亚马逊AWS官方博客
使用 Amazon SageMaker 运行基于 TensorFlow 的中文命名实体识别
一、背景
利用业内数据构建知识图谱是很多客户正在面临的问题,其中中文命名实体识别(Named Entity Recognition,简称NER)是构建知识图谱的一个重要环节。我们在与客户的交流中发现,现有的NER工具(比如Jiagu)对于特定领域的中文命名实体识别效果难以满足业务需求,而且这些工具很难使用自定义数据集训练。因此客户迫切想使用业内最先进的算法在行业内数据集上进行训练,以改进现有NER工具的不足。本文将介绍如何使用Amazon SageMaker运行基于TensorFlow的中文命名实体识别。
命名实体识别,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。命名实体识别是信息提取、问答系统、句法分析、机器翻译、知识图谱等应用领域的重要基础工具。
英语中的命名实体具有比较明显的形式标志(即实体中的每个词的第一个字母要大写),所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,中文命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
二、中文命名实体识别算法
NER一直是自然语言处理(NLP)领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。

早期的命名实体识别方法基本都是基于规则的。之后由于基于大规模的语料库的统计方法在自然语言处理各个方面取得不错的效果之后,一大批机器学习的方法也出现在命名实体类识别任务。
值得一提的是,由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是LSTM+CRF、BiLSTM+CRF。
我们知道,预训练模型可以大幅提升计算机视觉的深度学习算法表现,而在NLP领域也是同理,预训练语言模型可以有效提升文本分类、机器翻译、命名实体识别等任务的效果。预训练语言模型经历了从词嵌入(Word Embedding),到BERT,再到ALBERT的演进。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的编码器(Encoder),因为解码器(Decoder)是不能获得要预测的信息的。模型的主要创新点都在预训练方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的表示。
ALBERT(见参考资料4)基于BERT,但有一些改进,它可以在主要基准测试上获得最先进的性能,而参数却减少了30%。比如,对于albert_base_zh,它只有原始BERT模型的10%的参数,但是保留了主要精度。
本文将使用预训练语言模型ALBERT做中文命名实体识别,该项目基于开源的代码修改而来(本文代码见参考资料1,原始代码见参考资料2),使用TensorFlow框架开发,在下一节,我们将展示如何在Amazon SageMaker中进行该模型的训练。
三、在Amazon SageMaker中运行TensorFlow
本节将介绍如何使用Amazon SageMaker的自定义容器 (Bring Your Own Container,简称BYOC)和自定义脚本(Bring Your Own Script,简称BYOS)两种方式来运行TensorFlow程序的训练任务。首先我们来看下如何在Amazon SageMaker Notebook上运行这个项目,然后再把它运行在Amazon SageMaker上。
1. 在Amazon SageMaker Notebook上运行TensorFlow开源代码
