亚马逊AWS官方博客
使用Athena (Presto) 分析本地 Oracle 数据库导出的数据
浏览本文需要约8分钟,建议按照章节分段阅读。
在传统企业客户,无论是前台的交易数据库还是后台的数据仓库,都会选择使用Oracle,它具备非常广泛的技术资料、社区资源和问题处理案例(各种踩坑的经验);同时它还有广泛的用户基础,很多企业的技术栈都是围绕Oracle数据库构建开发和运维工作,保障业务的使用。比如金融行业的Oracle数据库主要业务场景会涉及到账务、资金和资产中心。
如果用户希望和业务直接相关的数据可以更持久的存储并且做一些离线的分析,很多企业会构建自己的大数据分析平台,把数据存储到平台进行分析,就好比水从源头流入湖中,各种用户都可以来湖里获取、蒸馏和提纯这些水(数据)。下图是数据湖的一个典型逻辑架构,它是由多个大数据组件、云服务组成的一个解决方案,包括摄取层,处理/蒸馏层,维护层和数据洞察。

在水从源头流入湖中的摄取层,常见的场景是通过Apache Sqoop或DMS(亚马逊云科技数据迁移服务)将数据从RDBMS导入到数据湖(HDFS/HDFS/Hive/HBase),转换成列式存储格式,适配使用的查询引擎和计算框架,通过上图中的数据洞察来提供业务大盘和各种报表,辅助业务团队做决策。

Amazon DMS(Database Migration Service)是一种 Web 服务,用于将数据从源数据存储迁移到目标数据存储。可以在相同数据库引擎的源和目标节点之间迁移,也可在不同数据库引擎的源和目标点之间迁移。
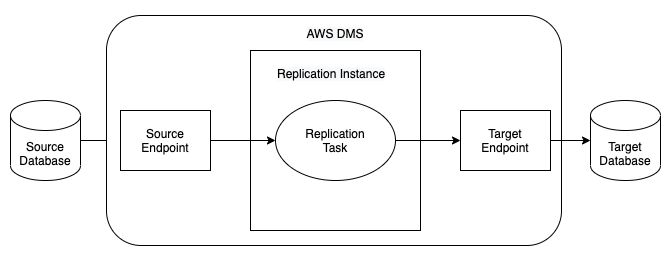
Amazon Athena是一种基于Presto的交互式查询服务,使用标准 SQL 直接分析Amazon S3 中的数据。数据科学家和数据工程师经常会使用 Athena 进行数据分析和交互式查询。Athena 是无服务器服务,可以自动扩展并执行并行查询,没有维护基础设施的工作,用户按照查询的数据量付费。

在企业环境下,混合云架构是一种常见的架构,理想环境下摄取层的传输场景是通过Apache Sqoop或DMS使用网络专线将本地Oracle数据库数据迁移到s3存储桶,再进行数据分析。

但受本地条件限制,很多用户是用Oracle Datapump或者Exp/Imp将数据导出后,再将本地数据传输到s3存储桶。本文通过阐述使用上述两种不同的工具,介绍如何将数据导入s3存储桶,使用Athena做数据分析。
1. 方案概述
方案一,使用 Oracle 数据泵将本地 Oracle 数据库数据导出,上传到s3存储桶,再由适用的 Amazon RDS for Oracle加载数据,利用DMS服务将RDS Oracle数据库数据迁移到s3存储桶,使用云上的大数据组件Athena进行分析。

方案二,使用 Oracle Exp将本地 Oracle 数据库数据导出,上传到s3存储桶,再在云上EC2安装Oracle对应版本的数据库,Imp数据到EC2 Oracle,使用DMS服务将EC2 Oracle数据库数据迁移到s3存储桶,利用云上的大数据组件Athena进行分析。

