摘要:
AWS Lambda 函数现已支持打包和部署容器镜像,开发者通过官方提供或自己构建镜像文件,可以非常方便利用现有的开发工具,工作流轻松构建基于AWS Lambda的应用程序。基于容器打包的应用通过AWS Lambda可以实现更为简便的操作部署,更为快速的启动时间,更为强大的并发扩展以及高可用,同时无缝与140余种AWS服务集成。
本文将展示如何基于官方镜像(public.ecr.aws/lambda/python:3.8)基于AWS Lambda,Amazon ECR 服务构建一个低成本,高并发的轻量级分布式压测引擎。
关键消息:
无服务器化,容器技术,压力测试,现代程序开发
关键服务:
AWS Lambda,Amazon ECR
正文内容
前言
压力测试(后续简称压测)属于软件测试门类的一种,通过超出正常操作范围的负载以确定系统在极限情况下的稳定性,可用性和错误行为处理。该负载通常是特定持续时间内通过模拟预期并发用户执行特定数量的事务操作。被测对象通常为任务关键型业务,如数据库,应用服务器等,压力测试能帮助完成:1)业务上线预热;2)性能瓶颈评估;3)站点容量规划;4)架构升级验证。
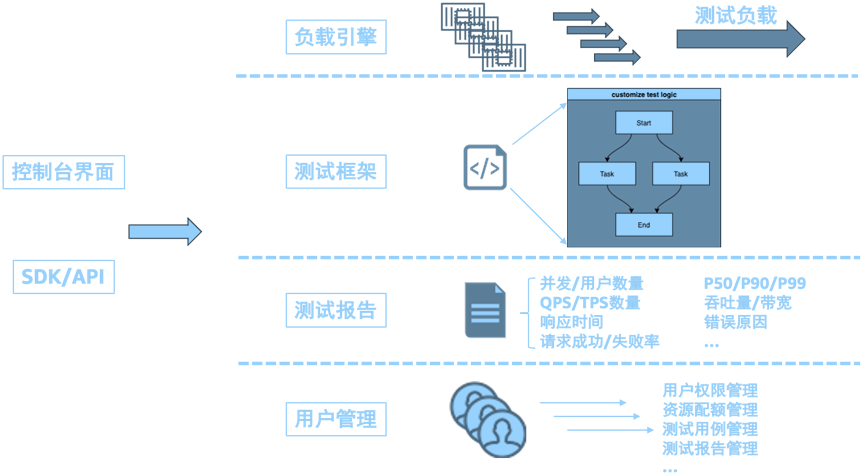
通常测试流程如下所示,其中测试工具的选择取决于被测系统的待测指标,业务的关键应用场景,团队对特定工具,框架的熟悉程度以及可支出的测试软硬件成本。

分布式压测平台通常包含几个核心组件:1)负载引擎,作为压测平台底层基础设施,根据测试框架特定配置产生对应并发数量,持续时间和流量协议的压测流量,如HTTP/HTTPS/TCP,理论上任何具有基本计算,网络和存储能力的设备都可以作为负载引擎;2)测试框架,负责产生虚拟用户模拟实际用户行为,提供配置文件编排测试逻辑,对接被测系统实现测试协议交互等;3)测试报告,负责通过实时或非实时的图表,文档等形式提供测试分析结果,包括并发/用户数量,QPS/TPS等指标;4)用户管理,负责测试用户权限管理,测试资源池的隔离和管理,测试用例和测试报告管理等。
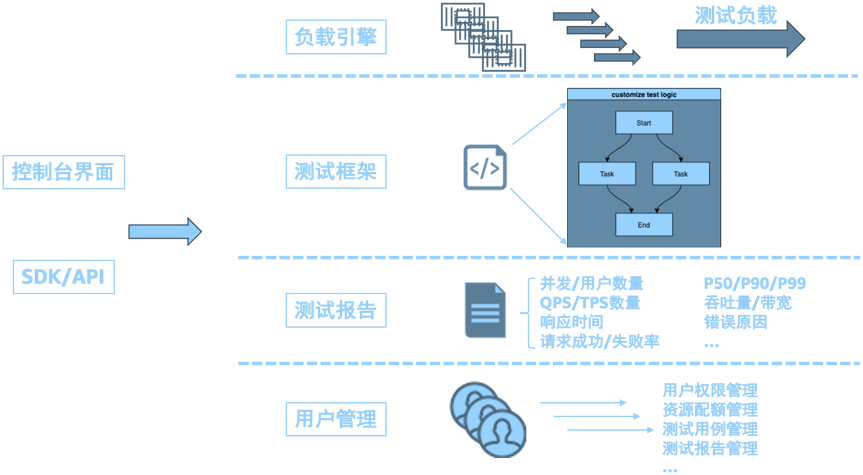
其中负载引擎作为产生测试负载的最终模块,其资源容量,调度速率,集成复杂度决定了最终压测平台所能产生的压力负载的上限。AWS Lambda作为无服务器架构的关键服务,具备无需运维后端计算资源,实例拉起速度快,按执行时长付费等特点,2020年新发布的Lambda Container特性使得基于容器进行测试框架的集成更为便捷高效。目前Lambda内存为2048MB的情况下单并发实例理论上可模拟100虚拟用户(vu),按照Lambda默认并发数量1000计算,利用Lambda作为负载引擎单账户可模拟的虚拟用户为10,0000。接下来我们将基于AWS Lambda来搭建一个轻量化的分布式压测引擎。
流程概览
伴随AWS Lambda对容器镜像支持的特性发布,AWS官方提供了一组Lambda基础镜像,可在Amazon ECR(gallery.ecr.aws/lambda)和Docker Hub(amazon/aws-lambda-python)上获取,该基础镜像预装了包括Node.js,Python,Java等语言的Lambda运行时,必要组件并提供了dockerfile。同时AWS官方还开源了运行时接口客户端(RIC)和运行时接口仿真器(RIE),方便用户构建同Lambda兼容的容器镜像并进行本地测试。
本文利用容器镜像来封装压测引擎所需的测试框架,通过Lambda实现测试配置参数的传入和测试用例的触发执行,其中所封装的测试框架为Taurus,一个开源测试自动化框架,底层集成诸多测试套件如JMeter,ApacheBenchmark,JUnit,提供了基于YAML的配置文件来实现测试逻辑编排,同时提供CLI命令行来执行测试用例并生成xml格式的测试结果。
创建步骤
构建容器镜像
我们采用AWS官方基础镜像,内置运行时接口客户端(RIC),实现了Lambda的运行时API,包括调用事件检索,调用响应返回,调用错误处理和初始化错误等功能实现Lambda能正确接收处理调用并返回结果。镜像dockerfile如下,主要包括:1)Taurus,JMeter(Taurus的默认执行脚本)安装;2)Taurus启动配置(bzt-rc);3)测试用例配置(test.json);4)测试执行脚本(load-test.sh)。需要注意AWS Lambda内文件系统仅/tmp是可读写,其他文件目录仅为可读目录,且Lambda在云端启动后会将/tmp目录重新初始化(本地调试没有该初始化),所以打包镜像文件时不能直接将bzt-rc,test.json等文件通过COPY/ADD方式放入/tmp目录,这里我们通过/var/task作为中间站进行转存,这个细节在app.py中会再次提到。