我们首先要创建Amazon SageMaker Notebook,然后下载代码和数据,最后运行代码。如果一切运行正常,我们就可以进行下一步工作——将该TensorFlow代码运行到Amazon SageMaker中了。
1.1 创建Amazon SageMaker Notebook
我们首先要创建一个Amazon SageMaker Notebook,笔记本实例类型最好选择ml.p2.xlarge,这样就可以使用GPU进行训练的测试了,卷大小建议改成10GB或以上,因为运行该项目需要下载一些额外的数据。

1.2 下载代码和数据
笔记本启动后,打开页面上的终端,执行以下命令下载代码:
执行以下命令下载和解压数据(数据来源见参考资料3):
1.3 运行代码
我们需要进入一个虚拟环境tensorflow_p36,该环境预制了运行TensorFlow所需要的常用组件,运行run_train.sh进行训练,命令如下:
如果出现下面的输出,说明运行结果正常,在实例类型为ml.p2.xlarge的笔记本中,训练速度可以达到23个样本/秒,如果是其他类型实例,速度可能有差异。

2. 自定义容器(BYOC)
自定义容器需要经历准备Dockerfile,创建训练的启动脚本,创建镜像并上传到Amazon ECR,本地测试和Amazon SageMaker测试等步骤。完整执行过程见tensorflow_bring_your_own.ipynb。
2.1 准备Dockerfile
我们首先需要准备Dockerfile,在其中安装TensorFlow程序运行必须的环境,拷贝所有代码到镜像中。
这里我们需要了解Amazon SageMaker对于容器内目录结构的要求,具体如下图所示,训练所需代码放到/opt/ml/code目录下,训练所需数据放到/opt/ml/input/data目录下,训练输出的模型放到/opt/ml/model目录下,训练结果文件或者日志文件放到/opt/ml/output目录下,训练超参数文件是由Amazon SageMaker自动生成的,在/opt/ml/input/config目录下。

2.2 创建训练的启动脚本
Amazon SageMaker在训练时默认的启动脚本是train,您可以将自己代码中的启动脚本命名为train,但我们更建议您使用我们提供的启动脚本train,该脚本是基于Python的,可以帮助您解析传入的超参数,并调用您代码中的实际启动脚本。
2.3 创建镜像并上传到Amazon ECR
在准备好Dockerfile和启动脚本后,我们可以使用build_and_push.sh这个脚本创建镜像并上传到Amazon ECR。注意这个过程可能需要进行很多次,因为我们不可避免地要修改Dockerfile或者TensorFlow程序以使得它们可以正常工作。如果尚未调试完成,我们可以暂时不执行该脚本的最后一句docker push ${fullname},以避免频繁上传镜像到Amazon ECR。
2.4 本地测试
在创建镜像完成后,我们可以使用Amazon SageMaker的本地模式进行本地测试:第一步,执行utils/setup.sh来初始化本地模式。第二步,指定执行的角色,这里我们假设您是在Amazon SageMaker Notebook上执行的,如果是其他环境,您可能需要手动指定角色的ARN。第三步,设定超参数,这里需要对应到您程序中所需的超参数。第四步,设定训练机型为local或者local_gpu(支持GPU)。第五步,创建Estimator,这里需要传入之前获得的角色、训练机型、机器数量、镜像名称、超参数等。第六步,启动训练,这里需要传入训练数据的位置,在本地模式下,训练数据的位置可以设置成本地路径。
训练启动后,我们可以看到训练的日志输出,以及监控本机的GPU、CPU、内存等的使用率等情况,以确认程序可以正常工作。