2. 使用的资源
| 节点/服务 名称 | 数据库/服务 版本 |
配置 (选用t2实例) |
| 本地Oracle数据库 | 19c | t2.medium 2C/4G/20G |
| 云上托管Oracle数据库 | 19c | t2.medium 2C/4G/20G |
| 云上EC2安装Oracle数据库 | 19c | t2.medium 2C/4G/20G |
| PL/SQL调试DBveaver | 22.0.3 | |
| Database Migration Service (DMS) | ||
| Athena |
3. 方案一 使用Oracle Datadump导出数据
Datapump是从Oracle 10g 中引入的功能,无论性能还是压缩比,都比传统的Exp/Imp更有优势。相比较Exp和Imp作为客户端工具程序而言,Expdp和Impdp是服务器端工具程序,只能在Oracle服务器端使用,不能在客户端使用。Data Pump 是将大量数据从Oracle 迁移到 Amazon RDS 数据库实例的首选方法。
3.1 最佳实践
当使用 Oracle 数据转储将数据导入到 Oracle 数据库实例时,建议使用以下最佳实践:
- 在 schema 或 table 模式中执行导入,以便导入特定架构和对象
- 请勿在full模式中导入
因为 Amazon RDS for Oracle 不允许访问 SYS 或 SYSDBA 管理用户,所以在 full 模式中导入架构可能会损坏 Oracle 数据字典并影响数据库的稳定性。
3.2 预期目标
- 在本地数据库新建一张表,并通过数据泵将该用户下的所有表导出
- 将dmp文件上传到s3存储桶
- 将dmp文件加载到RDS Oracle并能查询到表
- 使用DMS将数据导出Parquet格式存在s3,并能查询到表
- 在Athena中查询表

3.3 本地Oracle数据库建表和导出
1. 在本地DPADMIN用户下新建一个表dep,插入数据
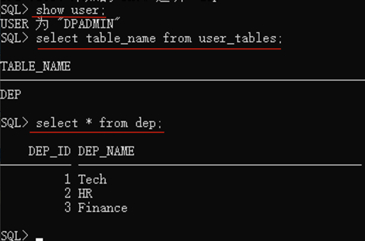
2. 创建数据转储文件

3. 上传数据转储文件到s3存储桶

4. 配置RDS Oracle DB选项组和s3存储桶的集成
RDS for Oracle 与 Amazon S3 集成,数据库实例必须可以访问 Amazon S3 存储桶。
4.1 首先要RDS中创建一个选项组,步骤如下
- 在RDS选项组选择创建组

- 命名并选择相应的引擎和版本

4.2 其次在选项组中添加和s3存储桶集成的选项,步骤如下
- 创建完成后再次打开这个选项组,选择Add option
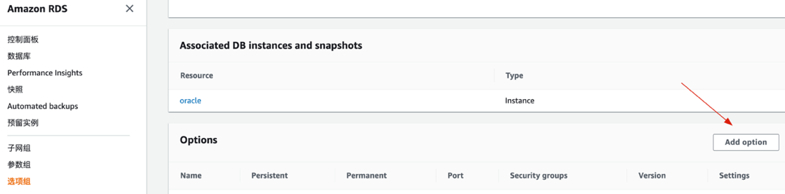
- 在Option name选择S3_INTEGRATION,Version选择1.0,立即应用

4.3 然后将上述选项组应用到RDS Oracle中,步骤如下
- 回到RDS Oracle,选择Configuration,可以看到现有的Option Groups
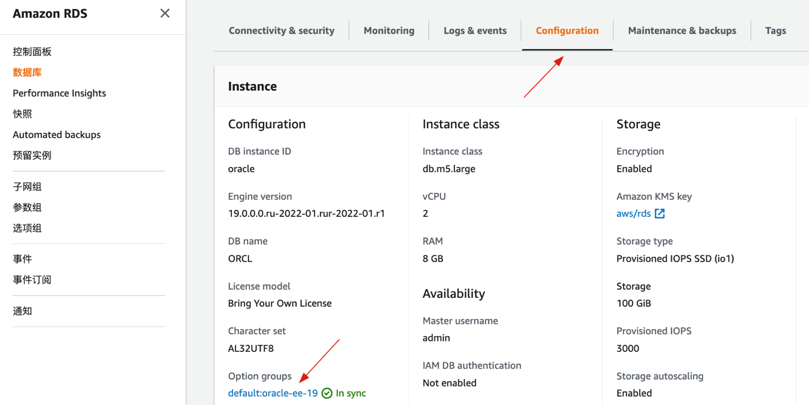
- 选择Modify –> Configuration