# FROM blazemeter/taurus
FROM public.ecr.aws/lambda/python:3.8
ARG JMETER_VERSION=5.4.1
# Taurus includes python and pip
# RUN /usr/bin/python3 -m pip install --upgrade pip
RUN /var/lang/bin/python3.8 -m pip install --upgrade pip
RUN yum install -y gcc java xmlstarlet bc unzip
RUN pip install bzt
RUN pip install --no-cache-dir awscli
COPY apache-jmeter-${JMETER_VERSION}.zip /var/task
RUN mkdir -p /var/task/.bzt/jmeter-taurus/${JMETER_VERSION}
RUN unzip /var/task/apache-jmeter-${JMETER_VERSION}.zip -d /var/task/.bzt/jmeter-taurus/${JMETER_VERSION}
COPY bzt-rc /var/task/.bzt-rc
COPY cli.py /var/lang/lib/python3.8/site-packages/bzt/cli.py
RUN mkdir -p /tmp/artifacts
# Taurus working directory /tmp in Lambda container
COPY test.json /var/task
COPY load-test.sh /var/task
RUN chmod 755 /var/task/load-test.sh
# schedule app to invoke Taurus shell
COPY app.py ./
CMD ["app.handler"]
Taurus启动配置文件(bzt-rc)如下,包括指定测试过程生成文件的存放目录,测试工具JMeter的执行路径。
settings:
# default-executor: jmeter # if you prefer using other executor by default - change this option
artifacts-dir: /tmp/bzt-artifacts/%Y-%m-%d_%H-%M-%S.%f # change the default place to store artifact files
check-updates: false # check for newer version of Taurus on startup
modules:
jmeter:
path: /tmp/.bzt/jmeter-taurus/5.4.1/bin/jmeter # path to local jmeter installation
test.json测试用例配置文件如下,主要用于配置并发(concurrency),预热(ramp-up),持续时间(hold-for),测试方法(url/method/body/headers)等基础参数。
{
"execution": [
{
"concurrency": 100,
"ramp-up": "5m",
"hold-for": "1m",
"scenario": "your scenario name"
}
],
"scenarios": {
"exampleName": {
"requests": [
{
"url": "http://www.example.com",
"method": "GET",
"body": {},
"headers": {}
}
]
}
},
"reporting": [
{
"module": "final-stats",
"summary": true,
"percentiles": true,
"summary-labels": true,
"test-duration": true,
"dump-xml": "/tmp/artifacts/results.xml"
}
]
}
Lambda的执行文件app.py内容如下,代码首先将上述bzt-rc,test.json,load-test.sh等文件拷贝至/tmp进行后续的读写操作,同时我们利用Lambda环境变量传入S3_BUCKET参数来指定测试结果上传的S3桶,之后调用load-test.sh来实现最终实现Taurus的执行。
from __future__ import print_function