如果在此过程中需要进入正在运行的容器内调试,我们可以使用docker ps命令获取当前正在运行的容器ID,并使用docker exec -it <CONTAINER ID> /bin/bash进入容器内进行调试。
2.5 Amazon SageMaker测试
在本地测试和上传镜像到Amazon ECR完成后,我们可以使用Amazon SageMaker进行测试:第一步,上传数据到Amazon S3,获取镜像在Amazon ECR的地址。第二步,指定执行的角色,这里我们假设您是在Amazon SageMaker Notebook上执行的,如果是其他环境,您可能需要手动指定角色的ARN。第三步,设定超参数,这里需要对应到您程序中所需的超参数。第四步,设定训练机型为ml.p2.xlarge(支持GPU)。第五步,创建Estimator,这里需要传入之前获得的角色、训练机型、机器数量、镜像地址、超参数等。第六步,启动训练,这里需要传入训练数据的位置,在Amazon SageMaker模式下,训练数据的位置需要设置成Amazon S3路径。
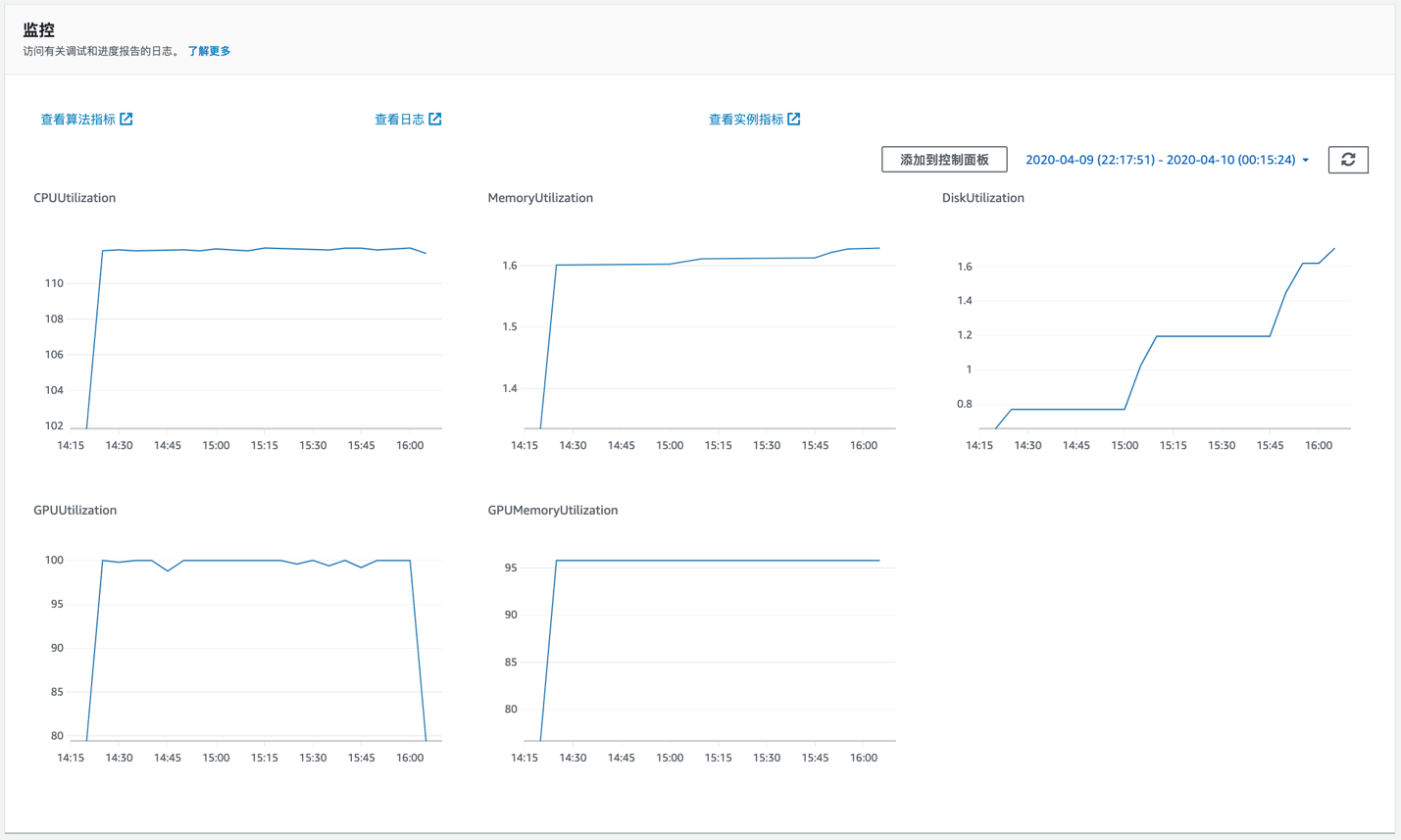
训练启动后,我们可以在Amazon SageMaker控制台看到这个训练任务,点进详情可以看到训练的详情,日志输出,以及监控机器的GPU、CPU、内存等的使用率等情况,以确认程序可以正常工作。

在此过程中我们无法进入正在运行的容器内调试,您可以将尽量多的日志打印出来,或者输出到/opt/ml/output路径下,该路径下的所有文件在训练完成后会被自动打包成output.tar.gz放到设定好的位于Amazon S3的输出路径下。
2.6 训练结果
本文所示程序使用了MSRA公开的中文实体识别数据集进行训练,在训练3轮之后,最优的F1值就可以达到0.948345,属于比较领先的结果。
3. 自定义脚本(BYOS)
使用BYOS的方法和BYOC的不同之处在于:BYOC是使用用户自己创建的镜像来运行程序,更适用于用户对镜像自定义程度较高的使用情景;而BYOS是使用预先构建好的镜像,只是传入用户自己的代码来运行程序,不需要用户自己调试镜像,更适用于比较简单的使用情景。
由于不需要编译自定义镜像,我们可以直接进行本地测试和Amazon SageMaker测试,完整流程见tensorflow_script_mode_quickstart.ipynb。
3.1 本地测试
我们可以使用Amazon SageMaker的本地模式进行本地测试:第一步,执行utils/setup.sh来初始化本地模式。第二步,指定执行的角色,这里我们假设您是在Amazon SageMaker Notebook上执行的,如果是其他环境,您可能需要手动指定角色的ARN。第三步,设定超参数,这里需要对应到您程序中所需的超参数。第四步,设定训练机型为local或者local_gpu(支持GPU)。第五步,创建一个名为TensorFlow的Estimator,这里需要传入训练入口脚本(entry_point)、源代码路径(source_dir)、之前获得的角色、训练机型、机器数量、TensorFlow版本、Python版本、超参数等。第六步,启动训练,这里需要传入训练数据的位置,在本地模式下,训练数据的位置可以设置成本地路径。
这里我们可以注意到estimator.fit()传入的参数与BYOC略有不同,这两个写法其实是等价的,事实上,这里的写法更规范一些,按照Amazon SageMaker的文档,输入数据可以有多个通道(Channel),默认的通道是training,在本文的代码中,训练、验证等过程其实都是从training通道中读取的数据,所以更规范的做法是,我们应该额外增加一个通道validation,用来存放验证数据。
