeflow Dashboard, 默认用户名为 user@example.com,密码为12341234。因为涉及到 RDS 和 S3的使用,请参考 下一步验证安全结果。
kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
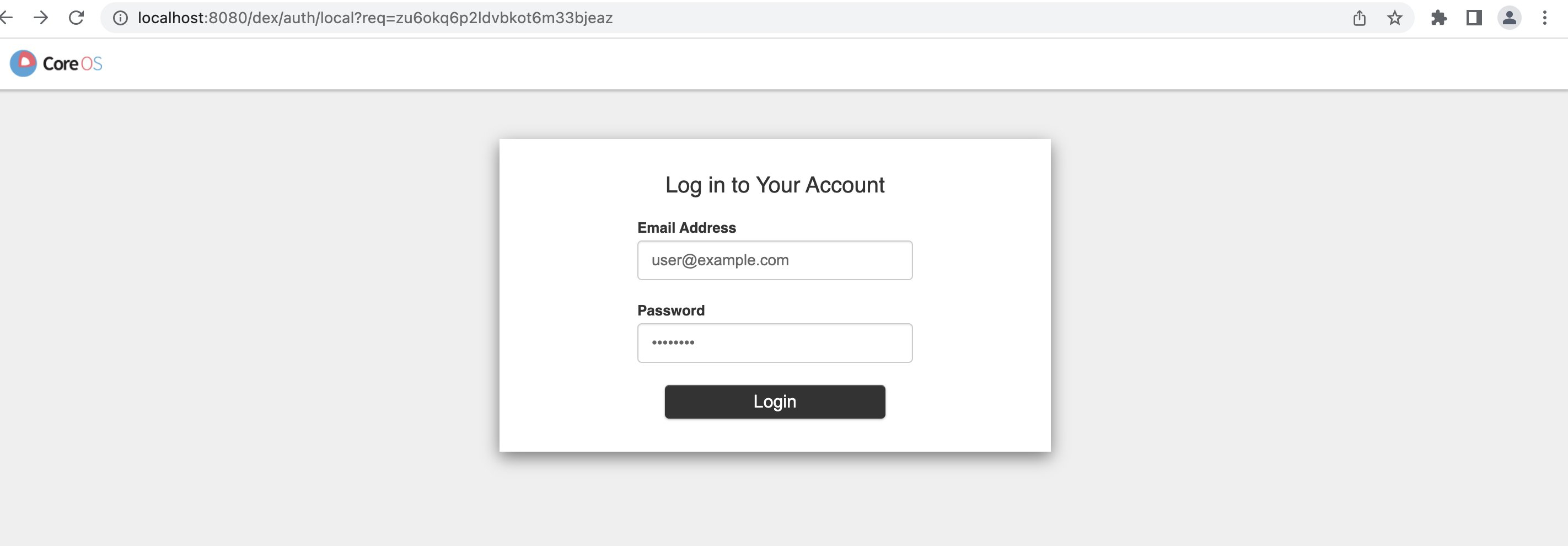
登陆后,可以看到Kubeflow的控制台界面如下。Kubeflow 支持的主要功能可以在界面上找到,用户编程测试工作台(Jupyter Notebook),超参调优 (Experiment(AutoML)), 机器学习工作流(Pipeline)等。