import json
import sys
import os
import logging
from os import getenv
from boto3 import client
from botocore.exceptions import ClientError
# REQUIRED: The table name to copy records to.
S3_BUCKET = getenv('S3_BUCKET')
# @see https://docs.python.org/3/library/logging.html#logging-levels
LOGGING_LEVEL = getenv('LOGGING_LEVEL', 'INFO')
# Set up logging level, and stream stream to stdout if not running in Lambda.
# (We don't want to change the basicConfig if we ARE running in Lambda).
logger = logging.getLogger(__name__)
if getenv('AWS_EXECUTION_ENV') is None:
logging.basicConfig(stream=sys.stdout, level=LOGGING_LEVEL)
else:
logger.setLevel(LOGGING_LEVEL)
# Helper class to convert a DynamoDB item to JSON.
class DecimalEncoder(json.JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
if o % 1 > 0:
return float(o)
else:
return int(o)
return super(DecimalEncoder, self).default(o)
dynamodb = client('dynamodb', region_name='us-east-1')
def handler(event, context):
os.system('cp -r /var/task/. /tmp')
os.system('touch /tmp/artifacts/results.xml')
cmd = '/tmp/load-test.sh '+ S3_BUCKET
os.system(cmd)
logger.info('invoke event from jmeter %s' % json.dumps(event, indent=4, cls=DecimalEncoder))
# upload test results to DynamoDB
# Omit here…
return {
"statusCode": 200,
"body": json.dumps({
"HTTPStatusCode": 200,
}),
}
其中load-test.sh脚本内容如下,主要包括Taurus命令行调用,测试结果解析和测试结果上传等功能。
#!/bin/bash
echo "S3_BUCKET:: ${1}"
S3_BUCKET=${1}
echo "Running test"
bzt test.json -o modules.console.disable=true | tee -a result.tmp
if [ -f /tmp/artifacts/results.xml ]; then
echo "Validating Test Duration"
TEST_DURATION=`xmlstarlet sel -t -v "/FinalStatus/TestDuration" /tmp/artifacts/results.xml`
if (( $(echo "$TEST_DURATION > $CALCULATED_DURATION" | bc -l) )); then
echo "Updating test duration: $CALCULATED_DURATION s"
xmlstarlet ed -L -u /FinalStatus/TestDuration -v $CALCULATED_DURATION /tmp/artifacts/results.xml
fi
echo "Uploading results"
aws s3 cp /tmp/artifacts/results.xml s3://$S3_BUCKET/results/demo.xml
else
echo "There might be an error happened while the test."