- 把Option group选择为刚才新建的s3-integration-group

- 修改DB实例,立即应用,该过程不需要重启实例

- 在Configuration –> Option groups下查看当前选项组,变更完成

4.4 最后将创建好的访问s3存储桶的Role关联到RDS,步骤如下
1. 在IAM –> 角色下,创建RDS Role,附加可以访问对应s3存储桶的策略

2. 在RDS –> 数据库 –> Oracle –> Connectivity & security –> Manage IAM roles下,选择创建的RDS_access_s3角色和S3_INTEGRATION功能,添加角色

5. 使用RDS Oracle DB从s3导入数据
- 在终端节点上,使用DBveaver工具管理RDS Oracle。配置其连接的URL,用户名和口令

- 将ora-datadump存储桶下dump目录中的所有文件下载到DATA_PUMP_DIR目录
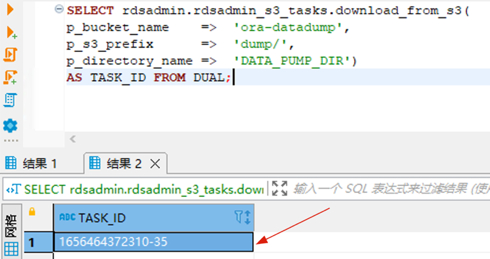
- 通过显示任务的输出文件来查看结果

- 使用rdsadmin.rds_file_util.read_text_file存储过程查看bdump文件的内容

- 从导入的转储文件中还原架构和数据

- 查询表是否已导入

6. 创建DMS RDS终端节点和复制实例
6.1 创建终端节点
1. 创建终端节点RDS Oracle,只需选择已有的实例即可

2. 配置终端节点RDS Oracle的用户名和口令
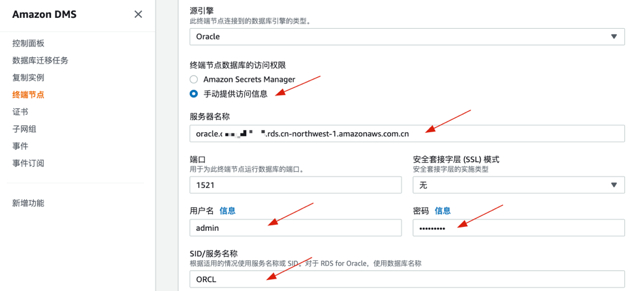
3. 创建终端节点为s3

4. 配置终端节点s3的存储桶名和文件夹

5. 配置终端节点s3参数,使用以下额外连接属性来指定输出文件的 Parquet 版本:
parquetVersion=PARQUET_2_0;

6.2 创建复制实例
1. 创建复制实例,命名并选择实例类型
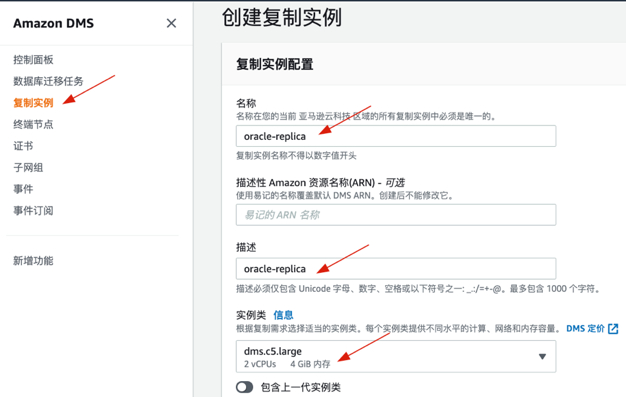
2. 配置复制实例

6.3 创建并执行迁移任务
1. 创建数据库迁移任务,命名标识符,选择创建的复制实例,选择源和目标终端节点

2. 配置数据库迁移任务,选择向导模式

3. 配置数据库迁移任务表映像,架构名称为%,表名称为之前Oracle数据库创建的表DEP;选择“创建任务”

4. 观察数据库迁移任务状态,从“正在运行”到“加载完成”