验证安装结果
在Kubeflow安装之后,我们通过两个方面进行验证,RDS和S3的验证,这两个角度的验证也是在侧面验证超参调优和工作流工作。
验证 RDS数据库
RDS中会存储
- 连接 RDS 数据库
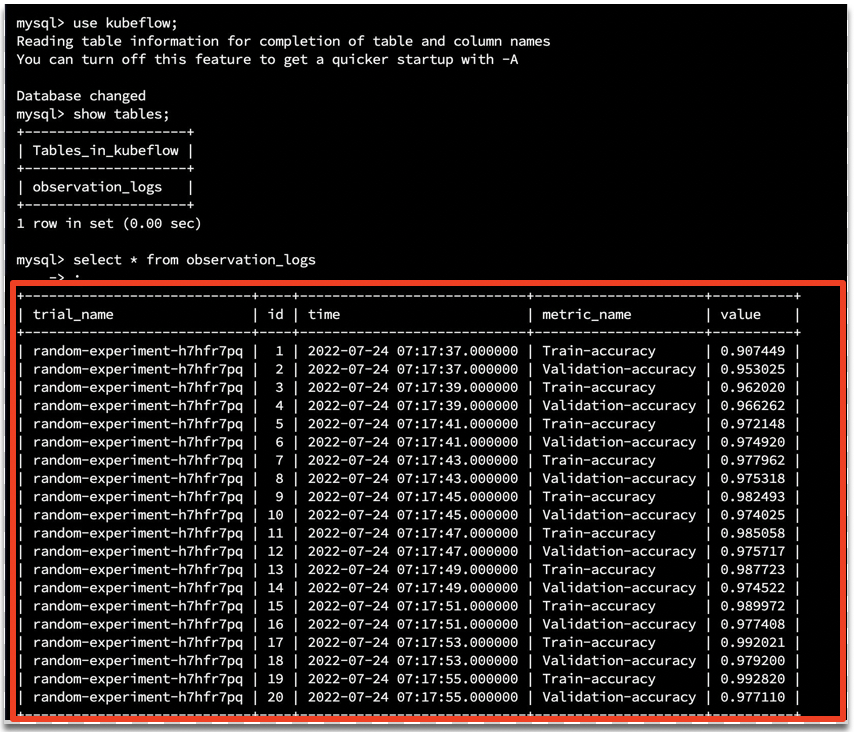
- 连接成功后,查看 kubeflow 和mlpipeline 数据是否存在, 同时查看在mlpipeline中是否有如下的表。

- 登录进入到Kubeflow Dashboard, 使用此 yaml 文件(注意需要更改 namespace) 运行一个实验。具体操作为Dashboard –> Experiments (AutoML) –> New Experiment.

实验成功后,RDS中表中会有相关的实验执行信息。
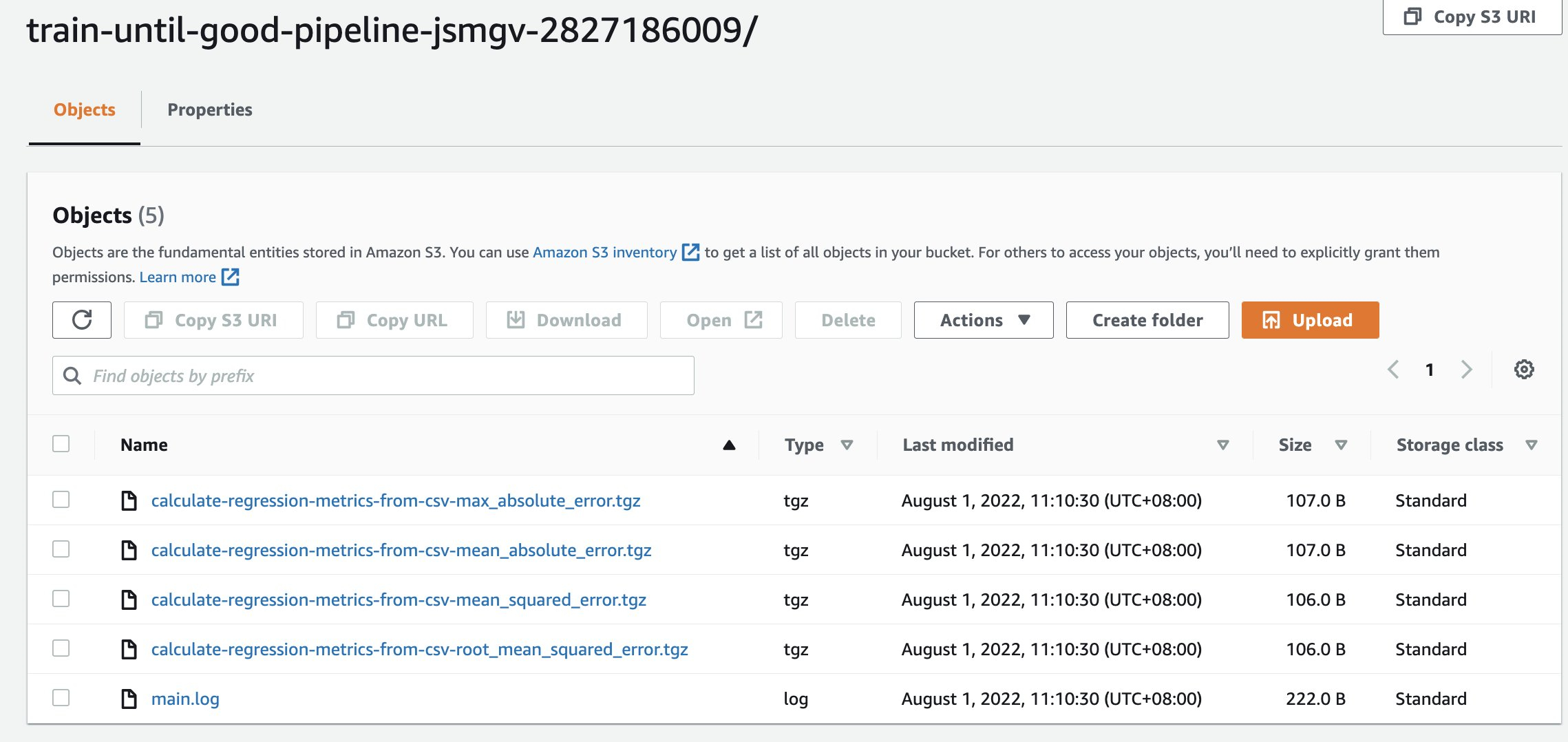
验证 S3
在Kubeflow Dashboard中,创建一个Experiment 并运行,运行结束之后,我们可以去到第二步部署的S3 bucket中,如果可以查看到 log ,S3 部分没有问题。 可以参考下图:

利用 Karpenter 进行动态的资源扩展满足Kubeflow ML 训练的需求
在 Karpenter 之前,EKS用户使用Cluster Autoscaler动态调整集群的计算容量,他的原理是使用 Amazon EC2 Auto Scaling 组进行扩展底层的EC2资源。Karpenter 会观察未调度的一组容器 (pod) 的总资源请求,然后像 Amazon EC2直接发送命令并作出启动和终止新节点的决策,从而减少调度延迟并降低基础设施成本。在机器学习场景下,用户可以像该文中一样使用一个EKS 节点组安装和管理Kubeflow,在提交训练任务时,通过Karpenter开启GPU资源,在训练结束后终止GPU资源。
Karpenter的安装不在此介绍了,可以参考官方文档安装。我们主要演示在Karpenter部署后,Kubeflow 中如何使用。使用验证 RDS的例子,在spec中添加resource为 nvidia.com/gpu, 添加后在Kubeflow Dashboard 中 Experiments (AutoML) 部分运行修改后的yaml文件。
在提交了这个 Experiment后,可以通过命令行查看 Karpenter 的日志。我们可以看到GPU 机器可快速创建起来。
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller


在任务执行完毕后,可以看到创建的GPU EC2 被删除。通过Karpenter, 我们可以随时扩展资源进行训练,不需要提前配置很多GPU 资源。



总结
通过使用EKS, Kubeflow, Karpenter可以建立弹性扩展性强的机器学习平台,在安装中需要注意的问题包含:
- Kubeflow中使用了很多源是io的image,可通过这个工具自动化拉取Image。
- 在中国区Kubeflow和Karpenter安装的时候,需要修改一些服务的endpoint和ARN像是amazonaws.com 到s3.cn-north-1.amazonaws.com.cn。Kubeflow的配置文件代码量比较大,在部署前通过检索的方式发现需要修改的endpoint外。 最好的办法是通过查看Pod 运行状态进行Troubleshooting,一般这几个配置都在configmap中,修改configmap即可。
- 在使用Karpenter 调度GPU资源前,记得安装NVIDIA设备的插件,kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.9.0/nvidia-device-plugin.yml
参考文档
Kubeflow on AWS: https://awslabs.github.io/kubeflow-manifests/docs/deployment/rds-s3/guide/#42-verify-s3
Karpenter介绍: https://aws.amazon.com/cn/blogs/china/karpenter-new-generation-kubernetes-auto-scaling-tools/
Karpenter 安装:https://karpenter.sh/v0.12.1/getting-started/getting-started-with-eksctl/