fi
所有文件准备完毕后,我们开始打包容器镜像并推送到AWS ECR,执行如下命令:
# 登陆ECR
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
# 打包,tag,推送
docker build -t bzt-lambda:local -f DockerfileLambda . && docker tag bzt-lambda:local 123456789012.dkr.ecr.us-east-1.amazonaws.com/taurus:latest && docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/taurus:latest
至此,容器镜像已经构建完毕,接下来我们利用内置运行时接口客户端(RIC)进行本地调试。
本地调试验证
登陆终端在本地拉起容器,命令如下。
docker run -p 9000:8080 bzt-lambda:local
新开一个终端登录进该容器,检查对应的脚本文件是否正常创建。
docker exec -it $(docker ps -q) /bin/bash
bash-4.2# ls /tmp/
artifacts
bash-4.2# ls /var/task/
apache-jmeter-5.4.1.zip app.py load-test.sh test.json
bash-4.2# which bzt
/var/lang/bin/bzt
退出容器,执行如下命令触发测试执行。
curl -XPOST "http://localhost:9000/2015-0331/functions/function/invocations" -d '{}'
在原终端界面能看到对应的测试执行信息如下。
Running test
15:20:00 INFO: Taurus CLI Tool v1.15.2
15:20:00 INFO: Starting with configs: ['test.json']
15:20:00 INFO: Configuring...
15:20:00 INFO: Artifacts dir: /tmp/bzt-artifacts/2021-02-24_15-20-00.431695
15:20:00 INFO: Preparing...
…
15:21:01 INFO: Current: 15 vu 17 succ 0 fail 0.865 avg rt / Cumulative: 0.910 avg rt, 0% failures
15:21:02 INFO: Current: 16 vu 19 succ 0 fail 0.925 avg rt / Cumulative: 0.911 avg rt, 0% failures
15:21:03 INFO: Current: 16 vu 16 succ 0 fail 0.881 avg rt / Cumulative: 0.910 avg rt, 0% failures
15:21:04 INFO: Current: 16 vu 17 succ 0 fail 0.876 avg rt / Cumulative: 0.908 avg rt, 0% failures