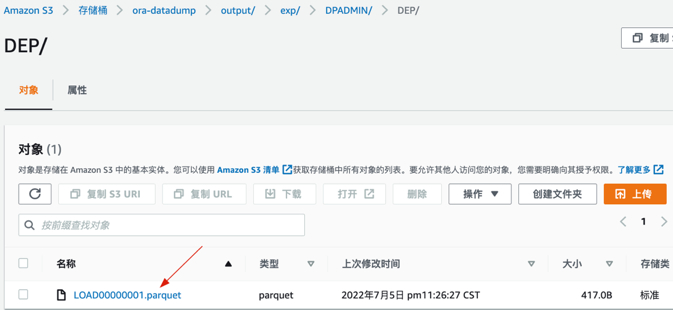
5. 查看s3终端节点的目录,可以看到生成parquet文件

7. 使用Athena分析Oracle Expdp导出数据
7.1 Athena操作步骤
- 先设置一下Athena查询结果的存放位置,选择s3存储桶的路径
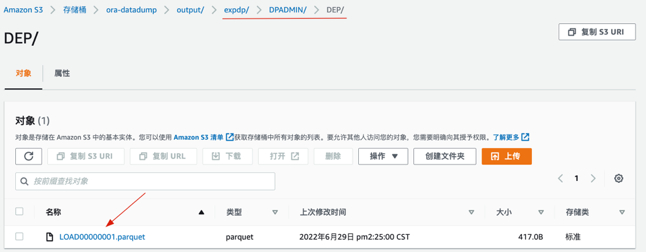
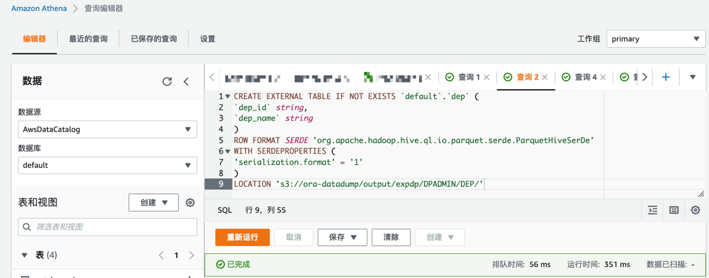
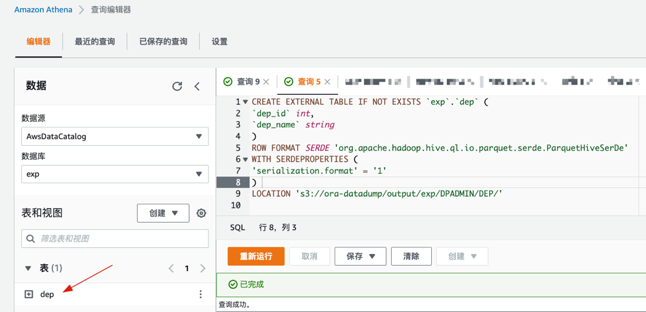
- 在Default数据库下创建表dep,CREATE TABLE 语句必须包含分区详细信息,使用 LOCATION 指定分区数据的根位置,运行以下内容进行查询

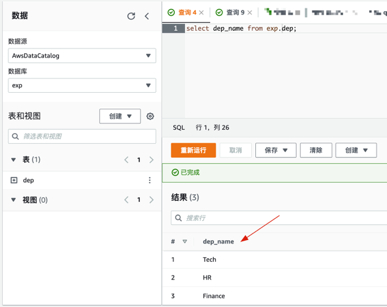
- 查询dep表的结果
8. 方案二 使用Oracle Exp导出数据
受限于Oracle版本和使用习惯,很多用户还在使用Exp/Imp,其更适合用于数据量较小且不需要BINARY_FLOAT 和BINARY_DOUBLE等数据类型。导入过程会创建架构对象,非常适合用于包含小型表的数据库。
上述RDS Oracle DBMS_DATAPUMP 仅适用于Oracle Datadump导出的 expdp 文件,而使用Exp/Imp工具导出的二进制文件无法直接导入RDS Oracle。需要新建一台EC2,安装Oracle DB,Imp导入二进制文件。
8.1 预期目标
- 在本地数据库新建一张表,并通过Exp将该用户下的所有表导出
- 将dmp文件上传到s3存储桶
- 启动一台EC2 Windows,并安装Oracle 19c,安装步骤请参考Oracle Database Installation
- 将dmp文件导入到EC2 Oracle,并能查询到表
- 使用DMS将数据导出Parquet格式存在s3,并能查询到表
- 在Athena中查询表