训练启动后,我们可以看到训练的日志输出,以及监控本机的GPU、CPU、内存等的使用率等情况,以确认程序可以正常工作。
如果在此过程中需要进入正在运行的容器内调试,我们可以使用docker ps命令获取当前正在运行的容器ID,并使用docker exec -it <CONTAINER ID> /bin/bash进入容器内进行调试。另外,我们使用docker images命令可以看到Amazon SageMaker自动下载了一个名为763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-training:1.15.2-gpu-py3的镜像,该镜像是由Amazon SageMaker预编译的。

3.2 Amazon SageMaker测试
在本地测试完成后,我们可以使用Amazon SageMaker进行测试:第一步,上传数据到Amazon S3。第二步,指定执行的角色,这里我们假设您是在Amazon SageMaker Notebook上执行的,如果是其他环境,您可能需要手动指定角色的ARN。第三步,设定超参数,这里需要对应到您程序中所需的超参数。第四步,设定训练机型为ml.p2.xlarge(支持GPU)。第五步,创建一个名为TensorFlow的Estimator,这里需要传入训练入口脚本(entry_point)、源代码路径(source_dir)、之前获得的角色、训练机型、机器数量、TensorFlow版本、Python版本、超参数等。第六步,启动训练,这里需要传入训练数据的位置,在Amazon SageMaker模式下,训练数据的位置需要设置成Amazon S3路径。
训练启动后,我们可以在Amazon SageMaker控制台看到这个训练任务,点进详情可以看到训练的详情,日志输出,以及监控机器的GPU、CPU、内存等的使用率等情况,以确认程序可以正常工作。
在这里,source_dir我们设置的是本地代码路径,Amazon SageMaker会自动将该路径下的所有代码和数据拷贝进容器中。此外,BYOS模式还支持git路径作为代码路径,使用方法如下:
但是,由于本文所用代码需要ALBERT预训练数据,而该数据不包含在git内,所以我们需要对代码进行改造,以使得在代码内下载并解压数据,才能够正常训练。这里我们不再展示如何操作,感兴趣的读者可以自行尝试。
四、结论
本文讲解了如何使用Amazon SageMaker运行基于TensorFlow的中文命名实体识别,其中算法部分是使用预训练语言模型ALBERT做中文命名实体识别。
本文展示了如何把一个已有项目快速运行到Amazon SageMaker上,如果您想使用到Amazon SageMaker的更多高级用法,需要对已有项目进行改造,比如支持实时推理、批量推理、断点重新训练等,具体可以查看Amazon SageMaker的文档。
本文所演示的使用方法是基于单机单卡的,Amazon SageMaker 提供基于 Docker 的简化分布式 TensorFlow 训练平台,如果要将程序扩展到多机多卡进行训练,可以参考其他相关博客。
参考资料
- 本文代码:https://github.com/whn09/albert-chinese-ner
- 使用预训练语言模型ALBERT做中文NER:https://github.com/ProHiryu/albert-chinese-ner
- 海量中文预训练ALBERT模型:https://github.com/brightmart/albert_zh
- ALBERT论文:https://arxiv.org/pdf/1909.11942.pdf
- 命名实体识别 – Named-entity recognition | NER:https://easyai.tech/ai-definition/ner/