15:21:05 INFO: Current: 17 vu 24 succ 0 fail 0.835 avg rt / Cumulative: 0.905 avg rt, 0% failures
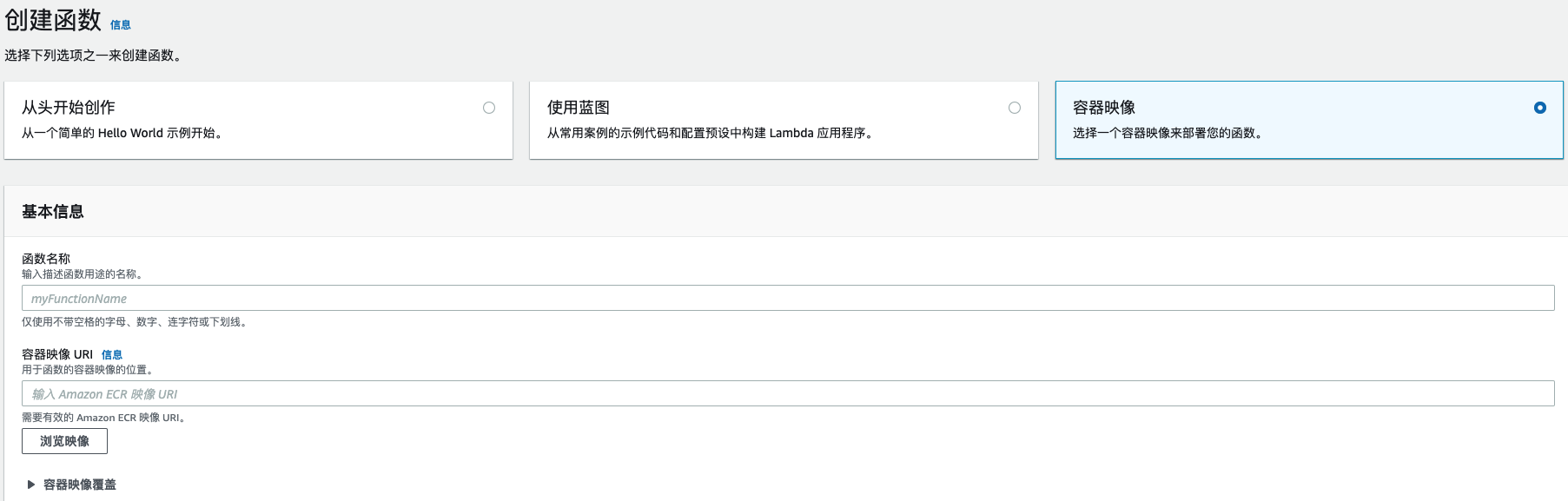
创建Lambda函数
登陆到Lambda控制台,点击“创建函数”,选择“容器映像”
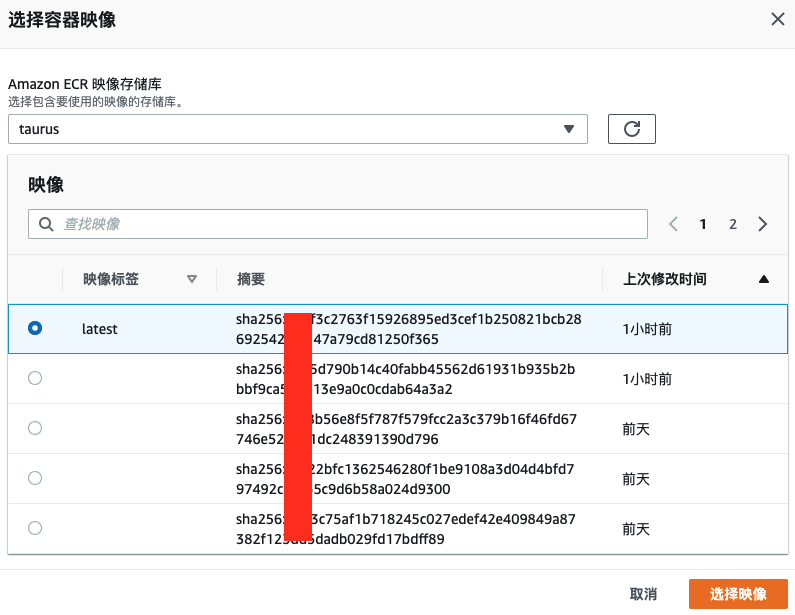
然后选择“浏览映像”,选择之前推送到AWS ECR 的容器镜像,点击创建函数即可。
创建完毕后设置内存为1024M以上以保障Taurus能正常运行,超时时间按照压测时间调整,比如15分钟。
通过环境变量写入S3_BUCKET参数来指定测试结果上传的S3桶,至此基于Lambda的压测引擎创建完毕。

对接HTTP服务
Lambda创建完毕后,用户可以结合API Gateway实现HTTP前端调用来进一步整合后端压测引擎,实现测试任务的编排等功能。通过SAM(Serverless Application Model)模版我们可以快速构建一个典型的HTTP前端加Lambda后端的测试应用,示例模版部分内容如下所示:
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
PackageType: Image
Events:
InvokeTest:
Type: Api
Properties:
Path: /test
Method: get
ImageUrl: ‘123456789012.dkr.ecr.us-east-1.amazonaws.com/taurus:latest’
ImageConfig:
Command:
- "app.handler"
WorkingDirectory: "/var/task"
Metadata:
DockerTag: python3.8
DockerContext: ./test
Dockerfile: Dockerfile
之后通过SAM CLI实现AWS API Gateway,Lambda以及对应IAM的编译,调试和部署,有关SAM的具体的操作参见这里。待服务部署完毕后,用户可通过调用类似curl –request POST -H “Content-Type: application/json” -d ‘{“testName”: “demo”, “concurrency”: “100 “}’ https://1234567890.execute-api.us-east-1.amazonaws.com/test
写在最后
利用AWS Lambda构建分布式压测引擎,我们无需关心底层计算资源的配置,调度和运维工作,借助无服务架构的自动扩容,按执行计费等优点,使得不论是个人还是企业都能以极低成本快速构建一个轻量级压测引擎,并通过进一步结合AWS其他服务实现更为复杂的测试平台功能。需要注意受限于目前AWS Lambda最长执行时长,相应压测最长时间不能超过15分钟,后续我们可以考虑结合AWS Step Function的方式来实现较长压测任务下AWS Lambda实例的分解和串联,以消除该15分钟限制实现更为丰富的功能。
本篇作者