9. 导出数据并上传到s3存储桶
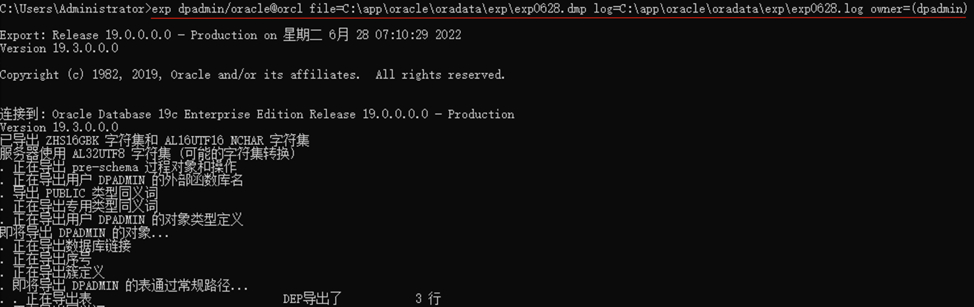
- EXP导出数据和日志

- 将日志上传到s3存储桶对应的文件夹
- 在云上EC2 Windows上下载AWS CLI客户端

- 选中EC2 Windows,选择 操作–>实例设置 –> 附加/替换IAM角色,选择创建好的S3_full_access Role(附加可以访问对应s3存储桶的策略)

- 使用AWS CLI同步本地和s3存储桶的文件,将Exp导出的数据上传到s3

10. 使用EC2 Oracle Imp导入数据
- 在测试用的EC2 Oracle DB,先将dep表删除

- 再将数据导入orcl数据库中,指定用户名和表名

- 验证导入的表

11. 创建DMS 终端节点
11.1 创建终端节点
1. 创建终端节点EC2 Oracle

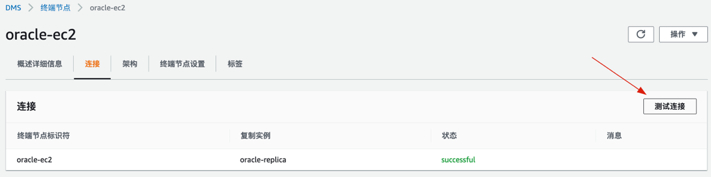
2.测试终端节点EC2 Oracle连通性
3.创建终端节点s3

- 配置终端节点s3参数,使用以下额外连接属性来指定输出文件的 Parquet 版本:

11.2 创建并执行迁移任务
1. 创建数据库迁移任务,命名“任务标识符”,延用之前的复制实例,选择源和目标终端节点

2. 配置数据库迁移任务,选择向导模式

3. 配置数据库迁移任务“表映像”,架构名称为%,表名称为之前创建的DEP

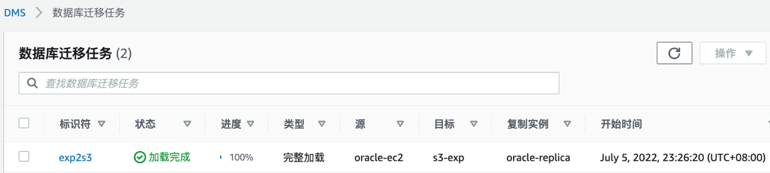
4. 查看数据库迁移任务状态
5. 查看s3终端节点的目录,可以看到生成parquet文件
12. 使用Athena分析Oracle Exp导出数据
12.1 Athena操作步骤
- 创建库exp

- CREATE TABLE 语句必须包含分区详细信息,使用 LOCATION 指定分区数据的根位置,运行以下内容并进行查询
- 查询dep表的结果
13. 总结
本文讨论的是在混合云架构下将本地Oracle数据库数据上传到云上,利用云上的大数据工具进行分析,这只是亚马逊云科技数据湖的一个使用场景。数据湖是由多个大数据组件和云服务组成的一个解决方案,可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、JSON),非结构化数据(如文档、PDF)和二进制数据(如图片、音视频)。通过数据湖可以快速地存储、处理、分析海量的数据,同时在安全合规的场景下使用多种多样的手段进行分析。
14. 参考资料
[1] 使用 AWS DMS 以 Parquet 格式将数据迁移到 Amazon S3
[2] Amazon RDS for Oracle与Amazon S3集成
[3] 使用Oracle数据泵将本地Oracle数据库迁移到适用Amazon RDS for Oracle