亚马逊AWS官方博客
利用 Amazon EKS 集群运行 Spark 实现大数据处理
为了满足客户对Kubernetes的应用需求,AWS推出了托管的Kubernetes服务——Amazon Elastic Kubernetes Service (Amazon EKS),它带来了诸多优点,如:高可用的控制平面、VPC网络插件、与AWS其他服务无缝集成(访问授权,审计日志,负载均衡等)。并且与开源版本Kubernetes无缝集成,能够实现平滑迁移。
在大数据处理与分析领域,Apache Spark也具有日益增长的趋势和重要地位。过去,它支持了Standalone, Mesos和YARN的集群资源管理平台,其中以YARN最为常见,常与我们熟知的Hadoop平台进行集成,在集群每个节点之上采用HDFS分布式文件系统进行数据存储。随着数据量的急剧增长和云原生应用架构和数据湖概念的日益普及,计算能力与存储分离的需求也随之增多,以实现计算资源的弹性化、数据高持久化、高性价比的大数据应用架构,AWS也推出了满足以上需求的托管式Hadoop服务——Amazon Elastic MapReduce(EMR)。
当今两个最火热的技术的结合迸发出了新的火花:新版本的Apache Spark添加了对Kubernetes平台的支持,使我们能够利用原生的Kubernetes调度器进行集群资源的分配与管理Spark应用。在此模式下,Spark Driver和Executor均使用Pod来运行,进一步可通过指定Node Selector功能将应用运行于特定节点之上(如:带有GPU的节点实例)。
下图讲述了Apache Spark on Kubernetes的工作方式:

(from: https://spark.apache.org)
接下来,我们讲解如何实现Spark on EKS。
注:完成本文的内容需要安装eksctl, kubectl, aws-iam-authenticator, docker及aws cli,并正确配置。详细步骤请参考相应文档,本文不再赘述。
1.创建EKS集群
使用eksctl一键创建EKS集群:
过程约10-15分钟,然后执行命令对集群进行测试:
输出:

2.在Kubernetes集群中创建名称为spark的服务帐户及绑定权限
3.下载Spark二进制文件
从http://spark.apache.org/downloads.html 选择合适的版本下载至本地(本例中使用2.4.4版本)
解压缩:
4.确认jar文件的Kubernetes版本兼容性
Spark采用了fabric8.io的Kubernetes客户端来连接API Server进行资源调度和分配,需要先确认自带的版本能否与集群版本相兼容。本文中Spark 2.4.4自带的Kubernetes-client版本为4.1.2, EKS集群版本为1.13,存在不兼容问题,需要更高版本支持。

全部版本兼容信息详见:https://github.com/fabric8io/kubernetes-client
本例中所采用的Spark中带有的kubernetes-client的版本为4.1.2,与Kubernetes 1.13版本并不兼容,需要下载更高版本(如:kubernetes-client-4.4.2.jar)。
kubernetes-client: https://mvnrepository.com/artifact/io.fabric8/kubernetes-client
下载完成后拷贝至jars/目录下,并删除原有旧版本文件,如:kubernetes-client-4.1.2.jar
5.Spark中添加对aws的支持
我们的目标是利用Spark来处理位于S3存储桶中的数据,需要添加Spark对aws及S3的支持,将hadoop-aws和aws-java-sdk两个jar包添加至
jars/目录,并且版本需要和其他包相一致。本例中需要2.7.3版本(可参考jars/目录中其他 jar文件名中的版本,保持一致即可),我们从以下地址下载hadoop-aws jar文件以及他它所依赖的aws-java-sdk的1.7.4版本。
hadoop-aws-2.7.3.jar: https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-aws/2.7.3
aws-java-sdk-1.7.4.jar: https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk/1.7.4
下载完成后将以上两个jar文件复制到jars/目录下。
6.构建Spark容器镜像并推送至ECR
从AWS 管理控制台上进入ECR服务
创建三个Repository,分别为:spark, spark-py, spark-r,并记录下ECR镜像仓库URI
进入Spark目录:
执行脚本构建Spark镜像:
登录至ECR私有仓库
使用aws cli命令行工具执行以下内容来获取登录命令:
推送镜像:

已推送至镜像仓库中,并记录镜像的URI地址。
7.创建Spark Driver Pod和Service
YAML文件定义:
注:需要配置Pod所运行的Service Account为步骤2中所创建的服务帐户
8.运行SparkPi示例程序
本测试中使用spark-submit命令提交示例应用spari-pi,为了能够让kubernetes来分配spark executor资源,需要设置参数为:
–master k8s://<API Server Endpoint URL>
小技巧:
如在Kubernetes Pod中运行,可以使用https://kubernetes来访问集群API Server Endpoint。
查找Spark Driver Pod并附加至Bash:
在Spark Driver Pod的Bash中执行:
部分输出及结果如下:

至此,Apach Spark已经能够在Kubernetes上正确运行。
9.使用Spark shell进行交互式分析,处理S3中的数据
在Pod的Bash中执行:
注:需要指定访问S3所使用的AWS Access Key和Secret Key。

将S3存储桶中的csv文件读取为Dataframe,使用的协议为s3a://
查看Dataframe Schema:

显示csv文件中的10条数据:
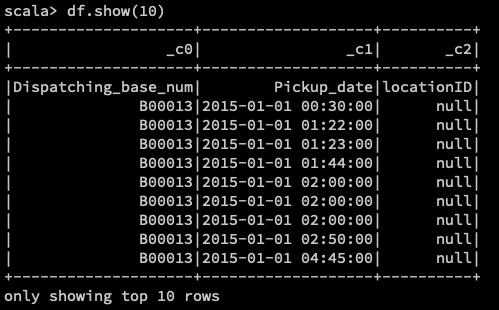
将csv文件中的10条数据写入到S3存储桶中
在S3管理控制台中查看,并使用S3 Select查看输出的文件内容

总结
通过以上几个步骤,即可实现在Kubernetes集群上运行Spark任务的平台搭建,与传统的Yarn资源管理调度相比较而言更为简单。将数据存储在S3当中进行分析,保证了数据的高持久性,并实现计算与存储的分离。